 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultLFG: Training-free Multi-LoRA composition using Frequency-domain Guidance
May 26, 2025



Low-Rank Adaptation (LoRA) has gained prominence as a computationally efficient method for fine-tuning generative models, enabling distinct visual concept synthesis with minimal overhead. However, current methods struggle to effectively merge multiple LoRA adapters without training, particularly in complex compositions involving diverse visual elements. We introduce MultLFG, a novel framework for training-free multi-LoRA composition that utilizes frequency-domain guidance to achieve adaptive fusion of multiple LoRAs. Unlike existing methods that uniformly aggregate concept-specific LoRAs, MultLFG employs a timestep and frequency subband adaptive fusion strategy, selectively activating relevant LoRAs based on content relevance at specific timesteps and frequency bands. This frequency-sensitive guidance not only improves spatial coherence but also provides finer control over multi-LoRA composition, leading to more accurate and consistent results. Experimental evaluations on the ComposLoRA benchmark reveal that MultLFG substantially enhances compositional fidelity and image quality across various styles and concept sets, outperforming state-of-the-art baselines in multi-concept generation tasks. Code will be released.
An Evaluation of Large Pre-Trained Models for Gesture Recognition using Synthetic Videos
Oct 03, 2024In this work, we explore the possibility of using synthetically generated data for video-based gesture recognition with large pre-trained models. We consider whether these models have sufficiently robust and expressive representation spaces to enable "training-free" classification. Specifically, we utilize various state-of-the-art video encoders to extract features for use in k-nearest neighbors classification, where the training data points are derived from synthetic videos only. We compare these results with another training-free approach -- zero-shot classification using text descriptions of each gesture. In our experiments with the RoCoG-v2 dataset, we find that using synthetic training videos yields significantly lower classification accuracy on real test videos compared to using a relatively small number of real training videos. We also observe that video backbones that were fine-tuned on classification tasks serve as superior feature extractors, and that the choice of fine-tuning data has a substantial impact on k-nearest neighbors performance. Lastly, we find that zero-shot text-based classification performs poorly on the gesture recognition task, as gestures are not easily described through natural language.
* Synthetic Data for Artificial Intelligence and Machine Learning: Tools, Techniques, and Applications II (SPIE Defense + Commercial Sensing, 2024)
MV2MAE: Multi-View Video Masked Autoencoders
Jan 29, 2024Videos captured from multiple viewpoints can help in perceiving the 3D structure of the world and benefit computer vision tasks such as action recognition, tracking, etc. In this paper, we present a method for self-supervised learning from synchronized multi-view videos. We use a cross-view reconstruction task to inject geometry information in the model. Our approach is based on the masked autoencoder (MAE) framework. In addition to the same-view decoder, we introduce a separate cross-view decoder which leverages cross-attention mechanism to reconstruct a target viewpoint video using a video from source viewpoint, to help representations robust to viewpoint changes. For videos, static regions can be reconstructed trivially which hinders learning meaningful representations. To tackle this, we introduce a motion-weighted reconstruction loss which improves temporal modeling. We report state-of-the-art results on the NTU-60, NTU-120 and ETRI datasets, as well as in the transfer learning setting on NUCLA, PKU-MMD-II and ROCOG-v2 datasets, demonstrating the robustness of our approach. Code will be made available.
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Dec 06, 2023



In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
DIFFNAT: Improving Diffusion Image Quality Using Natural Image Statistics
Nov 16, 2023



Diffusion models have advanced generative AI significantly in terms of editing and creating naturalistic images. However, efficiently improving generated image quality is still of paramount interest. In this context, we propose a generic "naturalness" preserving loss function, viz., kurtosis concentration (KC) loss, which can be readily applied to any standard diffusion model pipeline to elevate the image quality. Our motivation stems from the projected kurtosis concentration property of natural images, which states that natural images have nearly constant kurtosis values across different band-pass versions of the image. To retain the "naturalness" of the generated images, we enforce reducing the gap between the highest and lowest kurtosis values across the band-pass versions (e.g., Discrete Wavelet Transform (DWT)) of images. Note that our approach does not require any additional guidance like classifier or classifier-free guidance to improve the image quality. We validate the proposed approach for three diverse tasks, viz., (1) personalized few-shot finetuning using text guidance, (2) unconditional image generation, and (3) image super-resolution. Integrating the proposed KC loss has improved the perceptual quality across all these tasks in terms of both FID, MUSIQ score, and user evaluation.
HaLP: Hallucinating Latent Positives for Skeleton-based Self-Supervised Learning of Actions
Apr 01, 2023Supervised learning of skeleton sequence encoders for action recognition has received significant attention in recent times. However, learning such encoders without labels continues to be a challenging problem. While prior works have shown promising results by applying contrastive learning to pose sequences, the quality of the learned representations is often observed to be closely tied to data augmentations that are used to craft the positives. However, augmenting pose sequences is a difficult task as the geometric constraints among the skeleton joints need to be enforced to make the augmentations realistic for that action. In this work, we propose a new contrastive learning approach to train models for skeleton-based action recognition without labels. Our key contribution is a simple module, HaLP - to Hallucinate Latent Positives for contrastive learning. Specifically, HaLP explores the latent space of poses in suitable directions to generate new positives. To this end, we present a novel optimization formulation to solve for the synthetic positives with an explicit control on their hardness. We propose approximations to the objective, making them solvable in closed form with minimal overhead. We show via experiments that using these generated positives within a standard contrastive learning framework leads to consistent improvements across benchmarks such as NTU-60, NTU-120, and PKU-II on tasks like linear evaluation, transfer learning, and kNN evaluation. Our code will be made available at https://github.com/anshulbshah/HaLP.
Synthetic-to-Real Domain Adaptation for Action Recognition: A Dataset and Baseline Performances
Mar 17, 2023



Human action recognition is a challenging problem, particularly when there is high variability in factors such as subject appearance, backgrounds and viewpoint. While deep neural networks (DNNs) have been shown to perform well on action recognition tasks, they typically require large amounts of high-quality labeled data to achieve robust performance across a variety of conditions. Synthetic data has shown promise as a way to avoid the substantial costs and potential ethical concerns associated with collecting and labeling enormous amounts of data in the real-world. However, synthetic data may differ from real data in important ways. This phenomenon, known as \textit{domain shift}, can limit the utility of synthetic data in robotics applications. To mitigate the effects of domain shift, substantial effort is being dedicated to the development of domain adaptation (DA) techniques. Yet, much remains to be understood about how best to develop these techniques. In this paper, we introduce a new dataset called Robot Control Gestures (RoCoG-v2). The dataset is composed of both real and synthetic videos from seven gesture classes, and is intended to support the study of synthetic-to-real domain shift for video-based action recognition. Our work expands upon existing datasets by focusing the action classes on gestures for human-robot teaming, as well as by enabling investigation of domain shift in both ground and aerial views. We present baseline results using state-of-the-art action recognition and domain adaptation algorithms and offer initial insight on tackling the synthetic-to-real and ground-to-air domain shifts.
DiffAlign : Few-shot learning using diffusion based synthesis and alignment
Dec 11, 2022



We address the problem of few-shot classification where the goal is to learn a classifier from a limited set of samples. While data-driven learning is shown to be effective in various applications, learning from less data still remains challenging. To address this challenge, existing approaches consider various data augmentation techniques for increasing the number of training samples. Pseudo-labeling is commonly used in a few-shot setup, where approximate labels are estimated for a large set of unlabeled images. We propose DiffAlign which focuses on generating images from class labels. Specifically, we leverage the recent success of the generative models (e.g., DALL-E and diffusion models) that can generate realistic images from texts. However, naive learning on synthetic images is not adequate due to the domain gap between real and synthetic images. Thus, we employ a maximum mean discrepancy (MMD) loss to align the synthetic images to the real images minimizing the domain gap. We evaluate our method on the standard few-shot classification benchmarks: CIFAR-FS, FC100, miniImageNet, tieredImageNet and a cross-domain few-shot classification benchmark: miniImageNet to CUB. The proposed approach significantly outperforms the stateof-the-art in both 5-shot and 1-shot setups on these benchmarks. Our approach is also shown to be effective in the zero-shot classification setup
Improved Modeling of 3D Shapes with Multi-view Depth Maps
Sep 07, 2020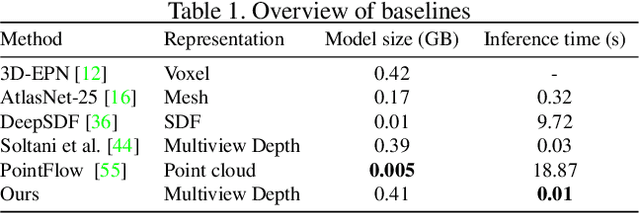
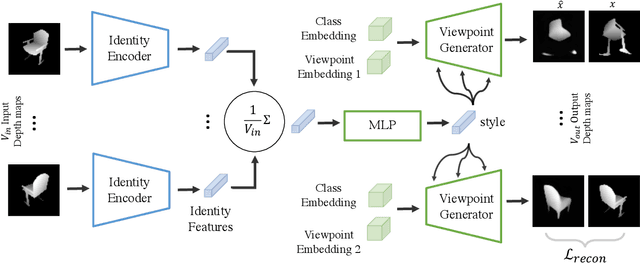
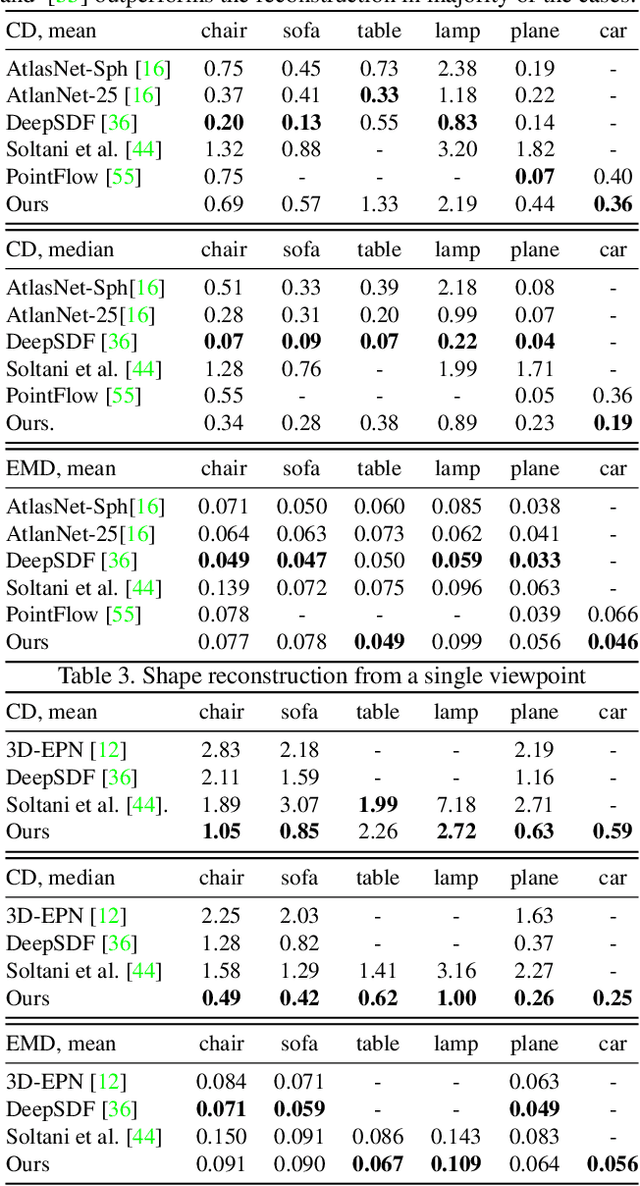

We present a simple yet effective general-purpose framework for modeling 3D shapes by leveraging recent advances in 2D image generation using CNNs. Using just a single depth image of the object, we can output a dense multi-view depth map representation of 3D objects. Our simple encoder-decoder framework, comprised of a novel identity encoder and class-conditional viewpoint generator, generates 3D consistent depth maps. Our experimental results demonstrate the two-fold advantage of our approach. First, we can directly borrow architectures that work well in the 2D image domain to 3D. Second, we can effectively generate high-resolution 3D shapes with low computational memory. Our quantitative evaluations show that our method is superior to existing depth map methods for reconstructing and synthesizing 3D objects and is competitive with other representations, such as point clouds, voxel grids, and implicit functions.
Photorealistic Image Reconstruction from Hybrid Intensity and Event based Sensor
Oct 25, 2018
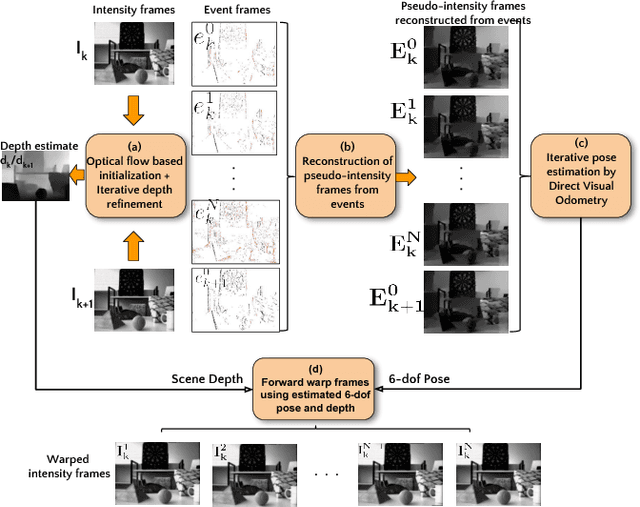
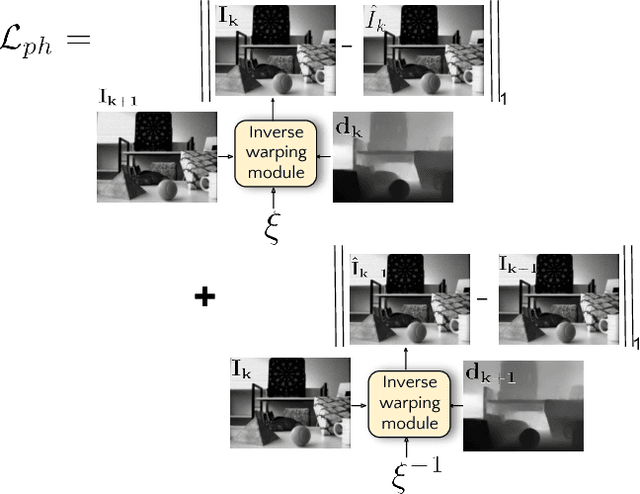
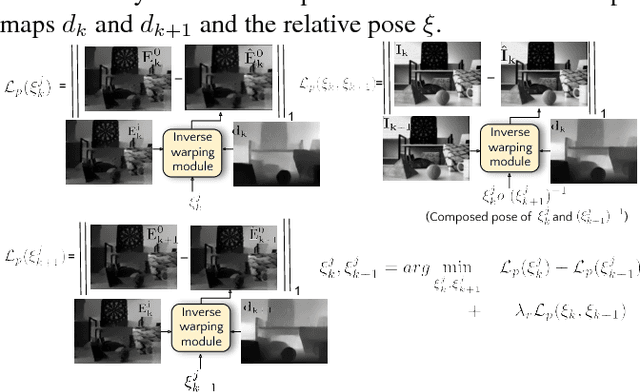
Event sensors output a stream of asynchronous brightness changes (called "events") at a very high temporal rate. Since, these "events" cannot be used directly for traditional computer vision algorithms, many researchers attempted at recovering the intensity information from this stream of events. Although the results are promising, they lack the texture and the consistency of natural videos. We propose to reconstruct photorealistic intensity images from a hybrid sensor consisting of a low frame rate conventional camera along with the event sensor. DAVIS is a commercially available hybrid sensor which bundles the conventional image sensor and the event sensor into a single hardware. To accomplish our task, we use the low frame rate intensity images and warp them to the temporally dense locations of the event data by estimating a spatially dense scene depth and temporally dense sensor ego-motion. We thereby obtain temporally dense photorealisitic images which would have been very difficult by using only either the event sensor or the conventional low frame-rate image sensor. In addition, we also obtain spatio-temporally dense scene flow as a by product of estimating spatially dense depth map and temporally dense sensor ego-motion.