 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Radiance Maps for Extraterrestrial Navigation and Path Planning
Mar 18, 2026Autonomous vehicles such as the Mars rovers currently lead the vanguard of surface exploration on extraterrestrial planets and moons. In order to accelerate the pace of exploration and science objectives, it is critical to plan safe and efficient paths for these vehicles. However, current rover autonomy is limited by a lack of global maps which can be easily constructed and stored for onboard re-planning. Recently, Neural Radiance Fields (NeRFs) have been introduced as a detailed 3D scene representation which can be trained from sparse 2D images and efficiently stored. We propose to use NeRFs to construct maps for online use in autonomous navigation, and present a planning framework which leverages the NeRF map to integrate local and global information. Our approach interpolates local cost observations across global regions using kernel ridge regression over terrain features extracted from the NeRF map, allowing the rover to re-route itself around untraversable areas discovered during online operation. We validate our approach in high-fidelity simulation and demonstrate lower cost and higher percentage success rate path planning compared to various baselines.
NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
Feb 25, 2026Vision-Language-Action (VLA) models are advancing autonomous driving by replacing modular pipelines with unified end-to-end architectures. However, current VLAs face two expensive requirements: (1) massive dataset collection, and (2) dense reasoning annotations. In this work, we address both challenges with NORD (No Reasoning for Driving). Compared to existing VLAs, NORD achieves competitive performance while being fine-tuned on <60% of the data and no reasoning annotations, resulting in 3x fewer tokens. We identify that standard Group Relative Policy Optimization (GRPO) fails to yield significant improvements when applied to policies trained on such small, reasoning-free datasets. We show that this limitation stems from difficulty bias, which disproportionately penalizes reward signals from scenarios that produce high-variance rollouts within GRPO. NORD overcomes this by incorporating Dr. GRPO, a recent algorithm designed to mitigate difficulty bias in LLMs. As a result, NORD achieves competitive performance on Waymo and NAVSIM with a fraction of the training data and no reasoning overhead, enabling more efficient autonomous systems. Website: https://nord-vla-ai.github.io/
Framework for Co-distillation Driven Federated Learning to Address Class Imbalance in Healthcare
Nov 15, 2024



Federated Learning (FL) is a pioneering approach in distributed machine learning, enabling collaborative model training across multiple clients while retaining data privacy. However, the inherent heterogeneity due to imbalanced resource representations across multiple clients poses significant challenges, often introducing bias towards the majority class. This issue is particularly prevalent in healthcare settings, where hospitals acting as clients share medical images. To address class imbalance and reduce bias, we propose a co-distillation driven framework in a federated healthcare setting. Unlike traditional federated setups with a designated server client, our framework promotes knowledge sharing among clients to collectively improve learning outcomes. Our experiments demonstrate that in a federated healthcare setting, co-distillation outperforms other federated methods in handling class imbalance. Additionally, we demonstrate that our framework has the least standard deviation with increasing imbalance while outperforming other baselines, signifying the robustness of our framework for FL in healthcare.
MedSAGa: Few-shot Memory Efficient Medical Image Segmentation using Gradient Low-Rank Projection in SAM
Jul 21, 2024



The application of large-scale models in medical image segmentation demands substantial quantities of meticulously annotated data curated by experts along with high computational resources, both of which are challenges in resource-poor settings. In this study, we present the Medical Segment Anything Model with Galore MedSAGa where we adopt the Segment Anything Model (SAM) to achieve memory-efficient, few-shot medical image segmentation by applying Gradient Low-Rank Projection GaLore to the parameters of the image encoder of SAM. Meanwhile, the weights of the prompt encoder and mask decoder undergo full parameter fine-tuning using standard optimizers. We further assess MedSAGa's few-shot learning capabilities, reporting on its memory efficiency and segmentation performance across multiple standard medical image segmentation datasets. We compare it with several baseline models, including LoRA fine-tuned SAM (SAMed) and DAE-Former. Experiments across multiple datasets and these baseline models with different number of images for fine tuning demonstrated that the GPU memory consumption of MedSAGa is significantly less than that of the baseline models, achieving an average memory efficiency of 66% more than current state-of-the-art (SOTA) models for medical image segmentation. The combination of substantially lower memory requirements and comparable to SOTA results in few-shot learning for medical image segmentation positions MedSAGa as an optimal solution for deployment in resource-constrained settings.
Neural Elevation Models for Terrain Mapping and Path Planning
May 24, 2024



This work introduces Neural Elevations Models (NEMos), which adapt Neural Radiance Fields to a 2.5D continuous and differentiable terrain model. In contrast to traditional terrain representations such as digital elevation models, NEMos can be readily generated from imagery, a low-cost data source, and provide a lightweight representation of terrain through an implicit continuous and differentiable height field. We propose a novel method for jointly training a height field and radiance field within a NeRF framework, leveraging quantile regression. Additionally, we introduce a path planning algorithm that performs gradient-based optimization of a continuous cost function for minimizing distance, slope changes, and control effort, enabled by differentiability of the height field. We perform experiments on simulated and real-world terrain imagery, demonstrating NEMos ability to generate high-quality reconstructions and produce smoother paths compared to discrete path planning methods. Future work will explore the incorporation of features and semantics into the height field, creating a generalized terrain model.
BOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023



Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.
A Deep Reinforcement Learning Approach to Rare Event Estimation
Nov 22, 2022



An important step in the design of autonomous systems is to evaluate the probability that a failure will occur. In safety-critical domains, the failure probability is extremely small so that the evaluation of a policy through Monte Carlo sampling is inefficient. Adaptive importance sampling approaches have been developed for rare event estimation but do not scale well to sequential systems with long horizons. In this work, we develop two adaptive importance sampling algorithms that can efficiently estimate the probability of rare events for sequential decision making systems. The basis for these algorithms is the minimization of the Kullback-Leibler divergence between a state-dependent proposal distribution and a target distribution over trajectories, but the resulting algorithms resemble policy gradient and value-based reinforcement learning. We apply multiple importance sampling to reduce the variance of our estimate and to address the issue of multi-modality in the optimal proposal distribution. We demonstrate our approach on a control task with both continuous and discrete actions spaces and show accuracy improvements over several baselines.
Improving GNSS Positioning using Neural Network-based Corrections
Oct 18, 2021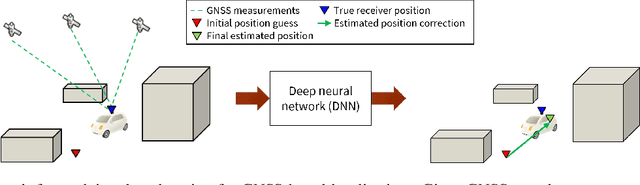



Deep Neural Networks (DNNs) are a promising tool for Global Navigation Satellite System (GNSS) positioning in the presence of multipath and non-line-of-sight errors, owing to their ability to model complex errors using data. However, developing a DNN for GNSS positioning presents various challenges, such as 1) poor numerical conditioning caused by large variations in measurements and position values across the globe, 2) varying number and order within the set of measurements due to changing satellite visibility, and 3) overfitting to available data. In this work, we address the aforementioned challenges and propose an approach for GNSS positioning by applying DNN-based corrections to an initial position guess. Our DNN learns to output the position correction using the set of pseudorange residuals and satellite line-of-sight vectors as inputs. The limited variation in these input and output values improves the numerical conditioning for our DNN. We design our DNN architecture to combine information from the available GNSS measurements, which vary both in number and order, by leveraging recent advancements in set-based deep learning methods. Furthermore, we present a data augmentation strategy for reducing overfitting in the DNN by randomizing the initial position guesses. We first perform simulations and show an improvement in the initial positioning error when our DNN-based corrections are applied. After this, we demonstrate that our approach outperforms a WLS baseline on real-world data. Our implementation is available at github.com/Stanford-NavLab/deep_gnss.
Data-Driven Protection Levels for Camera and 3D Map-based Safe Urban Localization
Jan 20, 2021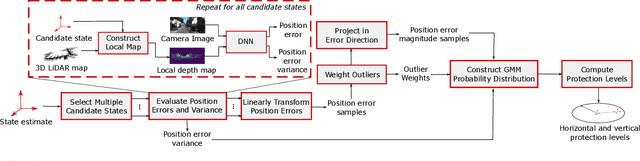

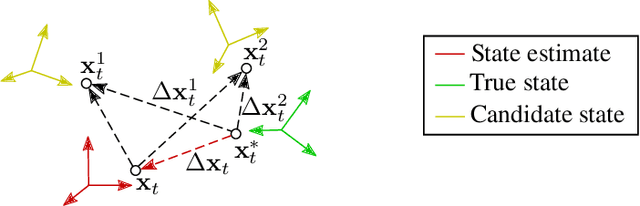
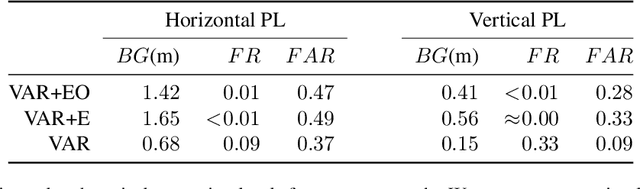
Reliably assessing the error in an estimated vehicle position is integral for ensuring the vehicle's safety in urban environments. Many existing approaches use GNSS measurements to characterize protection levels (PLs) as probabilistic upper bounds on the position error. However, GNSS signals might be reflected or blocked in urban environments, and thus additional sensor modalities need to be considered to determine PLs. In this paper, we propose a novel approach for computing PLs by matching camera image measurements to a LiDAR-based 3D map of the environment. We specify a Gaussian mixture model probability distribution of position error using deep neural network-based data-driven models and statistical outlier weighting techniques. From the probability distribution, we compute the PLs by evaluating the position error bound using numerical line-search methods. Through experimental validation with real-world data, we demonstrate that the PLs computed from our method are reliable bounds on the position error in urban environments.
A New Particle Filter Framework for Bayesian Receiver Autonomous Integrity Monitoring in Urban Environments
Jan 20, 2021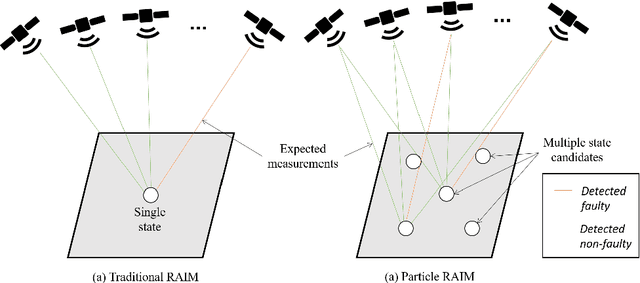

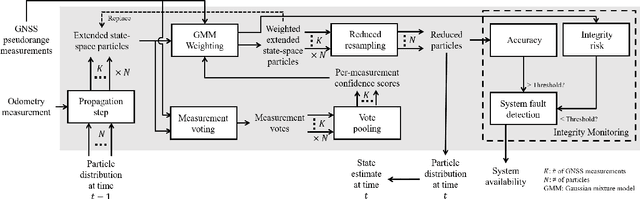
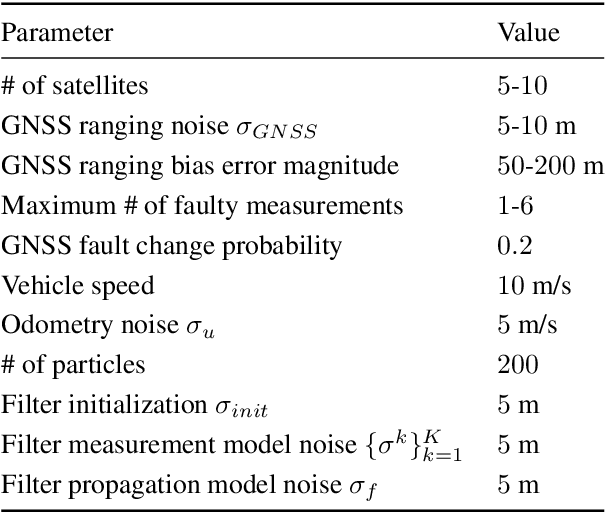
Existing urban navigation algorithms employ integrity monitoring (IM) to mitigate the impact of measurement bias errors and determine system availability when estimating the position of a receiver. Many IM techniques, such as receiver autonomous integrity monitoring (RAIM), utilize measurement residuals associated with a single receiver position to provide integrity. However, identifying a single correct receiver position is often challenging in urban environments due to low satellite visibility and multiple measurements with bias errors. To address this, we propose Particle RAIM as a novel framework for robust state estimation and IM using GNSS and odometry measurements. Particle RAIM integrates residual-based RAIM with a particle filter and Gaussian mixture model likelihood to jointly perform state estimation and fault mitigation using a multimodal probability distribution of the receiver state. Our experiments on simulated and real-world data show that Particle RAIM achieves smaller positioning errors as well as smaller probability of false alarm and probability of missed-identification in determining system availability than existing urban localization and IM approaches in challenging environments with a relatively small computation overhead.