 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistive AI for Augmenting Human Decision-making
Oct 18, 2024Regulatory frameworks for the use of AI are emerging. However, they trail behind the fast-evolving malicious AI technologies that can quickly cause lasting societal damage. In response, we introduce a pioneering Assistive AI framework designed to enhance human decision-making capabilities. This framework aims to establish a trust network across various fields, especially within legal contexts, serving as a proactive complement to ongoing regulatory efforts. Central to our framework are the principles of privacy, accountability, and credibility. In our methodology, the foundation of reliability of information and information sources is built upon the ability to uphold accountability, enhance security, and protect privacy. This approach supports, filters, and potentially guides communication, thereby empowering individuals and communities to make well-informed decisions based on cutting-edge advancements in AI. Our framework uses the concept of Boards as proxies to collectively ensure that AI-assisted decisions are reliable, accountable, and in alignment with societal values and legal standards. Through a detailed exploration of our framework, including its main components, operations, and sample use cases, the paper shows how AI can assist in the complex process of decision-making while maintaining human oversight. The proposed framework not only extends regulatory landscapes but also highlights the synergy between AI technology and human judgement, underscoring the potential of AI to serve as a vital instrument in discerning reality from fiction and thus enhancing the decision-making process. Furthermore, we provide domain-specific use cases to highlight the applicability of our framework.
A Self-Supervised Method for Body Part Segmentation and Keypoint Detection of Rat Images
May 07, 2024



Recognition of individual components and keypoint detection supported by instance segmentation is crucial to analyze the behavior of agents on the scene. Such systems could be used for surveillance, self-driving cars, and also for medical research, where behavior analysis of laboratory animals is used to confirm the aftereffects of a given medicine. A method capable of solving the aforementioned tasks usually requires a large amount of high-quality hand-annotated data, which takes time and money to produce. In this paper, we propose a method that alleviates the need for manual labeling of laboratory rats. To do so, first, we generate initial annotations with a computer vision-based approach, then through extensive augmentation, we train a deep neural network on the generated data. The final system is capable of instance segmentation, keypoint detection, and body part segmentation even when the objects are heavily occluded.
Enhancing Apparent Personality Trait Analysis with Cross-Modal Embeddings
May 06, 2024



Automatic personality trait assessment is essential for high-quality human-machine interactions. Systems capable of human behavior analysis could be used for self-driving cars, medical research, and surveillance, among many others. We present a multimodal deep neural network with a Siamese extension for apparent personality trait prediction trained on short video recordings and exploiting modality invariant embeddings. Acoustic, visual, and textual information are utilized to reach high-performance solutions in this task. Due to the highly centralized target distribution of the analyzed dataset, the changes in the third digit are relevant. Our proposed method addresses the challenge of under-represented extreme values, achieves 0.0033 MAE average improvement, and shows a clear advantage over the baseline multimodal DNN without the introduced module.
* 14 pages, 4 figures
Perceived personality state estimation in dyadic and small group interaction with deep learning methods
Nov 09, 2022Dyadic and small group collaboration is an evolutionary advantageous behaviour and the need for such collaboration is a regular occurrence in day to day life. In this paper we estimate the perceived personality traits of individuals in dyadic and small groups over thin-slices of interaction on four multimodal datasets. We find that our transformer based predictive model performs similarly to human annotators tasked with predicting the perceived big-five personality traits of participants. Using this model we analyse the estimated perceived personality traits of individuals performing tasks in small groups and dyads. Permutation analysis shows that in the case of small groups undergoing collaborative tasks, the perceived personality of group members clusters, this is also observed for dyads in a collaborative problem solving task, but not in dyads under non-collaborative task settings. Additionally, we find that the group level average perceived personality traits provide a better predictor of group performance than the group level average self-reported personality traits.
Structural Extensions of Basis Pursuit: Guarantees on Adversarial Robustness
May 05, 2022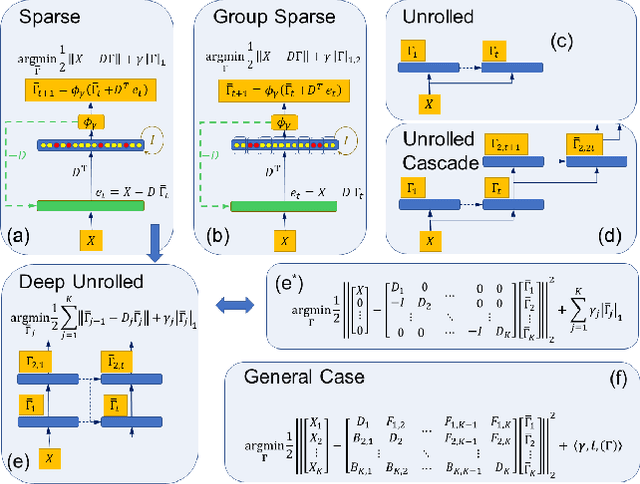
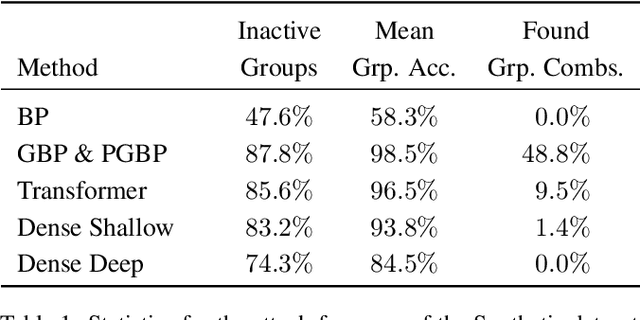
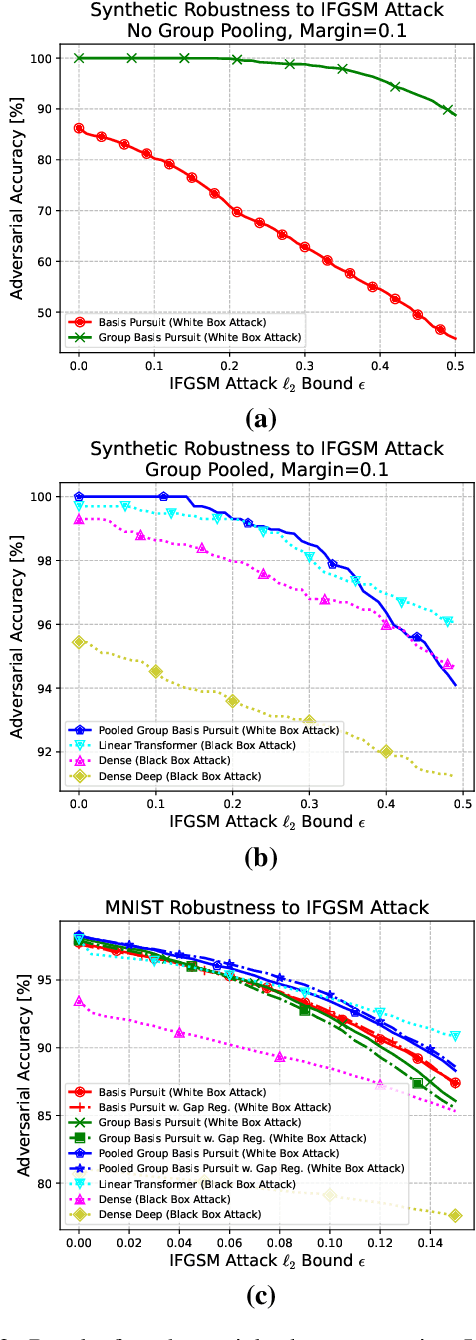
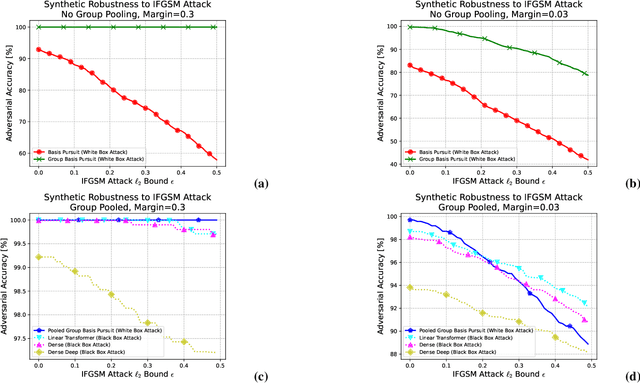
While deep neural networks are sensitive to adversarial noise, sparse coding using the Basis Pursuit (BP) method is robust against such attacks, including its multi-layer extensions. We prove that the stability theorem of BP holds upon the following generalizations: (i) the regularization procedure can be separated into disjoint groups with different weights, (ii) neurons or full layers may form groups, and (iii) the regularizer takes various generalized forms of the $\ell_1$ norm. This result provides the proof for the architectural generalizations of Cazenavette et al. (2021), including (iv) an approximation of the complete architecture as a shallow sparse coding network. Due to this approximation, we settled to experimenting with shallow networks and studied their robustness against the Iterative Fast Gradient Sign Method on a synthetic dataset and MNIST. We introduce classification based on the $\ell_2$ norms of the groups and show numerically that it can be accurate and offers considerable speedups. In this family, linear transformer shows the best performance. Based on the theoretical results and the numerical simulations, we highlight numerical matters that may improve performance further.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Mar 09, 2021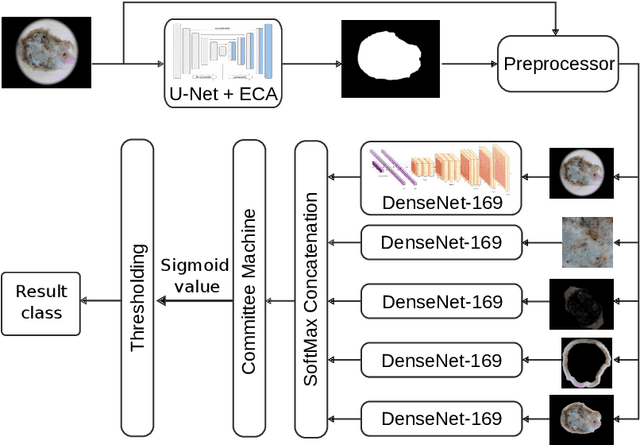
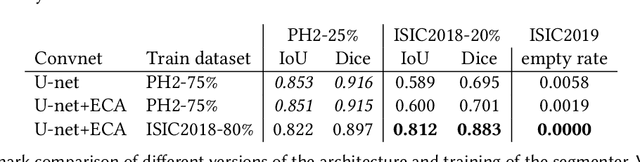
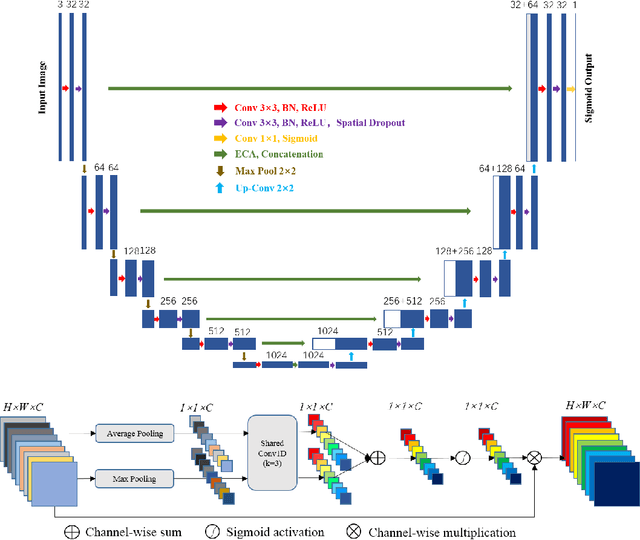
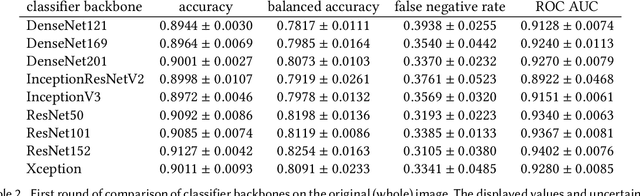
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.
Fast Interactive Video Object Segmentation with Graph Neural Networks
Mar 05, 2021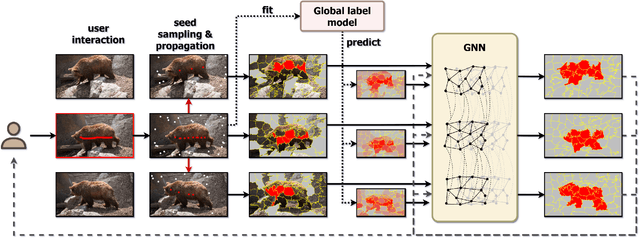


Pixelwise annotation of image sequences can be very tedious for humans. Interactive video object segmentation aims to utilize automatic methods to speed up the process and reduce the workload of the annotators. Most contemporary approaches rely on deep convolutional networks to collect and process information from human annotations throughout the video. However, such networks contain millions of parameters and need huge amounts of labeled training data to avoid overfitting. Beyond that, label propagation is usually executed as a series of frame-by-frame inference steps, which is difficult to be parallelized and is thus time consuming. In this paper we present a graph neural network based approach for tackling the problem of interactive video object segmentation. Our network operates on superpixel-graphs which allow us to reduce the dimensionality of the problem by several magnitudes. We show, that our network possessing only a few thousand parameters is able to achieve state-of-the-art performance, while inference remains fast and can be trained quickly with very little data.
Absolute Human Pose Estimation with Depth Prediction Network
Apr 11, 2019
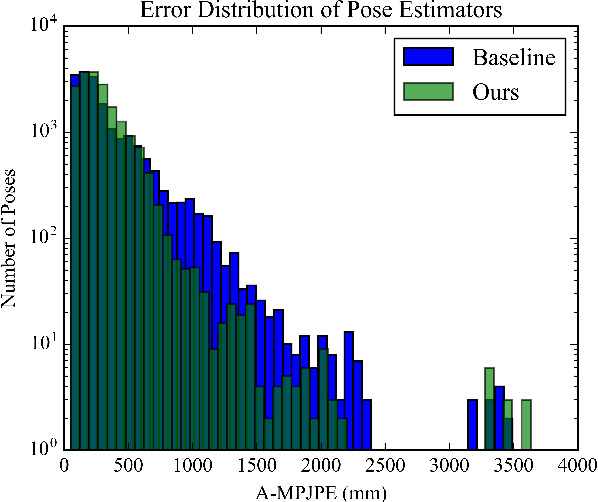
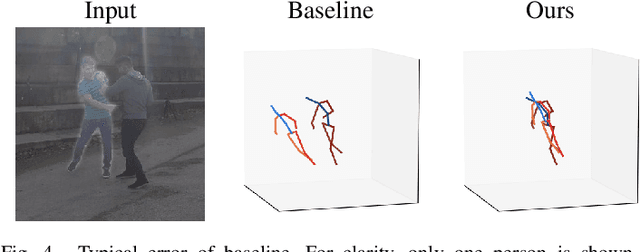
The common approach to 3D human pose estimation is predicting the body joint coordinates relative to the hip. This works well for a single person but is insufficient in the case of multiple interacting people. Methods predicting absolute coordinates first estimate a root-relative pose then calculate the translation via a secondary optimization task. We propose a neural network that predicts joints in a camera centered coordinate system instead of a root-relative one. Unlike previous methods, our network works in a single step without any post-processing. Our network beats previous methods on the MuPoTS-3D dataset and achieves state-of-the-art results.
3D Human Pose Estimation with Siamese Equivariant Embedding
Sep 19, 2018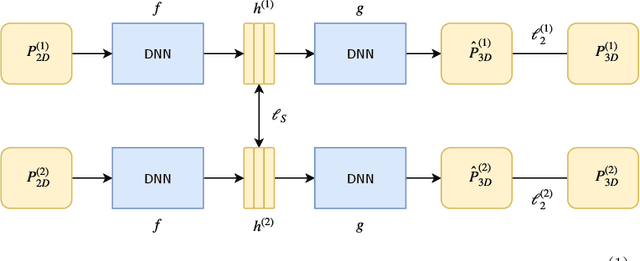
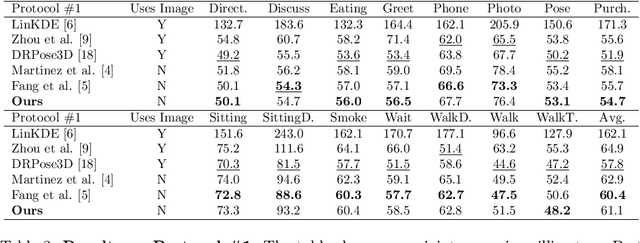
In monocular 3D human pose estimation a common setup is to first detect 2D positions and then lift the detection into 3D coordinates. Many algorithms suffer from overfitting to camera positions in the training set. We propose a siamese architecture that learns a rotation equivariant hidden representation to reduce the need for data augmentation. Our method is evaluated on multiple databases with different base networks and shows a consistent improvement of error metrics. It achieves state-of-the-art cross-camera error rate among algorithms that use estimated 2D joint coordinates only.
Fine-tuning deep CNN models on specific MS COCO categories
Sep 05, 2017
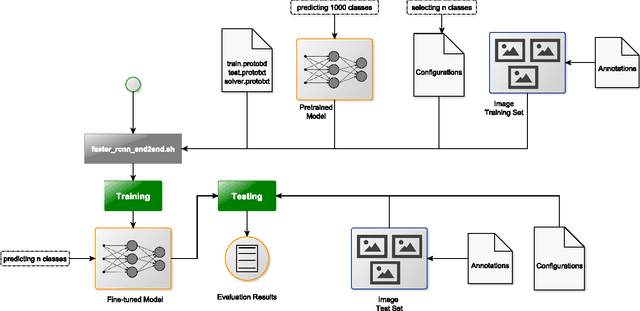

Fine-tuning of a deep convolutional neural network (CNN) is often desired. This paper provides an overview of our publicly available py-faster-rcnn-ft software library that can be used to fine-tune the VGG_CNN_M_1024 model on custom subsets of the Microsoft Common Objects in Context (MS COCO) dataset. For example, we improved the procedure so that the user does not have to look for suitable image files in the dataset by hand which can then be used in the demo program. Our implementation randomly selects images that contain at least one object of the categories on which the model is fine-tuned.