 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RP2K: A Large-Scale Retail Product Dataset for Fine-Grained Image Classification
Jun 22, 2020

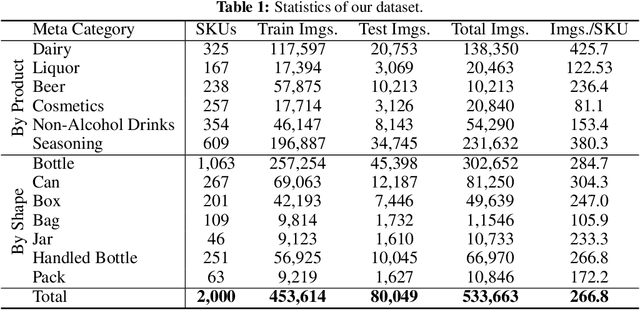
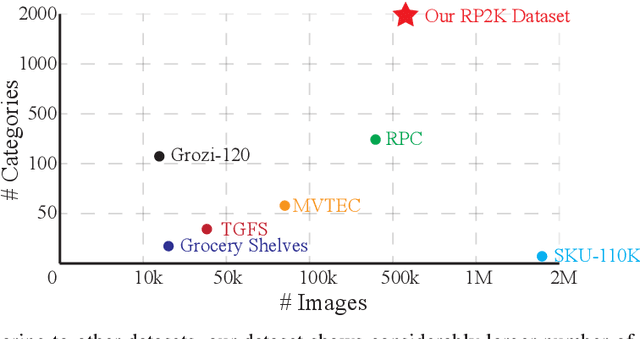
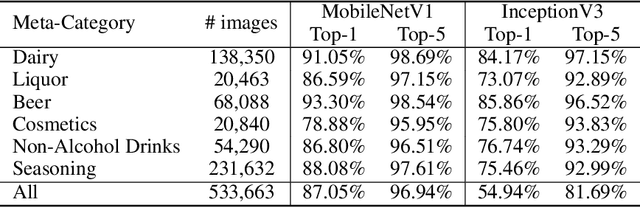
We introduce RP2K, a new large-scale retail product dataset for fine-grained image classification. Unlike previous datasets focusing on relatively few products, we collect more than 500,000 images of retail products on shelves belonging to 2000 different products. Our dataset aims to advance the research in retail object recognition, which has massive applications such as automatic shelf auditing and image-based product information retrieval. Our dataset enjoys following properties: (1) It is by far the largest scale dataset in terms of product categories. (2) All images are captured manually in physical retail stores with natural lightings, matching the scenario of real applications. (3) We provide rich annotations to each object, including the sizes, shapes and flavors/scents. We believe our dataset could benefit both computer vision research and retail industry.
Multi-Modal MRI Reconstruction with Spatial Alignment Network
Aug 12, 2021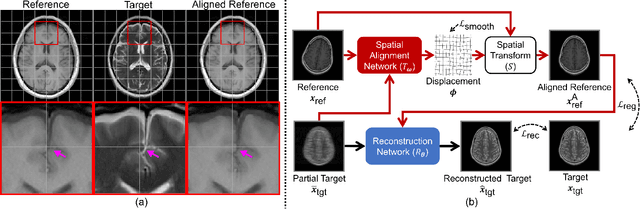
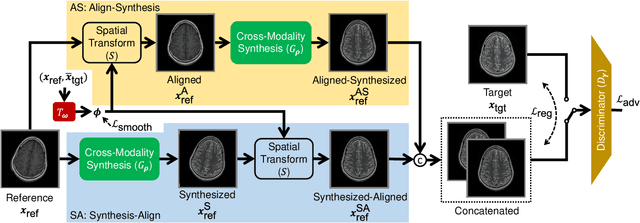

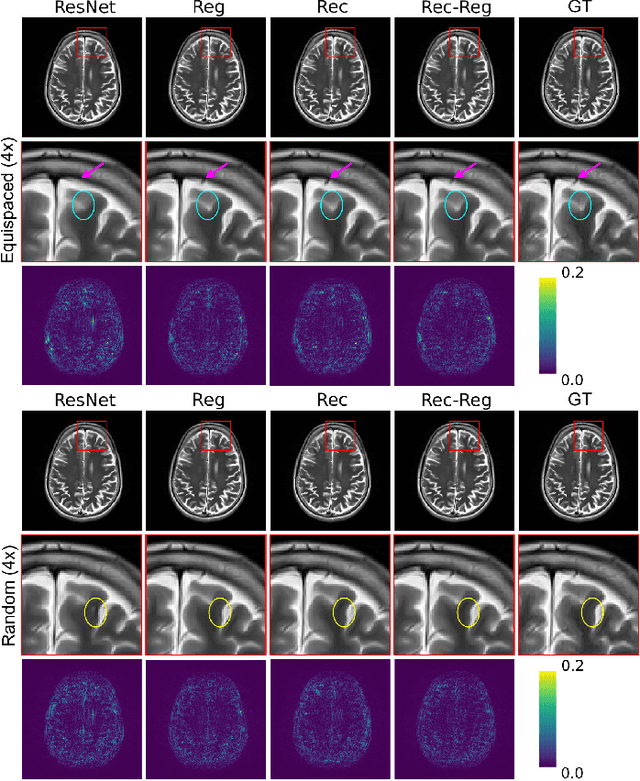
In clinical practice, magnetic resonance imaging (MRI) with multiple contrasts is usually acquired in a single study to assess different properties of the same region of interest in human body. The whole acquisition process can be accelerated by having one or more modalities under-sampled in the k-space. Recent researches demonstrate that, considering the redundancy between different contrasts or modalities, a target MRI modality under-sampled in the k-space can be better reconstructed with the helps from a fully-sampled sequence (i.e., the reference modality). It implies that, in the same study of the same subject, multiple sequences can be utilized together toward the purpose of highly efficient multi-modal reconstruction. However, we find that multi-modal reconstruction can be negatively affected by subtle spatial misalignment between different sequences, which is actually common in clinical practice. In this paper, we integrate the spatial alignment network with reconstruction, to improve the quality of the reconstructed target modality. Specifically, the spatial alignment network estimates the spatial misalignment between the fully-sampled reference and the under-sampled target images, and warps the reference image accordingly. Then, the aligned fully-sampled reference image joins the under-sampled target image in the reconstruction network, to produce the high-quality target image. Considering the contrast difference between the target and the reference, we particularly design the cross-modality-synthesis-based registration loss, in combination with the reconstruction loss, to jointly train the spatial alignment network and the reconstruction network. Our experiments on both clinical MRI and multi-coil k-space raw data demonstrate the superiority and robustness of our spatial alignment network. Code is publicly available at https://github.com/woxuankai/SpatialAlignmentNetwork.
Learning a self-supervised tone mapping operator via feature contrast masking loss
Oct 19, 2021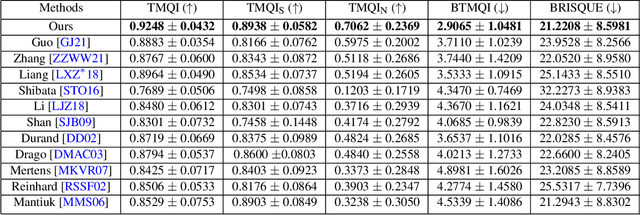
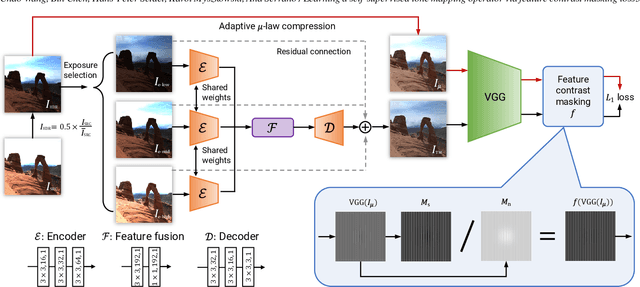

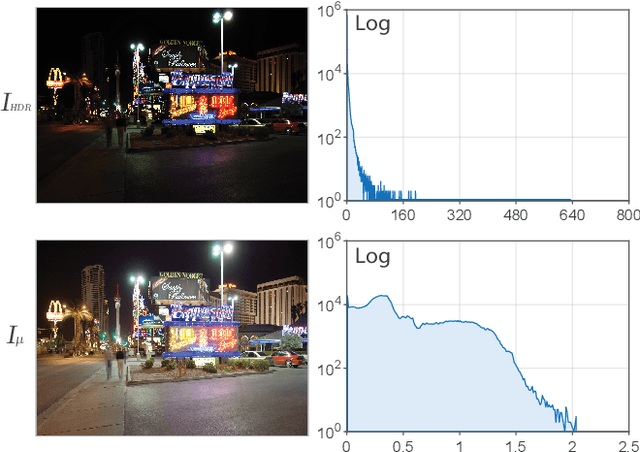
High Dynamic Range (HDR) content is becoming ubiquitous due to the rapid development of capture technologies. Nevertheless, the dynamic range of common display devices is still limited, therefore tone mapping (TM) remains a key challenge for image visualization. Recent work has demonstrated that neural networks can achieve remarkable performance in this task when compared to traditional methods, however, the quality of the results of these learning-based methods is limited by the training data. Most existing works use as training set a curated selection of best-performing results from existing traditional tone mapping operators (often guided by a quality metric), therefore, the quality of newly generated results is fundamentally limited by the performance of such operators. This quality might be even further limited by the pool of HDR content that is used for training. In this work we propose a learning-based self-supervised tone mapping operator that is trained at test time specifically for each HDR image and does not need any data labeling. The key novelty of our approach is a carefully designed loss function built upon fundamental knowledge on contrast perception that allows for directly comparing the content in the HDR and tone mapped images. We achieve this goal by reformulating classic VGG feature maps into feature contrast maps that normalize local feature differences by their average magnitude in a local neighborhood, allowing our loss to account for contrast masking effects. We perform extensive ablation studies and exploration of parameters and demonstrate that our solution outperforms existing approaches with a single set of fixed parameters, as confirmed by both objective and subjective metrics.
Detection of Large Vessel Occlusions using Deep Learning by Deforming Vessel Tree Segmentations
Dec 03, 2021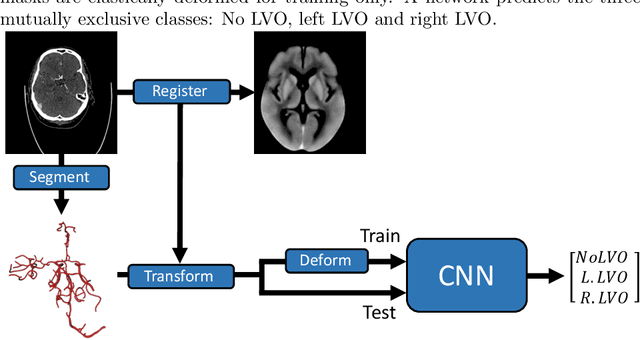
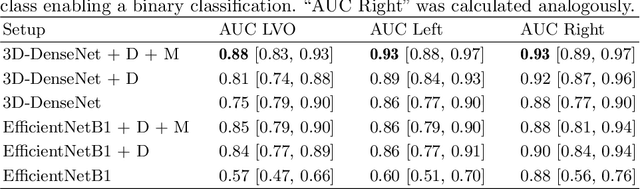
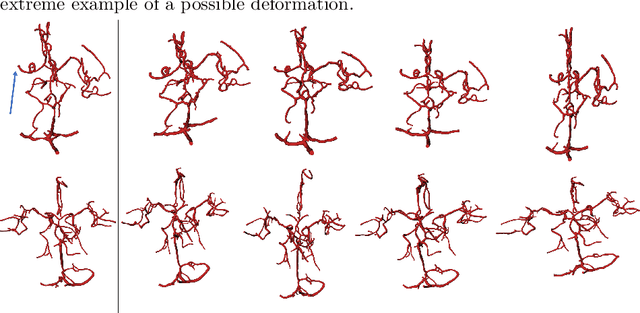
Computed Tomography Angiography is a key modality providing insights into the cerebrovascular vessel tree that are crucial for the diagnosis and treatment of ischemic strokes, in particular in cases of large vessel occlusions (LVO). Thus, the clinical workflow greatly benefits from an automated detection of patients suffering from LVOs. This work uses convolutional neural networks for case-level classification trained with elastic deformation of the vessel tree segmentation masks to artificially augment training data. Using only masks as the input to our model uniquely allows us to apply such deformations much more aggressively than one could with conventional image volumes while retaining sample realism. The neural network classifies the presence of an LVO and the affected hemisphere. In a 5-fold cross validated ablation study, we demonstrate that the use of the suggested augmentation enables us to train robust models even from few data sets. Training the EfficientNetB1 architecture on 100 data sets, the proposed augmentation scheme was able to raise the ROC AUC to 0.85 from a baseline value of 0.57 using no augmentation. The best performance was achieved using a 3D-DenseNet yielding an AUC of 0.88. The augmentation had positive impact in classification of the affected hemisphere as well, where the 3D-DenseNet reached an AUC of 0.93 on both sides.
Detect Faces Efficiently: A Survey and Evaluations
Dec 03, 2021
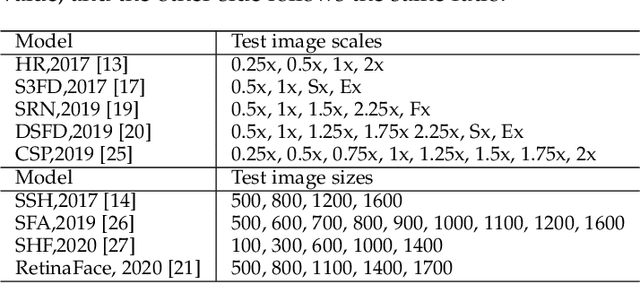
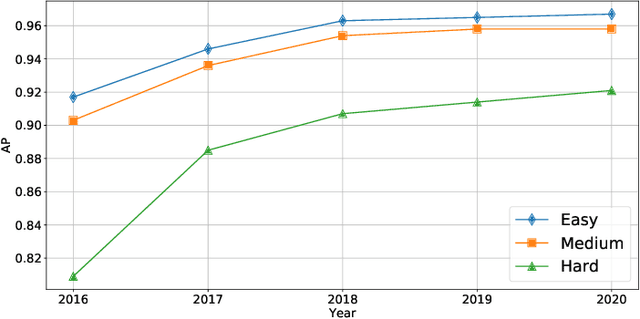
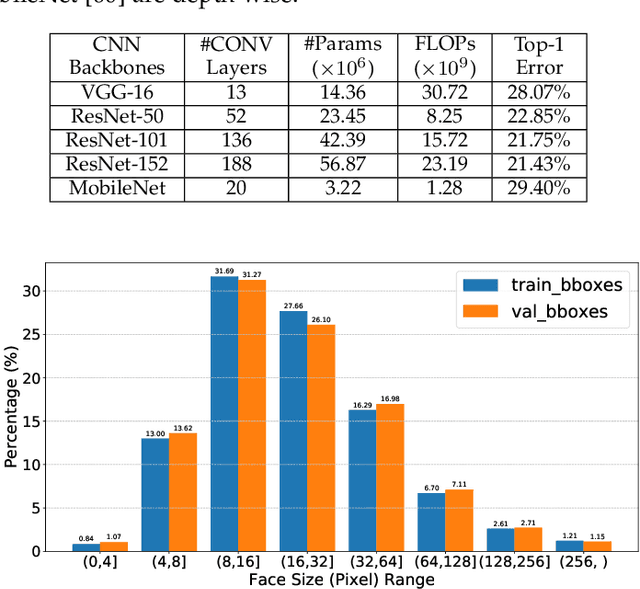
Face detection is to search all the possible regions for faces in images and locate the faces if there are any. Many applications including face recognition, facial expression recognition, face tracking and head-pose estimation assume that both the location and the size of faces are known in the image. In recent decades, researchers have created many typical and efficient face detectors from the Viola-Jones face detector to current CNN-based ones. However, with the tremendous increase in images and videos with variations in face scale, appearance, expression, occlusion and pose, traditional face detectors are challenged to detect various "in the wild" faces. The emergence of deep learning techniques brought remarkable breakthroughs to face detection along with the price of a considerable increase in computation. This paper introduces representative deep learning-based methods and presents a deep and thorough analysis in terms of accuracy and efficiency. We further compare and discuss the popular and challenging datasets and their evaluation metrics. A comprehensive comparison of several successful deep learning-based face detectors is conducted to uncover their efficiency using two metrics: FLOPs and latency. The paper can guide to choose appropriate face detectors for different applications and also to develop more efficient and accurate detectors.
On the Role of Receptive Field in Unsupervised Sim-to-Real Image Translation
Jan 25, 2020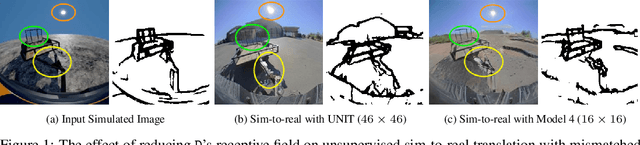
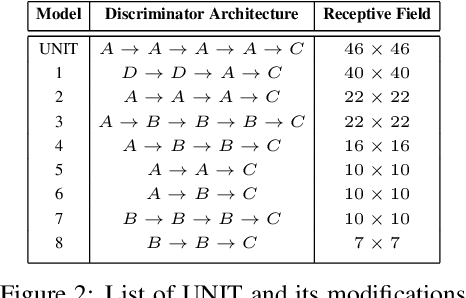
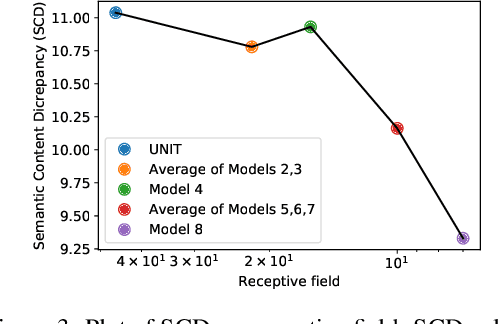

Generative Adversarial Networks (GANs) are now widely used for photo-realistic image synthesis. In applications where a simulated image needs to be translated into a realistic image (sim-to-real), GANs trained on unpaired data from the two domains are susceptible to failure in semantic content retention as the image is translated from one domain to the other. This failure mode is more pronounced in cases where the real data lacks content diversity, resulting in a content \emph{mismatch} between the two domains - a situation often encountered in real-world deployment. In this paper, we investigate the role of the discriminator's receptive field in GANs for unsupervised image-to-image translation with mismatched data, and study its effect on semantic content retention. Experiments with the discriminator architecture of a state-of-the-art coupled Variational Auto-Encoder (VAE) - GAN model on diverse, mismatched datasets show that the discriminator receptive field is directly correlated with semantic content discrepancy of the generated image.
Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks
Dec 03, 2021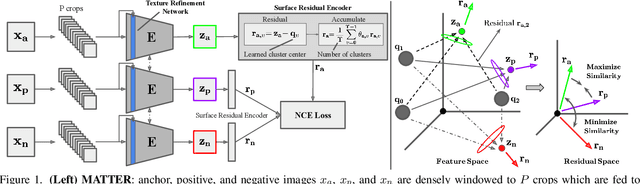
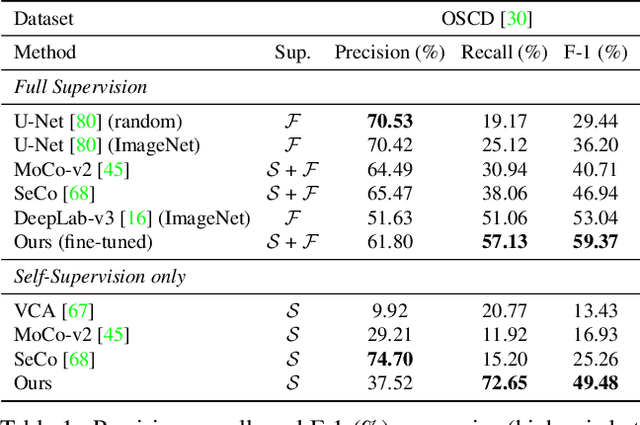
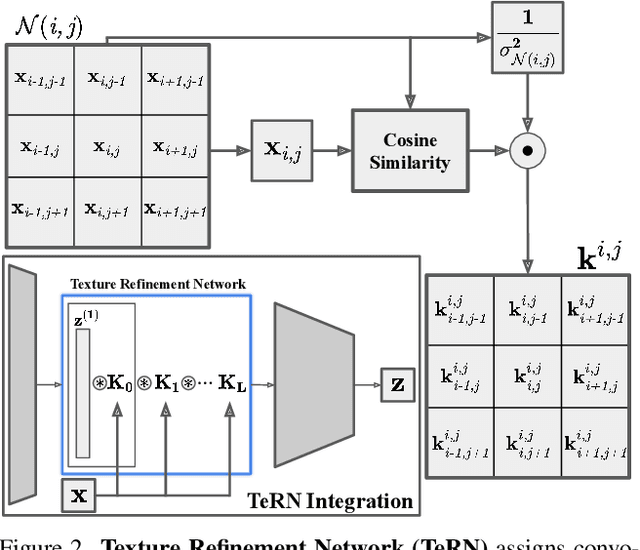

Self-supervised learning aims to learn image feature representations without the usage of manually annotated labels. It is often used as a precursor step to obtain useful initial network weights which contribute to faster convergence and superior performance of downstream tasks. While self-supervision allows one to reduce the domain gap between supervised and unsupervised learning without the usage of labels, the self-supervised objective still requires a strong inductive bias to downstream tasks for effective transfer learning. In this work, we present our material and texture based self-supervision method named MATTER (MATerial and TExture Representation Learning), which is inspired by classical material and texture methods. Material and texture can effectively describe any surface, including its tactile properties, color, and specularity. By extension, effective representation of material and texture can describe other semantic classes strongly associated with said material and texture. MATTER leverages multi-temporal, spatially aligned remote sensing imagery over unchanged regions to learn invariance to illumination and viewing angle as a mechanism to achieve consistency of material and texture representation. We show that our self-supervision pre-training method allows for up to 24.22% and 6.33% performance increase in unsupervised and fine-tuned setups, and up to 76% faster convergence on change detection, land cover classification, and semantic segmentation tasks.
Adaptive Perturbation for Adversarial Attack
Nov 27, 2021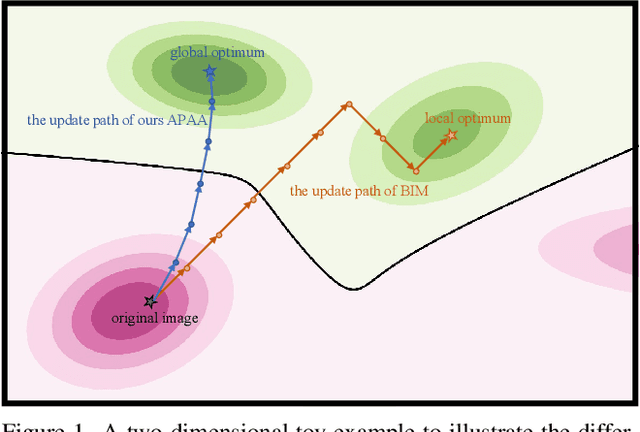
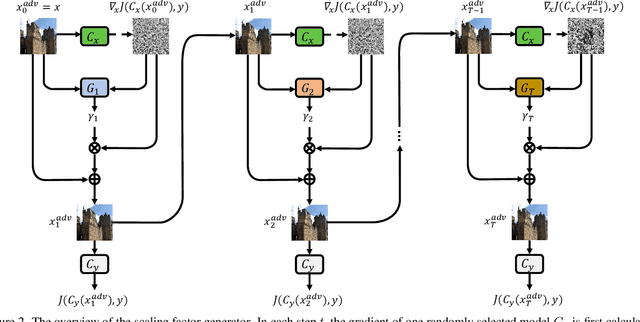
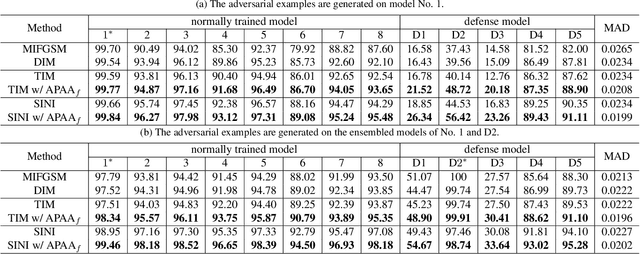
In recent years, the security of deep learning models achieves more and more attentions with the rapid development of neural networks, which are vulnerable to adversarial examples. Almost all existing gradient-based attack methods use the sign function in the generation to meet the requirement of perturbation budget on $L_\infty$ norm. However, we find that the sign function may be improper for generating adversarial examples since it modifies the exact gradient direction. We propose to remove the sign function and directly utilize the exact gradient direction with a scaling factor for generating adversarial perturbations, which improves the attack success rates of adversarial examples even with fewer perturbations. Moreover, considering that the best scaling factor varies across different images, we propose an adaptive scaling factor generator to seek an appropriate scaling factor for each image, which avoids the computational cost for manually searching the scaling factor. Our method can be integrated with almost all existing gradient-based attack methods to further improve the attack success rates. Extensive experiments on the CIFAR10 and ImageNet datasets show that our method exhibits higher transferability and outperforms the state-of-the-art methods.
Hybrid Instance-aware Temporal Fusion for Online Video Instance Segmentation
Dec 03, 2021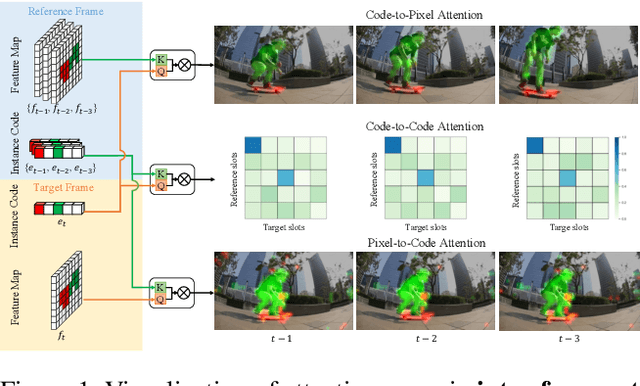
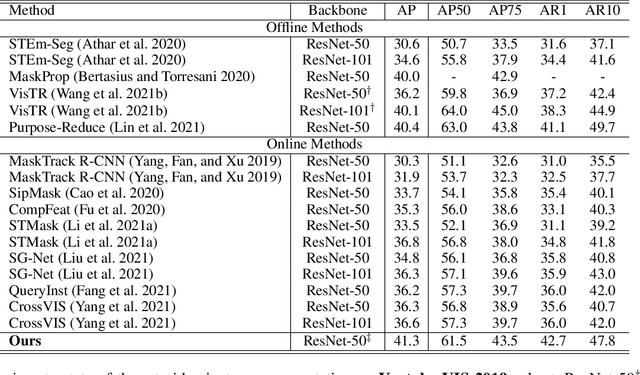
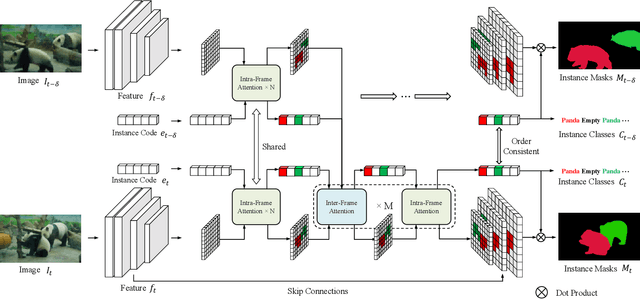
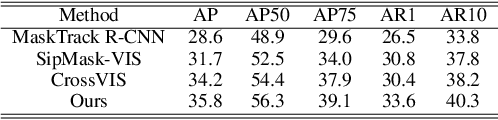
Recently, transformer-based image segmentation methods have achieved notable success against previous solutions. While for video domains, how to effectively model temporal context with the attention of object instances across frames remains an open problem. In this paper, we propose an online video instance segmentation framework with a novel instance-aware temporal fusion method. We first leverages the representation, i.e., a latent code in the global context (instance code) and CNN feature maps to represent instance- and pixel-level features. Based on this representation, we introduce a cropping-free temporal fusion approach to model the temporal consistency between video frames. Specifically, we encode global instance-specific information in the instance code and build up inter-frame contextual fusion with hybrid attentions between the instance codes and CNN feature maps. Inter-frame consistency between the instance codes are further enforced with order constraints. By leveraging the learned hybrid temporal consistency, we are able to directly retrieve and maintain instance identities across frames, eliminating the complicated frame-wise instance matching in prior methods. Extensive experiments have been conducted on popular VIS datasets, i.e. Youtube-VIS-19/21. Our model achieves the best performance among all online VIS methods. Notably, our model also eclipses all offline methods when using the ResNet-50 backbone.
Triangle Attack: A Query-efficient Decision-based Adversarial Attack
Dec 13, 2021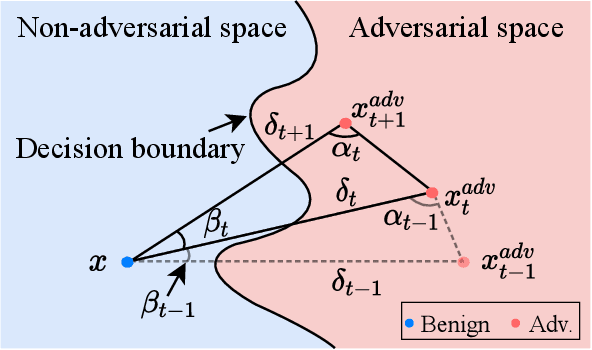
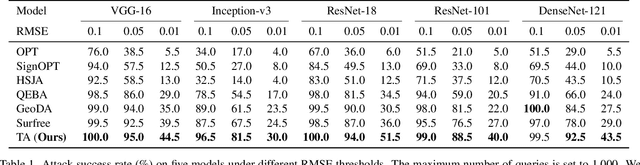
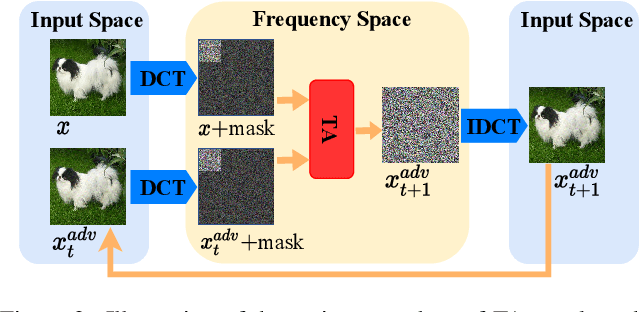
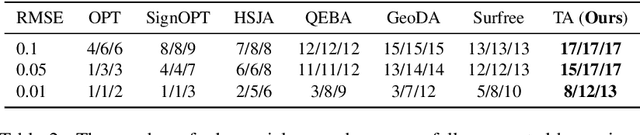
Decision-based attack poses a severe threat to real-world applications since it regards the target model as a black box and only accesses the hard prediction label. Great efforts have been made recently to decrease the number of queries; however, existing decision-based attacks still require thousands of queries in order to generate good quality adversarial examples. In this work, we find that a benign sample, the current and the next adversarial examples could naturally construct a triangle in a subspace for any iterative attacks. Based on the law of sines, we propose a novel Triangle Attack (TA) to optimize the perturbation by utilizing the geometric information that the longer side is always opposite the larger angle in any triangle. However, directly applying such information on the input image is ineffective because it cannot thoroughly explore the neighborhood of the input sample in the high dimensional space. To address this issue, TA optimizes the perturbation in the low frequency space for effective dimensionality reduction owing to the generality of such geometric property. Extensive evaluations on the ImageNet dataset demonstrate that TA achieves a much higher attack success rate within 1,000 queries and needs a much less number of queries to achieve the same attack success rate under various perturbation budgets than existing decision-based attacks. With such high efficiency, we further demonstrate the applicability of TA on real-world API, i.e., Tencent Cloud API.