 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBAGAN-RRT: Convolutional Block Attention Generative Adversarial Network for Sampling-Based Path Planning
May 13, 2023Sampling-based path planning algorithms play an important role in autonomous robotics. However, a common problem among the RRT-based algorithms is that the initial path generated is not optimal and the convergence is too slow to be used in real-world applications. In this paper, we propose a novel image-based learning algorithm (CBAGAN-RRT) using a Convolutional Block Attention Generative Adversarial Network with a combination of spatial and channel attention and a novel loss function to design the heuristics, find a better optimal path, and improve the convergence of the algorithm both concerning time and speed. The probability distribution of the paths generated from our GAN model is used to guide the sampling process for the RRT algorithm. We train and test our network on the dataset generated by \cite{zhang2021generative} and demonstrate that our algorithm outperforms the previous state-of-the-art algorithms using both the image quality generation metrics like IOU Score, Dice Score, FID score, and path planning metrics like time cost and the number of nodes. We conduct detailed experiments and ablation studies to illustrate the feasibility of our study and show that our model performs well not only on the training dataset but also on the unseen test dataset. The advantage of our approach is that we can avoid the complicated preprocessing in the state space, our model can be generalized to complicated environments like those containing turns and narrow passages without loss of accuracy, and our model can be easily integrated with other sampling-based path planning algorithms.
ViTBIS: Vision Transformer for Biomedical Image Segmentation
Jan 15, 2022In this paper, we propose a novel network named Vision Transformer for Biomedical Image Segmentation (ViTBIS). Our network splits the input feature maps into three parts with $1\times 1$, $3\times 3$ and $5\times 5$ convolutions in both encoder and decoder. Concat operator is used to merge the features before being fed to three consecutive transformer blocks with attention mechanism embedded inside it. Skip connections are used to connect encoder and decoder transformer blocks. Similarly, transformer blocks and multi scale architecture is used in decoder before being linearly projected to produce the output segmentation map. We test the performance of our network using Synapse multi-organ segmentation dataset, Automated cardiac diagnosis challenge dataset, Brain tumour MRI segmentation dataset and Spleen CT segmentation dataset. Without bells and whistles, our network outperforms most of the previous state of the art CNN and transformer based models using Dice score and the Hausdorff distance as the evaluation metrics.
* Published at Clinical Image-Based Procedures, Distributed and Collaborative Learning, Artificial Intelligence for Combating COVID-19 and Secure and Privacy-Preserving Machine Learning workshop at MICCAI 2021
AA3DNet: Attention Augmented Real Time 3D Object Detection
Aug 11, 2021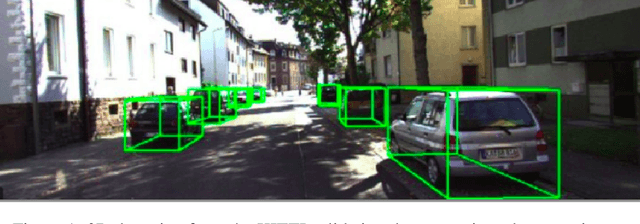
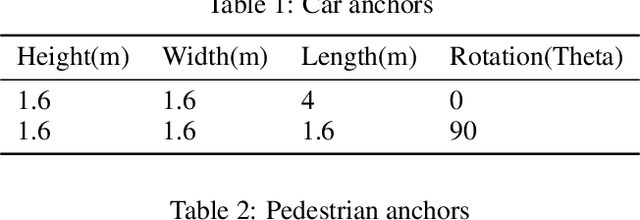
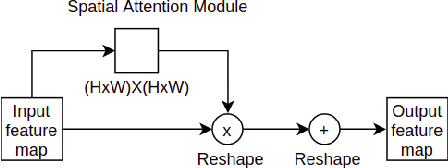
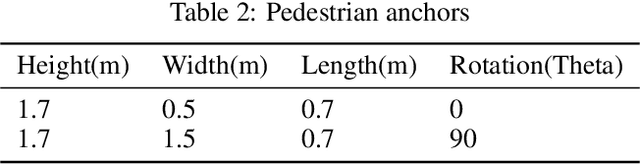
In this work, we address the problem of 3D object detection from point cloud data in real time. For autonomous vehicles to work, it is very important for the perception component to detect the real world objects with both high accuracy and fast inference. We propose a novel neural network architecture along with the training and optimization details for detecting 3D objects using point cloud data. We present anchor design along with custom loss functions used in this work. A combination of spatial and channel wise attention module is used in this work. We use the Kitti 3D Birds Eye View dataset for benchmarking and validating our results. Our method surpasses previous state of the art in this domain both in terms of average precision and speed running at > 30 FPS. Finally, we present the ablation study to demonstrate that the performance of our network is generalizable. This makes it a feasible option to be deployed in real time applications like self driving cars.
AASeg: Attention Aware Network for Real Time Semantic Segmentation
Aug 11, 2021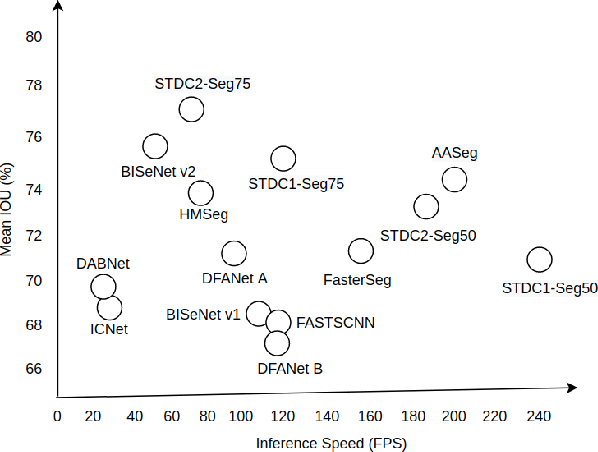
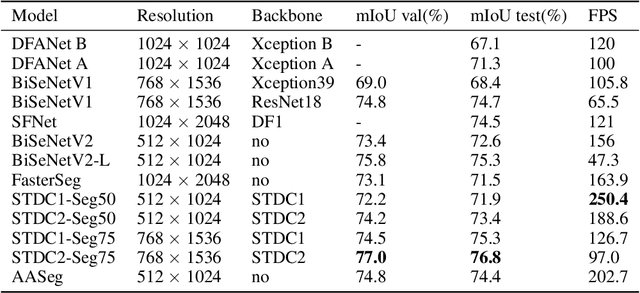
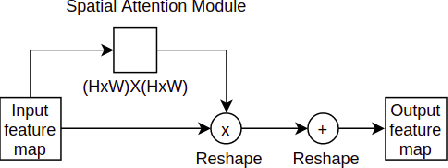
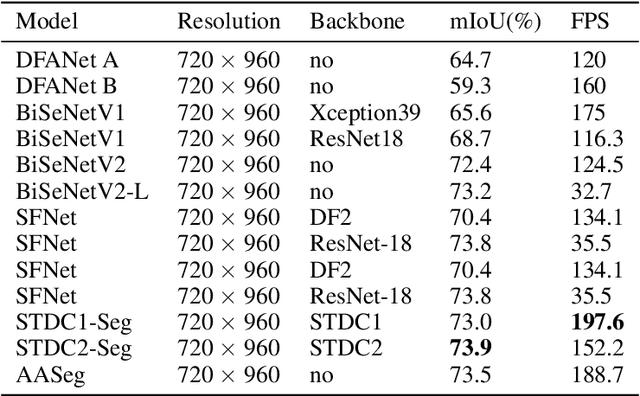
In this paper, we present a new network named Attention Aware Network (AASeg) for real time semantic image segmentation. Our network incorporates spatial and channel information using Spatial Attention (SA) and Channel Attention (CA) modules respectively. It also uses dense local multi-scale context information using Multi Scale Context (MSC) module. The feature maps are concatenated individually to produce the final segmentation map. We demonstrate the effectiveness of our method using a comprehensive analysis, quantitative experimental results and ablation study using Cityscapes, ADE20K and Camvid datasets. Our network performs better than most previous architectures with a 74.4\% Mean IOU on Cityscapes test dataset while running at 202.7 FPS.
DMSANet: Dual Multi Scale Attention Network
Jun 13, 2021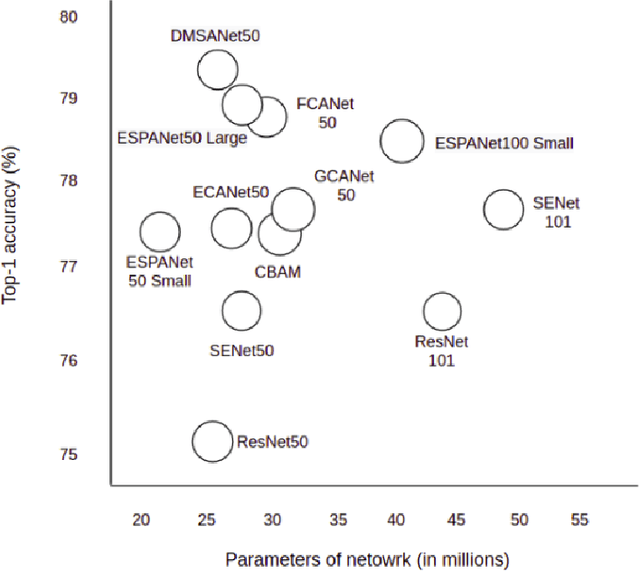
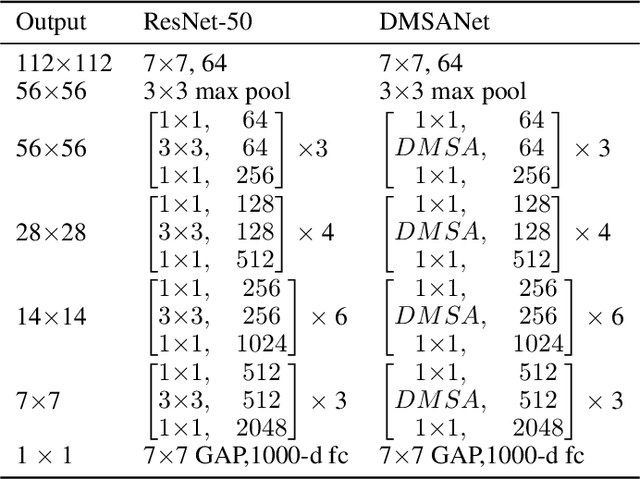
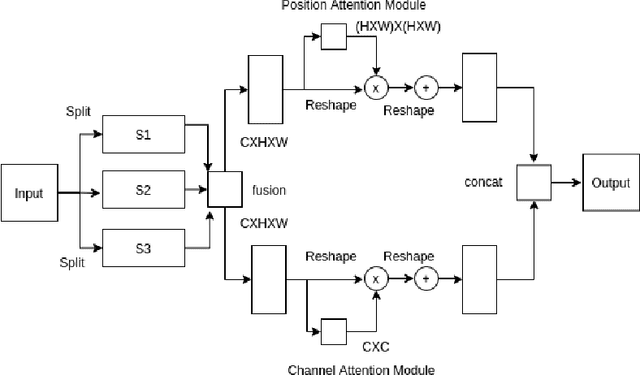
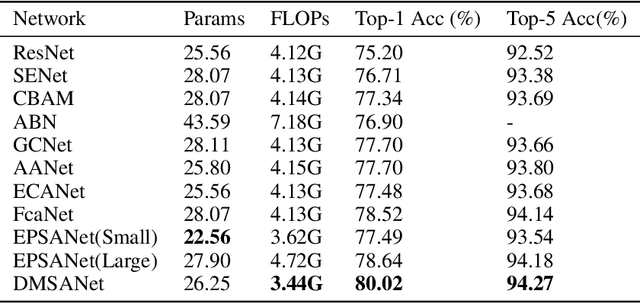
Attention mechanism of late has been quite popular in the computer vision community. A lot of work has been done to improve the performance of the network, although almost always it results in increased computational complexity. In this paper, we propose a new attention module that not only achieves the best performance but also has lesser parameters compared to most existing models. Our attention module can easily be integrated with other convolutional neural networks because of its lightweight nature. The proposed network named Dual Multi Scale Attention Network (DMSANet) is comprised of two parts: the first part is used to extract features at various scales and aggregate them, the second part uses spatial and channel attention modules in parallel to adaptively integrate local features with their global dependencies. We benchmark our network performance for Image Classification on ImageNet dataset, Object Detection and Instance Segmentation both on MS COCO dataset.
Generate Novel Molecules With Target Properties Using Conditional Generative Models
Sep 15, 2020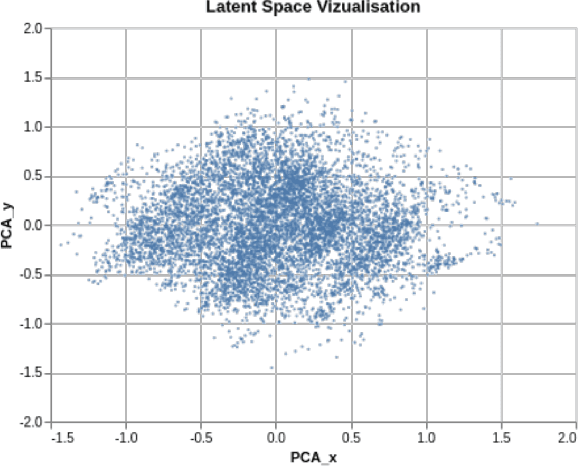
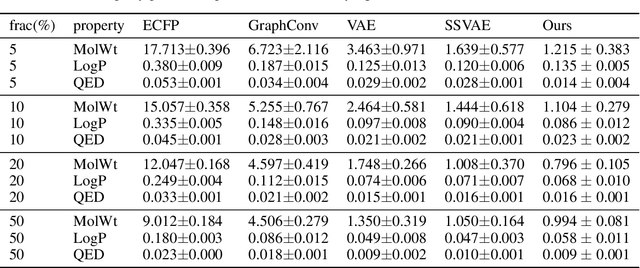
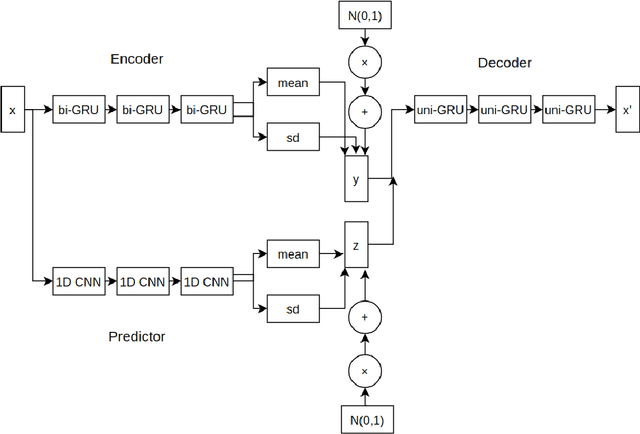
Drug discovery using deep learning has attracted a lot of attention of late as it has obvious advantages like higher efficiency, less manual guessing and faster process time. In this paper, we present a novel neural network for generating small molecules similar to the ones in the training set. Our network consists of an encoder made up of bi-GRU layers for converting the input samples to a latent space, predictor for enhancing the capability of encoder made up of 1D-CNN layers and a decoder comprised of uni-GRU layers for reconstructing the samples from the latent space representation. Condition vector in latent space is used for generating molecules with the desired properties. We present the loss functions used for training our network, experimental details and property prediction metrics. Our network outperforms previous methods using Molecular weight, LogP and Quantitative Estimation of Drug-likeness as the evaluation metrics.
Monocular Depth Estimation Using Multi Scale Neural Network And Feature Fusion
Sep 11, 2020



Depth estimation from monocular images is a challenging problem in computer vision. In this paper, we tackle this problem using a novel network architecture using multi scale feature fusion. Our network uses two different blocks, first which uses different filter sizes for convolution and merges all the individual feature maps. The second block uses dilated convolutions in place of fully connected layers thus reducing computations and increasing the receptive field. We present a new loss function for training the network which uses a depth regression term, SSIM loss term and a multinomial logistic loss term combined. We train and test our network on Make 3D dataset, NYU Depth V2 dataset and Kitti dataset using standard evaluation metrics for depth estimation comprised of RMSE loss and SILog loss. Our network outperforms previous state of the art methods with lesser parameters.
HRVGAN: High Resolution Video Generation using Spatio-Temporal GAN
Aug 17, 2020



In this paper, we present a novel network for high resolution video generation. Our network uses ideas from Wasserstein GANs by enforcing k-Lipschitz constraint on the loss term and Conditional GANs using class labels for training and testing. We present Generator and Discriminator network layerwise details along with the combined network architecture, optimization details and algorithm used in this work. Our network uses a combination of two loss terms: mean square pixel loss and an adversarial loss. The datasets used for training and testing our network are UCF101, Golf and Aeroplane Datasets. Using Inception Score and Fr\'echet Inception Distance as the evaluation metrics, our network outperforms previous state of the art networks on unsupervised video generation.
Generate High Resolution Images With Generative Variational Autoencoder
Aug 12, 2020
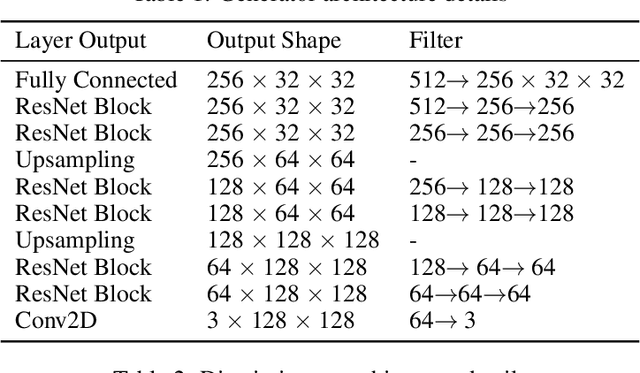
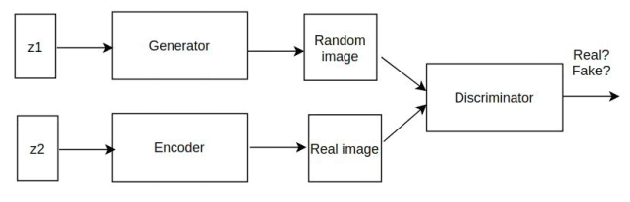
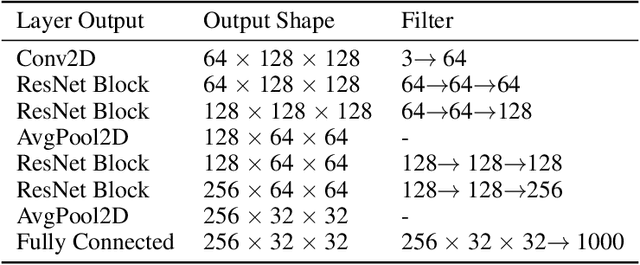
In this work, we present a novel neural network to generate high resolution images. We replace the decoder of VAE with a discriminator while using the encoder as it is. The encoder uses data from a normal distribution while the generator from a gaussian distribution. The combination from both is given to a discriminator which tells whether the generated images are correct or not. We evaluate our network on 3 different datasets: MNIST, LSUN and CelebA-HQ dataset. Our network beats the previous state of the art using MMD, SSIM, log likelihood, reconstruction error, ELBO and KL divergence as the evaluation metrics while generating much sharper images. This work is potentially very exciting as we are able to combine the advantages of generative models and inference models in a principled bayesian manner.
Uncertainty Quantification using Variational Inference for Biomedical Image Segmentation
Aug 12, 2020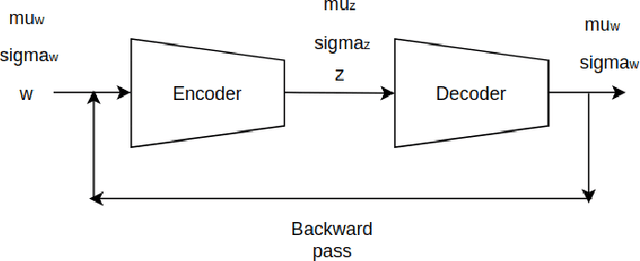
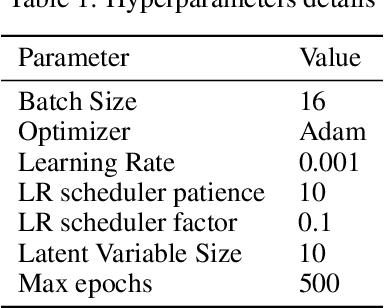
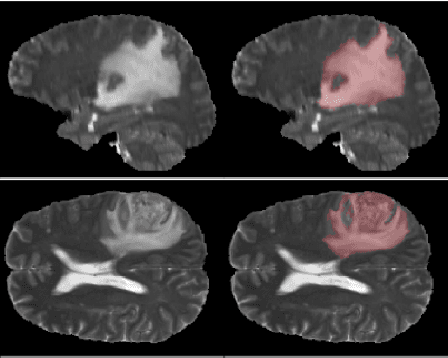
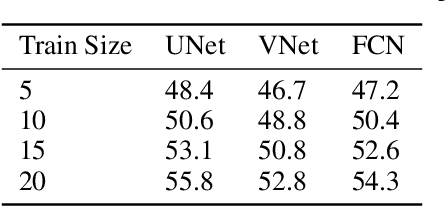
Deep learning motivated by convolutional neural networks has been highly successful in a range of medical imaging problems like image classification, image segmentation, image synthesis etc. However for validation and interpretability, not only do we need the predictions made by the model but also how confident it is while making those predictions. This is important in safety critical applications for the people to accept it. In this work, we used an encoder decoder architecture based on variational inference techniques for segmenting brain tumour images. We compare different backbones architectures like U-Net, V-Net and FCN as sampling data from the conditional distribution for the encoder. We evaluate our work on the publicly available BRATS dataset using Dice Similarity Coefficient (DSC) and Intersection Over Union (IOU) as the evaluation metrics. Our model outperforms previous state of the art results while making use of uncertainty quantification in a principled bayesian manner.