 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boundary-Aware Segmentation Network for Mobile and Web Applications
Jan 12, 2021

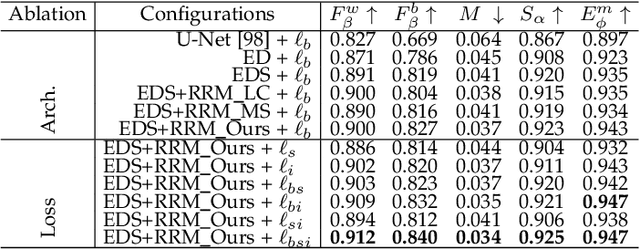
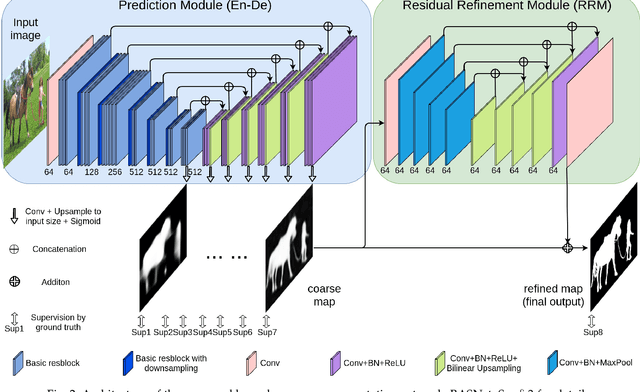
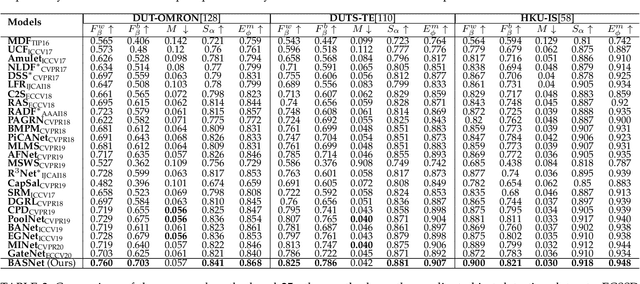
Although deep models have greatly improved the accuracy and robustness of image segmentation, obtaining segmentation results with highly accurate boundaries and fine structures is still a challenging problem. In this paper, we propose a simple yet powerful Boundary-Aware Segmentation Network (BASNet), which comprises a predict-refine architecture and a hybrid loss, for highly accurate image segmentation. The predict-refine architecture consists of a densely supervised encoder-decoder network and a residual refinement module, which are respectively used to predict and refine a segmentation probability map. The hybrid loss is a combination of the binary cross entropy, structural similarity and intersection-over-union losses, which guide the network to learn three-level (ie, pixel-, patch- and map- level) hierarchy representations. We evaluate our BASNet on two reverse tasks including salient object segmentation, camouflaged object segmentation, showing that it achieves very competitive performance with sharp segmentation boundaries. Importantly, BASNet runs at over 70 fps on a single GPU which benefits many potential real applications. Based on BASNet, we further developed two (close to) commercial applications: AR COPY & PASTE, in which BASNet is integrated with augmented reality for "COPYING" and "PASTING" real-world objects, and OBJECT CUT, which is a web-based tool for automatic object background removal. Both applications have already drawn huge amount of attention and have important real-world impacts. The code and two applications will be publicly available at: https://github.com/NathanUA/BASNet.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Mar 09, 2021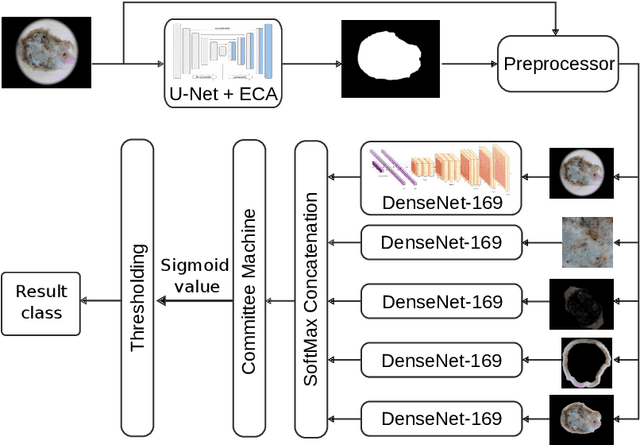
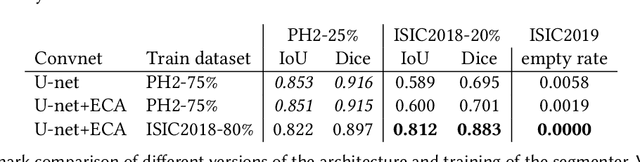
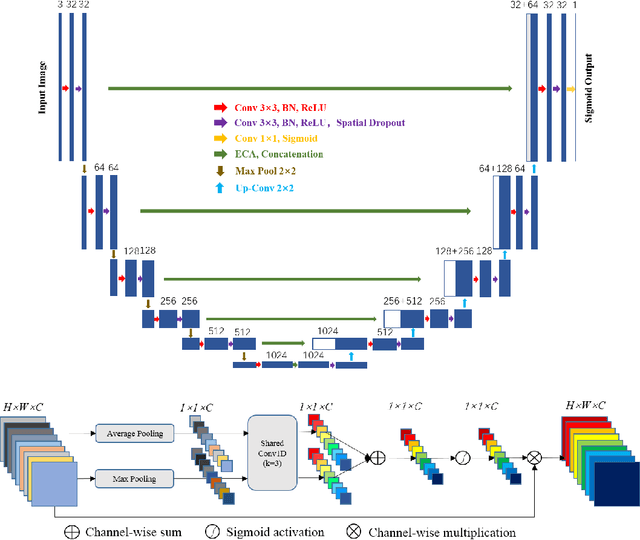
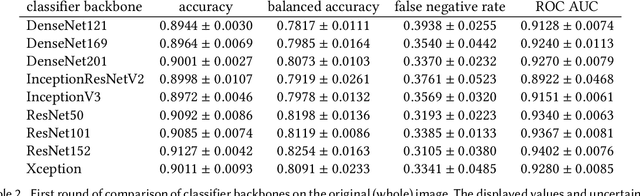
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.
Impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning
Apr 06, 2018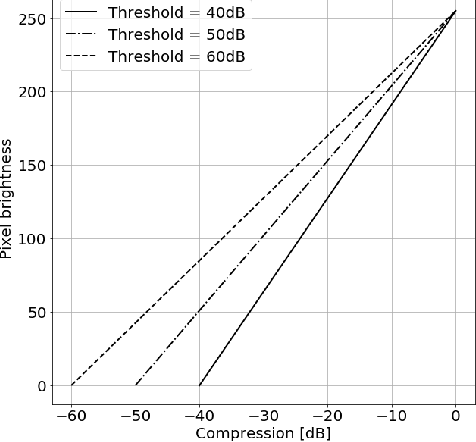
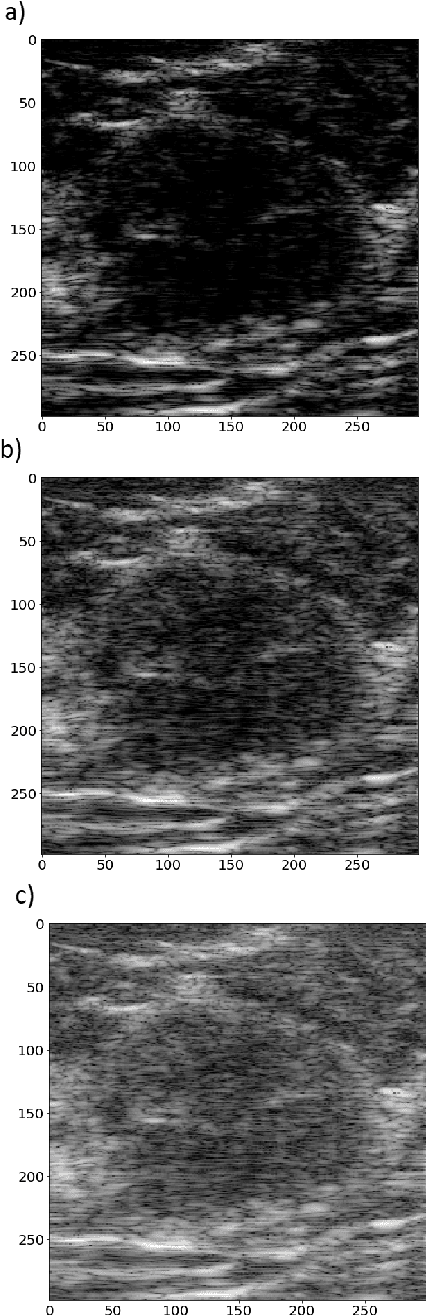
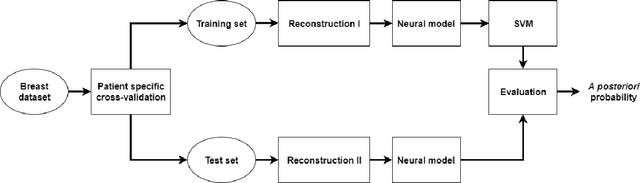
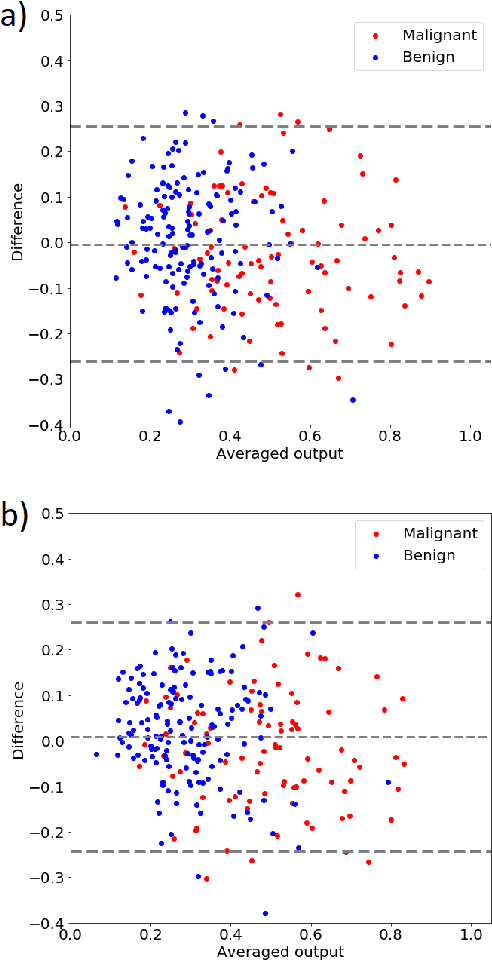
Deep learning algorithms, especially convolutional neural networks, have become a methodology of choice in medical image analysis. However, recent studies in computer vision show that even a small modification of input image intensities may cause a deep learning model to classify the image differently. In medical imaging, the distribution of image intensities is related to applied image reconstruction algorithm. In this paper we investigate the impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning. Due to high dynamic range raw ultrasonic signals are commonly compressed in order to reconstruct B-mode images. Based on raw data acquired from breast lesions, we reconstruct B-mode images using different compression levels. Next, transfer learning is applied for classification. Differently reconstructed images are employed for training and evaluation. We show that the modification of the reconstruction algorithm leads to decrease of classification performance. As a remedy, we propose a method of data augmentation. We show that the augmentation of the training set with differently reconstructed B-mode images leads to a more robust and efficient classification. Our study suggests that it is important to take into account image reconstruction algorithms implemented in medical scanners during development of computer aided diagnosis systems.
Photorealistic Image Reconstruction from Hybrid Intensity and Event based Sensor
Oct 25, 2018
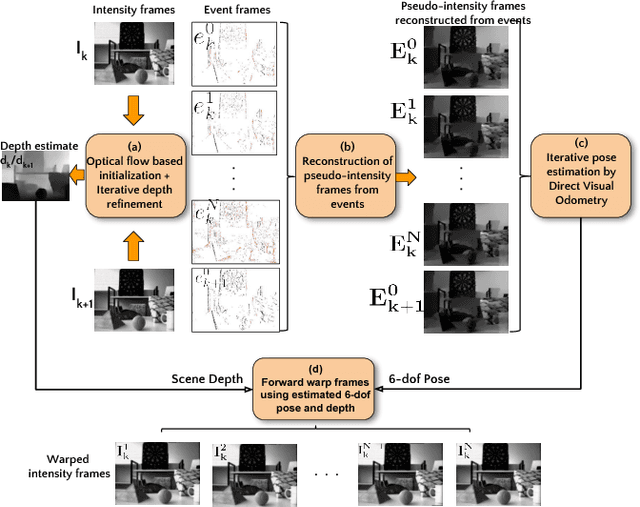
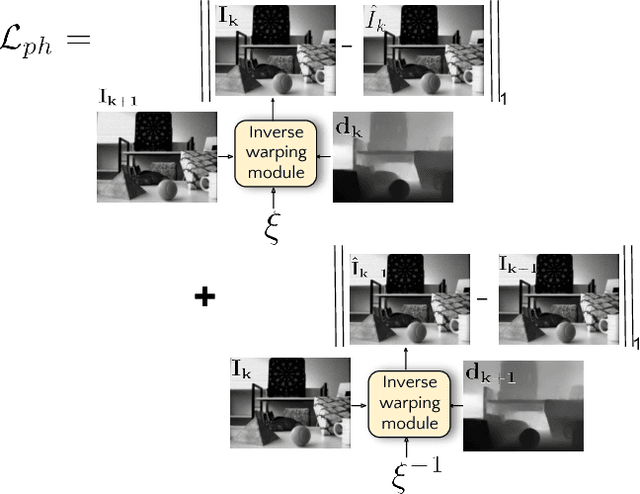
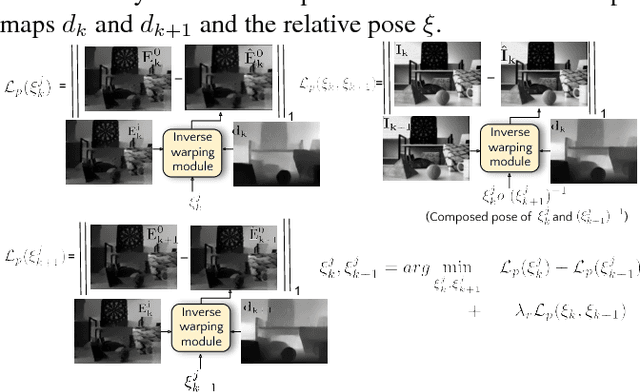
Event sensors output a stream of asynchronous brightness changes (called "events") at a very high temporal rate. Since, these "events" cannot be used directly for traditional computer vision algorithms, many researchers attempted at recovering the intensity information from this stream of events. Although the results are promising, they lack the texture and the consistency of natural videos. We propose to reconstruct photorealistic intensity images from a hybrid sensor consisting of a low frame rate conventional camera along with the event sensor. DAVIS is a commercially available hybrid sensor which bundles the conventional image sensor and the event sensor into a single hardware. To accomplish our task, we use the low frame rate intensity images and warp them to the temporally dense locations of the event data by estimating a spatially dense scene depth and temporally dense sensor ego-motion. We thereby obtain temporally dense photorealisitic images which would have been very difficult by using only either the event sensor or the conventional low frame-rate image sensor. In addition, we also obtain spatio-temporally dense scene flow as a by product of estimating spatially dense depth map and temporally dense sensor ego-motion.
Deep Learning Methods for Screening Pulmonary Tuberculosis Using Chest X-rays
Dec 25, 2020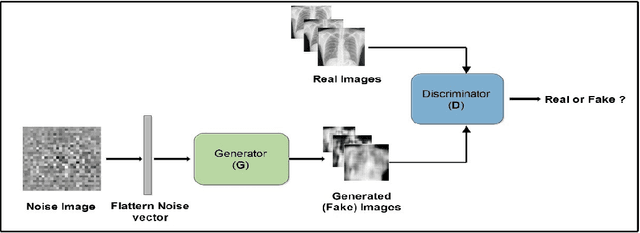
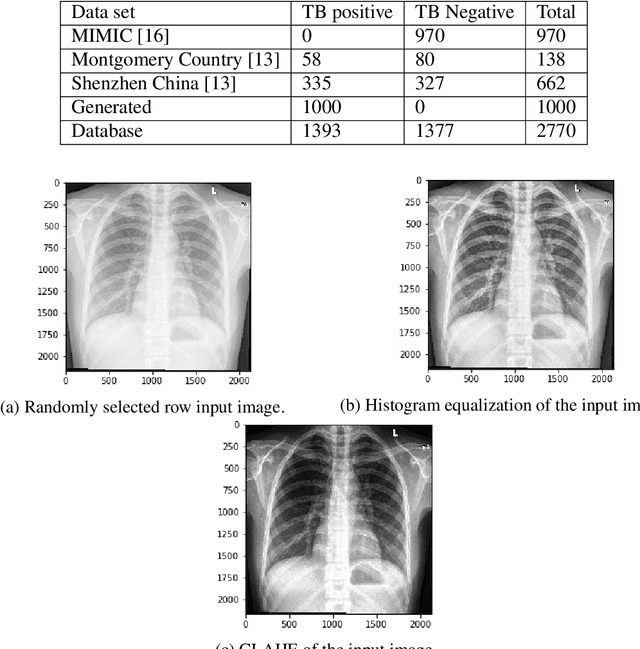
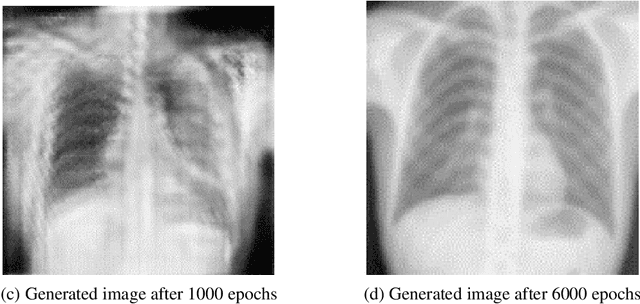
Tuberculosis (TB) is a contagious bacterial airborne disease, and is one of the top 10 causes of death worldwide. According to the World Health Organization (WHO), around 1.8 billion people are infected with TB and 1.6 million deaths were reported in 2018. More importantly,95% of cases and deaths were from developing countries. Yet, TB is a completely curable disease through early diagnosis. To achieve this goal one of the key requirements is efficient utilization of existing diagnostic technologies, among which chest X-ray is the first line of diagnostic tool used for screening for active TB. The presented deep learning pipeline consists of three different state of the art deep learning architectures, to generate, segment and classify lung X-rays. Apart from this image preprocessing, image augmentation, genetic algorithm based hyper parameter tuning and model ensembling were used to to improve the diagnostic process. We were able to achieve classification accuracy of 97.1% (Youden's index-0.941,sensitivity of 97.9% and specificity of 96.2%) which is a considerable improvement compared to the existing work in the literature. In our work, we present an highly accurate, automated TB screening system using chest X-rays, which would be helpful especially for low income countries with low access to qualified medical professionals.
* Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization (2020)
mDALU: Multi-Source Domain Adaptation and Label Unification with Partial Datasets
Dec 15, 2020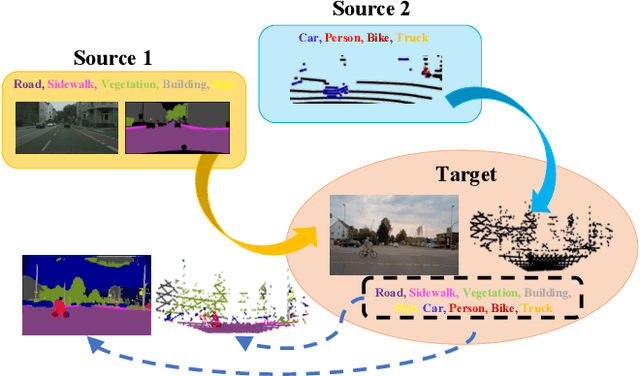

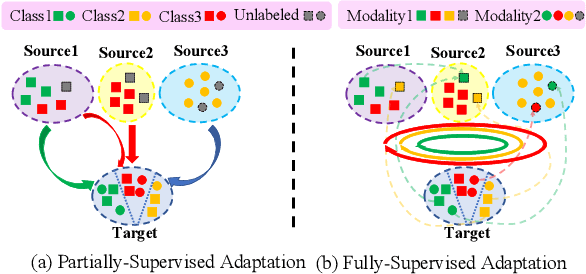
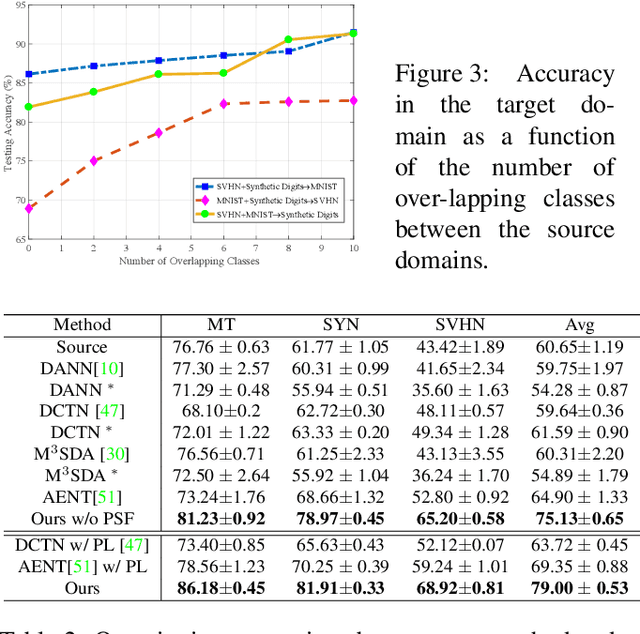
Object recognition advances very rapidly these days. One challenge is to generalize existing methods to new domains, to more classes and/or to new data modalities. In order to avoid annotating one dataset for each of these new cases, one needs to combine and reuse existing datasets that may belong to different domains, have partial annotations, and/or have different data modalities. This paper treats this task as a multi-source domain adaptation and label unification (mDALU) problem and proposes a novel method for it. Our method consists of a partially-supervised adaptation stage and a fully-supervised adaptation stage. In the former, partial knowledge is transferred from multiple source domains to the target domain and fused therein. Negative transfer between unmatched label space is mitigated via three new modules: domain attention, uncertainty maximization and attention-guided adversarial alignment. In the latter, knowledge is transferred in the unified label space after a label completion process with pseudo-labels. We verify the method on three different tasks, image classification, 2D semantic image segmentation, and joint 2D-3D semantic segmentation. Extensive experiments show that our method outperforms all competing methods significantly.
Pose2Pose: 3D Positional Pose-Guided 3D Rotational Pose Prediction for Expressive 3D Human Pose and Mesh Estimation
Nov 23, 2020
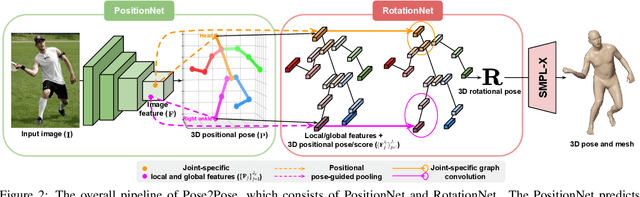

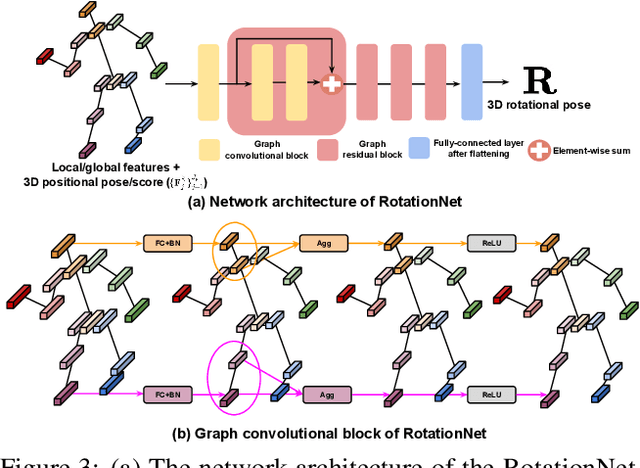
Previous 3D human pose and mesh estimation methods mostly rely on only global image feature to predict 3D rotations of human joints (i.e., 3D rotational pose) from an input image. However, local features on the position of human joints (i.e., positional pose) can provide joint-specific information, which is essential to understand human articulation. To effectively utilize both local and global features, we present Pose2Pose, a 3D positional pose-guided 3D rotational pose prediction network, along with a positional pose-guided pooling and joint-specific graph convolution. The positional pose-guided pooling extracts useful joint-specific local and global features. Also, the joint-specific graph convolution effectively processes the joint-specific features by learning joint-specific characteristics and different relationships between different joints. We use Pose2Pose for expressive 3D human pose and mesh estimation and show that it outperforms all previous part-specific and expressive methods by a large margin. The codes will be publicly available.
AMPA-Net: Optimization-Inspired Attention Neural Network for Deep Compressed Sensing
Oct 22, 2020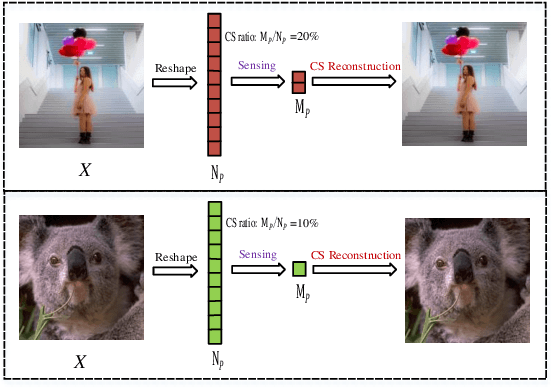
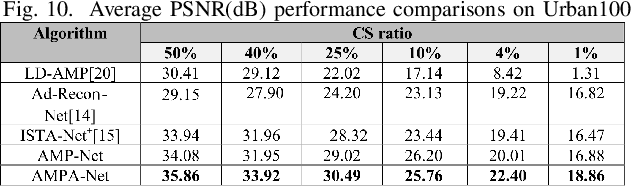
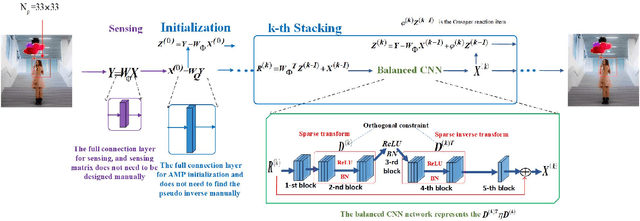
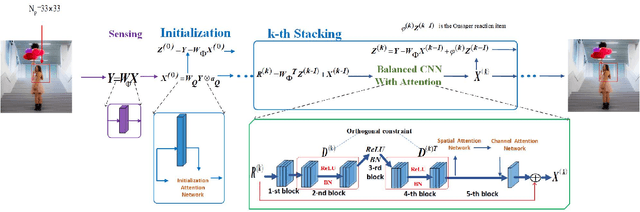
Compressed sensing (CS) is a challenging problem in image processing due to reconstructing an almost complete image from a limited measurement. To achieve fast and accurate CS reconstruction, we synthesize the advantages of two well-known methods (neural network and optimization algorithm) to propose a novel optimization inspired neural network which dubbed AMP-Net. AMP-Net realizes the fusion of the Approximate Message Passing (AMP) algorithm and neural network. All of its parameters are learned automatically. Furthermore, we propose an AMPA-Net which uses three attention networks to improve the representation ability of AMP-Net. Finally, We demonstrate the effectiveness of AMP-Net and AMPA-Net on four standard CS reconstruction benchmark data sets.
* 7 pages,7 figures
Flexible Bayesian Modelling for Nonlinear Image Registration
Jun 03, 2020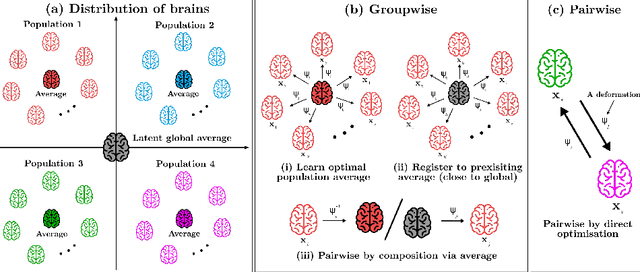
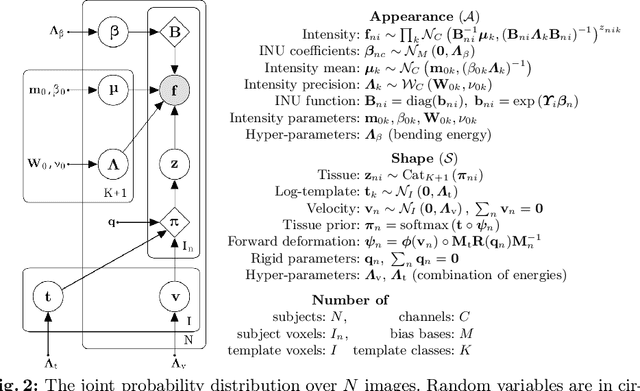

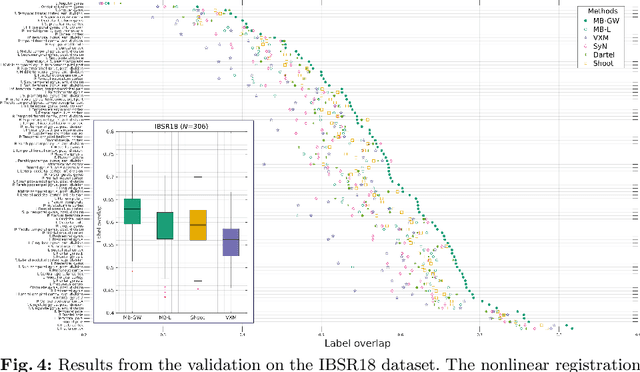
We describe a diffeomorphic registration algorithm that allows groups of images to be accurately aligned to a common space, which we intend to incorporate into the SPM software. The idea is to perform inference in a probabilistic graphical model that accounts for variability in both shape and appearance. The resulting framework is general and entirely unsupervised. The model is evaluated at inter-subject registration of 3D human brain scans. Here, the main modeling assumption is that individual anatomies can be generated by deforming a latent 'average' brain. The method is agnostic to imaging modality and can be applied with no prior processing. We evaluate the algorithm using freely available, manually labelled datasets. In this validation we achieve state-of-the-art results, within reasonable runtimes, against previous state-of-the-art widely used, inter-subject registration algorithms. On the unprocessed dataset, the increase in overlap score is over 17%. These results demonstrate the benefits of using informative computational anatomy frameworks for nonlinear registration.
Visual Distant Supervision for Scene Graph Generation
Mar 29, 2021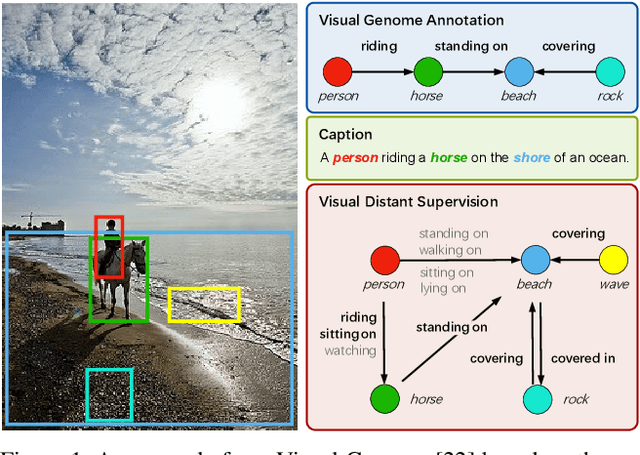
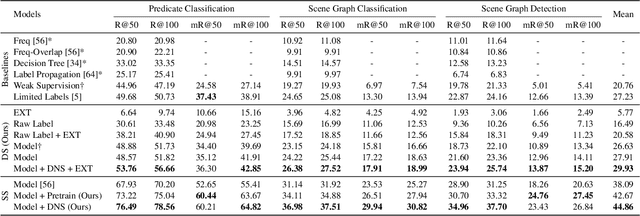
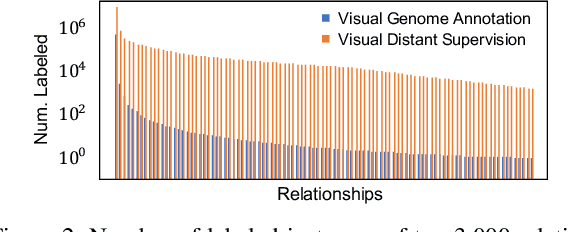
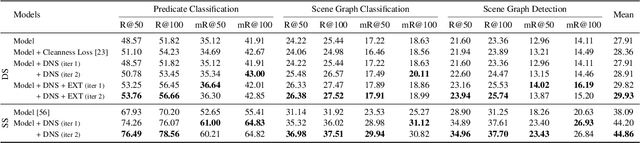
Scene graph generation aims to identify objects and their relations in images, providing structured image representations that can facilitate numerous applications in computer vision. However, scene graph models usually require supervised learning on large quantities of labeled data with intensive human annotation. In this work, we propose visual distant supervision, a novel paradigm of visual relation learning, which can train scene graph models without any human-labeled data. The intuition is that by aligning commonsense knowledge bases and images, we can automatically create large-scale labeled data to provide distant supervision for visual relation learning. To alleviate the noise in distantly labeled data, we further propose a framework that iteratively estimates the probabilistic relation labels and eliminates the noisy ones. Comprehensive experimental results show that our distantly supervised model outperforms strong weakly supervised and semi-supervised baselines. By further incorporating human-labeled data in a semi-supervised fashion, our model outperforms state-of-the-art fully supervised models by a large margin (e.g., 8.6 micro- and 7.6 macro-recall@50 improvements for predicate classification in Visual Genome evaluation). All the data and code will be available to facilitate future research.