 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Enhancement and Super-Resolution of Underwater Imagery for Improved Visual Perception
Paper and Code



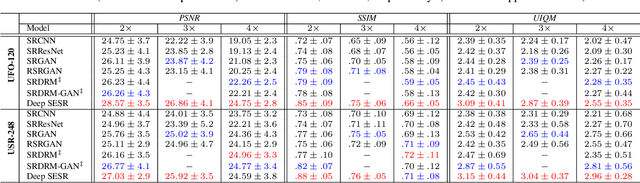
In this paper, we introduce and tackle the simultaneous enhancement and super-resolution (SESR) problem for underwater robot vision and provide an efficient solution for near real-time applications. We present Deep SESR, a residual-in-residual network-based generative model that can learn to restore perceptual image qualities at 2x, 3x, or 4x higher spatial resolution. We supervise its training by formulating a multi-modal objective function that addresses the chrominance-specific underwater color degradation, lack of image sharpness, and loss in high-level feature representation. It is also supervised to learn salient foreground regions in the image, which in turn guides the network to learn global contrast enhancement. We design an end-to-end training pipeline to jointly learn the saliency prediction and SESR on a shared hierarchical feature space for fast inference. Moreover, we present UFO-120, the first dataset to facilitate large-scale SESR learning; it contains over 1500 training samples and a benchmark test set of 120 samples. By thorough experimental evaluation on the UFO-120 and other standard datasets, we demonstrate that Deep SESR outperforms the existing solutions for underwater image enhancement and super-resolution. We also validate its generalization performance on several test cases that include underwater images with diverse spectral and spatial degradation levels, and also terrestrial images with unseen natural objects. Lastly, we analyze its computational feasibility for single-board deployments and demonstrate its operational benefits for visually-guided underwater robots. The model and dataset information will be available at: https://github.com/xahidbuffon/Deep-SESR.