 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LAMP: Large Deep Nets with Automated Model Parallelism for Image Segmentation
Jun 22, 2020
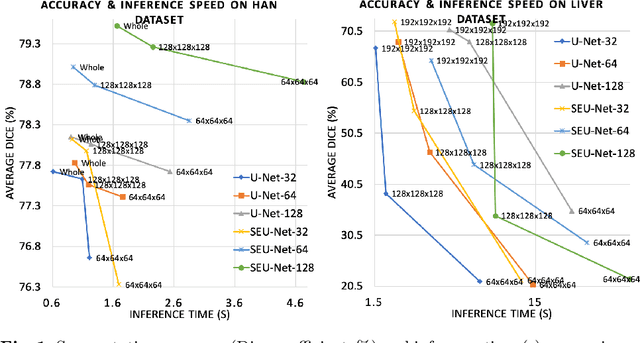
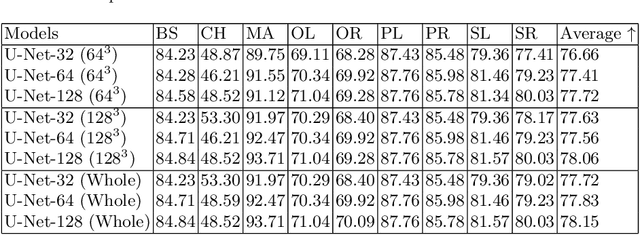
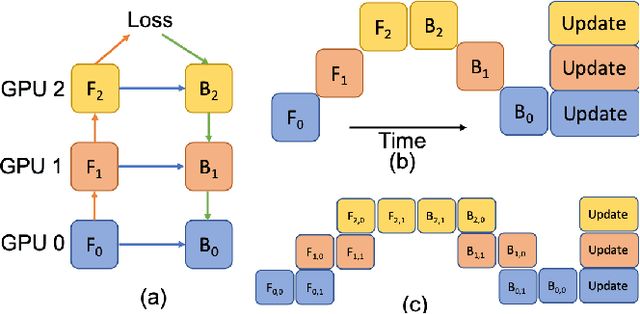
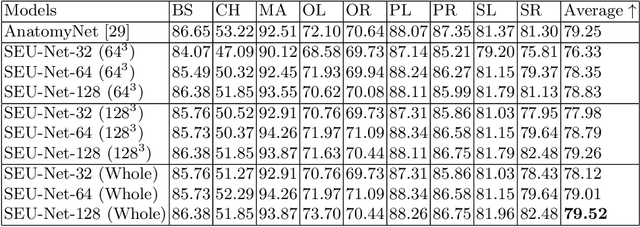
Deep Learning (DL) models are becoming larger, because the increase in model size might offer significant accuracy gain. To enable the training of large deep networks, data parallelism and model parallelism are two well-known approaches for parallel training. However, data parallelism does not help reduce memory footprint per device. In this work, we introduce Large deep 3D ConvNets with Automated Model Parallelism (LAMP) and investigate the impact of both input's and deep 3D ConvNets' size on segmentation accuracy. Through automated model parallelism, it is feasible to train large deep 3D ConvNets with a large input patch, even the whole image. Extensive experiments demonstrate that, facilitated by the automated model parallelism, the segmentation accuracy can be improved through increasing model size and input context size, and large input yields significant inference speedup compared with sliding window of small patches in the inference. Code is available\footnote{https://github.com/wentaozhu/lamp-automated-model-parallelism}.
Coherent Semantic Attention for Image Inpainting
Jun 12, 2019
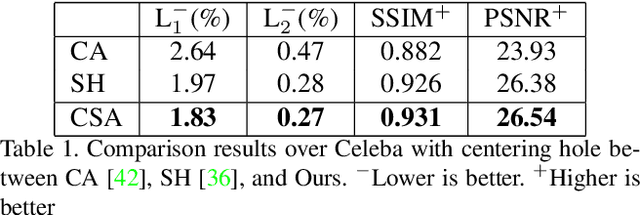
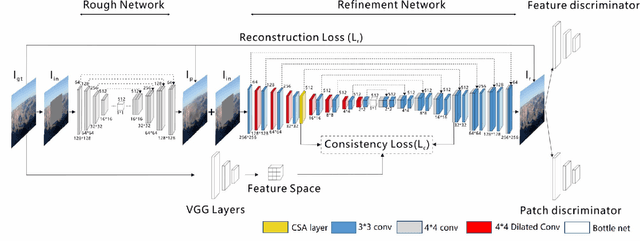
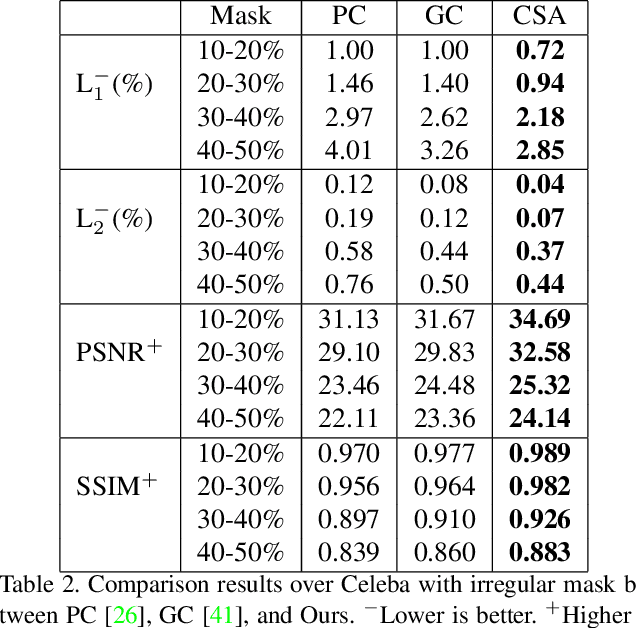
The latest deep learning-based approaches have shown promising results for the challenging task of inpainting missing regions of an image. However, the existing methods often generate contents with blurry textures and distorted structures due to the discontinuity of the local pixels. From a semantic-level perspective, the local pixel discontinuity is mainly because these methods ignore the semantic relevance and feature continuity of hole regions. To handle this problem, we investigate the human behavior in repairing pictures and propose a fined deep generative model-based approach with a novel coherent semantic attention (CSA) layer, which can not only preserve contextual structure but also make more effective predictions of missing parts by modeling the semantic relevance between the holes features. The task is divided into rough, refinement as two steps and model each step with a neural network under the U-Net architecture, where the CSA layer is embedded into the encoder of refinement step. To stabilize the network training process and promote the CSA layer to learn more effective parameters, we propose a consistency loss to enforce the both the CSA layer and the corresponding layer of the CSA in decoder to be close to the VGG feature layer of a ground truth image simultaneously. The experiments on CelebA, Places2, and Paris StreetView datasets have validated the effectiveness of our proposed methods in image inpainting tasks and can obtain images with a higher quality as compared with the existing state-of-the-art approaches.
Using Image Priors to Improve Scene Understanding
Oct 02, 2019
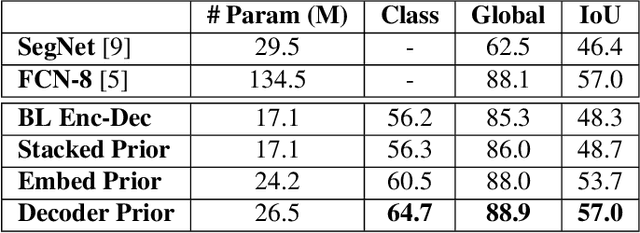
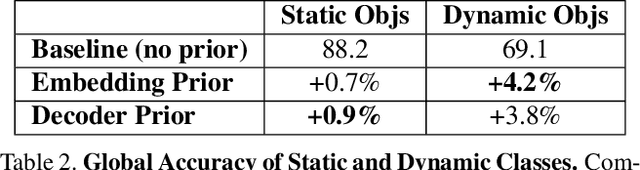
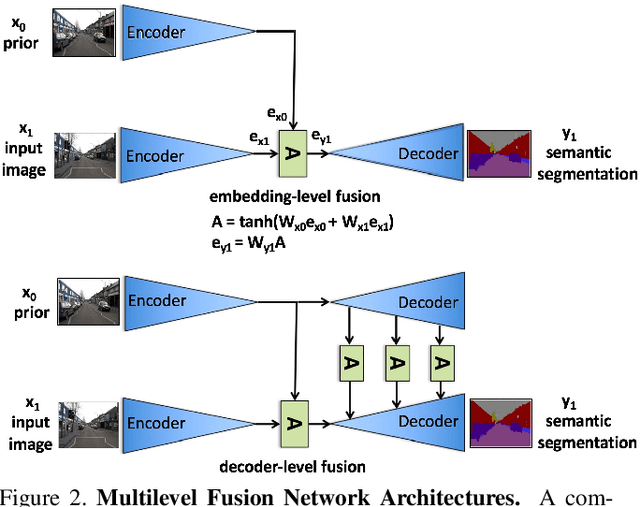
Semantic segmentation algorithms that can robustly segment objects across multiple camera viewpoints are crucial for assuring navigation and safety in emerging applications such as autonomous driving. Existing algorithms treat each image in isolation, but autonomous vehicles often revisit the same locations or maintain information from the immediate past. We propose a simple yet effective method for leveraging these image priors to improve semantic segmentation of images from sequential driving datasets. We examine several methods to fuse these temporal scene priors, and introduce a prior fusion network that is able to learn how to transfer this information. The prior fusion model improves the accuracy over the non-prior baseline from 69.1% to 73.3% for dynamic classes, and from 88.2% to 89.1% for static classes. Compared to models such as FCN-8, our prior method achieves the same accuracy with 5 times fewer parameters. We used a simple encoder decoder backbone, but this general prior fusion method could be applied to more complex semantic segmentation backbones. We also discuss how structured representations of scenes in the form of a scene graph could be leveraged as priors to further improve scene understanding.
A Deep Learning Approach to Predicting Collateral Flow in Stroke Patients Using Radiomic Features from Perfusion Images
Oct 24, 2021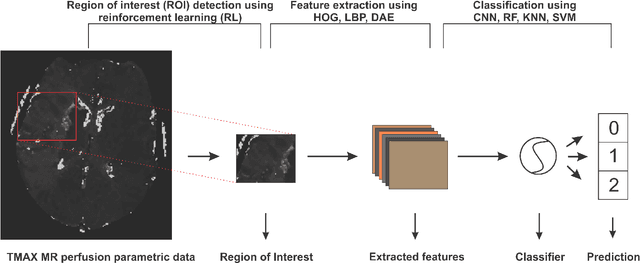
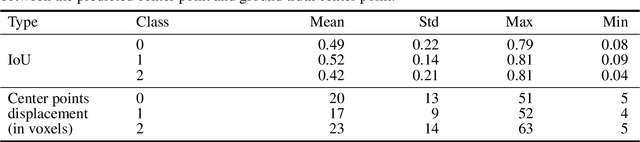
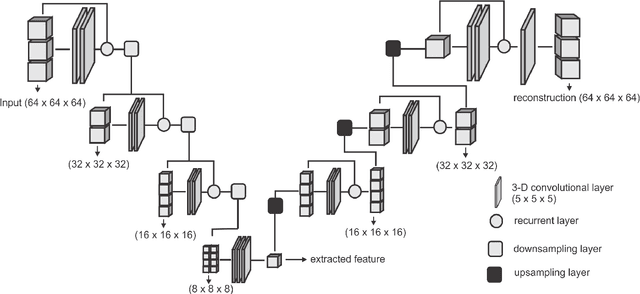
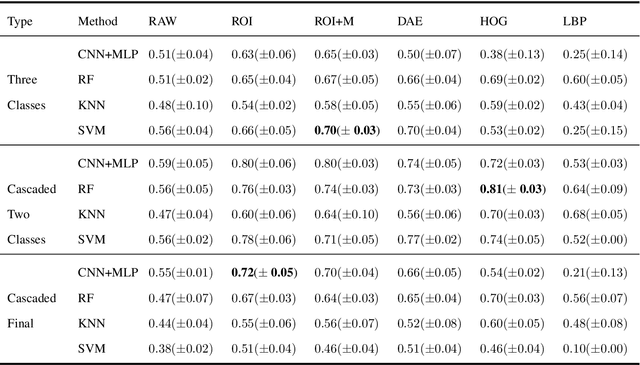
Collateral circulation results from specialized anastomotic channels which are capable of providing oxygenated blood to regions with compromised blood flow caused by ischemic injuries. The quality of collateral circulation has been established as a key factor in determining the likelihood of a favorable clinical outcome and goes a long way to determine the choice of stroke care model - that is the decision to transport or treat eligible patients immediately. Though there exist several imaging methods and grading criteria for quantifying collateral blood flow, the actual grading is mostly done through manual inspection of the acquired images. This approach is associated with a number of challenges. First, it is time-consuming - the clinician needs to scan through several slices of images to ascertain the region of interest before deciding on what severity grade to assign to a patient. Second, there is a high tendency for bias and inconsistency in the final grade assigned to a patient depending on the experience level of the clinician. We present a deep learning approach to predicting collateral flow grading in stroke patients based on radiomic features extracted from MR perfusion data. First, we formulate a region of interest detection task as a reinforcement learning problem and train a deep learning network to automatically detect the occluded region within the 3D MR perfusion volumes. Second, we extract radiomic features from the obtained region of interest through local image descriptors and denoising auto-encoders. Finally, we apply a convolutional neural network and other machine learning classifiers to the extracted radiomic features to automatically predict the collateral flow grading of the given patient volume as one of three severity classes - no flow (0), moderate flow (1), and good flow (2)...
GCN-Based Linkage Prediction for Face Clustering on Imbalanced Datasets: An Empirical Study
Jul 07, 2021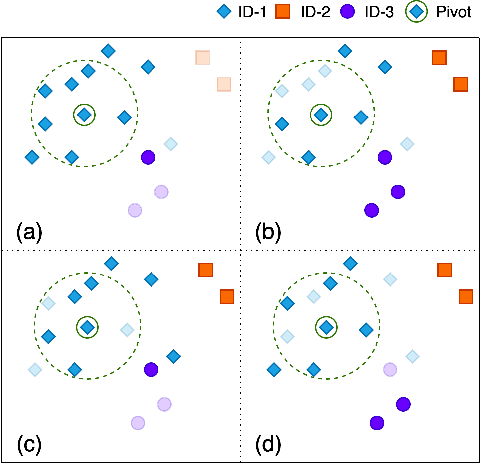
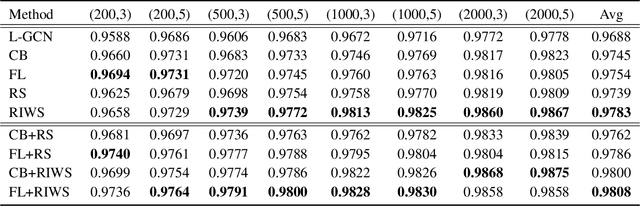
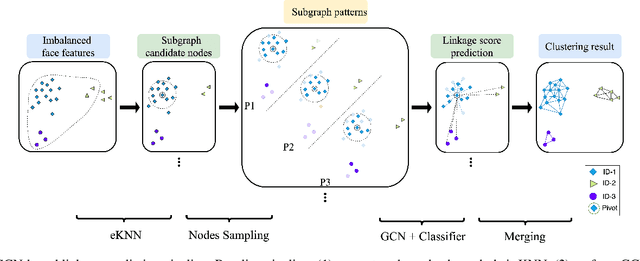
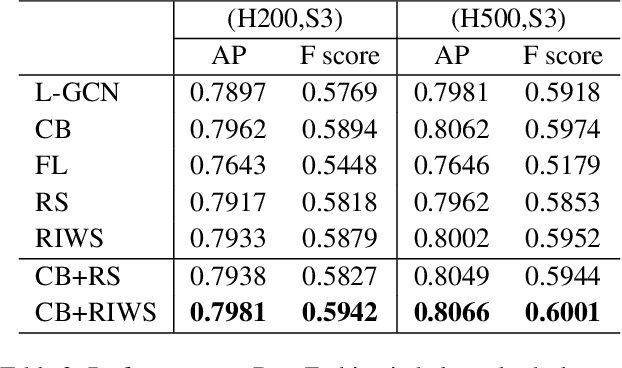
In recent years, benefiting from the expressive power of Graph Convolutional Networks (GCNs), significant breakthroughs have been made in face clustering. However, rare attention has been paid to GCN-based clustering on imbalanced data. Although imbalance problem has been extensively studied, the impact of imbalanced data on GCN-based linkage prediction task is quite different, which would cause problems in two aspects: imbalanced linkage labels and biased graph representations. The problem of imbalanced linkage labels is similar to that in image classification task, but the latter is a particular problem in GCN-based clustering via linkage prediction. Significantly biased graph representations in training can cause catastrophic overfitting of a GCN model. To tackle these problems, we evaluate the feasibility of those existing methods for imbalanced image classification problem on graphs with extensive experiments, and present a new method to alleviate the imbalanced labels and also augment graph representations using a Reverse-Imbalance Weighted Sampling (RIWS) strategy, followed with insightful analyses and discussions. The code and a series of imbalanced benchmark datasets synthesized from MS-Celeb-1M and DeepFashion are available on https://github.com/espectre/GCNs_on_imbalanced_datasets.
High-Resolution Pelvic MRI Reconstruction Using a Generative Adversarial Network with Attention and Cyclic Loss
Jul 21, 2021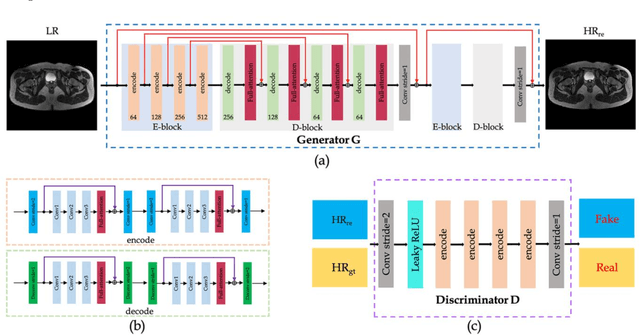
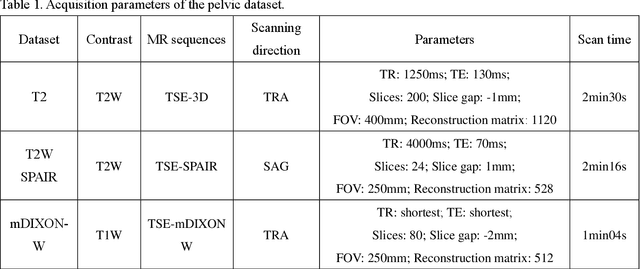
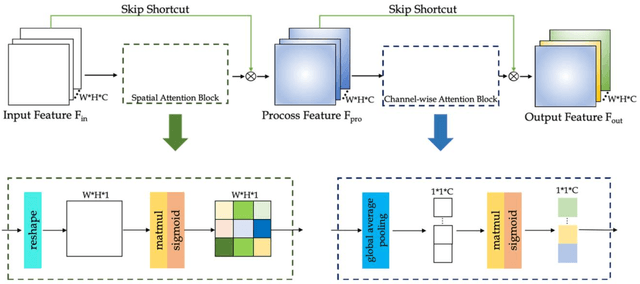

Magnetic resonance imaging (MRI) is an important medical imaging modality, but its acquisition speed is quite slow due to the physiological limitations. Recently, super-resolution methods have shown excellent performance in accelerating MRI. In some circumstances, it is difficult to obtain high-resolution images even with prolonged scan time. Therefore, we proposed a novel super-resolution method that uses a generative adversarial network (GAN) with cyclic loss and attention mechanism to generate high-resolution MR images from low-resolution MR images by a factor of 2. We implemented our model on pelvic images from healthy subjects as training and validation data, while those data from patients were used for testing. The MR dataset was obtained using different imaging sequences, including T2, T2W SPAIR, and mDIXON-W. Four methods, i.e., BICUBIC, SRCNN, SRGAN, and EDSR were used for comparison. Structural similarity, peak signal to noise ratio, root mean square error, and variance inflation factor were used as calculation indicators to evaluate the performances of the proposed method. Various experimental results showed that our method can better restore the details of the high-resolution MR image as compared to the other methods. In addition, the reconstructed high-resolution MR image can provide better lesion textures in the tumor patients, which is promising to be used in clinical diagnosis.
Hexagonal Image Processing in the Context of Machine Learning: Conception of a Biologically Inspired Hexagonal Deep Learning Framework
Dec 31, 2019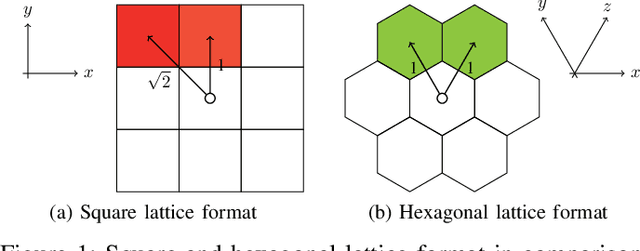
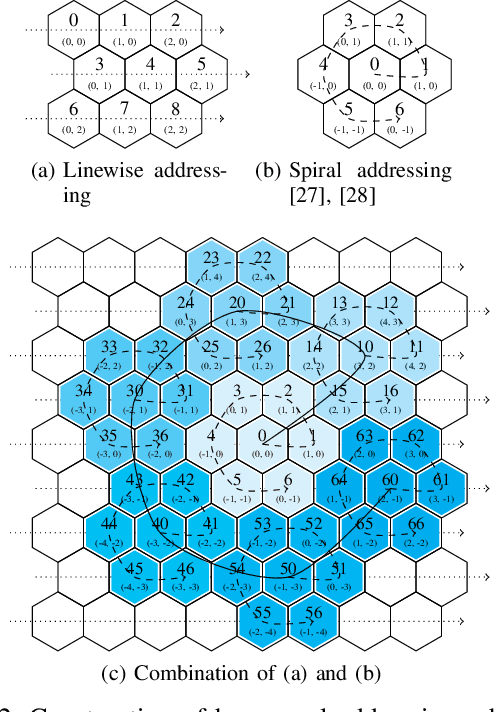
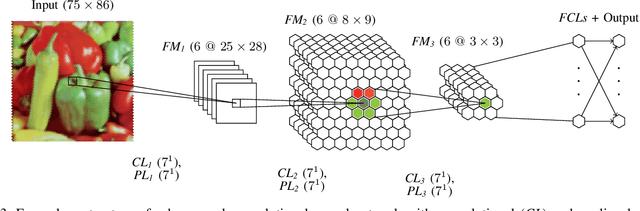

Inspired by the human visual perception system, hexagonal image processing in the context of machine learning deals with the development of image processing systems that combine the advantages of evolutionary motivated structures based on biological models. While conventional state of the art image processing systems of recording and output devices almost exclusively utilize square arranged methods, their hexagonal counterparts offer a number of key advantages that can benefit both researchers and users. This contribution serves as a general application-oriented approach with the synthesis of the therefor designed hexagonal image processing framework, called Hexnet, the processing steps of hexagonal image transformation, and dependent methods. The results of our created test environment show that the realized framework surpasses current approaches of hexagonal image processing systems, while hexagonal artificial neural networks can benefit from the implemented hexagonal architecture. As hexagonal lattice format based deep neural networks, also called H-DNN, can be compared to their square counterpart by transforming classical square lattice based data sets into their hexagonal representation, they can also result in a reduction of trainable parameters as well as result in increased training and test rates.
iART: A Search Engine for Art-Historical Images to Support Research in the Humanities
Aug 03, 2021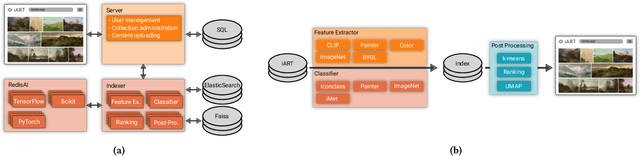
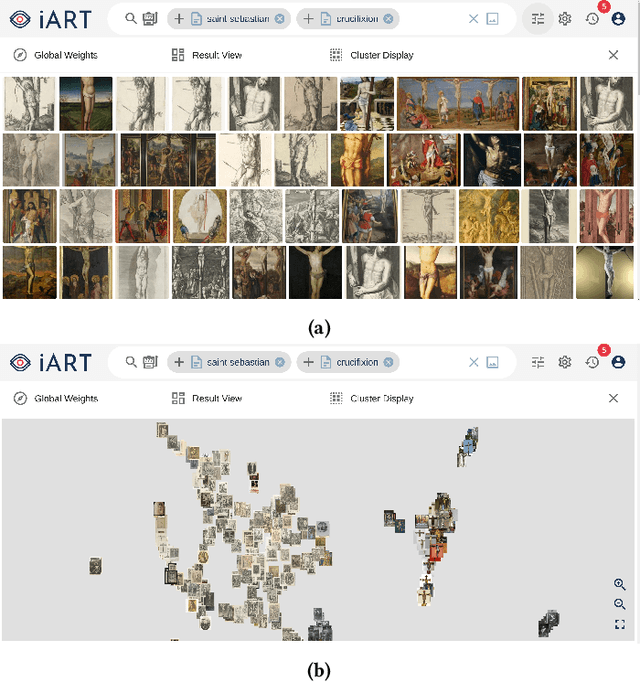
In this paper, we introduce iART: an open Web platform for art-historical research that facilitates the process of comparative vision. The system integrates various machine learning techniques for keyword- and content-based image retrieval as well as category formation via clustering. An intuitive GUI supports users to define queries and explore results. By using a state-of-the-art cross-modal deep learning approach, it is possible to search for concepts that were not previously detected by trained classification models. Art-historical objects from large, openly licensed collections such as Amsterdam Rijksmuseum and Wikidata are made available to users.
Melatect: A Machine Learning Model Approach For Identifying Malignant Melanoma in Skin Growths
Sep 21, 2021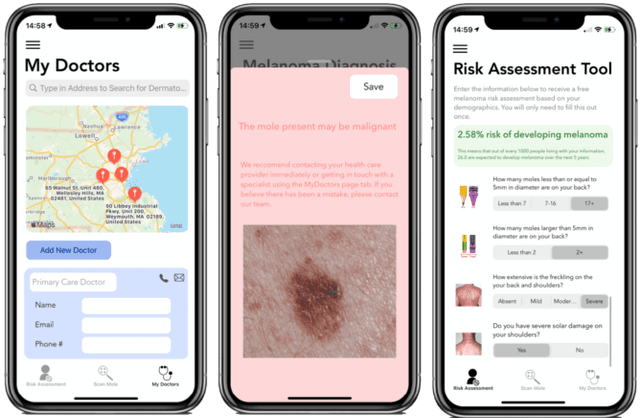
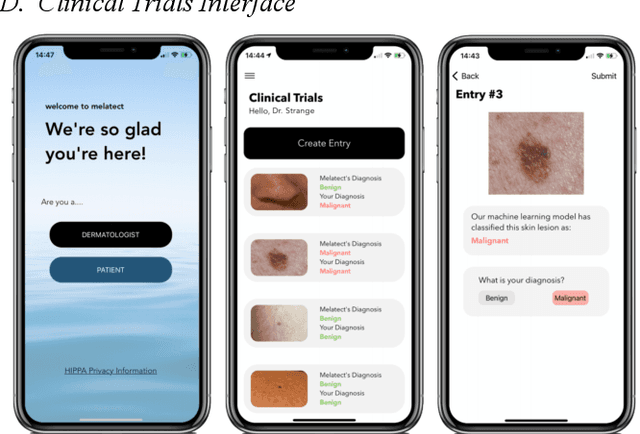
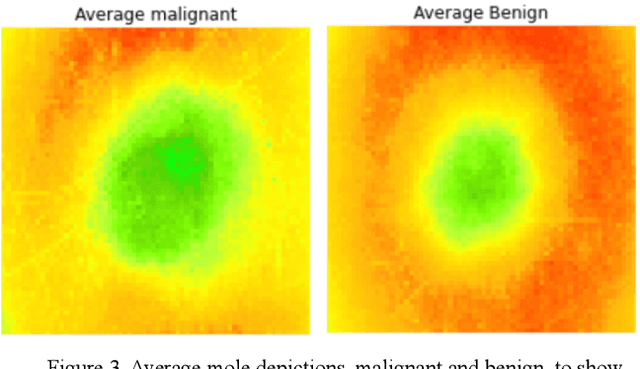
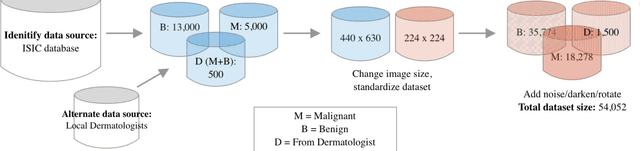
Malignant melanoma is a common skin cancer that is mostly curable before metastasis -when growths spawn in organs away from the original site. Melanoma is the most dangerous type of skin cancer if left untreated due to the high risk of metastasis. This paper presents Melatect, a machine learning (ML) model embedded in an iOS app that identifies potential malignant melanoma. Melatect accurately classifies lesions as malignant or benign over 96.6% of the time with no apparent bias or overfitting. Using the Melatect app, users have the ability to take pictures of skin lesions (moles) and subsequently receive a mole classification. The Melatect app provides a convenient way to get free advice on lesions and track these lesions over time. A recursive computer image analysis algorithm and modified MLOps pipeline was developed to create a model that performs at a higher accuracy than existing models. Our training dataset included 18,400 images of benign and malignant lesions, including 18,000 from the International Skin Imaging Collaboration (ISIC) archive, as well as 400 images gathered from local dermatologists; these images were augmented using DeepAugment, an AutoML tool, to 54,054 images.
Camera-to-Robot Pose Estimation from a Single Image
Dec 05, 2019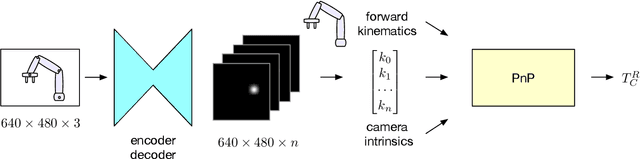

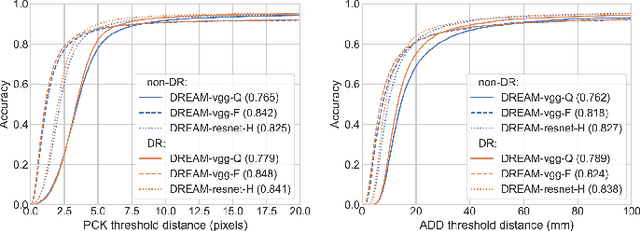
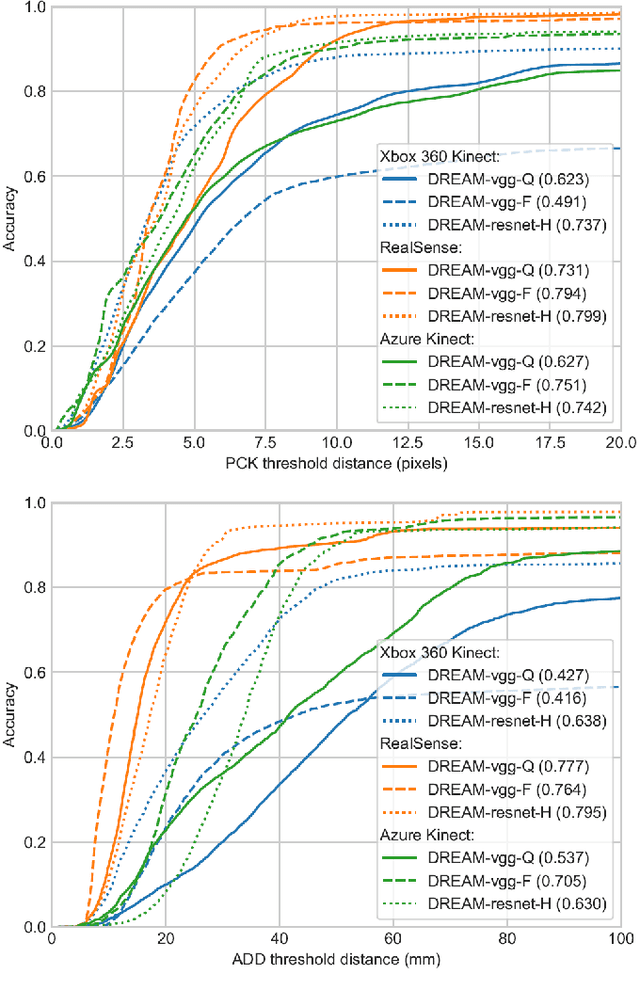
We present an approach for estimating the pose of a camera with respect to a robot from a single image. Our method uses a deep neural network to process an RGB image from the camera to detect 2D keypoints on the robot. The network is trained entirely on simulated data using domain randomization. Perspective-$n$-point (P$n$P) is then used to recover the camera extrinsics, assuming that the joint configuration of the robot manipulator is known. Unlike classic hand-eye calibration systems, our method does not require an off-line calibration step but rather is capable of computing the camera extrinsics from a single frame, thus opening the possibility of on-line calibration. We show experimental results for three different camera sensors, demonstrating that our approach is able to achieve accuracy with a single frame that is better than that of classic off-line hand-eye calibration using multiple frames. With additional frames, accuracy improves even further. Code, datasets, and pretrained models for three widely-used robot manipulators will be made available.