 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modulating Localization and Classification for Harmonized Object Detection
Mar 25, 2021
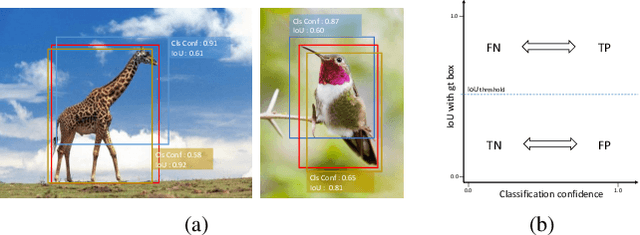

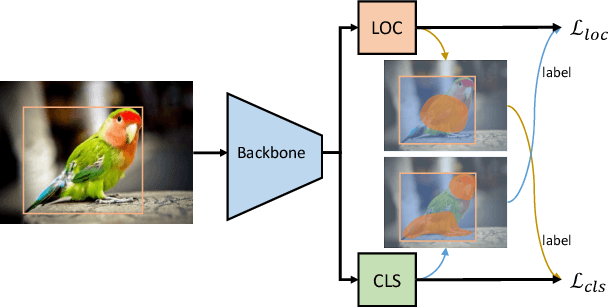
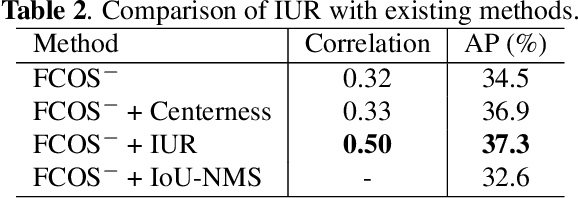
Object detection involves two sub-tasks, i.e. localizing objects in an image and classifying them into various categories. For existing CNN-based detectors, we notice the widespread divergence between localization and classification, which leads to degradation in performance. In this work, we propose a mutual learning framework to modulate the two tasks. In particular, the two tasks are forced to learn from each other with a novel mutual labeling strategy. Besides, we introduce a simple yet effective IoU rescoring scheme, which further reduces the divergence. Moreover, we define a Spearman rank correlation-based metric to quantify the divergence, which correlates well with the detection performance. The proposed approach is general-purpose and can be easily injected into existing detectors such as FCOS and RetinaNet. We achieve a significant performance gain over the baseline detectors on the COCO dataset.
MM-Rec: Multimodal News Recommendation
Apr 15, 2021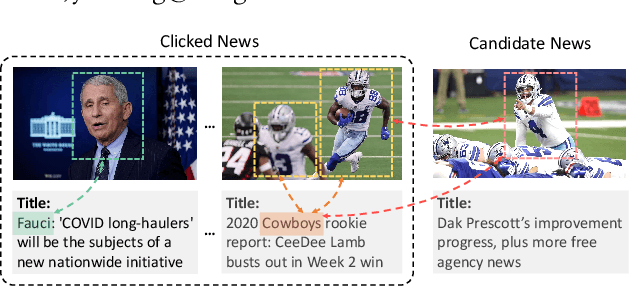

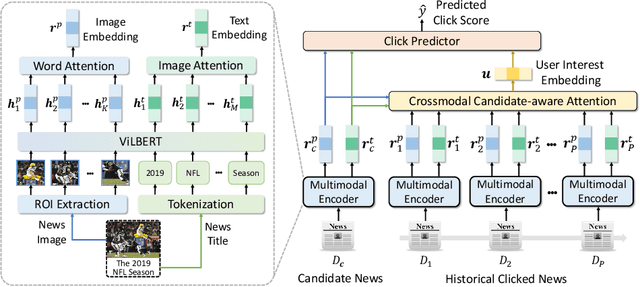
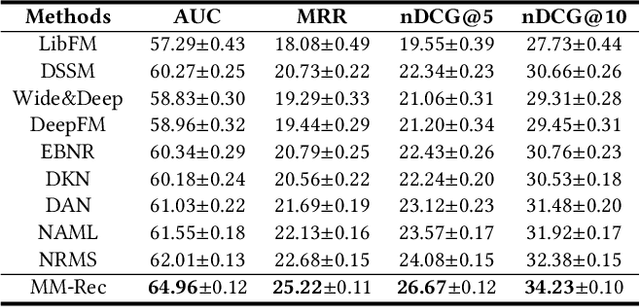
Accurate news representation is critical for news recommendation. Most of existing news representation methods learn news representations only from news texts while ignore the visual information in news like images. In fact, users may click news not only because of the interest in news titles but also due to the attraction of news images. Thus, images are useful for representing news and predicting user behaviors. In this paper, we propose a multimodal news recommendation method, which can incorporate both textual and visual information of news to learn multimodal news representations. We first extract region-of-interests (ROIs) from news images via objective detection. Then we use a pre-trained visiolinguistic model to encode both news texts and news image ROIs and model their inherent relatedness using co-attentional Transformers. In addition, we propose a crossmodal candidate-aware attention network to select relevant historical clicked news for accurate user modeling by measuring the crossmodal relatedness between clicked news and candidate news. Experiments validate that incorporating multimodal news information can effectively improve news recommendation.
SubSpectral Normalization for Neural Audio Data Processing
Mar 25, 2021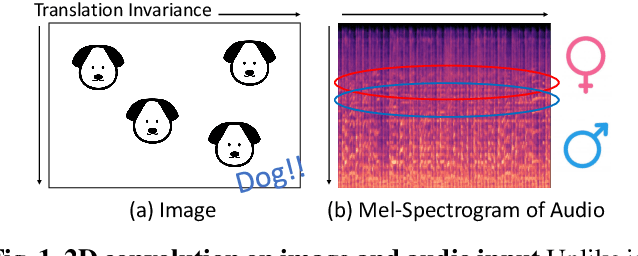

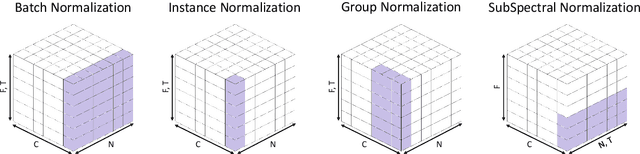
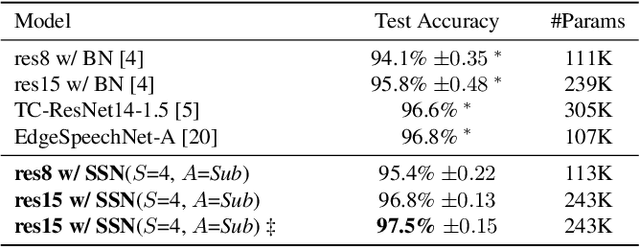
Convolutional Neural Networks are widely used in various machine learning domains. In image processing, the features can be obtained by applying 2D convolution to all spatial dimensions of the input. However, in the audio case, frequency domain input like Mel-Spectrogram has different and unique characteristics in the frequency dimension. Thus, there is a need for a method that allows the 2D convolution layer to handle the frequency dimension differently. In this work, we introduce SubSpectral Normalization (SSN), which splits the input frequency dimension into several groups (sub-bands) and performs a different normalization for each group. SSN also includes an affine transformation that can be applied to each group. Our method removes the inter-frequency deflection while the network learns a frequency-aware characteristic. In the experiments with audio data, we observed that SSN can efficiently improve the network's performance.
Deep Image-to-Video Adaptation and Fusion Networks for Action Recognition
Nov 25, 2019
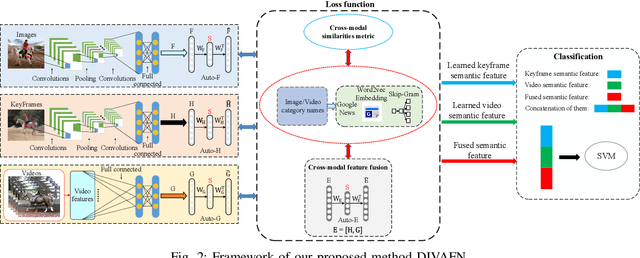


Existing deep learning methods for action recognition in videos require a large number of labeled videos for training, which is labor-intensive and time-consuming. For the same action, the knowledge learned from different media types, e.g., videos and images, may be related and complementary. However, due to the domain shifts and heterogeneous feature representations between videos and images, the performance of classifiers trained on images may be dramatically degraded when directly deployed to videos. In this paper, we propose a novel method, named Deep Image-to-Video Adaptation and Fusion Networks (DIVAFN), to enhance action recognition in videos by transferring knowledge from images using video keyframes as a bridge. The DIVAFN is a unified deep learning model, which integrates domain-invariant representations learning and cross-modal feature fusion into a unified optimization framework. Specifically, we design an efficient cross-modal similarities metric to reduce the modality shift among images, keyframes and videos. Then, we adopt an autoencoder architecture, whose hidden layer is constrained to be the semantic representations of the action class names. In this way, when the autoencoder is adopted to project the learned features from different domains to the same space, more compact, informative and discriminative representations can be obtained. Finally, the concatenation of the learned semantic feature representations from these three autoencoders are used to train the classifier for action recognition in videos. Comprehensive experiments on four real-world datasets show that our method outperforms some state-of-the-art domain adaptation and action recognition methods.
DAP: Detection-Aware Pre-training with Weak Supervision
Mar 30, 2021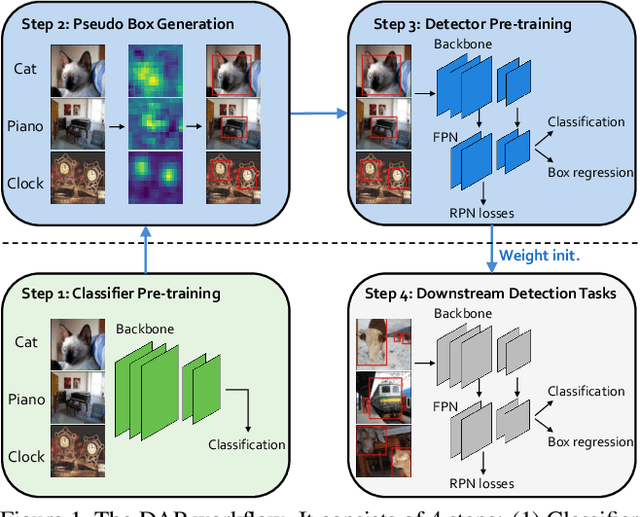
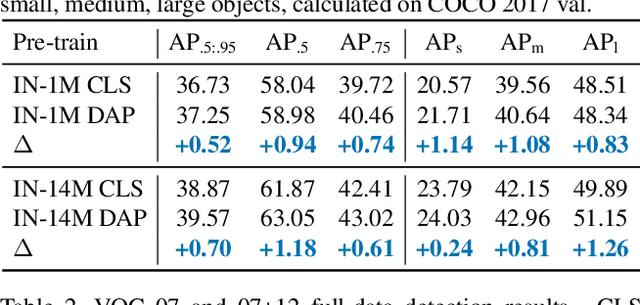
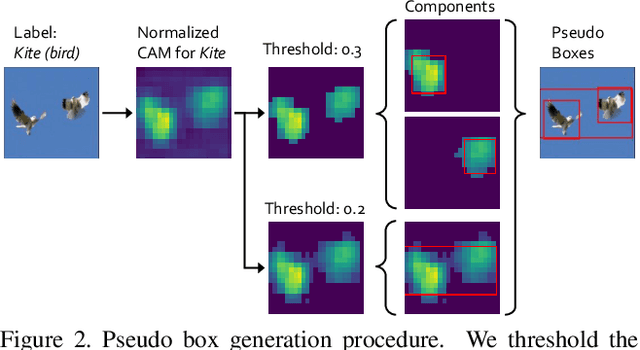
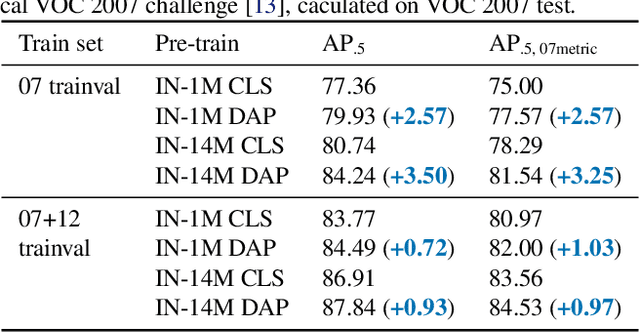
This paper presents a detection-aware pre-training (DAP) approach, which leverages only weakly-labeled classification-style datasets (e.g., ImageNet) for pre-training, but is specifically tailored to benefit object detection tasks. In contrast to the widely used image classification-based pre-training (e.g., on ImageNet), which does not include any location-related training tasks, we transform a classification dataset into a detection dataset through a weakly supervised object localization method based on Class Activation Maps to directly pre-train a detector, making the pre-trained model location-aware and capable of predicting bounding boxes. We show that DAP can outperform the traditional classification pre-training in terms of both sample efficiency and convergence speed in downstream detection tasks including VOC and COCO. In particular, DAP boosts the detection accuracy by a large margin when the number of examples in the downstream task is small.
Improving axial resolution in SIM using deep learning
Sep 04, 2020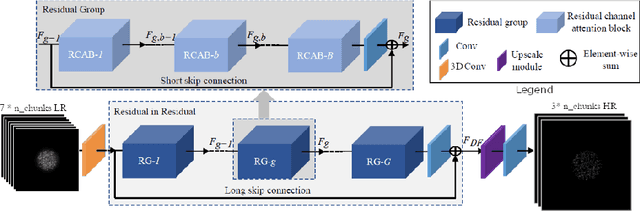

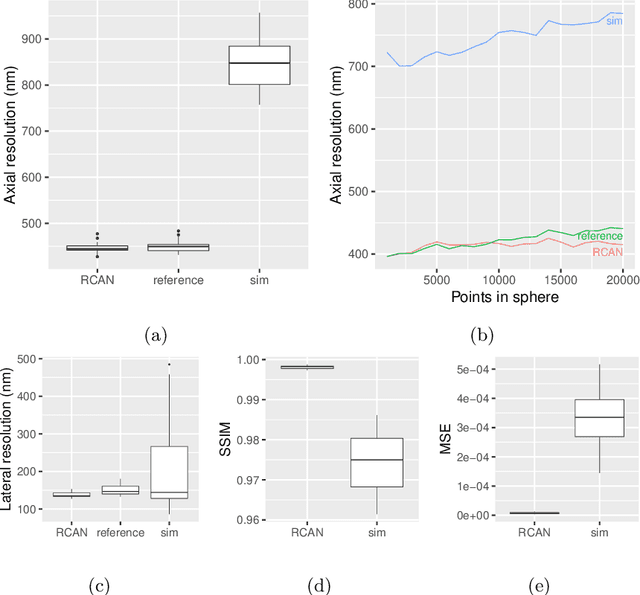
Structured Illumination Microscopy is a widespread methodology to image live and fixed biological structures smaller than the diffraction limits of conventional optical microscopy. Using recent advances in image up-scaling through deep learning models, we demonstrate a method to reconstruct 3D SIM image stacks with twice the axial resolution attainable through conventional SIM reconstructions. We further evaluate our method for robustness to noise & generalisability to varying observed specimens, and discuss potential adaptions of the method to further improvements in resolution.
Synthesizing a 4D Spatio-Angular Consistent Light Field from a Single Image
Mar 29, 2019
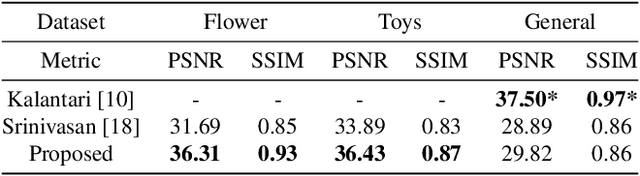
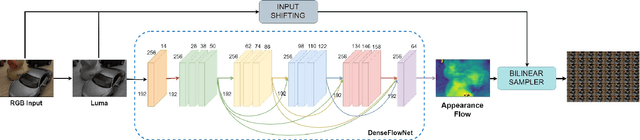
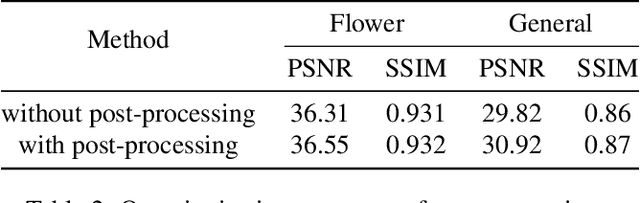
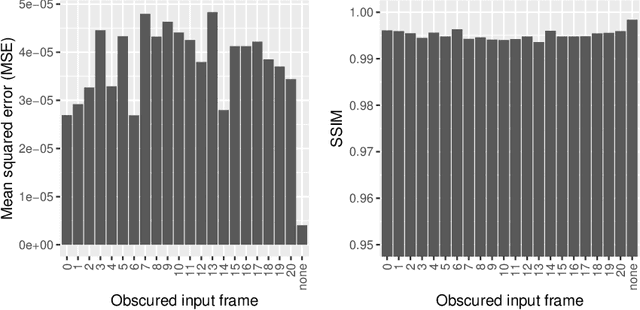
Synthesizing a densely sampled light field from a single image is highly beneficial for many applications. The conventional method reconstructs a depth map and relies on physical-based rendering and a secondary network to improve the synthesized novel views. Simple pixel-based loss also limits the network by making it rely on pixel intensity cue rather than geometric reasoning. In this study, we show that a different geometric representation, namely, appearance flow, can be used to synthesize a light field from a single image robustly and directly. A single end-to-end deep neural network that does not require a physical-based approach nor a post-processing subnetwork is proposed. Two novel loss functions based on known light field domain knowledge are presented to enable the network to preserve the spatio-angular consistency between sub-aperture images effectively. Experimental results show that the proposed model successfully synthesizes dense light fields and qualitatively and quantitatively outperforms the previous model . The method can be generalized to arbitrary scenes, rather than focusing on a particular class of object. The synthesized light field can be used for various applications, such as depth estimation and refocusing.
Scene Coordinate and Correspondence Learning for Image-Based Localization
Jul 26, 2018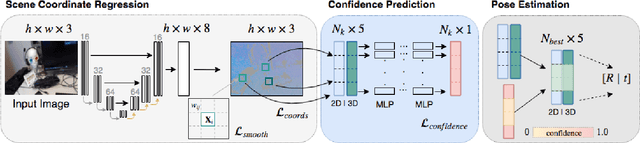
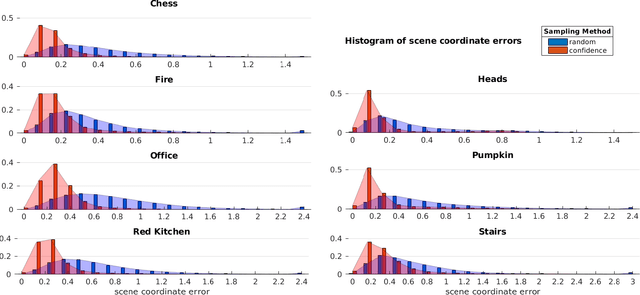

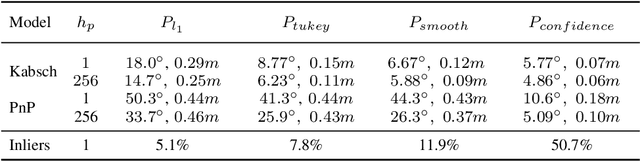
Scene coordinate regression has become an essential part of current camera re-localization methods. Different versions, such as regression forests and deep learning methods, have been successfully applied to estimate the corresponding camera pose given a single input image. In this work, we propose to regress the scene coordinates pixel-wise for a given RGB image by using deep learning. Compared to the recent methods, which usually employ RANSAC to obtain a robust pose estimate from the established point correspondences, we propose to regress confidences of these correspondences, which allows us to immediately discard erroneous predictions and improve the initial pose estimates. Finally, the resulting confidences can be used to score initial pose hypothesis and aid in pose refinement, offering a generalized solution to solve this task.
Self-supervised Pre-training with Hard Examples Improves Visual Representations
Dec 25, 2020
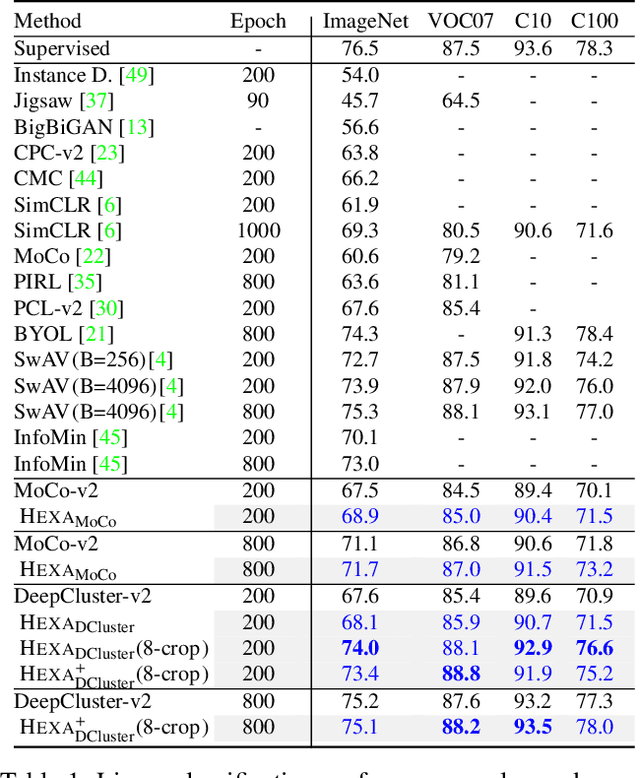
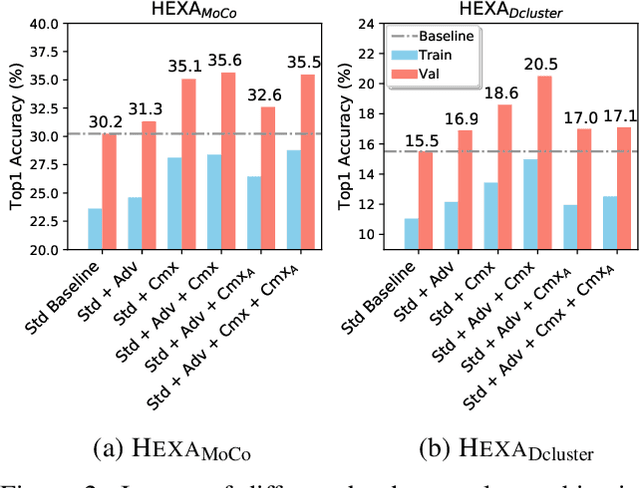
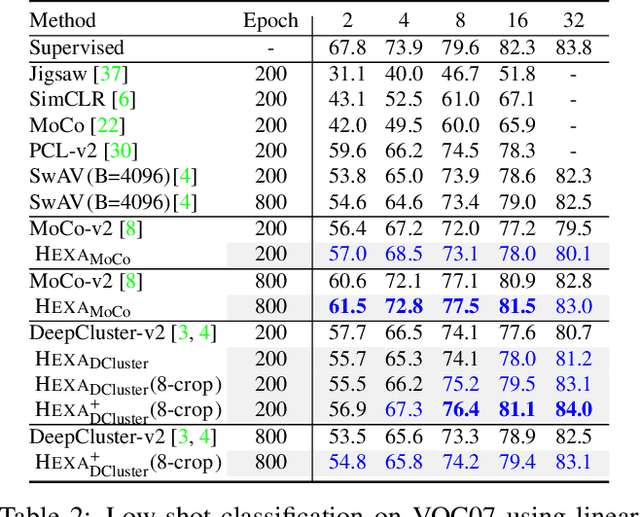
Self-supervised pre-training (SSP) employs random image transformations to generate training data for visual representation learning. In this paper, we first present a modeling framework that unifies existing SSP methods as learning to predict pseudo-labels. Then, we propose new data augmentation methods of generating training examples whose pseudo-labels are harder to predict than those generated via random image transformations. Specifically, we use adversarial training and CutMix to create hard examples (HEXA) to be used as augmented views for MoCo-v2 and DeepCluster-v2, leading to two variants HEXA_{MoCo} and HEXA_{DCluster}, respectively. In our experiments, we pre-train models on ImageNet and evaluate them on multiple public benchmarks. Our evaluation shows that the two new algorithm variants outperform their original counterparts, and achieve new state-of-the-art on a wide range of tasks where limited task supervision is available for fine-tuning. These results verify that hard examples are instrumental in improving the generalization of the pre-trained models.
A self-supervised learning strategy for postoperative brain cavity segmentation simulating resections
May 24, 2021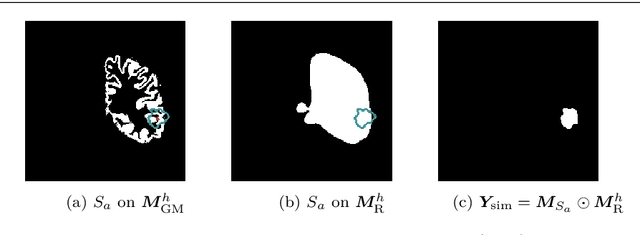
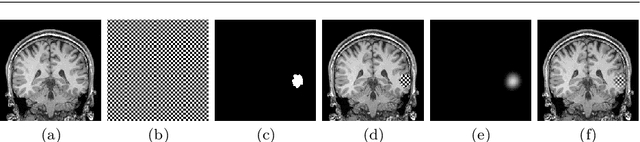
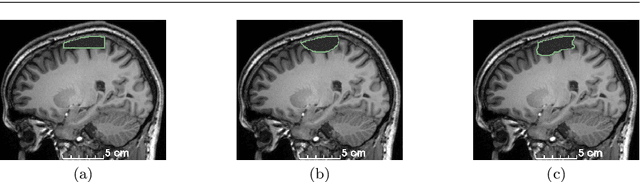
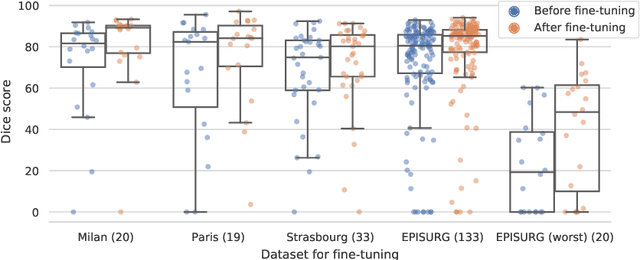
Accurate segmentation of brain resection cavities (RCs) aids in postoperative analysis and determining follow-up treatment. Convolutional neural networks (CNNs) are the state-of-the-art image segmentation technique, but require large annotated datasets for training. Annotation of 3D medical images is time-consuming, requires highly-trained raters, and may suffer from high inter-rater variability. Self-supervised learning strategies can leverage unlabeled data for training. We developed an algorithm to simulate resections from preoperative magnetic resonance images (MRIs). We performed self-supervised training of a 3D CNN for RC segmentation using our simulation method. We curated EPISURG, a dataset comprising 430 postoperative and 268 preoperative MRIs from 430 refractory epilepsy patients who underwent resective neurosurgery. We fine-tuned our model on three small annotated datasets from different institutions and on the annotated images in EPISURG, comprising 20, 33, 19 and 133 subjects. The model trained on data with simulated resections obtained median (interquartile range) Dice score coefficients (DSCs) of 81.7 (16.4), 82.4 (36.4), 74.9 (24.2) and 80.5 (18.7) for each of the four datasets. After fine-tuning, DSCs were 89.2 (13.3), 84.1 (19.8), 80.2 (20.1) and 85.2 (10.8). For comparison, inter-rater agreement between human annotators from our previous study was 84.0 (9.9). We present a self-supervised learning strategy for 3D CNNs using simulated RCs to accurately segment real RCs on postoperative MRI. Our method generalizes well to data from different institutions, pathologies and modalities. Source code, segmentation models and the EPISURG dataset are available at https://github.com/fepegar/ressegijcars .