 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-o3: Deep Nested Omnimodal Deduction for Deliberative Audio-Visual Reasoning
Apr 27, 2026Omnimodal understanding entails a massive, highly redundant search space of cross-modal interactions, demanding focused and deliberative reasoning. Current reasoning paradigms rely on either sequential step-by-step generation or parallel sample-by-sample rollouts, leading to isolated reasoning trajectories. This inability to share promising intermediate paths severely limits exploration efficiency and causes compounding errors in complex audio-visual tasks. To break this bottleneck, we introduce Omni-o3, a novel framework driven by a deep nested deduction policy. By formulating reasoning as a dynamic recursive search, Omni-o3 inherently shares reasoning prefixes across branches, enabling the iterative execution of four atomic cognitive actions: expansion, selection, simulation, and backpropagation. To empower this framework, we propose a robust two-stage training paradigm: (1) cold-start supervised fine-tuning on 101K high-quality, long-chain trajectories distilled from 3.5M diverse omnimodal samples, enabling necessary recursive search patterns; and (2) nested group rollout-driven exploratory reinforcement learning on 18K complex multi-turn samples, explicitly guided by a novel multi-step reward model to stimulate deep nested reasoning. Extensive experiments demonstrate that Omni-o3 achieves competitive performance across 11 benchmarks, unlocking advanced capabilities in comprehensive audio-visual, visual-centric, and audio-centric reasoning tasks.
Beyond the Golden Data: Resolving the Motion-Vision Quality Dilemma via Timestep Selective Training
Mar 26, 2026Recent advances in video generation models have achieved impressive results. However, these models heavily rely on the use of high-quality data that combines both high visual quality and high motion quality. In this paper, we identify a key challenge in video data curation: the Motion-Vision Quality Dilemma. We discovered that visual quality and motion intensity inherently exhibit a negative correlation, making it hard to obtain golden data that excels in both aspects. To address this challenge, we first examine the hierarchical learning dynamics of video diffusion models and conduct gradient-based analysis on quality-degraded samples. We discover that quality-imbalanced data can produce gradients similar to golden data at appropriate timesteps. Based on this, we introduce the novel concept of Timestep selection in Training Process. We propose Timestep-aware Quality Decoupling (TQD), which modifies the data sampling distribution to better match the model's learning process. For certain types of data, the sampling distribution is skewed toward higher timesteps for motion-rich data, while high visual quality data is more likely to be sampled during lower timesteps. Through extensive experiments, we demonstrate that TQD enables training exclusively on separated imbalanced data to achieve performance surpassing conventional training with better data, challenging the necessity of perfect data in video generation. Moreover, our method also boosts model performance when trained on high-quality data, showcasing its effectiveness across different data scenarios.
Analytic Score Optimization for Multi Dimension Video Quality Assessment
Feb 18, 2026Video Quality Assessment (VQA) is evolving beyond single-number mean opinion score toward richer, multi-faceted evaluations of video content. In this paper, we present a large-scale multi-dimensional VQA dataset UltraVQA that encompasses diverse User-Generated Content~(UGC) annotated across five key quality dimensions: Motion Quality, Motion Amplitude, Aesthetic Quality, Content Quality, and Clarity Quality. Each video in our dataset is scored by over 3 human raters on these dimensions, with fine-grained sub-attribute labels, and accompanied by an explanatory rationale generated by GPT based on the collective human judgments. To better leverage these rich annotations and improve discrete quality score assessment, we introduce Analytic Score Optimization (ASO), a theoretically grounded post-training objective derived for multi-dimensional VQA. By reframing quality assessment as a regularized decision-making process, we obtain a closed-form solution that naturally captures the ordinal nature of human ratings, ensuring alignment with human ranking preferences. In experiments, our method outperforms most baselines including closed-source APIs and open-source models, while also reducing mean absolute error (MAE) in quality prediction. Our work highlights the importance of multi-dimensional, interpretable annotations and reinforcement-based alignment in advancing video quality assessment.
Embed-RL: Reinforcement Learning for Reasoning-Driven Multimodal Embeddings
Feb 14, 2026Leveraging Multimodal Large Language Models (MLLMs) has become pivotal for advancing Universal Multimodal Embeddings (UME) in addressing diverse cross-modal tasks. Recent studies demonstrate that incorporating generative Chain-of-Thought (CoT) reasoning can substantially enhance task-specific representations compared to discriminative methods. However, the generated reasoning CoTs of existing generative embedding methods are limited to the textual analysis of queries and are irrelevant to the retrieval of the targets. To address these limitations, we propose a reasoning-driven UME framework that integrates Embedder-Guided Reinforcement Learning (EG-RL) to optimize the Reasoner to produce evidential Traceability CoT (T-CoT). Our key contributions are threefold: (1) We design an EG-RL framework where the Embedder provides explicit supervision to the Reasoner, ensuring the generated CoT traces are aligned with embedding tasks. (2) We introduce T-CoT, which extracts critical multimodal cues to focus on retrieval-relevant elements and provides multimodal inputs for the Embedder. (3) With limited computational resources, our framework outperforms the pioneering embedding model on both MMEB-V2 and UVRB benchmarks. The integration of multimodal evidence in structured reasoning, paired with retrieval-oriented alignment, effectively strengthens cross-modal semantic consistency and boosts the fine-grained matching capability of the model as well as the generalization across complex scenarios. Our work demonstrates that targeted reasoning optimization can significantly improve multimodal embedding quality, providing a practical and efficient solution for reasoning-driven UME development.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Disentangling Identifiable Features from Noisy Data with Structured Nonlinear ICA
Jun 17, 2021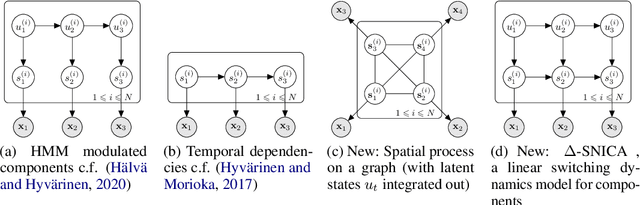
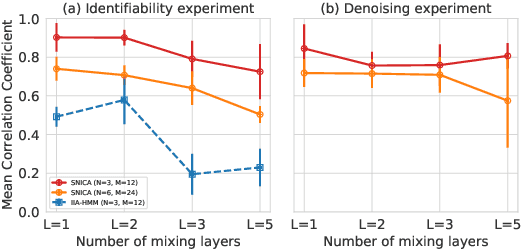
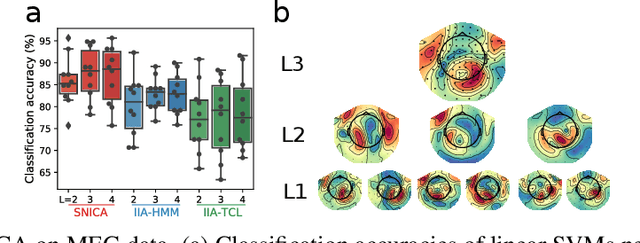
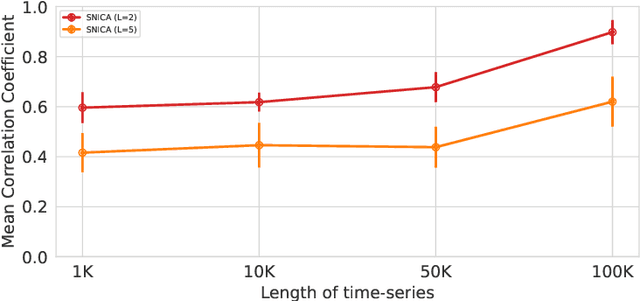
We introduce a new general identifiable framework for principled disentanglement referred to as Structured Nonlinear Independent Component Analysis (SNICA). Our contribution is to extend the identifiability theory of deep generative models for a very broad class of structured models. While previous works have shown identifiability for specific classes of time-series models, our theorems extend this to more general temporal structures as well as to models with more complex structures such as spatial dependencies. In particular, we establish the major result that identifiability for this framework holds even in the presence of noise of unknown distribution. The SNICA setting therefore subsumes all the existing nonlinear ICA models for time-series and also allows for new much richer identifiable models. Finally, as an example of our framework's flexibility, we introduce the first nonlinear ICA model for time-series that combines the following very useful properties: it accounts for both nonstationarity and autocorrelation in a fully unsupervised setting; performs dimensionality reduction; models hidden states; and enables principled estimation and inference by variational maximum-likelihood.
DeRenderNet: Intrinsic Image Decomposition of Urban Scenes with Shape-(In)dependent Shading Rendering
Apr 28, 2021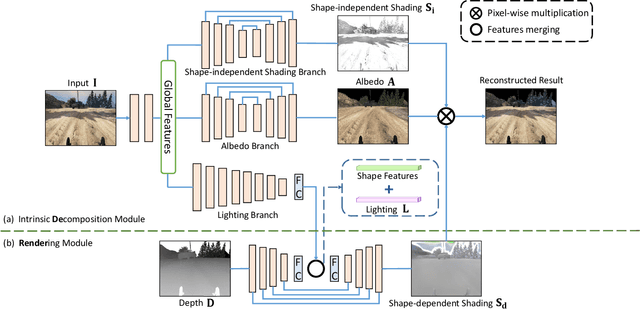
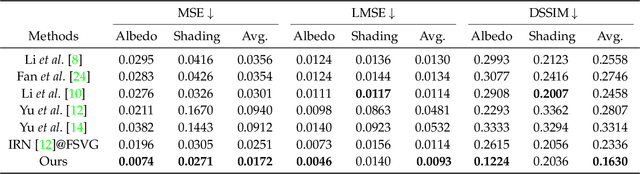
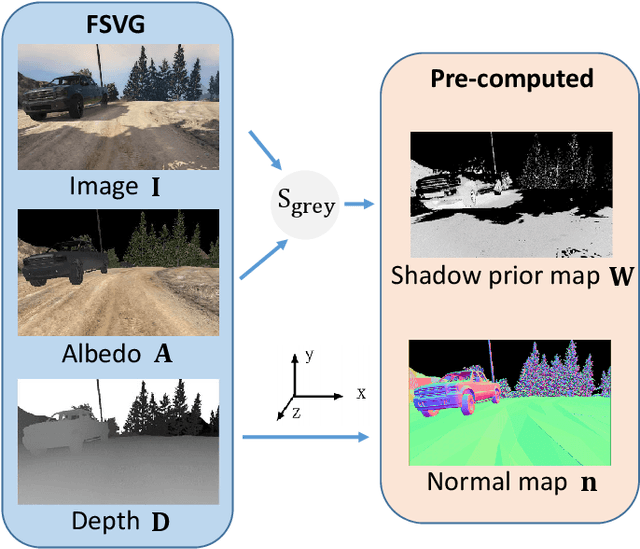
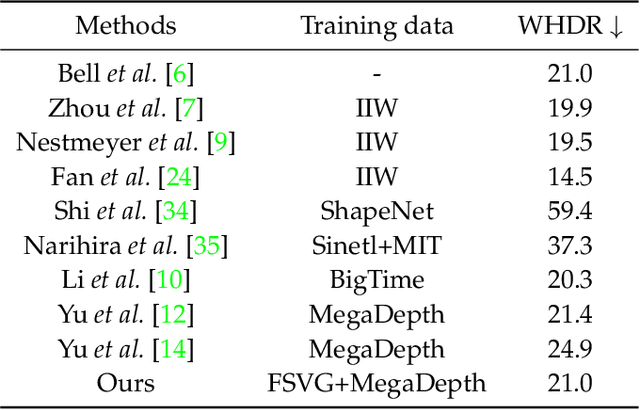
We propose DeRenderNet, a deep neural network to decompose the albedo and latent lighting, and render shape-(in)dependent shadings, given a single image of an outdoor urban scene, trained in a self-supervised manner. To achieve this goal, we propose to use the albedo maps extracted from scenes in videogames as direct supervision and pre-compute the normal and shadow prior maps based on the depth maps provided as indirect supervision. Compared with state-of-the-art intrinsic image decomposition methods, DeRenderNet produces shadow-free albedo maps with clean details and an accurate prediction of shadows in the shape-independent shading, which is shown to be effective in re-rendering and improving the accuracy of high-level vision tasks for urban scenes.
Spatially-Varying Outdoor Lighting Estimation from Intrinsics
Apr 28, 2021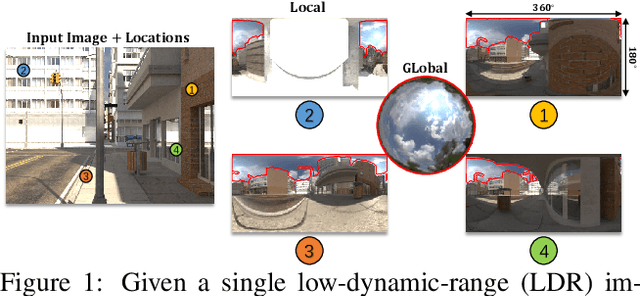
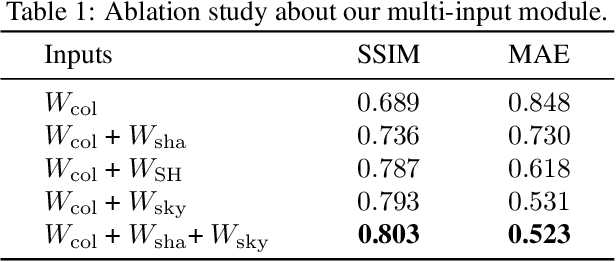
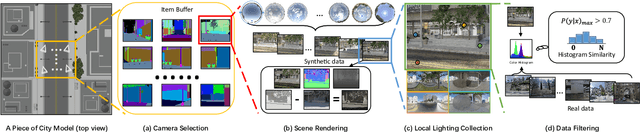
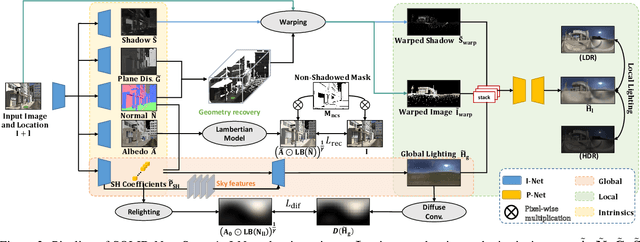
We present SOLID-Net, a neural network for spatially-varying outdoor lighting estimation from a single outdoor image for any 2D pixel location. Previous work has used a unified sky environment map to represent outdoor lighting. Instead, we generate spatially-varying local lighting environment maps by combining global sky environment map with warped image information according to geometric information estimated from intrinsics. As no outdoor dataset with image and local lighting ground truth is readily available, we introduce the SOLID-Img dataset with physically-based rendered images and their corresponding intrinsic and lighting information. We train a deep neural network to regress intrinsic cues with physically-based constraints and use them to conduct global and local lightings estimation. Experiments on both synthetic and real datasets show that SOLID-Net significantly outperforms previous methods.