 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
Multi-Modal MRI Reconstruction Assisted with Spatial Alignment Network
Aug 30, 2021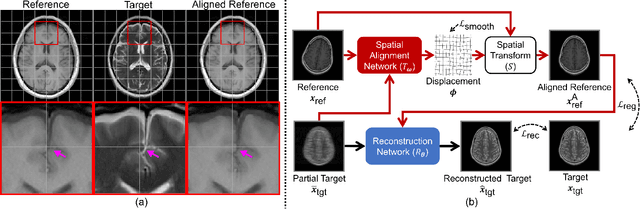
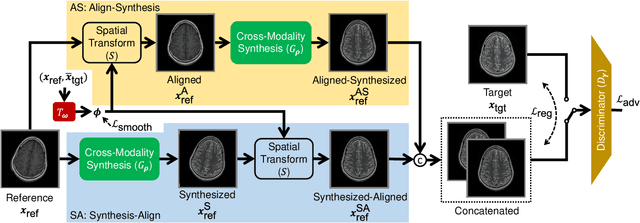

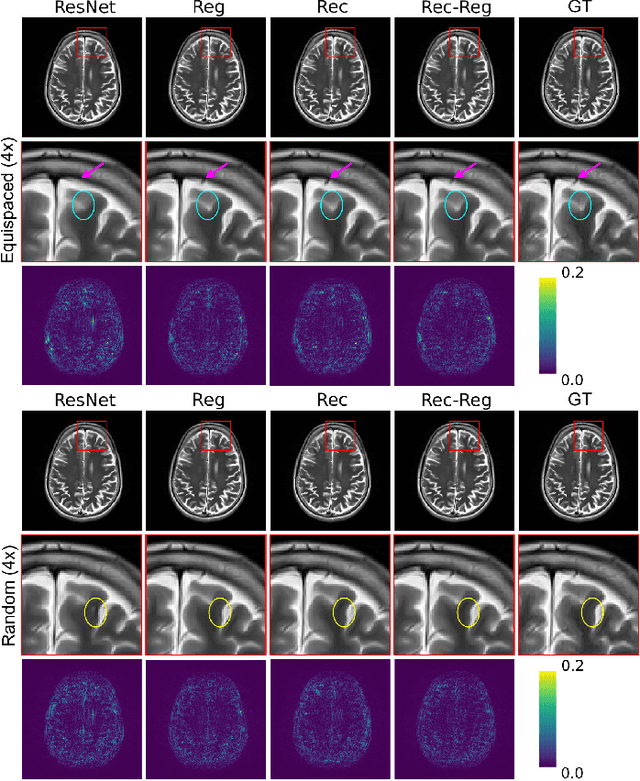
In clinical practice, magnetic resonance imaging (MRI) with multiple contrasts is usually acquired in a single study to assess different properties of the same region of interest in human body. The whole acquisition process can be accelerated by having one or more modalities under-sampled in the $k$-space. Recent researches demonstrate that, considering the redundancy between different contrasts or modalities, a target MRI modality under-sampled in the $k$-space can be more efficiently reconstructed with a fully-sampled MRI contrast as the reference modality. However, we find that the performance of the above multi-modal reconstruction can be negatively affected by subtle spatial misalignment between different contrasts, which is actually common in clinical practice. In this paper, to compensate for such spatial misalignment, we integrate the spatial alignment network with multi-modal reconstruction towards better reconstruction quality of the target modality. First, the spatial alignment network estimates the spatial misalignment between the fully-sampled reference and the under-sampled target images, and warps the reference image accordingly. Then, the aligned fully-sampled reference image joins the multi-modal reconstruction of the under-sampled target image. Also, considering the contrast difference between the target and the reference images, we particularly design the cross-modality-synthesis-based registration loss, in combination with the reconstruction loss, to jointly train the spatial alignment network and the reconstruction network. Experiments on both clinical MRI and multi-coil $k$-space raw data demonstrate the superiority and robustness of multi-modal MRI reconstruction empowered with our spatial alignment network. Our code is publicly available at \url{https://github.com/woxuankai/SpatialAlignmentNetwork}.