 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Evaluation of Visible and Infrared Image Fusion
Oct 09, 2024



Visible and Infrared Image Fusion (VIF) has garnered significant interest across a wide range of high-level vision tasks, such as object detection and semantic segmentation. However, the evaluation of VIF methods remains challenging due to the absence of ground truth. This paper proposes a Segmentation-oriented Evaluation Approach (SEA) to assess VIF methods by incorporating the semantic segmentation task and leveraging segmentation labels available in latest VIF datasets. Specifically, SEA utilizes universal segmentation models, capable of handling diverse images and classes, to predict segmentation outputs from fused images and compare these outputs with segmentation labels. Our evaluation of recent VIF methods using SEA reveals that their performance is comparable or even inferior to using visible images only, despite nearly half of the infrared images demonstrating better performance than visible images. Further analysis indicates that the two metrics most correlated to our SEA are the gradient-based fusion metric $Q_{\text{ABF}}$ and the visual information fidelity metric $Q_{\text{VIFF}}$ in conventional VIF evaluation metrics, which can serve as proxies when segmentation labels are unavailable. We hope that our evaluation will guide the development of novel and practical VIF methods. The code has been released in \url{https://github.com/Yixuan-2002/SEA/}.
Controllable and Gradual Facial Blemishes Retouching via Physics-Based Modelling
Jun 19, 2024



Face retouching aims to remove facial blemishes, such as pigmentation and acne, and still retain fine-grain texture details. Nevertheless, existing methods just remove the blemishes but focus little on realism of the intermediate process, limiting their use more to beautifying facial images on social media rather than being effective tools for simulating changes in facial pigmentation and ance. Motivated by this limitation, we propose our Controllable and Gradual Face Retouching (CGFR). Our CGFR is based on physical modelling, adopting Sum-of-Gaussians to approximate skin subsurface scattering in a decomposed melanin and haemoglobin color space. Our CGFR offers a user-friendly control over the facial blemishes, achieving realistic and gradual blemishes retouching. Experimental results based on actual clinical data shows that CGFR can realistically simulate the blemishes' gradual recovering process.
Efficient Test-Time Adaptation of Vision-Language Models
Mar 27, 2024



Test-time adaptation with pre-trained vision-language models has attracted increasing attention for tackling distribution shifts during the test time. Though prior studies have achieved very promising performance, they involve intensive computation which is severely unaligned with test-time adaptation. We design TDA, a training-free dynamic adapter that enables effective and efficient test-time adaptation with vision-language models. TDA works with a lightweight key-value cache that maintains a dynamic queue with few-shot pseudo labels as values and the corresponding test-sample features as keys. Leveraging the key-value cache, TDA allows adapting to test data gradually via progressive pseudo label refinement which is super-efficient without incurring any backpropagation. In addition, we introduce negative pseudo labeling that alleviates the adverse impact of pseudo label noises by assigning pseudo labels to certain negative classes when the model is uncertain about its pseudo label predictions. Extensive experiments over two benchmarks demonstrate TDA's superior effectiveness and efficiency as compared with the state-of-the-art. The code has been released in \url{https://kdiaaa.github.io/tda/}.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023



Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
Noise-Tolerant Unsupervised Adapter for Vision-Language Models
Sep 26, 2023



Recent advances in large-scale vision-language models have achieved very impressive performance in various zero-shot image classification tasks. While prior studies have demonstrated significant improvements by introducing few-shot labelled target samples, they still require labelling of target samples, which greatly degrades their scalability while handling various visual recognition tasks. We design NtUA, a Noise-tolerant Unsupervised Adapter that allows learning superior target models with few-shot unlabelled target samples. NtUA works as a key-value cache that formulates visual features and predicted pseudo-labels of the few-shot unlabelled target samples as key-value pairs. It consists of two complementary designs. The first is adaptive cache formation that combats pseudo-label noises by weighting the key-value pairs according to their prediction confidence. The second is pseudo-label rectification, which corrects both pair values (i.e., pseudo-labels) and cache weights by leveraging knowledge distillation from large-scale vision language models. Extensive experiments show that NtUA achieves superior performance consistently across multiple widely adopted benchmarks.
3D Semantic Segmentation in the Wild: Learning Generalized Models for Adverse-Condition Point Clouds
Apr 03, 2023



Robust point cloud parsing under all-weather conditions is crucial to level-5 autonomy in autonomous driving. However, how to learn a universal 3D semantic segmentation (3DSS) model is largely neglected as most existing benchmarks are dominated by point clouds captured under normal weather. We introduce SemanticSTF, an adverse-weather point cloud dataset that provides dense point-level annotations and allows to study 3DSS under various adverse weather conditions. We study all-weather 3DSS modeling under two setups: 1) domain adaptive 3DSS that adapts from normal-weather data to adverse-weather data; 2) domain generalizable 3DSS that learns all-weather 3DSS models from normal-weather data. Our studies reveal the challenge while existing 3DSS methods encounter adverse-weather data, showing the great value of SemanticSTF in steering the future endeavor along this very meaningful research direction. In addition, we design a domain randomization technique that alternatively randomizes the geometry styles of point clouds and aggregates their embeddings, ultimately leading to a generalizable model that can improve 3DSS under various adverse weather effectively. The SemanticSTF and related codes are available at \url{https://github.com/xiaoaoran/SemanticSTF}.
PolarMix: A General Data Augmentation Technique for LiDAR Point Clouds
Jul 30, 2022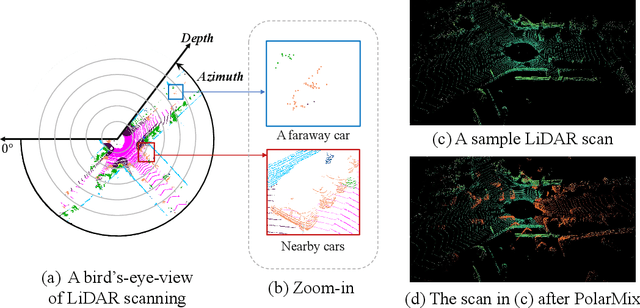
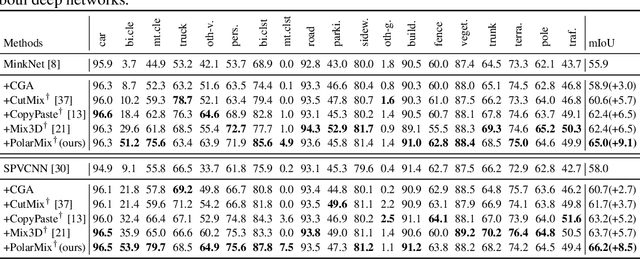
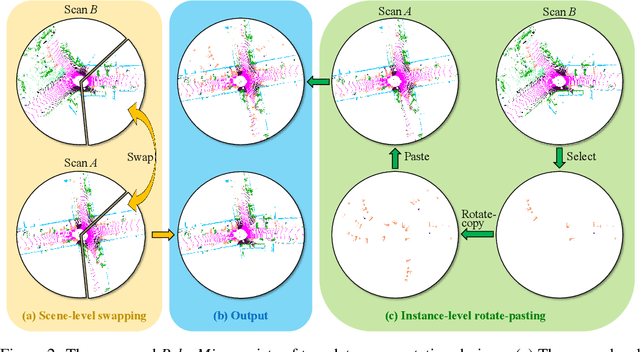
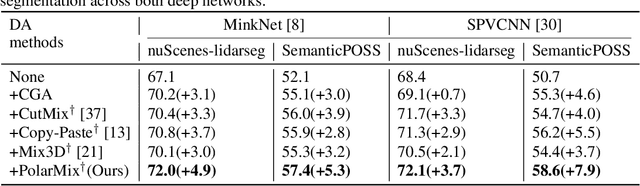
LiDAR point clouds, which are usually scanned by rotating LiDAR sensors continuously, capture precise geometry of the surrounding environment and are crucial to many autonomous detection and navigation tasks. Though many 3D deep architectures have been developed, efficient collection and annotation of large amounts of point clouds remain one major challenge in the analytic and understanding of point cloud data. This paper presents PolarMix, a point cloud augmentation technique that is simple and generic but can mitigate the data constraint effectively across different perception tasks and scenarios. PolarMix enriches point cloud distributions and preserves point cloud fidelity via two cross-scan augmentation strategies that cut, edit, and mix point clouds along the scanning direction. The first is scene-level swapping which exchanges point cloud sectors of two LiDAR scans that are cut along the azimuth axis. The second is instance-level rotation and paste which crops point instances from one LiDAR scan, rotates them by multiple angles (to create multiple copies), and paste the rotated point instances into other scans. Extensive experiments show that PolarMix achieves superior performance consistently across different perception tasks and scenarios. In addition, it can work as plug-and-play for various 3D deep architectures and also performs well for unsupervised domain adaptation.
Domain Adaptive Video Segmentation via Temporal Pseudo Supervision
Jul 06, 2022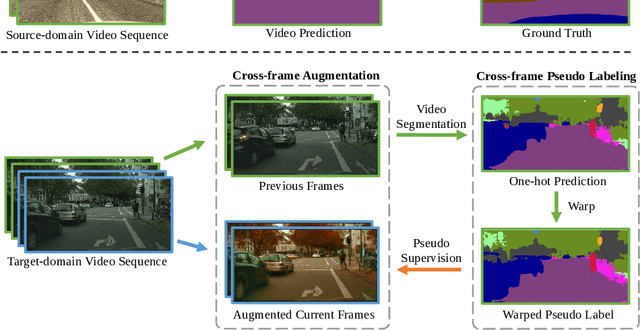
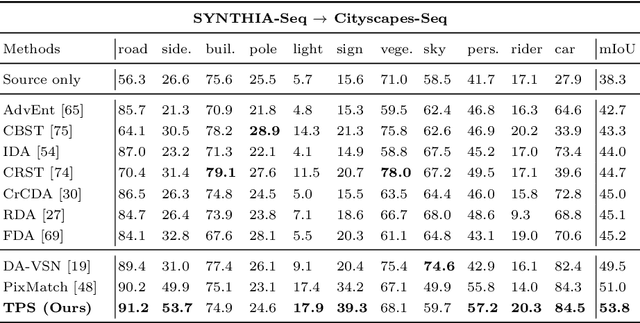
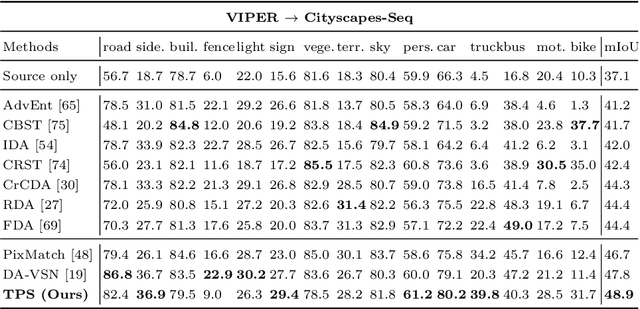

Video semantic segmentation has achieved great progress under the supervision of large amounts of labelled training data. However, domain adaptive video segmentation, which can mitigate data labelling constraints by adapting from a labelled source domain toward an unlabelled target domain, is largely neglected. We design temporal pseudo supervision (TPS), a simple and effective method that explores the idea of consistency training for learning effective representations from unlabelled target videos. Unlike traditional consistency training that builds consistency in spatial space, we explore consistency training in spatiotemporal space by enforcing model consistency across augmented video frames which helps learn from more diverse target data. Specifically, we design cross-frame pseudo labelling to provide pseudo supervision from previous video frames while learning from the augmented current video frames. The cross-frame pseudo labelling encourages the network to produce high-certainty predictions, which facilitates consistency training with cross-frame augmentation effectively. Extensive experiments over multiple public datasets show that TPS is simpler to implement, much more stable to train, and achieves superior video segmentation accuracy as compared with the state-of-the-art.
Unbiased Subclass Regularization for Semi-Supervised Semantic Segmentation
Mar 26, 2022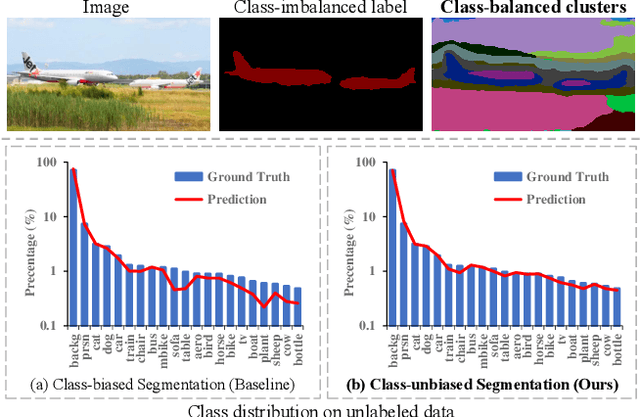
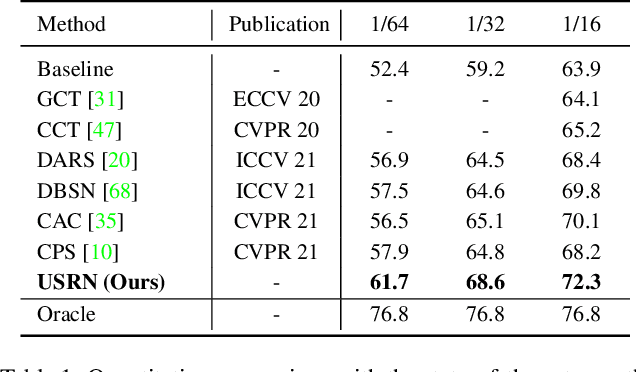
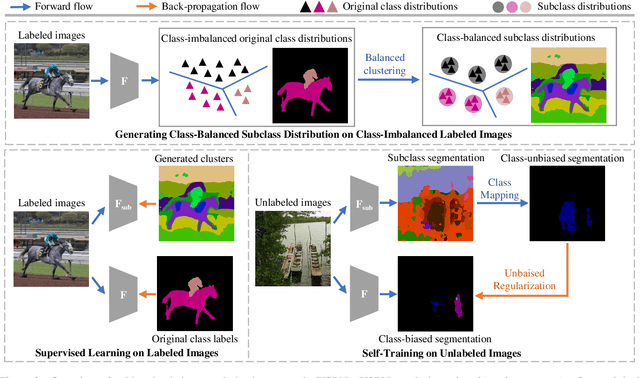
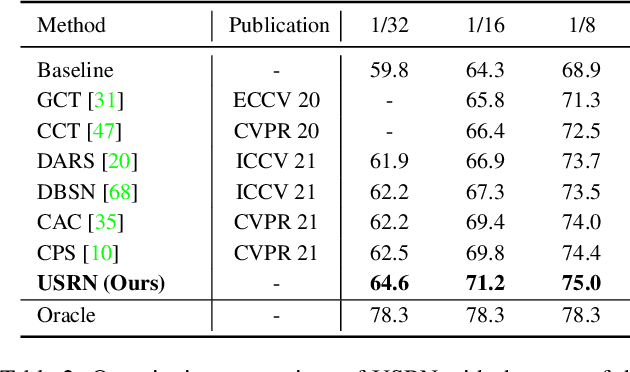
Semi-supervised semantic segmentation learns from small amounts of labelled images and large amounts of unlabelled images, which has witnessed impressive progress with the recent advance of deep neural networks. However, it often suffers from severe class-bias problem while exploring the unlabelled images, largely due to the clear pixel-wise class imbalance in the labelled images. This paper presents an unbiased subclass regularization network (USRN) that alleviates the class imbalance issue by learning class-unbiased segmentation from balanced subclass distributions. We build the balanced subclass distributions by clustering pixels of each original class into multiple subclasses of similar sizes, which provide class-balanced pseudo supervision to regularize the class-biased segmentation. In addition, we design an entropy-based gate mechanism to coordinate learning between the original classes and the clustered subclasses which facilitates subclass regularization effectively by suppressing unconfident subclass predictions. Extensive experiments over multiple public benchmarks show that USRN achieves superior performance as compared with the state-of-the-art.
Unsupervised Representation Learning for Point Clouds: A Survey
Feb 28, 2022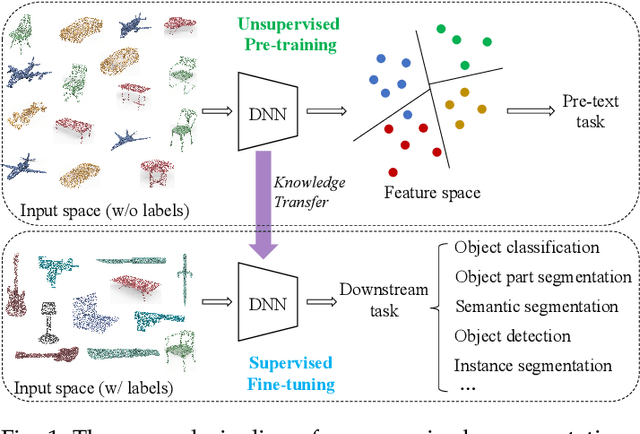

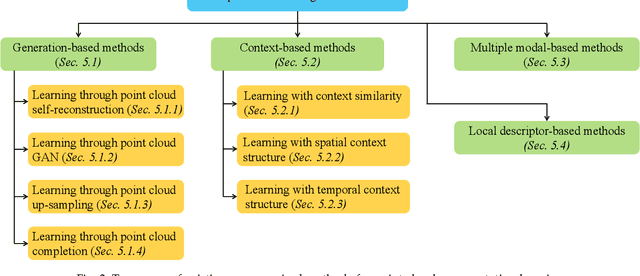
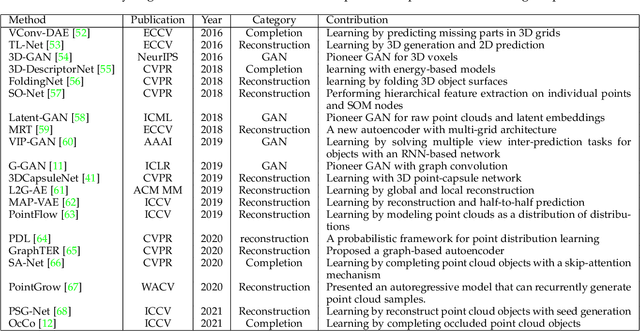
Point cloud data have been widely explored due to its superior accuracy and robustness under various adverse situations. Meanwhile, deep neural networks (DNNs) have achieved very impressive success in various applications such as surveillance and autonomous driving. The convergence of point cloud and DNNs has led to many deep point cloud models, largely trained under the supervision of large-scale and densely-labelled point cloud data. Unsupervised point cloud representation learning, which aims to learn general and useful point cloud representations from unlabelled point cloud data, has recently attracted increasing attention due to the constraint in large-scale point cloud labelling. This paper provides a comprehensive review of unsupervised point cloud representation learning using DNNs. It first describes the motivation, general pipelines as well as terminologies of the recent studies. Relevant background including widely adopted point cloud datasets and DNN architectures is then briefly presented. This is followed by an extensive discussion of existing unsupervised point cloud representation learning methods according to their technical approaches. We also quantitatively benchmark and discuss the reviewed methods over multiple widely adopted point cloud datasets. Finally, we share our humble opinion about several challenges and problems that could be pursued in the future research in unsupervised point cloud representation learning. A project associated with this survey has been built at https://github.com/xiaoaoran/3d_url_survey.