 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Low-Light Maritime Image Enhancement with Regularized Illumination Optimization and Deep Noise Suppression
Aug 09, 2020
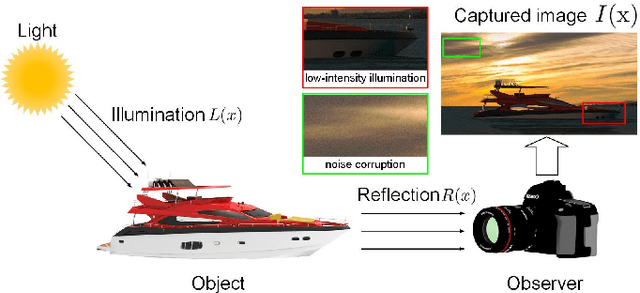



Maritime images captured under low-light imaging condition easily suffer from low visibility and unexpected noise, leading to negative effects on maritime traffic supervision and management. To promote imaging performance, it is necessary to restore the important visual information from degraded low-light images. In this paper, we propose to enhance the low-light images through regularized illumination optimization and deep noise suppression. In particular, a hybrid regularized variational model, which combines L0-norm gradient sparsity prior with structure-aware regularization, is presented to refine the coarse illumination map originally estimated using Max-RGB. The adaptive gamma correction method is then introduced to adjust the refined illumination map. Based on the assumption of Retinex theory, a guided filter-based detail boosting method is introduced to optimize the reflection map. The adjusted illumination and optimized reflection maps are finally combined to generate the enhanced maritime images. To suppress the effect of unwanted noise on imaging performance, a deep learning-based blind denoising framework is further introduced to promote the visual quality of enhanced image. In particular, this framework is composed of two sub-networks, i.e., E-Net and D-Net adopted for noise level estimation and non-blind noise reduction, respectively. The main benefit of our image enhancement method is that it takes full advantage of the regularized illumination optimization and deep blind denoising. Comprehensive experiments have been conducted on both synthetic and realistic maritime images to compare our proposed method with several state-of-the-art imaging methods. Experimental results have illustrated its superior performance in terms of both quantitative and qualitative evaluations.
MPI: Multi-receptive and Parallel Integration for Salient Object Detection
Aug 08, 2021
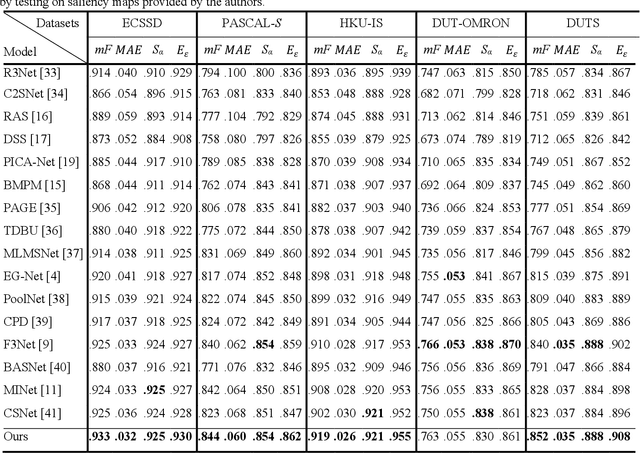
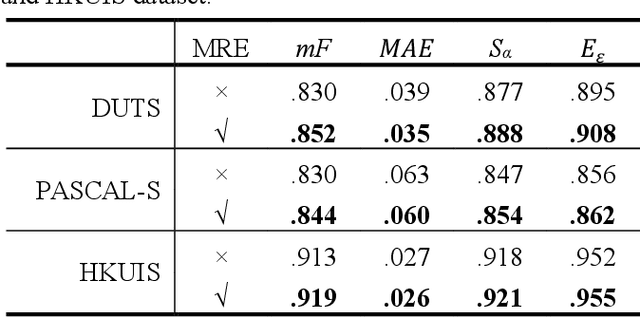
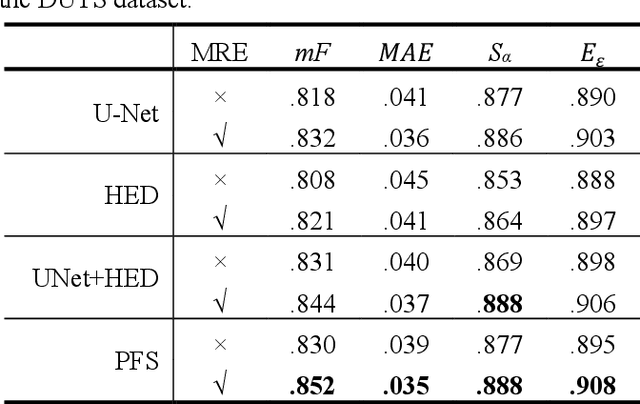
The semantic representation of deep features is essential for image context understanding, and effective fusion of features with different semantic representations can significantly improve the model's performance on salient object detection. In this paper, a novel method called MPI is proposed for salient object detection. Firstly, a multi-receptive enhancement module (MRE) is designed to effectively expand the receptive fields of features from different layers and generate features with different receptive fields. MRE can enhance the semantic representation and improve the model's perception of the image context, which enables the model to locate the salient object accurately. Secondly, in order to reduce the reuse of redundant information in the complex top-down fusion method and weaken the differences between semantic features, a relatively simple but effective parallel fusion strategy (PFS) is proposed. It allows multi-scale features to better interact with each other, thus improving the overall performance of the model. Experimental results on multiple datasets demonstrate that the proposed method outperforms state-of-the-art methods under different evaluation metrics.
Geodesic Density Regression for Correcting 4DCT Pulmonary Respiratory Motion Artifacts
Jun 12, 2021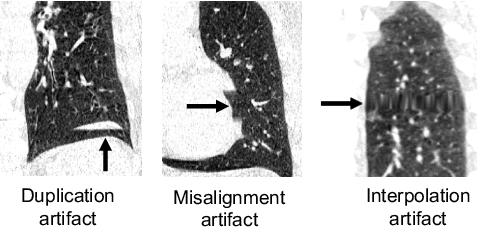
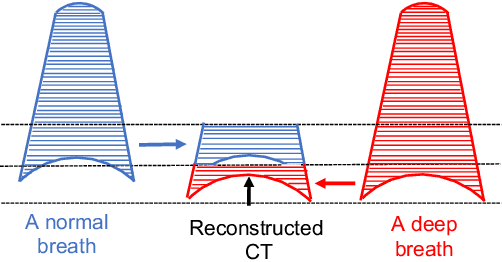
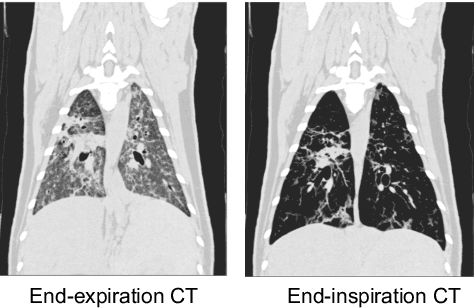
Pulmonary respiratory motion artifacts are common in four-dimensional computed tomography (4DCT) of lungs and are caused by missing, duplicated, and misaligned image data. This paper presents a geodesic density regression (GDR) algorithm to correct motion artifacts in 4DCT by correcting artifacts in one breathing phase with artifact-free data from corresponding regions of other breathing phases. The GDR algorithm estimates an artifact-free lung template image and a smooth, dense, 4D (space plus time) vector field that deforms the template image to each breathing phase to produce an artifact-free 4DCT scan. Correspondences are estimated by accounting for the local tissue density change associated with air entering and leaving the lungs, and using binary artifact masks to exclude regions with artifacts from image regression. The artifact-free lung template image is generated by mapping the artifact-free regions of each phase volume to a common reference coordinate system using the estimated correspondences and then averaging. This procedure generates a fixed view of the lung with an improved signal-to-noise ratio. The GDR algorithm was evaluated and compared to a state-of-the-art geodesic intensity regression (GIR) algorithm using simulated CT time-series and 4DCT scans with clinically observed motion artifacts. The simulation shows that the GDR algorithm has achieved significantly more accurate Jacobian images and sharper template images, and is less sensitive to data dropout than the GIR algorithm. We also demonstrate that the GDR algorithm is more effective than the GIR algorithm for removing clinically observed motion artifacts in treatment planning 4DCT scans. Our code is freely available at https://github.com/Wei-Shao-Reg/GDR.
TUCaN: Progressively Teaching Colourisation to Capsules
Jun 29, 2021

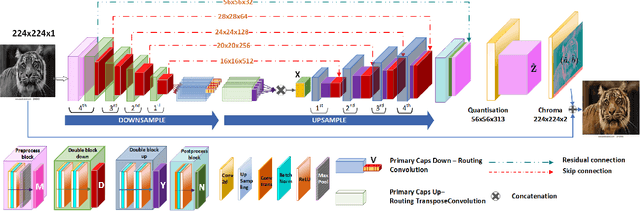
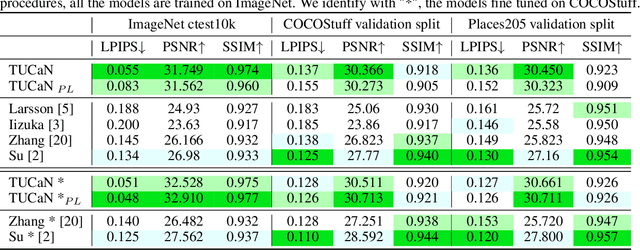
Automatic image colourisation is the computer vision research path that studies how to colourise greyscale images (for restoration). Deep learning techniques improved image colourisation yielding astonishing results. These differ by various factors, such as structural differences, input types, user assistance, etc. Most of them, base the architectural structure on convolutional layers with no emphasis on layers specialised in object features extraction. We introduce a novel downsampling upsampling architecture named TUCaN (Tiny UCapsNet) that exploits the collaboration of convolutional layers and capsule layers to obtain a neat colourisation of entities present in every single image. This is obtained by enforcing collaboration among such layers by skip and residual connections. We pose the problem as a per pixel colour classification task that identifies colours as a bin in a quantized space. To train the network, in contrast with the standard end to end learning method, we propose the progressive learning scheme to extract the context of objects by only manipulating the learning process without changing the model. In this scheme, the upsampling starts from the reconstruction of low resolution images and progressively grows to high resolution images throughout the training phase. Experimental results on three benchmark datasets show that our approach with ImageNet10k dataset outperforms existing methods on standard quality metrics and achieves state of the art performances on image colourisation. We performed a user study to quantify the perceptual realism of the colourisation results demonstrating: that progressive learning let the TUCaN achieve better colours than the end to end scheme; and pointing out the limitations of the existing evaluation metrics.
Addressing out-of-distribution label noise in webly-labelled data
Oct 26, 2021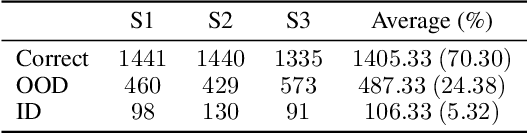
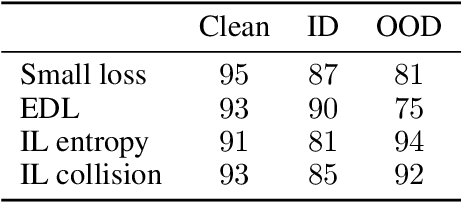
A recurring focus of the deep learning community is towards reducing the labeling effort. Data gathering and annotation using a search engine is a simple alternative to generating a fully human-annotated and human-gathered dataset. Although web crawling is very time efficient, some of the retrieved images are unavoidably noisy, i.e. incorrectly labeled. Designing robust algorithms for training on noisy data gathered from the web is an important research perspective that would render the building of datasets easier. In this paper we conduct a study to understand the type of label noise to expect when building a dataset using a search engine. We review the current limitations of state-of-the-art methods for dealing with noisy labels for image classification tasks in the case of web noise distribution. We propose a simple solution to bridge the gap with a fully clean dataset using Dynamic Softening of Out-of-distribution Samples (DSOS), which we design on corrupted versions of the CIFAR-100 dataset, and compare against state-of-the-art algorithms on the web noise perturbated MiniImageNet and Stanford datasets and on real label noise datasets: WebVision 1.0 and Clothing1M. Our work is fully reproducible https://git.io/JKGcj
Cryo-shift: Reducing domain shift in cryo-electron subtomograms with unsupervised domain adaptation and randomization
Nov 17, 2021

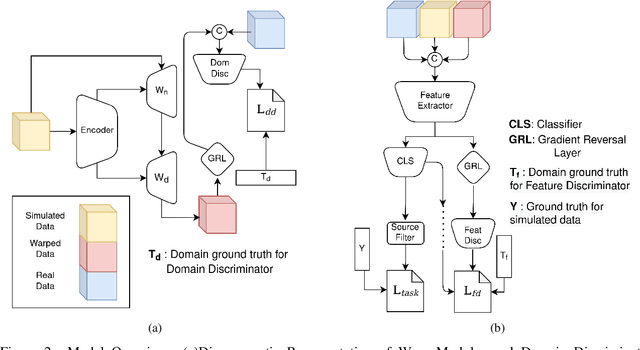

Cryo-Electron Tomography (cryo-ET) is a 3D imaging technology that enables the visualization of subcellular structures in situ at near-atomic resolution. Cellular cryo-ET images help in resolving the structures of macromolecules and determining their spatial relationship in a single cell, which has broad significance in cell and structural biology. Subtomogram classification and recognition constitute a primary step in the systematic recovery of these macromolecular structures. Supervised deep learning methods have been proven to be highly accurate and efficient for subtomogram classification, but suffer from limited applicability due to scarcity of annotated data. While generating simulated data for training supervised models is a potential solution, a sizeable difference in the image intensity distribution in generated data as compared to real experimental data will cause the trained models to perform poorly in predicting classes on real subtomograms. In this work, we present Cryo-Shift, a fully unsupervised domain adaptation and randomization framework for deep learning-based cross-domain subtomogram classification. We use unsupervised multi-adversarial domain adaption to reduce the domain shift between features of simulated and experimental data. We develop a network-driven domain randomization procedure with `warp' modules to alter the simulated data and help the classifier generalize better on experimental data. We do not use any labeled experimental data to train our model, whereas some of the existing alternative approaches require labeled experimental samples for cross-domain classification. Nevertheless, Cryo-Shift outperforms the existing alternative approaches in cross-domain subtomogram classification in extensive evaluation studies demonstrated herein using both simulated and experimental data.
* 14 pages
M5Product: A Multi-modal Pretraining Benchmark for E-commercial Product Downstream Tasks
Sep 09, 2021
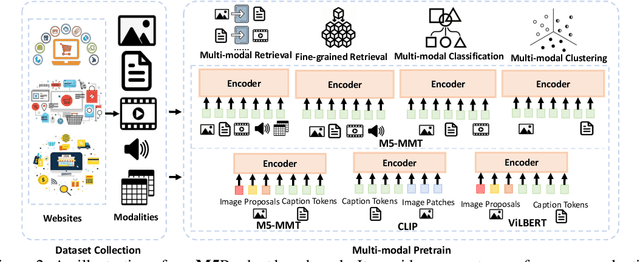
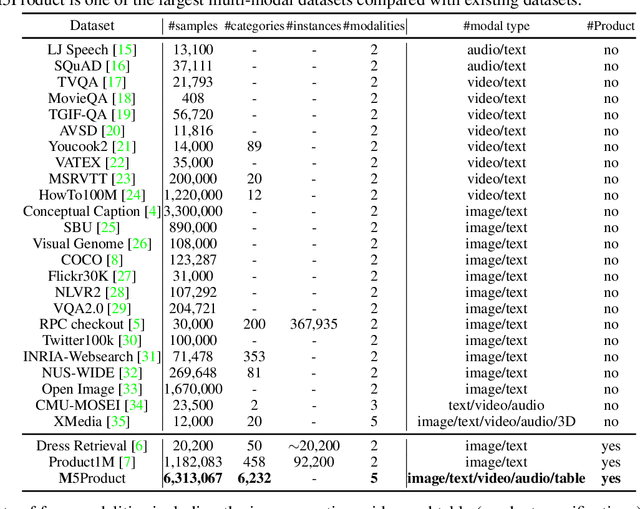
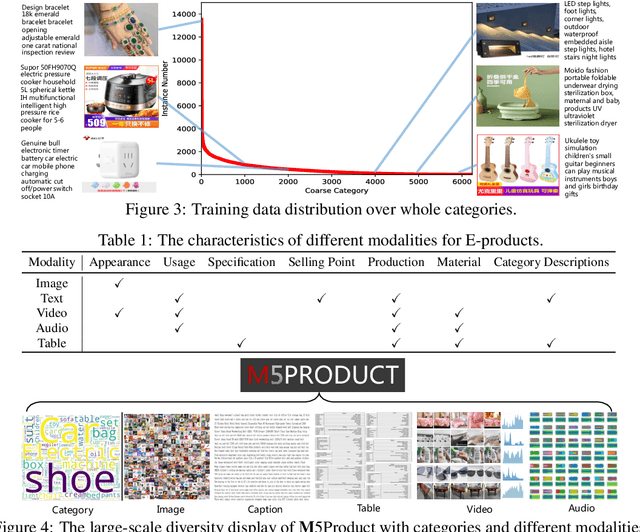
In this paper, we aim to advance the research of multi-modal pre-training on E-commerce and subsequently contribute a large-scale dataset, named M5Product, which consists of over 6 million multimodal pairs, covering more than 6,000 categories and 5,000 attributes. Generally, existing multi-modal datasets are either limited in scale or modality diversity. Differently, our M5Product is featured from the following aspects. First, the M5Product dataset is 500 times larger than the public multimodal dataset with the same number of modalities and nearly twice larger compared with the largest available text-image cross-modal dataset. Second, the dataset contains rich information of multiple modalities including image, text, table, video and audio, in which each modality can capture different views of semantic information (e.g. category, attributes, affordance, brand, preference) and complements the other. Third, to better accommodate with real-world problems, a few portion of M5Product contains incomplete modality pairs and noises while having the long-tailed distribution, which aligns well with real-world scenarios. Finally, we provide a baseline model M5-MMT that makes the first attempt to integrate the different modality configuration into an unified model for feature fusion to address the great challenge for semantic alignment. We also evaluate various multi-model pre-training state-of-the-arts for benchmarking their capabilities in learning from unlabeled data under the different number of modalities on the M5Product dataset. We conduct extensive experiments on four downstream tasks and provide some interesting findings on these modalities. Our dataset and related code are available at https://xiaodongsuper.github.io/M5Product_dataset.
A Precision Diagnostic Framework of Renal Cell Carcinoma on Whole-Slide Images using Deep Learning
Oct 26, 2021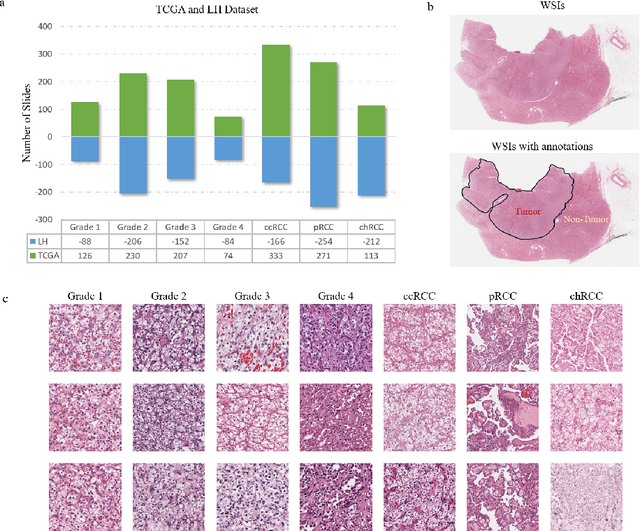
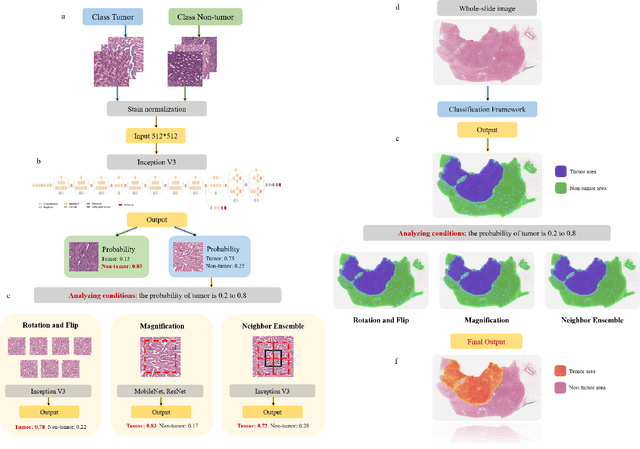
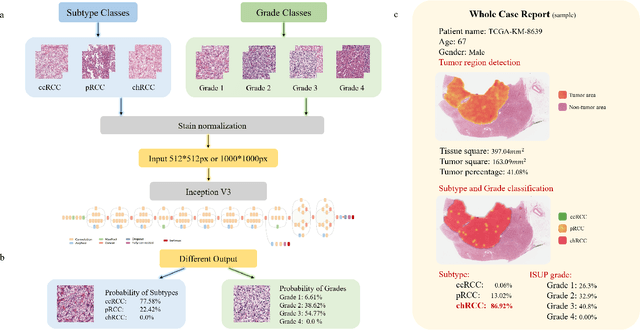
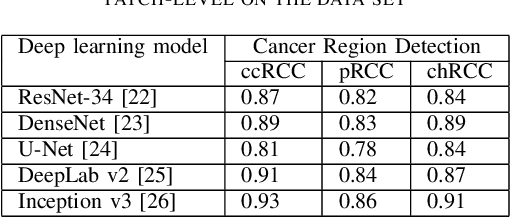
Diagnostic pathology, which is the basis and gold standard of cancer diagnosis, provides essential information on the prognosis of the disease and vital evidence for clinical treatment. Tumor region detection, subtype and grade classification are the fundamental diagnostic indicators for renal cell carcinoma (RCC) in whole-slide images (WSIs). However, pathological diagnosis is subjective, differences in observation and diagnosis between pathologists is common in hospitals with inadequate diagnostic capacity. The main challenge for developing deep learning based RCC diagnostic system is the lack of large-scale datasets with precise annotations. In this work, we proposed a deep learning-based framework for analyzing histopathological images of patients with renal cell carcinoma, which has the potential to achieve pathologist-level accuracy in diagnosis. A deep convolutional neural network (InceptionV3) was trained on the high-quality annotated dataset of The Cancer Genome Atlas (TCGA) whole-slide histopathological image for accurate tumor area detection, classification of RCC subtypes, and ISUP grades classification of clear cell carcinoma subtypes. These results suggest that our framework can help pathologists in the detection of cancer region and classification of subtypes and grades, which could be applied to any cancer type, providing auxiliary diagnosis and promoting clinical consensus.
Hepatic vessel segmentation based on 3D swin-transformer with inductive biased multi-head self-attention
Nov 22, 2021
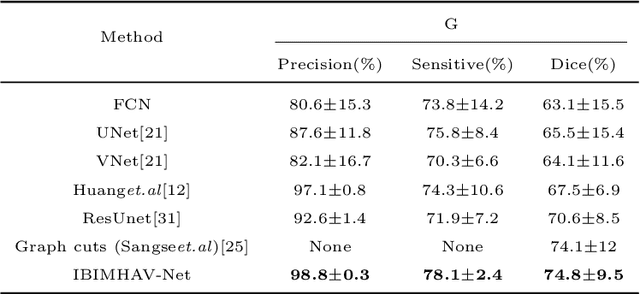
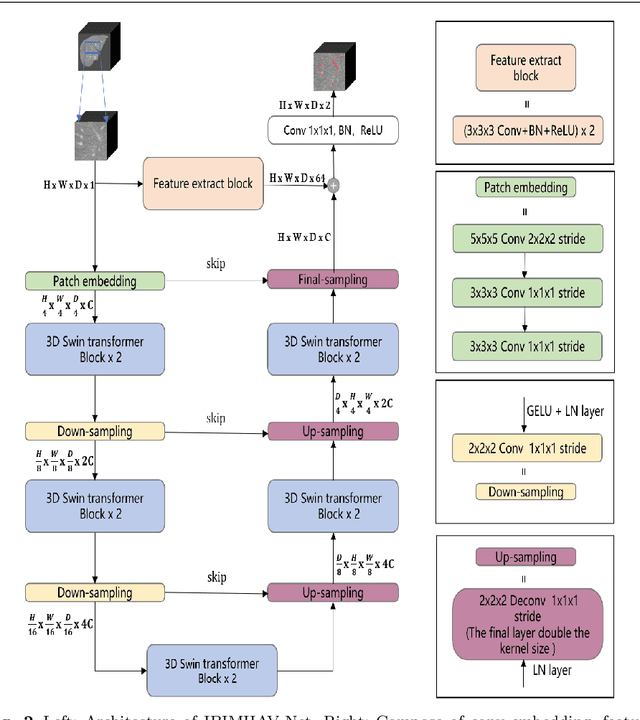
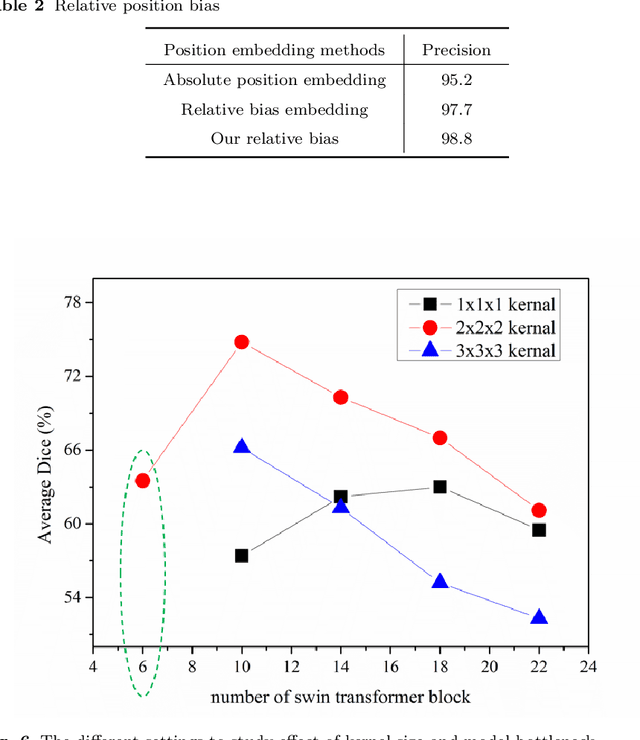
Purpose: Segmentation of liver vessels from CT images is indispensable prior to surgical planning and aroused broad range of interests in the medical image analysis community. Due to the complex structure and low contrast background, automatic liver vessel segmentation remains particularly challenging. Most of the related researches adopt FCN, U-net, and V-net variants as a backbone. However, these methods mainly focus on capturing multi-scale local features which may produce misclassified voxels due to the convolutional operator's limited locality reception field. Methods: We propose a robust end-to-end vessel segmentation network called Inductive BIased Multi-Head Attention Vessel Net(IBIMHAV-Net) by expanding swin transformer to 3D and employing an effective combination of convolution and self-attention. In practice, we introduce the voxel-wise embedding rather than patch-wise embedding to locate precise liver vessel voxels, and adopt multi-scale convolutional operators to gain local spatial information. On the other hand, we propose the inductive biased multi-head self-attention which learns inductive biased relative positional embedding from initialized absolute position embedding. Based on this, we can gain a more reliable query and key matrix. To validate the generalization of our model, we test on samples which have different structural complexity. Results: We conducted experiments on the 3DIRCADb datasets. The average dice and sensitivity of the four tested cases were 74.8% and 77.5%, which exceed results of existing deep learning methods and improved graph cuts method. Conclusion: The proposed model IBIMHAV-Net provides an automatic, accurate 3D liver vessel segmentation with an interleaved architecture that better utilizes both global and local spatial features in CT volumes. It can be further extended for other clinical data.
Semantic Diversity Learning for Zero-Shot Multi-label Classification
May 12, 2021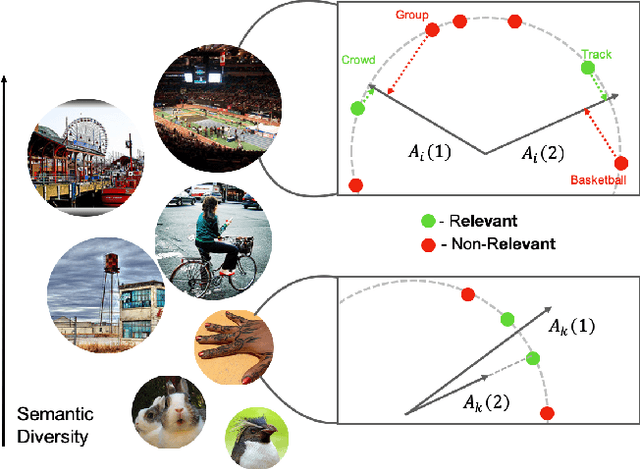
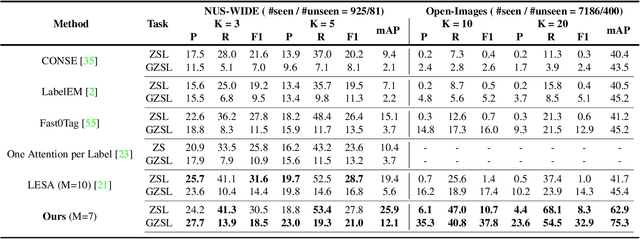
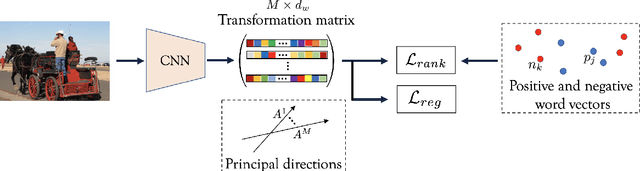
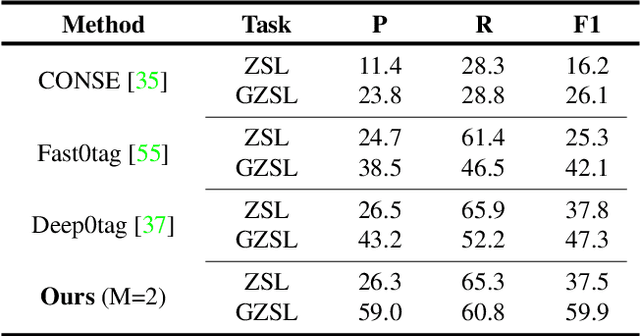
Training a neural network model for recognizing multiple labels associated with an image, including identifying unseen labels, is challenging, especially for images that portray numerous semantically diverse labels. As challenging as this task is, it is an essential task to tackle since it represents many real-world cases, such as image retrieval of natural images. We argue that using a single embedding vector to represent an image, as commonly practiced, is not sufficient to rank both relevant seen and unseen labels accurately. This study introduces an end-to-end model training for multi-label zero-shot learning that supports semantic diversity of the images and labels. We propose to use an embedding matrix having principal embedding vectors trained using a tailored loss function. In addition, during training, we suggest up-weighting in the loss function image samples presenting higher semantic diversity to encourage the diversity of the embedding matrix. Extensive experiments show that our proposed method improves the zero-shot model's quality in tag-based image retrieval achieving SoTA results on several common datasets (NUS-Wide, COCO, Open Images).