 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Remote Sensing Images Semantic Segmentation with General Remote Sensing Vision Model via a Self-Supervised Contrastive Learning Method
Jun 20, 2021
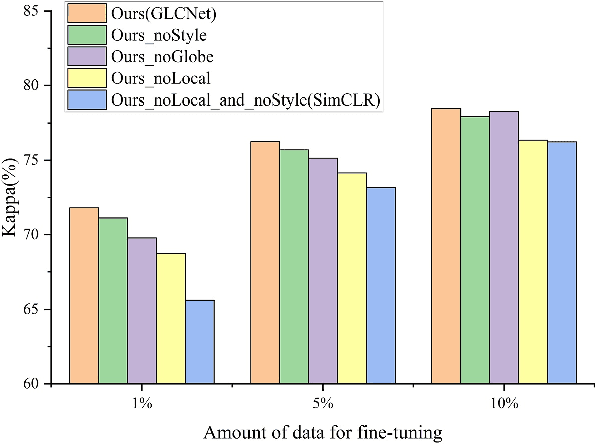
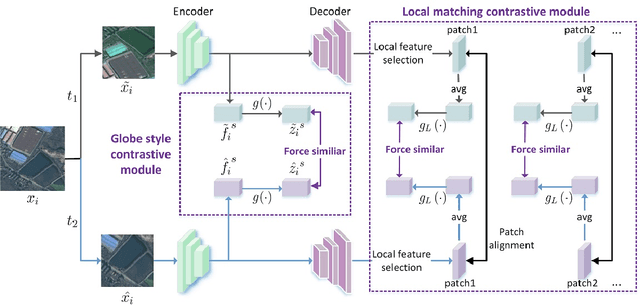
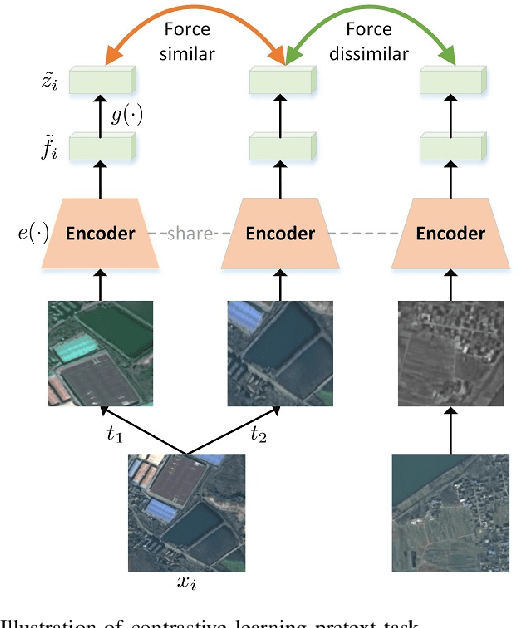
A new learning paradigm, self-supervised learning (SSL), can be used to solve such problems by pre-training a general model with large unlabeled images and then fine-tuning on a downstream task with very few labeled samples. Contrastive learning is a typical method of SSL, which can learn general invariant features. However, most of the existing contrastive learning is designed for classification tasks to obtain an image-level representation, which may be sub-optimal for semantic segmentation tasks requiring pixel-level discrimination. Therefore, we propose Global style and Local matching Contrastive Learning Network (GLCNet) for remote sensing semantic segmentation. Specifically, the global style contrastive module is used to learn an image-level representation better, as we consider the style features can better represent the overall image features; The local features matching contrastive module is designed to learn representations of local regions which is beneficial for semantic segmentation. We evaluate four remote sensing semantic segmentation datasets, and the experimental results show that our method mostly outperforms state-of-the-art self-supervised methods and ImageNet pre-training. Specifically, with 1\% annotation from the original dataset, our approach improves Kappa by 6\% on the ISPRS Potsdam dataset and 3\% on Deep Globe Land Cover Classification dataset relative to the existing baseline. Moreover, our method outperforms supervised learning when there are some differences between the datasets of upstream tasks and downstream tasks. Our study promotes the development of self-supervised learning in the field of remote sensing semantic segmentation. The source code is available at https://github.com/GeoX-Lab/G-RSIM.
Test-time Batch Statistics Calibration for Covariate Shift
Oct 06, 2021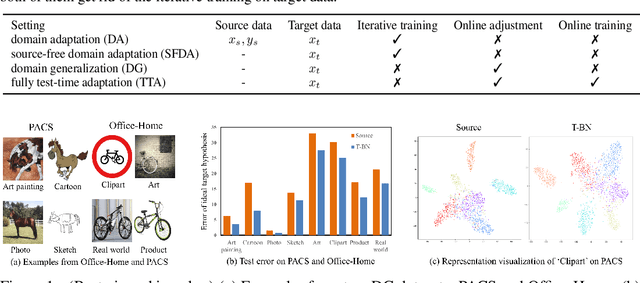

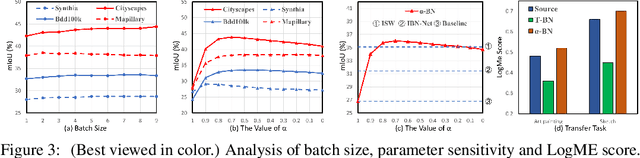
Deep neural networks have a clear degradation when applying to the unseen environment due to the covariate shift. Conventional approaches like domain adaptation requires the pre-collected target data for iterative training, which is impractical in real-world applications. In this paper, we propose to adapt the deep models to the novel environment during inference. An previous solution is test time normalization, which substitutes the source statistics in BN layers with the target batch statistics. However, we show that test time normalization may potentially deteriorate the discriminative structures due to the mismatch between target batch statistics and source parameters. To this end, we present a general formulation $\alpha$-BN to calibrate the batch statistics by mixing up the source and target statistics for both alleviating the domain shift and preserving the discriminative structures. Based on $\alpha$-BN, we further present a novel loss function to form a unified test time adaptation framework Core, which performs the pairwise class correlation online optimization. Extensive experiments show that our approaches achieve the state-of-the-art performance on total twelve datasets from three topics, including model robustness to corruptions, domain generalization on image classification and semantic segmentation. Particularly, our $\alpha$-BN improves 28.4\% to 43.9\% on GTA5 $\rightarrow$ Cityscapes without any training, even outperforms the latest source-free domain adaptation method.
AASeg: Attention Aware Network for Real Time Semantic Segmentation
Aug 11, 2021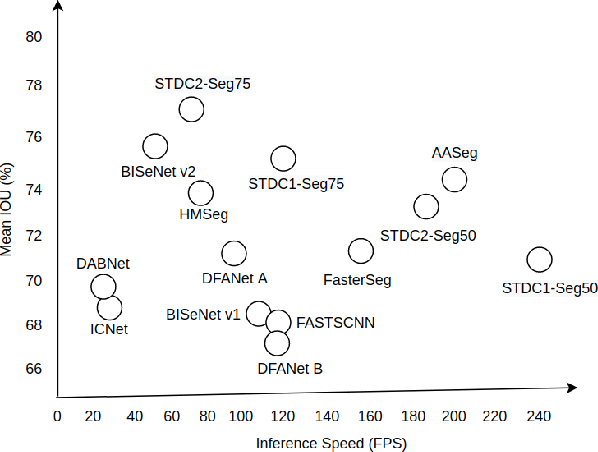
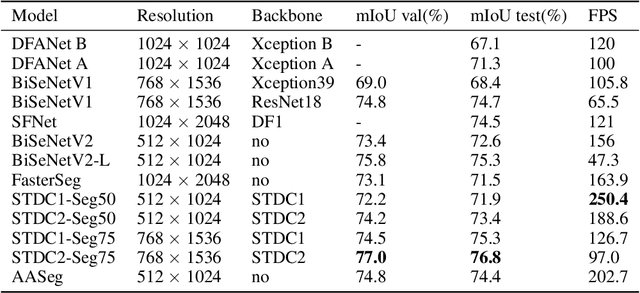
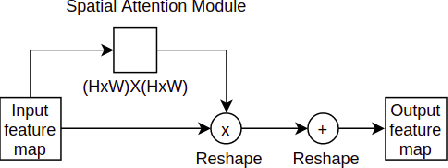
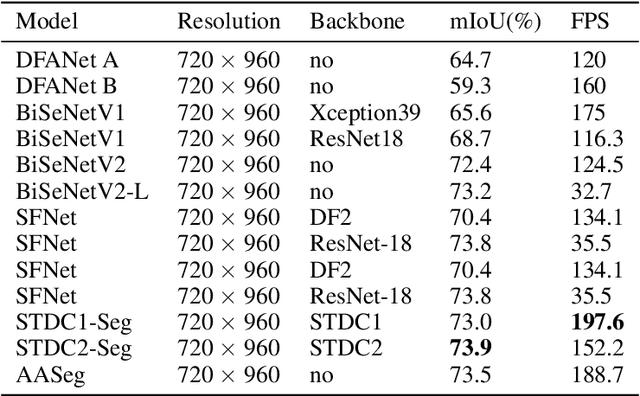
In this paper, we present a new network named Attention Aware Network (AASeg) for real time semantic image segmentation. Our network incorporates spatial and channel information using Spatial Attention (SA) and Channel Attention (CA) modules respectively. It also uses dense local multi-scale context information using Multi Scale Context (MSC) module. The feature maps are concatenated individually to produce the final segmentation map. We demonstrate the effectiveness of our method using a comprehensive analysis, quantitative experimental results and ablation study using Cityscapes, ADE20K and Camvid datasets. Our network performs better than most previous architectures with a 74.4\% Mean IOU on Cityscapes test dataset while running at 202.7 FPS.
Wavelet Transform-assisted Adaptive Generative Modeling for Colorization
Jul 09, 2021


Unsupervised deep learning has recently demonstrated the promise to produce high-quality samples. While it has tremendous potential to promote the image colorization task, the performance is limited owing to the manifold hypothesis in machine learning. This study presents a novel scheme that exploiting the score-based generative model in wavelet domain to address the issue. By taking advantage of the multi-scale and multi-channel representation via wavelet transform, the proposed model learns the priors from stacked wavelet coefficient components, thus learns the image characteristics under coarse and detail frequency spectrums jointly and effectively. Moreover, such a highly flexible generative model without adversarial optimization can execute colorization tasks better under dual consistency terms in wavelet domain, namely data-consistency and structure-consistency. Specifically, in the training phase, a set of multi-channel tensors consisting of wavelet coefficients are used as the input to train the network by denoising score matching. In the test phase, samples are iteratively generated via annealed Langevin dynamics with data and structure consistencies. Experiments demonstrated remarkable improvements of the proposed model on colorization quality, particularly on colorization robustness and diversity.
VSGM -- Enhance robot task understanding ability through visual semantic graph
May 25, 2021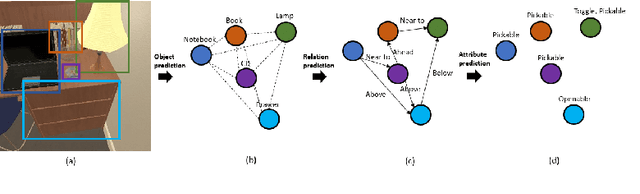
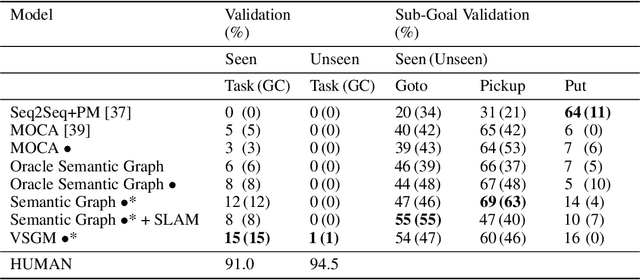

In recent years, developing AI for robotics has raised much attention. The interaction of vision and language of robots is particularly difficult. We consider that giving robots an understanding of visual semantics and language semantics will improve inference ability. In this paper, we propose a novel method-VSGM (Visual Semantic Graph Memory), which uses the semantic graph to obtain better visual image features, improve the robot's visual understanding ability. By providing prior knowledge of the robot and detecting the objects in the image, it predicts the correlation between the attributes of the object and the objects and converts them into a graph-based representation; and mapping the object in the image to be a top-down egocentric map. Finally, the important object features of the current task are extracted by Graph Neural Networks. The method proposed in this paper is verified in the ALFRED (Action Learning From Realistic Environments and Directives) dataset. In this dataset, the robot needs to perform daily indoor household tasks following the required language instructions. After the model is added to the VSGM, the task success rate can be improved by 6~10%.
On the combined effect of class imbalance and concept complexity in deep learning
Jul 29, 2021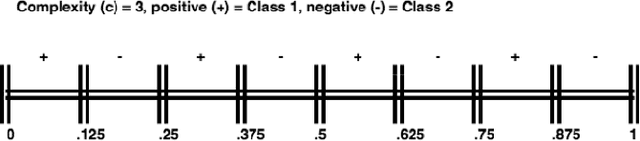
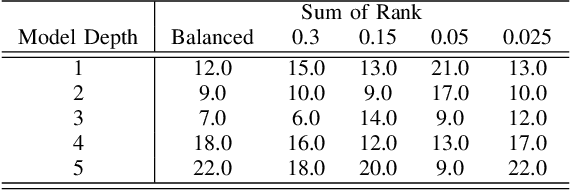
Structural concept complexity, class overlap, and data scarcity are some of the most important factors influencing the performance of classifiers under class imbalance conditions. When these effects were uncovered in the early 2000s, understandably, the classifiers on which they were demonstrated belonged to the classical rather than Deep Learning categories of approaches. As Deep Learning is gaining ground over classical machine learning and is beginning to be used in critical applied settings, it is important to assess systematically how well they respond to the kind of challenges their classical counterparts have struggled with in the past two decades. The purpose of this paper is to study the behavior of deep learning systems in settings that have previously been deemed challenging to classical machine learning systems to find out whether the depth of the systems is an asset in such settings. The results in both artificial and real-world image datasets (MNIST Fashion, CIFAR-10) show that these settings remain mostly challenging for Deep Learning systems and that deeper architectures seem to help with structural concept complexity but not with overlap challenges in simple artificial domains. Data scarcity is not overcome by deeper layers, either. In the real-world image domains, where overfitting is a greater concern than in the artificial domains, the advantage of deeper architectures is less obvious: while it is observed in certain cases, it is quickly cancelled as models get deeper and perform worse than their shallower counterparts.
Spatially-Varying Outdoor Lighting Estimation from Intrinsics
Apr 28, 2021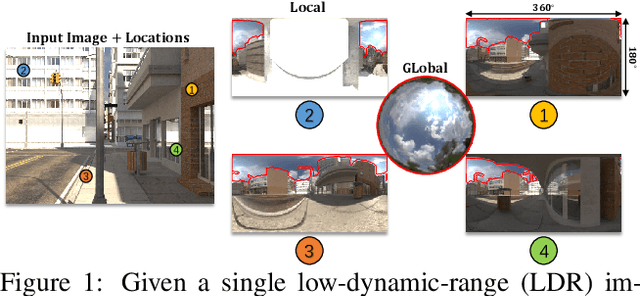
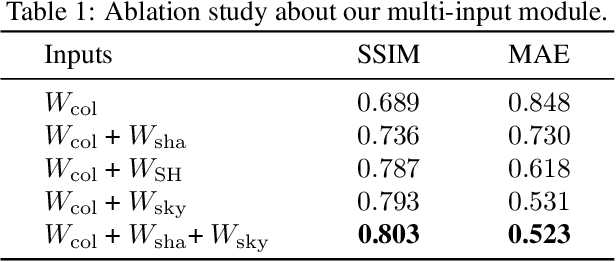
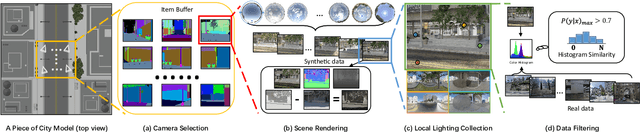
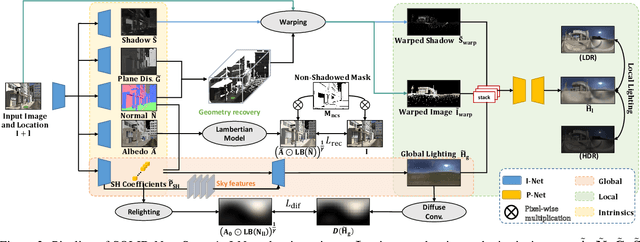
We present SOLID-Net, a neural network for spatially-varying outdoor lighting estimation from a single outdoor image for any 2D pixel location. Previous work has used a unified sky environment map to represent outdoor lighting. Instead, we generate spatially-varying local lighting environment maps by combining global sky environment map with warped image information according to geometric information estimated from intrinsics. As no outdoor dataset with image and local lighting ground truth is readily available, we introduce the SOLID-Img dataset with physically-based rendered images and their corresponding intrinsic and lighting information. We train a deep neural network to regress intrinsic cues with physically-based constraints and use them to conduct global and local lightings estimation. Experiments on both synthetic and real datasets show that SOLID-Net significantly outperforms previous methods.
Optical Tactile Sim-to-Real Policy Transfer via Real-to-Sim Tactile Image Translation
Jun 16, 2021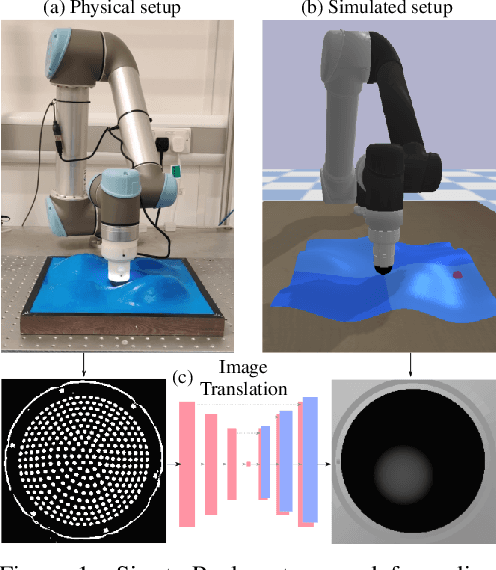

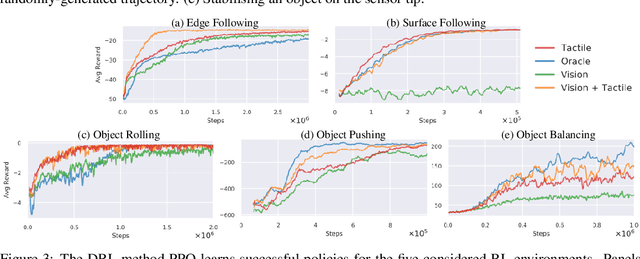

Simulation has recently become key for deep reinforcement learning to safely and efficiently acquire general and complex control policies from visual and proprioceptive inputs. Tactile information is not usually considered despite its direct relation to environment interaction. In this work, we present a suite of simulated environments tailored towards tactile robotics and reinforcement learning. A simple and fast method of simulating optical tactile sensors is provided, where high-resolution contact geometry is represented as depth images. Proximal Policy Optimisation (PPO) is used to learn successful policies across all considered tasks. A data-driven approach enables translation of the current state of a real tactile sensor to corresponding simulated depth images. This policy is implemented within a real-time control loop on a physical robot to demonstrate zero-shot sim-to-real policy transfer on several physically-interactive tasks requiring a sense of touch.
COIN: COmpression with Implicit Neural representations
Mar 03, 2021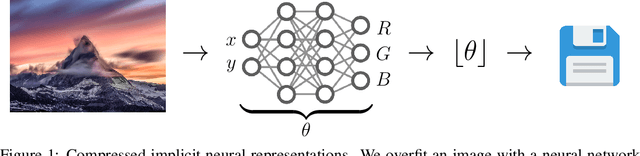
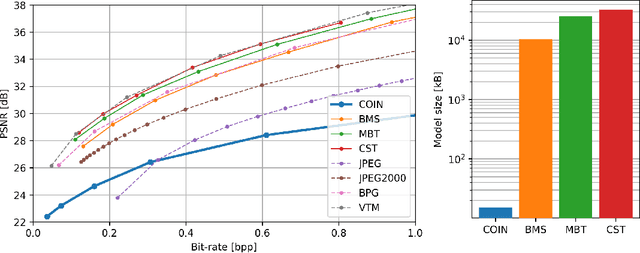
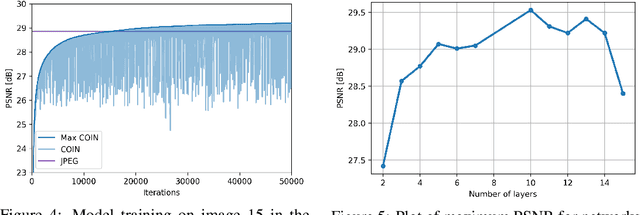
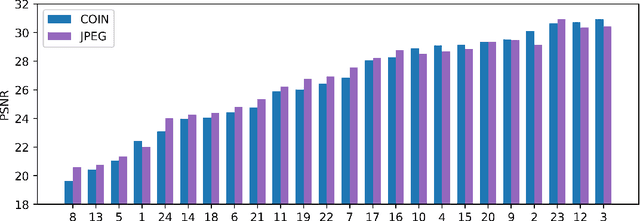
We propose a new simple approach for image compression: instead of storing the RGB values for each pixel of an image, we store the weights of a neural network overfitted to the image. Specifically, to encode an image, we fit it with an MLP which maps pixel locations to RGB values. We then quantize and store the weights of this MLP as a code for the image. To decode the image, we simply evaluate the MLP at every pixel location. We found that this simple approach outperforms JPEG at low bit-rates, even without entropy coding or learning a distribution over weights. While our framework is not yet competitive with state of the art compression methods, we show that it has various attractive properties which could make it a viable alternative to other neural data compression approaches.
Uncertainty-Aware Multi-Shot Knowledge Distillation for Image-Based Object Re-Identification
Jan 21, 2020



Object re-identification (re-id) aims to identify a specific object across times or camera views, with the person re-id and vehicle re-id as the most widely studied applications. Re-id is challenging because of the variations in viewpoints, (human) poses, and occlusions. Multi-shots of the same object can cover diverse viewpoints/poses and thus provide more comprehensive information. In this paper, we propose exploiting the multi-shots of the same identity to guide the feature learning of each individual image. Specifically, we design an Uncertainty-aware Multi-shot Teacher-Student (UMTS) Network. It consists of a teacher network (T-net) that learns the comprehensive features from multiple images of the same object, and a student network (S-net) that takes a single image as input. In particular, we take into account the data dependent heteroscedastic uncertainty for effectively transferring the knowledge from the T-net to S-net. To the best of our knowledge, we are the first to make use of multi-shots of an object in a teacher-student learning manner for effectively boosting the single image based re-id. We validate the effectiveness of our approach on the popular vehicle re-id and person re-id datasets. In inference, the S-net alone significantly outperforms the baselines and achieves the state-of-the-art performance.