 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Rec: Multimodal News Recommendation
Paper and Code
Apr 15, 2021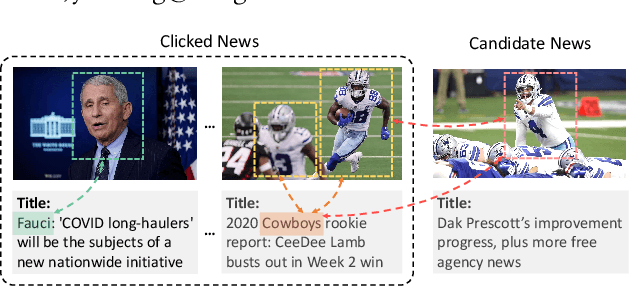

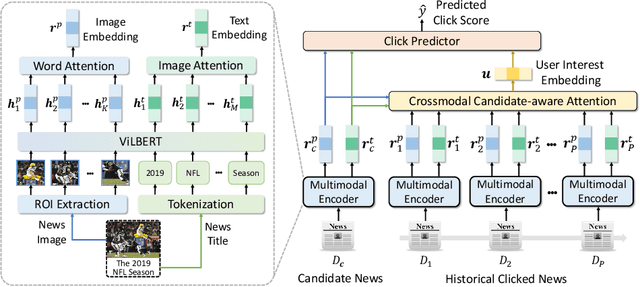
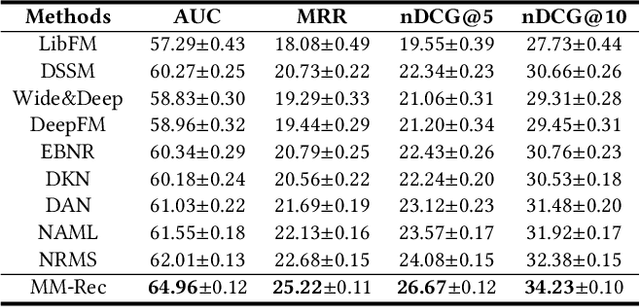
Accurate news representation is critical for news recommendation. Most of existing news representation methods learn news representations only from news texts while ignore the visual information in news like images. In fact, users may click news not only because of the interest in news titles but also due to the attraction of news images. Thus, images are useful for representing news and predicting user behaviors. In this paper, we propose a multimodal news recommendation method, which can incorporate both textual and visual information of news to learn multimodal news representations. We first extract region-of-interests (ROIs) from news images via objective detection. Then we use a pre-trained visiolinguistic model to encode both news texts and news image ROIs and model their inherent relatedness using co-attentional Transformers. In addition, we propose a crossmodal candidate-aware attention network to select relevant historical clicked news for accurate user modeling by measuring the crossmodal relatedness between clicked news and candidate news. Experiments validate that incorporating multimodal news information can effectively improve news recommendation.