 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reproducible Learning-based Compression
Oct 13, 2024



A deep learning system typically suffers from a lack of reproducibility that is partially rooted in hardware or software implementation details. The irreproducibility leads to skepticism in deep learning technologies and it can hinder them from being deployed in many applications. In this work, the irreproducibility issue is analyzed where deep learning is employed in compression systems while the encoding and decoding may be run on devices from different manufacturers. The decoding process can even crash due to a single bit difference, e.g., in a learning-based entropy coder. For a given deep learning-based module with limited resources for protection, we first suggest that reproducibility can only be assured when the mismatches are bounded. Then a safeguarding mechanism is proposed to tackle the challenges. The proposed method may be applied for different levels of protection either at the reconstruction level or at a selected decoding level. Furthermore, the overhead introduced for the protection can be scaled down accordingly when the error bound is being suppressed. Experiments demonstrate the effectiveness of the proposed approach for learning-based compression systems, e.g., in image compression and point cloud compression.
WrappingNet: Mesh Autoencoder via Deep Sphere Deformation
Aug 29, 2023



There have been recent efforts to learn more meaningful representations via fixed length codewords from mesh data, since a mesh serves as a complete model of underlying 3D shape compared to a point cloud. However, the mesh connectivity presents new difficulties when constructing a deep learning pipeline for meshes. Previous mesh unsupervised learning approaches typically assume category-specific templates, e.g., human face/body templates. It restricts the learned latent codes to only be meaningful for objects in a specific category, so the learned latent spaces are unable to be used across different types of objects. In this work, we present WrappingNet, the first mesh autoencoder enabling general mesh unsupervised learning over heterogeneous objects. It introduces a novel base graph in the bottleneck dedicated to representing mesh connectivity, which is shown to facilitate learning a shared latent space representing object shape. The superiority of WrappingNet mesh learning is further demonstrated via improved reconstruction quality and competitive classification compared to point cloud learning, as well as latent interpolation between meshes of different categories.
S2F2: Self-Supervised High Fidelity Face Reconstruction from Monocular Image
Apr 05, 2022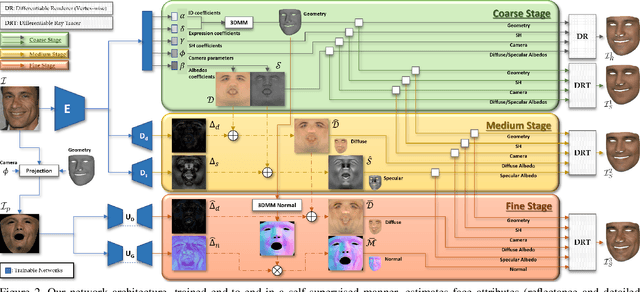


We present a novel face reconstruction method capable of reconstructing detailed face geometry, spatially varying face reflectance from a single monocular image. We build our work upon the recent advances of DNN-based auto-encoders with differentiable ray tracing image formation, trained in self-supervised manner. While providing the advantage of learning-based approaches and real-time reconstruction, the latter methods lacked fidelity. In this work, we achieve, for the first time, high fidelity face reconstruction using self-supervised learning only. Our novel coarse-to-fine deep architecture allows us to solve the challenging problem of decoupling face reflectance from geometry using a single image, at high computational speed. Compared to state-of-the-art methods, our method achieves more visually appealing reconstruction.
$\textit{FacialFilmroll}$: High-resolution multi-shot video editing
Oct 05, 2021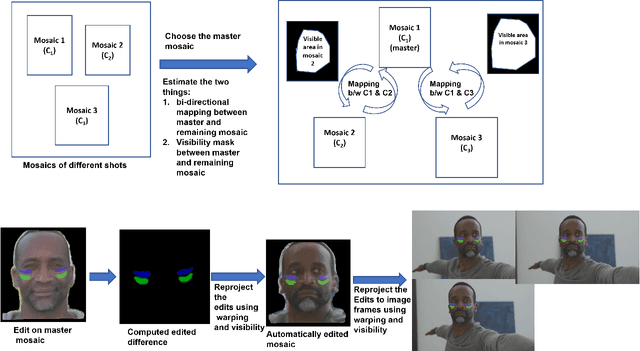
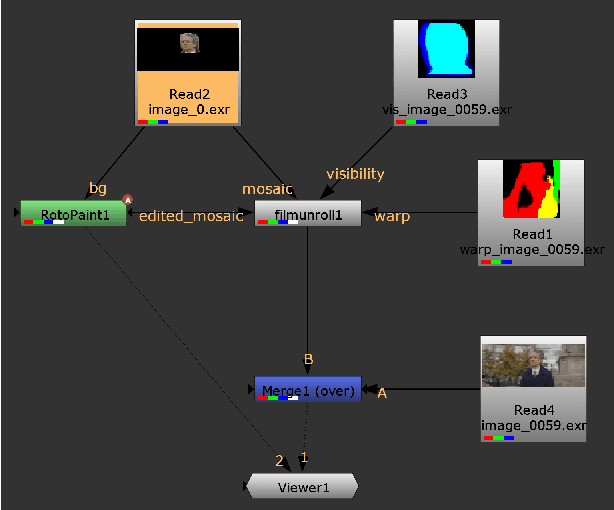


We present $\textit{FacialFilmroll}$, a solution for spatially and temporally consistent editing of faces in one or multiple shots. We build upon unwrap mosaic [Rav-Acha et al. 2008] by specializing it to faces. We leverage recent techniques to fit a 3D face model on monocular videos to (i) improve the quality of the mosaic for edition and (ii) permit the automatic transfer of edits from one shot to other shots of the same actor. We explain how $\textit{FacialFilmroll}$ is integrated in post-production facility. Finally, we present video editing results using $\textit{FacialFilmroll}$ on high resolution videos.
* European Conference on Visual Media Production (CVMP '21)
Towards High Fidelity Monocular Face Reconstruction with Rich Reflectance using Self-supervised Learning and Ray Tracing
Mar 29, 2021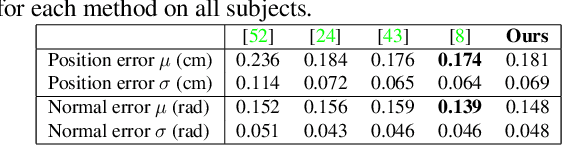
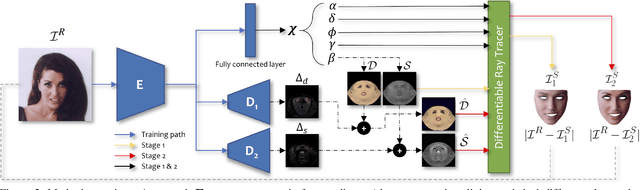
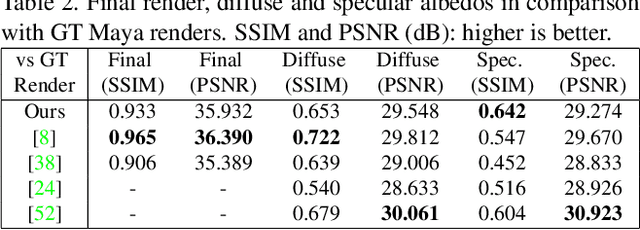
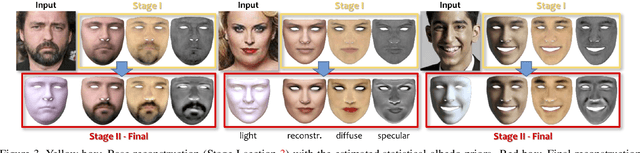
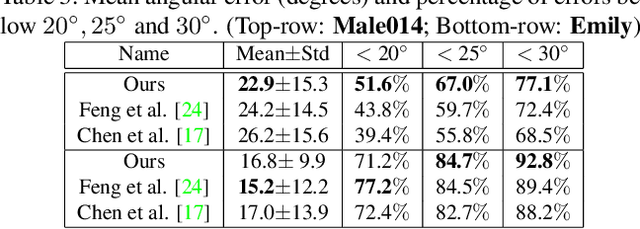
Robust face reconstruction from monocular image in general lighting conditions is challenging. Methods combining deep neural network encoders with differentiable rendering have opened up the path for very fast monocular reconstruction of geometry, lighting and reflectance. They can also be trained in self-supervised manner for increased robustness and better generalization. However, their differentiable rasterization based image formation models, as well as underlying scene parameterization, limit them to Lambertian face reflectance and to poor shape details. More recently, ray tracing was introduced for monocular face reconstruction within a classic optimization-based framework and enables state-of-the art results. However optimization-based approaches are inherently slow and lack robustness. In this paper, we build our work on the aforementioned approaches and propose a new method that greatly improves reconstruction quality and robustness in general scenes. We achieve this by combining a CNN encoder with a differentiable ray tracer, which enables us to base the reconstruction on much more advanced personalized diffuse and specular albedos, a more sophisticated illumination model and a plausible representation of self-shadows. This enables to take a big leap forward in reconstruction quality of shape, appearance and lighting even in scenes with difficult illumination. With consistent face attributes reconstruction, our method leads to practical applications such as relighting and self-shadows removal. Compared to state-of-the-art methods, our results show improved accuracy and validity of the approach.
Practical Face Reconstruction via Differentiable Ray Tracing
Jan 13, 2021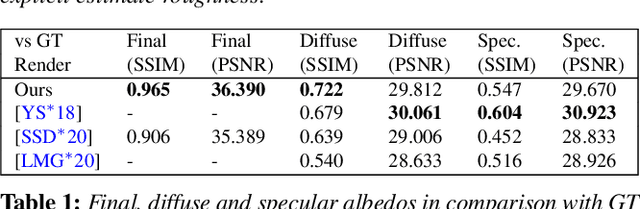
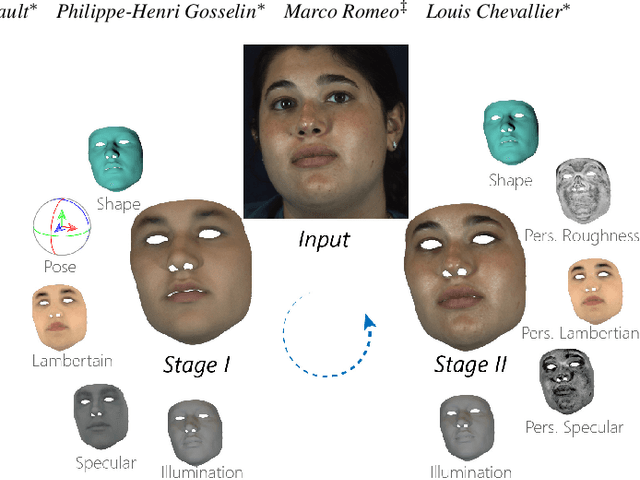
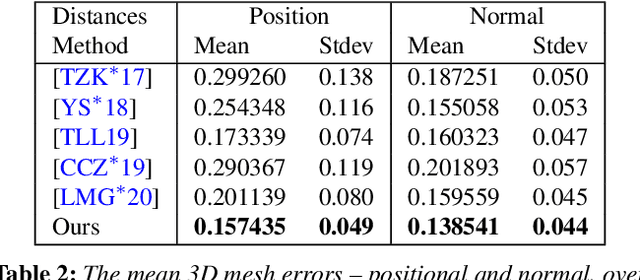
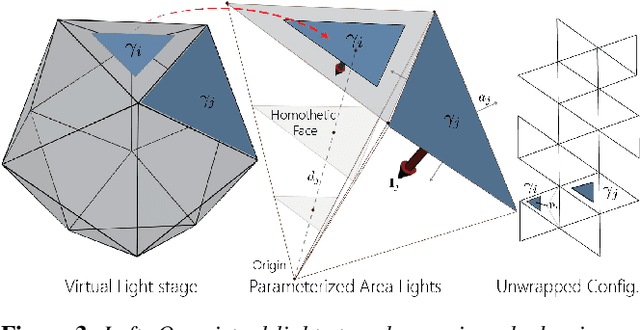
We present a differentiable ray-tracing based novel face reconstruction approach where scene attributes - 3D geometry, reflectance (diffuse, specular and roughness), pose, camera parameters, and scene illumination - are estimated from unconstrained monocular images. The proposed method models scene illumination via a novel, parameterized virtual light stage, which in-conjunction with differentiable ray-tracing, introduces a coarse-to-fine optimization formulation for face reconstruction. Our method can not only handle unconstrained illumination and self-shadows conditions, but also estimates diffuse and specular albedos. To estimate the face attributes consistently and with practical semantics, a two-stage optimization strategy systematically uses a subset of parametric attributes, where subsequent attribute estimations factor those previously estimated. For example, self-shadows estimated during the first stage, later prevent its baking into the personalized diffuse and specular albedos in the second stage. We show the efficacy of our approach in several real-world scenarios, where face attributes can be estimated even under extreme illumination conditions. Ablation studies, analyses and comparisons against several recent state-of-the-art methods show improved accuracy and versatility of our approach. With consistent face attributes reconstruction, our method leads to several style -- illumination, albedo, self-shadow -- edit and transfer applications, as discussed in the paper.
Face Reflectance and Geometry Modeling via Differentiable Ray Tracing
Oct 03, 2019
We present a novel strategy to automatically reconstruct 3D faces from monocular images with explicitly disentangled facial geometry (pose, identity and expression), reflectance (diffuse and specular albedo), and self-shadows. The scene lights are modeled as a virtual light stage with pre-oriented area lights used in conjunction with differentiable Monte-Carlo ray tracing to optimize the scene and face parameters. With correctly disentangled self-shadows and specular reflection parameters, we can not only obtain robust facial geometry reconstruction, but also gain explicit control over these parameters, with several practical applications. We can change facial expressions with accurate resultant self-shadows or relight the scene and obtain accurate specular reflection and several other parameter combinations.