 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Review of Uncertainty Quantification in Deep Learning: Techniques, Applications and Challenges
Nov 16, 2020
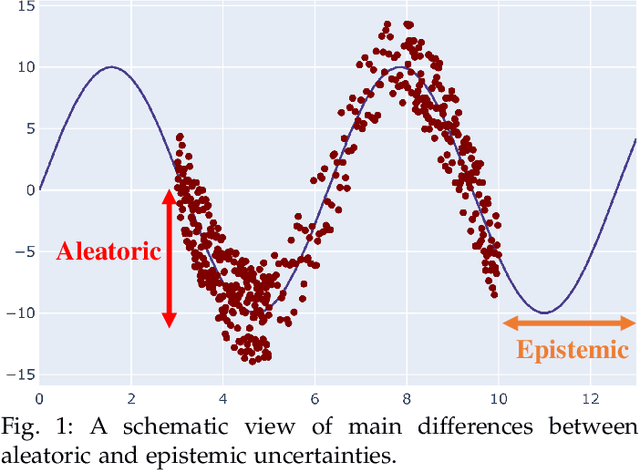
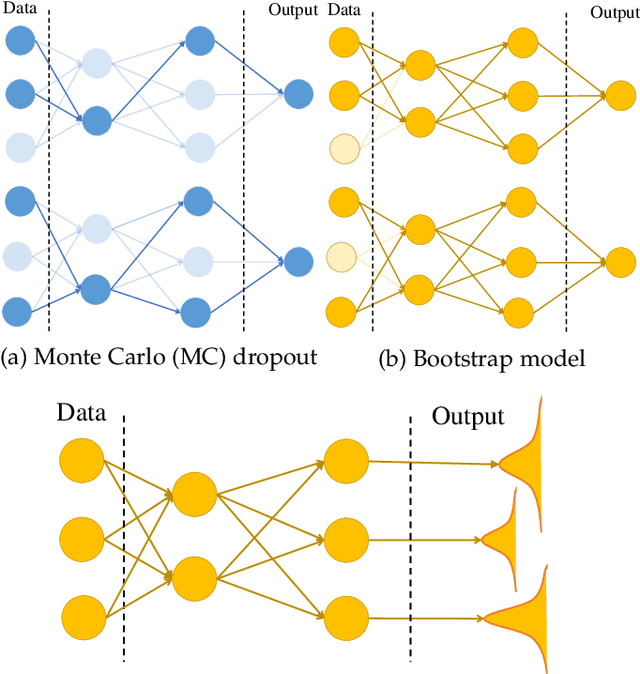
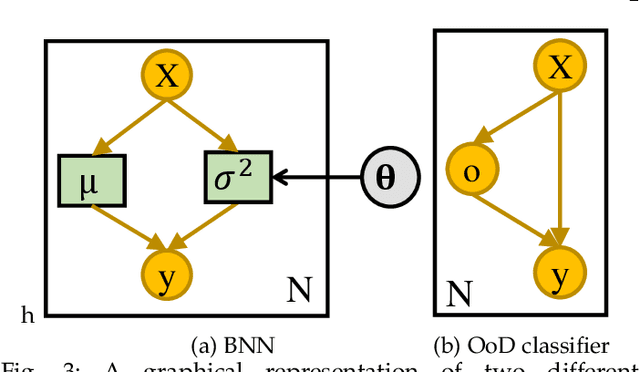
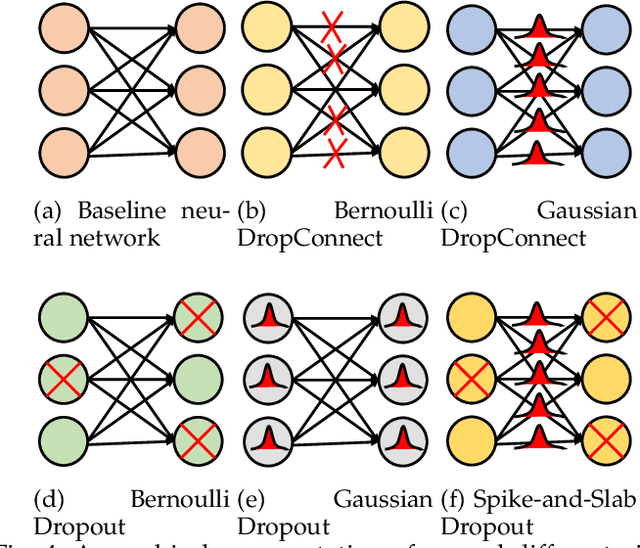
Uncertainty quantification (UQ) plays a pivotal role in reduction of uncertainties during both optimization and decision making processes. It can be applied to solve a variety of real-world applications in science and engineering. Bayesian approximation and ensemble learning techniques are two most widely-used UQ methods in the literature. In this regard, researchers have proposed different UQ methods and examined their performance in a variety of applications such as computer vision (e.g., self-driving cars and object detection), image processing (e.g., image restoration), medical image analysis (e.g., medical image classification and segmentation), natural language processing (e.g., text classification, social media texts and recidivism risk-scoring), bioinformatics, etc. This study reviews recent advances in UQ methods used in deep learning. Moreover, we also investigate the application of these methods in reinforcement learning (RL). Then, we outline a few important applications of UQ methods. Finally, we briefly highlight the fundamental research challenges faced by UQ methods and discuss the future research directions in this field.
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
Jun 05, 2021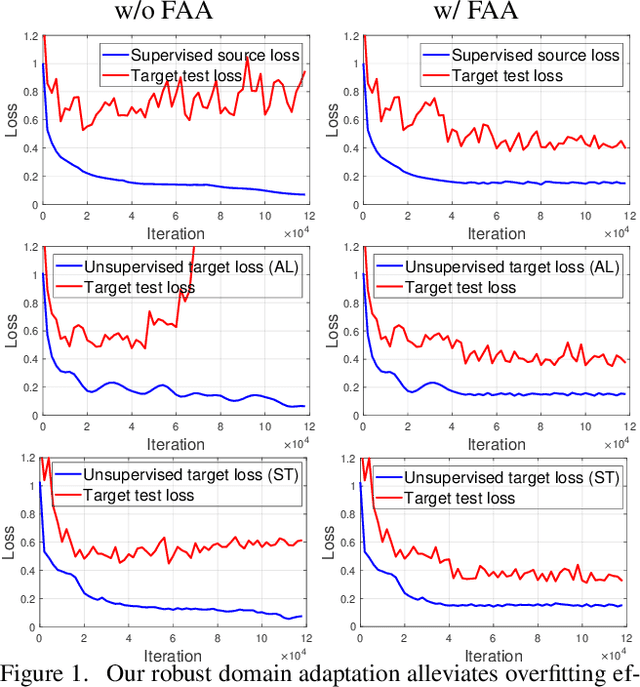
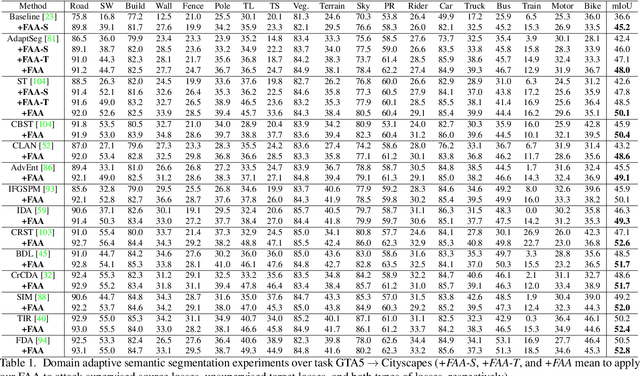
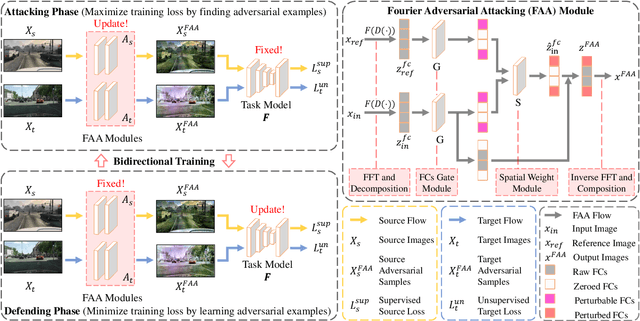
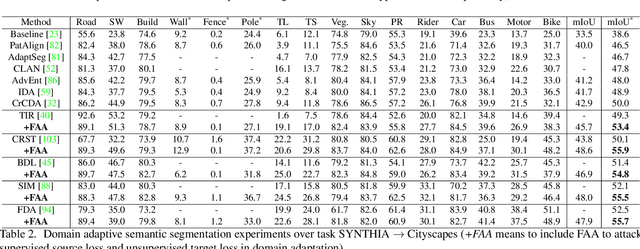
Unsupervised domain adaptation (UDA) involves a supervised loss in a labeled source domain and an unsupervised loss in an unlabeled target domain, which often faces more severe overfitting (than classical supervised learning) as the supervised source loss has clear domain gap and the unsupervised target loss is often noisy due to the lack of annotations. This paper presents RDA, a robust domain adaptation technique that introduces adversarial attacking to mitigate overfitting in UDA. We achieve robust domain adaptation by a novel Fourier adversarial attacking (FAA) method that allows large magnitude of perturbation noises but has minimal modification of image semantics, the former is critical to the effectiveness of its generated adversarial samples due to the existence of 'domain gaps'. Specifically, FAA decomposes images into multiple frequency components (FCs) and generates adversarial samples by just perturbating certain FCs that capture little semantic information. With FAA-generated samples, the training can continue the 'random walk' and drift into an area with a flat loss landscape, leading to more robust domain adaptation. Extensive experiments over multiple domain adaptation tasks show that RDA can work with different computer vision tasks with superior performance.
Mutual Contrastive Learning for Visual Representation Learning
Apr 26, 2021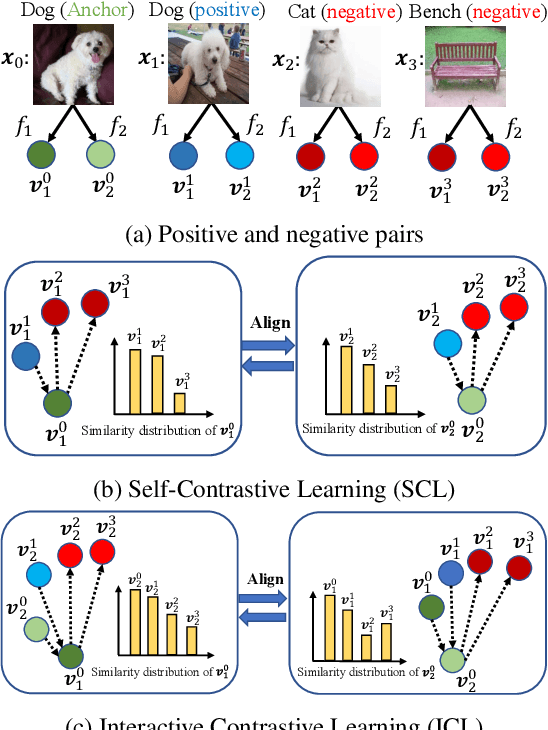
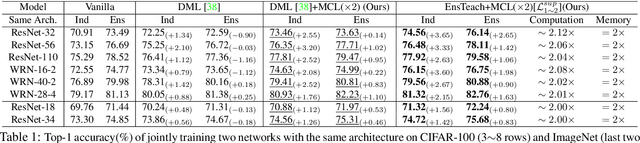
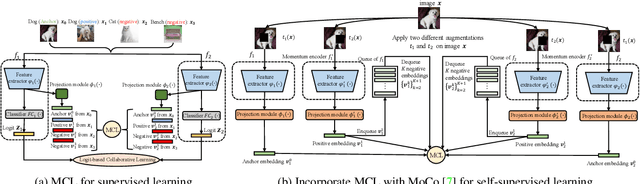
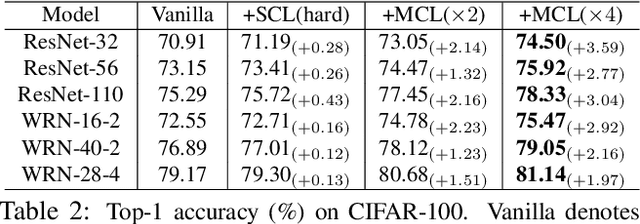
We present a collaborative learning method called Mutual Contrastive Learning (MCL) for general visual representation learning. The core idea of MCL is to perform mutual interaction and transfer of contrastive distributions among a cohort of models. Benefiting from MCL, each model can learn extra contrastive knowledge from others, leading to more meaningful feature representations for visual recognition tasks. We emphasize that MCL is conceptually simple yet empirically powerful. It is a generic framework that can be applied to both supervised and self-supervised representation learning. Experimental results on supervised and self-supervised image classification, transfer learning and few-shot learning show that MCL can lead to consistent performance gains, demonstrating that MCL can guide the network to generate better feature representations.
Visual Navigation with Spatial Attention
Apr 20, 2021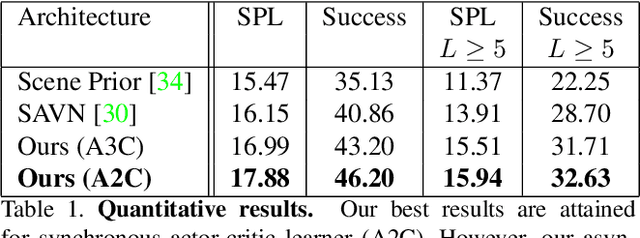
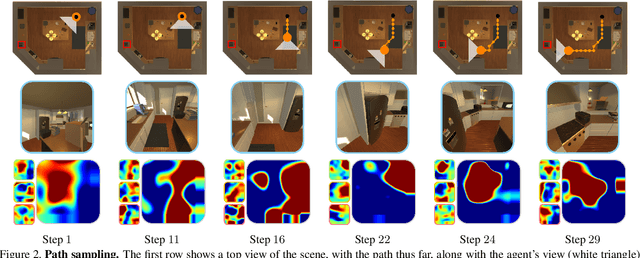
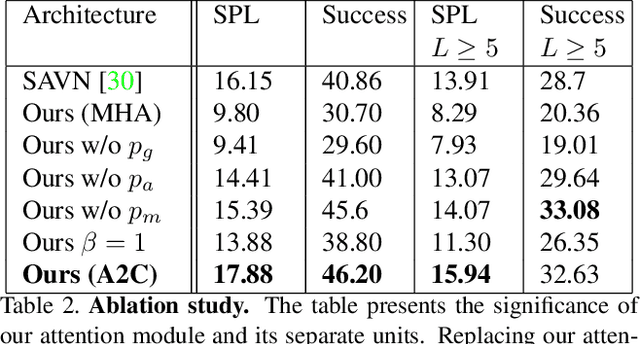
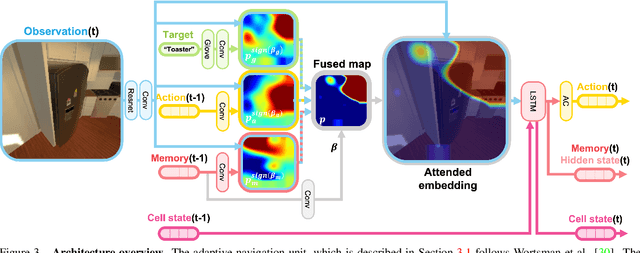
This work focuses on object goal visual navigation, aiming at finding the location of an object from a given class, where in each step the agent is provided with an egocentric RGB image of the scene. We propose to learn the agent's policy using a reinforcement learning algorithm. Our key contribution is a novel attention probability model for visual navigation tasks. This attention encodes semantic information about observed objects, as well as spatial information about their place. This combination of the "what" and the "where" allows the agent to navigate toward the sought-after object effectively. The attention model is shown to improve the agent's policy and to achieve state-of-the-art results on commonly-used datasets.
Searching for Efficient Multi-Scale Architectures for Dense Image Prediction
Sep 11, 2018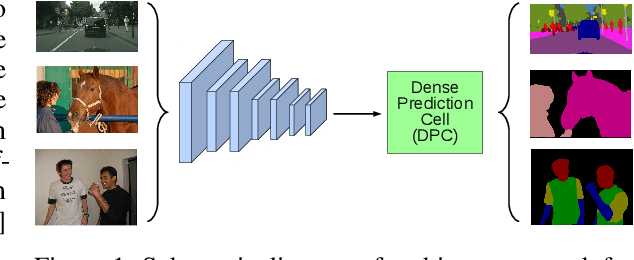
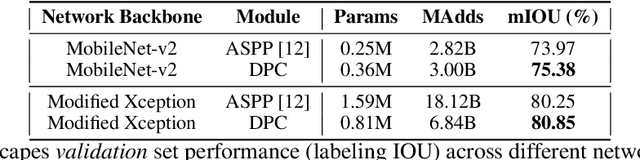
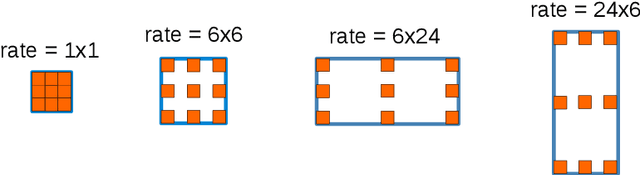
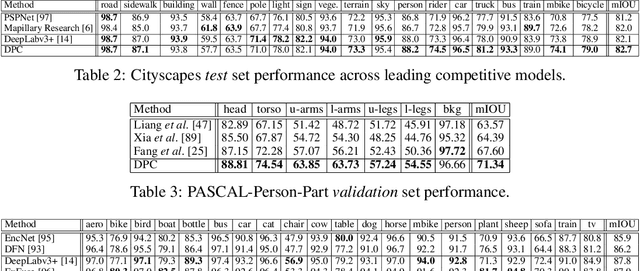
The design of neural network architectures is an important component for achieving state-of-the-art performance with machine learning systems across a broad array of tasks. Much work has endeavored to design and build architectures automatically through clever construction of a search space paired with simple learning algorithms. Recent progress has demonstrated that such meta-learning methods may exceed scalable human-invented architectures on image classification tasks. An open question is the degree to which such methods may generalize to new domains. In this work we explore the construction of meta-learning techniques for dense image prediction focused on the tasks of scene parsing, person-part segmentation, and semantic image segmentation. Constructing viable search spaces in this domain is challenging because of the multi-scale representation of visual information and the necessity to operate on high resolution imagery. Based on a survey of techniques in dense image prediction, we construct a recursive search space and demonstrate that even with efficient random search, we can identify architectures that outperform human-invented architectures and achieve state-of-the-art performance on three dense prediction tasks including 82.7\% on Cityscapes (street scene parsing), 71.3\% on PASCAL-Person-Part (person-part segmentation), and 87.9\% on PASCAL VOC 2012 (semantic image segmentation). Additionally, the resulting architecture is more computationally efficient, requiring half the parameters and half the computational cost as previous state of the art systems.
NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction
Jun 20, 2021
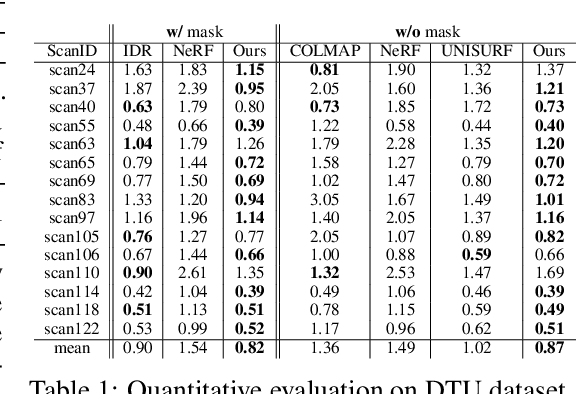
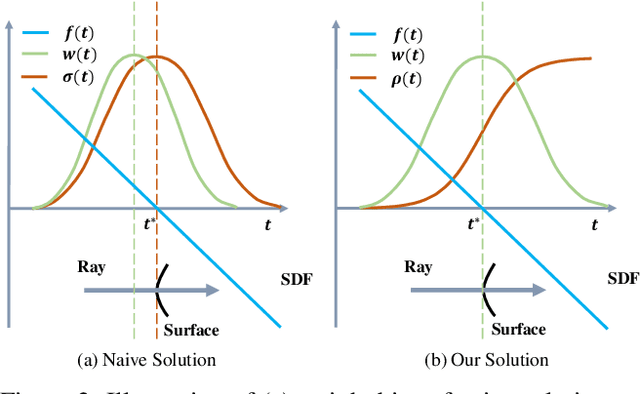
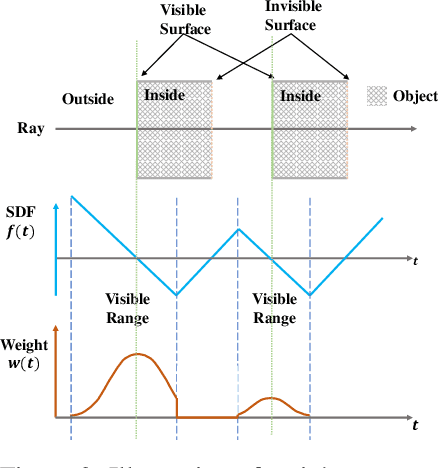
We present a novel neural surface reconstruction method, called NeuS, for reconstructing objects and scenes with high fidelity from 2D image inputs. Existing neural surface reconstruction approaches, such as DVR and IDR, require foreground mask as supervision, easily get trapped in local minima, and therefore struggle with the reconstruction of objects with severe self-occlusion or thin structures. Meanwhile, recent neural methods for novel view synthesis, such as NeRF and its variants, use volume rendering to produce a neural scene representation with robustness of optimization, even for highly complex objects. However, extracting high-quality surfaces from this learned implicit representation is difficult because there are not sufficient surface constraints in the representation. In NeuS, we propose to represent a surface as the zero-level set of a signed distance function (SDF) and develop a new volume rendering method to train a neural SDF representation. We observe that the conventional volume rendering method causes inherent geometric errors (i.e. bias) for surface reconstruction, and therefore propose a new formulation that is free of bias in the first order of approximation, thus leading to more accurate surface reconstruction even without the mask supervision. Experiments on the DTU dataset and the BlendedMVS dataset show that NeuS outperforms the state-of-the-arts in high-quality surface reconstruction, especially for objects and scenes with complex structures and self-occlusion.
Image Aesthetics Assessment Using Composite Features from off-the-Shelf Deep Models
Feb 22, 2019
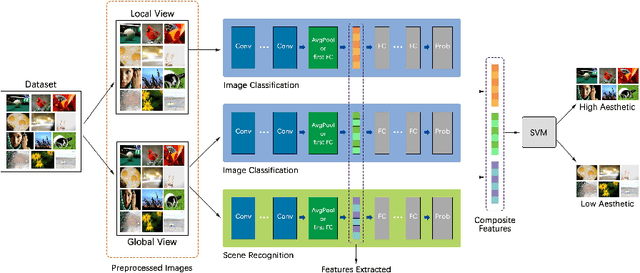
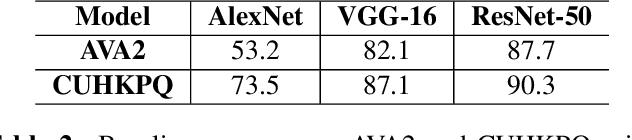
Deep convolutional neural networks have recently achieved great success on image aesthetics assessment task. In this paper, we propose an efficient method which takes the global, local and scene-aware information of images into consideration and exploits the composite features extracted from corresponding pretrained deep learning models to classify the derived features with support vector machine. Contrary to popular methods that require fine-tuning or training a new model from scratch, our training-free method directly takes the deep features generated by off-the-shelf models for image classification and scene recognition. Also, we analyzed the factors that could influence the performance from two aspects: the architecture of the deep neural network and the contribution of local and scene-aware information. It turns out that deep residual network could produce more aesthetics-aware image representation and composite features lead to the improvement of overall performance. Experiments on common large-scale aesthetics assessment benchmarks demonstrate that our method outperforms the state-of-the-art results in photo aesthetics assessment.
Hamiltonian Deep Neural Networks Guaranteeing Non-vanishing Gradients by Design
May 27, 2021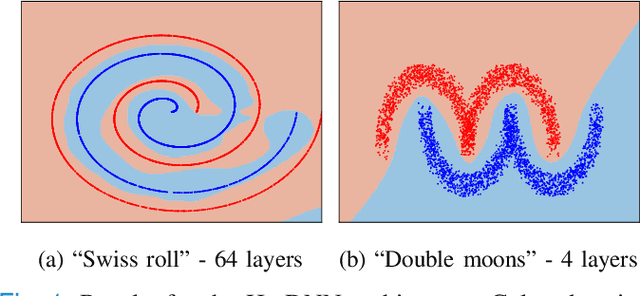
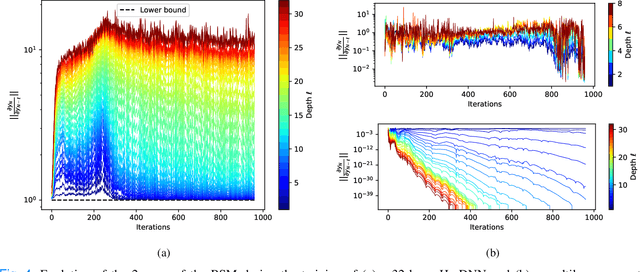
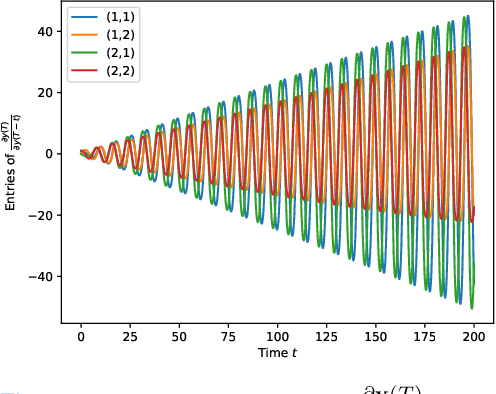
Deep Neural Networks (DNNs) training can be difficult due to vanishing and exploding gradients during weight optimization through backpropagation. To address this problem, we propose a general class of Hamiltonian DNNs (H-DNNs) that stem from the discretization of continuous-time Hamiltonian systems and include several existing architectures based on ordinary differential equations. Our main result is that a broad set of H-DNNs ensures non-vanishing gradients by design for an arbitrary network depth. This is obtained by proving that, using a semi-implicit Euler discretization scheme, the backward sensitivity matrices involved in gradient computations are symplectic. We also provide an upper bound to the magnitude of sensitivity matrices, and show that exploding gradients can be either controlled through regularization or avoided for special architectures. Finally, we enable distributed implementations of backward and forward propagation algorithms in H-DNNs by characterizing appropriate sparsity constraints on the weight matrices. The good performance of H-DNNs is demonstrated on benchmark classification problems, including image classification with the MNIST dataset.
Points2Polygons: Context-Based Segmentation from Weak Labels Using Adversarial Networks
Jun 05, 2021
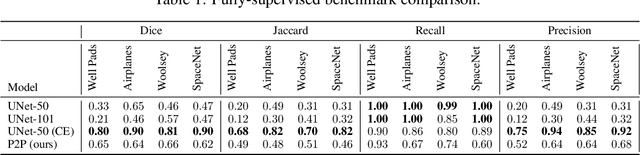
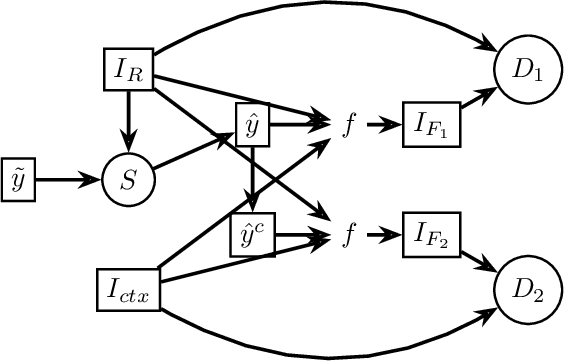
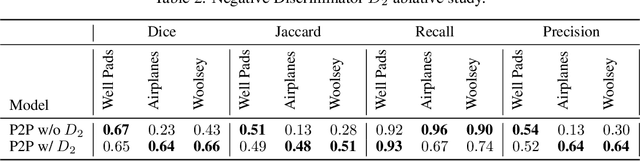
In applied image segmentation tasks, the ability to provide numerous and precise labels for training is paramount to the accuracy of the model at inference time. However, this overhead is often neglected, and recently proposed segmentation architectures rely heavily on the availability and fidelity of ground truth labels to achieve state-of-the-art accuracies. Failure to acknowledge the difficulty in creating adequate ground truths can lead to an over-reliance on pre-trained models or a lack of adoption in real-world applications. We introduce Points2Polygons (P2P), a model which makes use of contextual metric learning techniques that directly addresses this problem. Points2Polygons performs well against existing fully-supervised segmentation baselines with limited training data, despite using lightweight segmentation models (U-Net with a ResNet18 backbone) and having access to only weak labels in the form of object centroids and no pre-training. We demonstrate this on several different small but non-trivial datasets. We show that metric learning using contextual data provides key insights for self-supervised tasks in general, and allow segmentation models to easily generalize across traditionally label-intensive domains in computer vision.
Towards High Fidelity Monocular Face Reconstruction with Rich Reflectance using Self-supervised Learning and Ray Tracing
Mar 29, 2021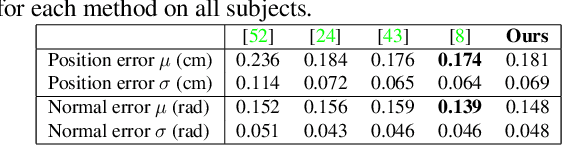
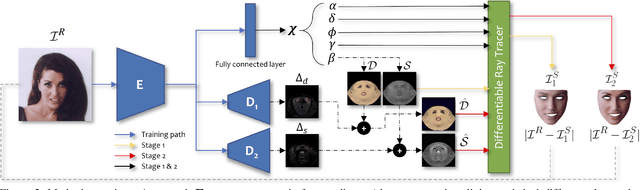
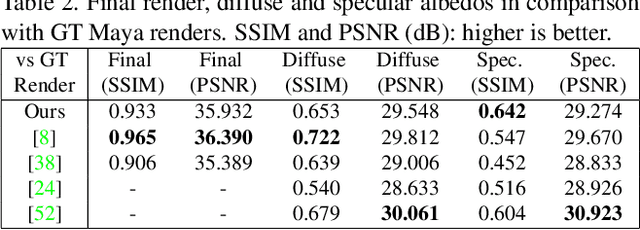
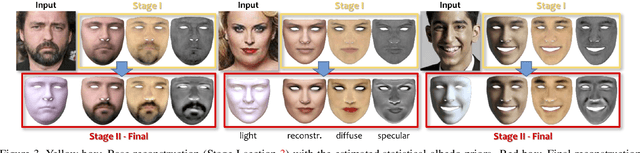
Robust face reconstruction from monocular image in general lighting conditions is challenging. Methods combining deep neural network encoders with differentiable rendering have opened up the path for very fast monocular reconstruction of geometry, lighting and reflectance. They can also be trained in self-supervised manner for increased robustness and better generalization. However, their differentiable rasterization based image formation models, as well as underlying scene parameterization, limit them to Lambertian face reflectance and to poor shape details. More recently, ray tracing was introduced for monocular face reconstruction within a classic optimization-based framework and enables state-of-the art results. However optimization-based approaches are inherently slow and lack robustness. In this paper, we build our work on the aforementioned approaches and propose a new method that greatly improves reconstruction quality and robustness in general scenes. We achieve this by combining a CNN encoder with a differentiable ray tracer, which enables us to base the reconstruction on much more advanced personalized diffuse and specular albedos, a more sophisticated illumination model and a plausible representation of self-shadows. This enables to take a big leap forward in reconstruction quality of shape, appearance and lighting even in scenes with difficult illumination. With consistent face attributes reconstruction, our method leads to practical applications such as relighting and self-shadows removal. Compared to state-of-the-art methods, our results show improved accuracy and validity of the approach.