 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Multi-Domain Multimodal Image-to-Image Translation with Explicit Domain-Constrained Disentanglement
Nov 02, 2019

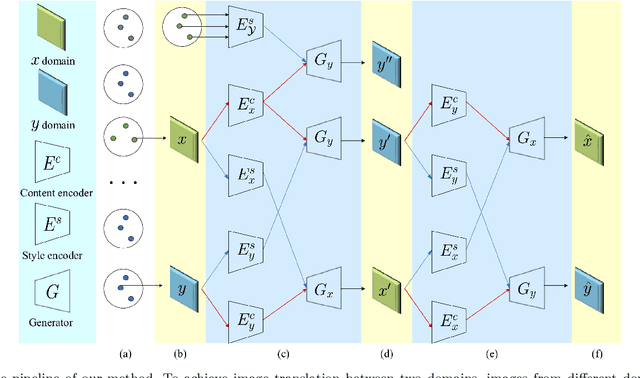
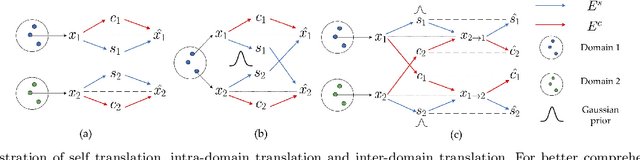
Image-to-image translation has drawn great attention during the past few years. It aims to translate an image in one domain to a given reference image in another domain. Due to its effectiveness and efficiency, many applications can be formulated as image-to-image translation problems. However, three main challenges remain in image-to-image translation: 1) the lack of large amounts of aligned training pairs for different tasks; 2) the ambiguity of multiple possible outputs from a single input image; and 3) the lack of simultaneous training of multiple datasets from different domains within a single network. We also found in experiments that the implicit disentanglement of content and style could lead to unexpect results. In this paper, we propose a unified framework for learning to generate diverse outputs using unpaired training data and allow simultaneous training of multiple datasets from different domains via a single network. Furthermore, we also investigate how to better extract domain supervision information so as to learn better disentangled representations and achieve better image translation. Experiments show that the proposed method outperforms or is comparable with the state-of-the-art methods.
Lightweight Jet Reconstruction and Identification as an Object Detection Task
Feb 09, 2022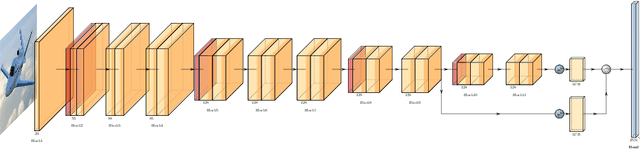
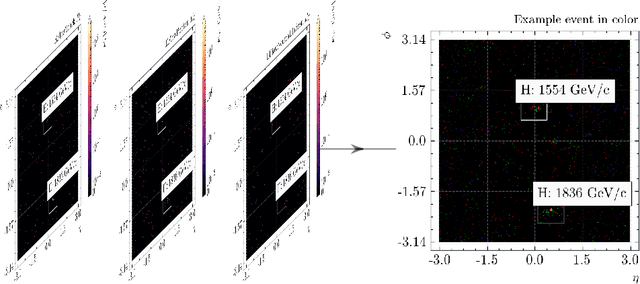
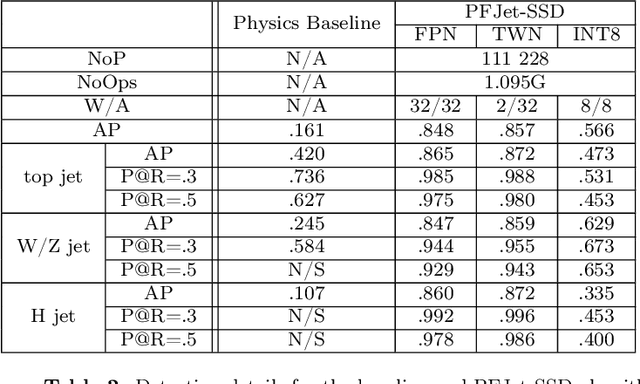
We apply object detection techniques based on deep convolutional blocks to end-to-end jet identification and reconstruction tasks encountered at the CERN Large Hadron Collider (LHC). Collision events produced at the LHC and represented as an image composed of calorimeter and tracker cells are given as an input to a Single Shot Detection network. The algorithm, named PFJet-SSD performs simultaneous localization, classification and regression tasks to cluster jets and reconstruct their features. This all-in-one single feed-forward pass gives advantages in terms of execution time and an improved accuracy w.r.t. traditional rule-based methods. A further gain is obtained from network slimming, homogeneous quantization, and optimized runtime for meeting memory and latency constraints of a typical real-time processing environment. We experiment with 8-bit and ternary quantization, benchmarking their accuracy and inference latency against a single-precision floating-point. We show that the ternary network closely matches the performance of its full-precision equivalent and outperforms the state-of-the-art rule-based algorithm. Finally, we report the inference latency on different hardware platforms and discuss future applications.
DiRS: On Creating Benchmark Datasets for Remote Sensing Image Interpretation
Jun 22, 2020



The past decade has witnessed great progress on remote sensing (RS) image interpretation and its wide applications. With RS images becoming more accessible than ever before, there is an increasing demand for the automatic interpretation of these images, where benchmark datasets are essential prerequisites for developing and testing intelligent interpretation algorithms. After reviewing existing benchmark datasets in the research community of RS image interpretation, this article discusses the problem of how to efficiently prepare a suitable benchmark dataset for RS image analysis. Specifically, we first analyze the current challenges of developing intelligent algorithms for RS image interpretation with bibliometric investigations. We then present some principles, i.e., diversity, richness, and scalability (called DiRS), on constructing benchmark datasets in efficient manners. Following the DiRS principles, we also provide an example on building datasets for RS image classification, i.e., Million-AID, a new large-scale benchmark dataset containing million instances for RS scene classification. Several challenges and perspectives in RS image annotation are finally discussed to facilitate the research in benchmark dataset construction. We do hope this paper will provide RS community an overall perspective on constructing large-scale and practical image datasets for further research, especially data-driven ones.
Street-view Panoramic Video Synthesis from a Single Satellite Image
Dec 11, 2020
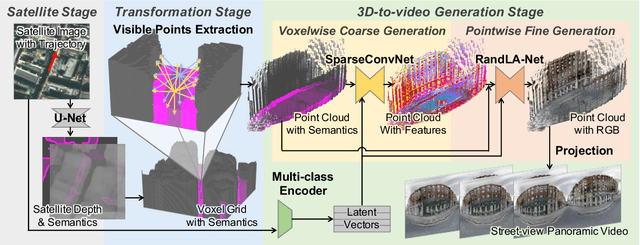


We present a novel method for synthesizing both temporally and geometrically consistent street-view panoramic video from a given single satellite image and camera trajectory. Existing cross-view synthesis approaches focus more on images, while video synthesis in such a case has not yet received enough attention. Single image synthesis approaches are not well suited for video synthesis since they lack temporal consistency which is a crucial property of videos. To this end, our approach explicitly creates a 3D point cloud representation of the scene and maintains dense 3D-2D correspondences across frames that reflect the geometric scene configuration inferred from the satellite view. We implement a cascaded network architecture with two hourglass modules for successive coarse and fine generation for colorizing the point cloud from the semantics and per-class latent vectors. By leveraging computed correspondences, the produced street-view video frames adhere to the 3D geometric scene structure and maintain temporal consistency. Qualitative and quantitative experiments demonstrate superior results compared to other state-of-the-art cross-view synthesis approaches that either lack temporal or geometric consistency. To the best of our knowledge, our work is the first work to synthesize cross-view images to video.
SGNet: A Super-class Guided Network for Image Classification and Object Detection
Apr 26, 2021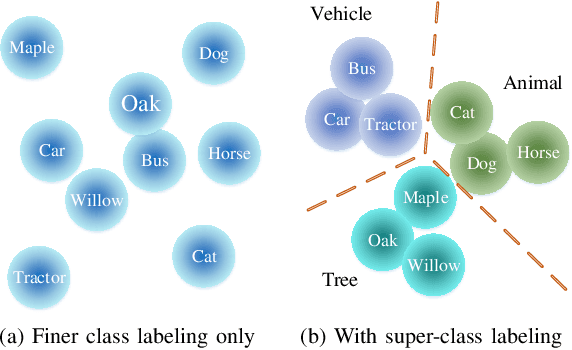
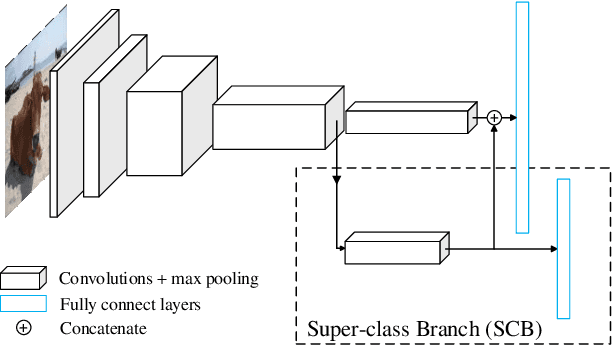
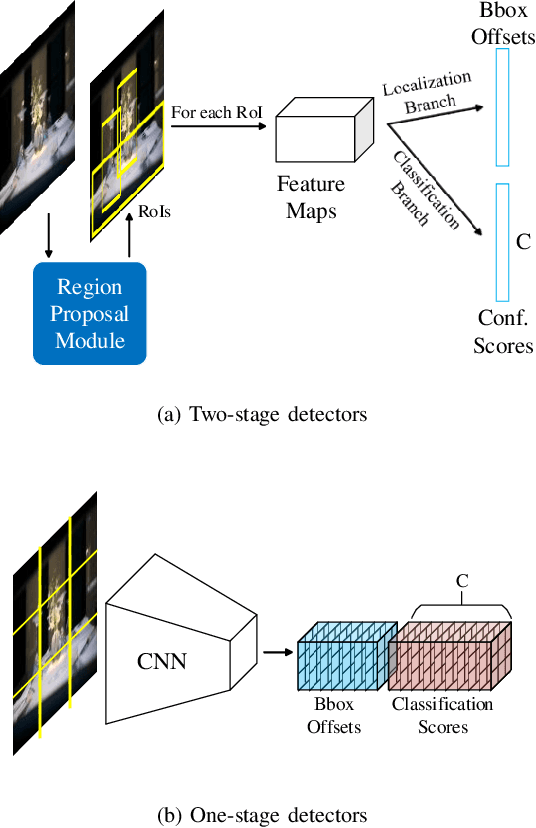
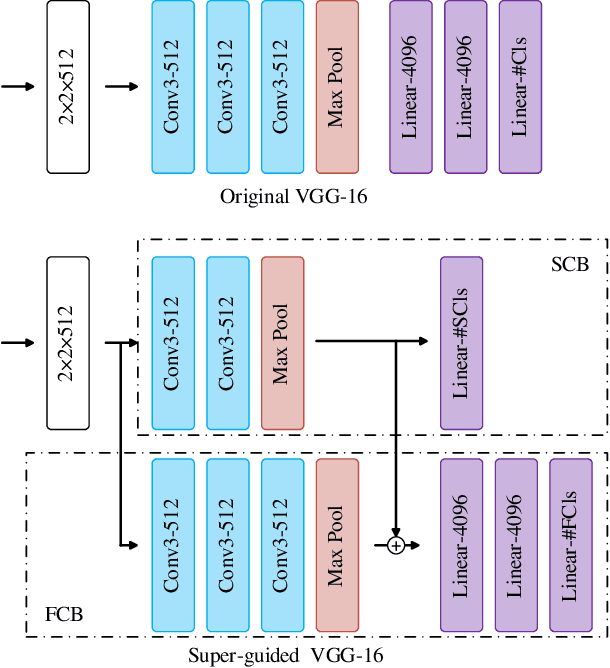
Most classification models treat different object classes in parallel and the misclassifications between any two classes are treated equally. In contrast, human beings can exploit high-level information in making a prediction of an unknown object. Inspired by this observation, the paper proposes a super-class guided network (SGNet) to integrate the high-level semantic information into the network so as to increase its performance in inference. SGNet takes two-level class annotations that contain both super-class and finer class labels. The super-classes are higher-level semantic categories that consist of a certain amount of finer classes. A super-class branch (SCB), trained on super-class labels, is introduced to guide finer class prediction. At the inference time, we adopt two different strategies: Two-step inference (TSI) and direct inference (DI). TSI first predicts the super-class and then makes predictions of the corresponding finer class. On the other hand, DI directly generates predictions from the finer class branch (FCB). Extensive experiments have been performed on CIFAR-100 and MS COCO datasets. The experimental results validate the proposed approach and demonstrate its superior performance on image classification and object detection.
SpectralNET: Exploring Spatial-Spectral WaveletCNN for Hyperspectral Image Classification
Apr 01, 2021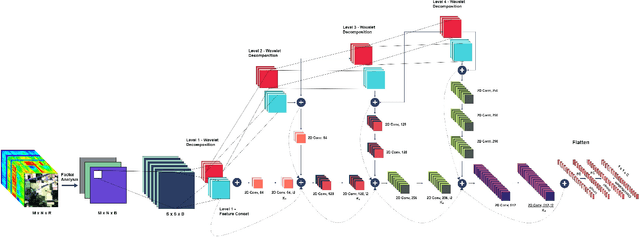
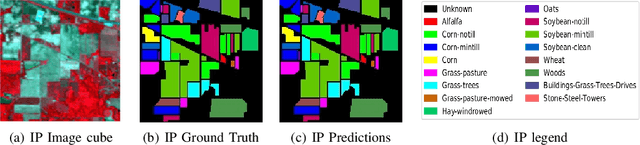
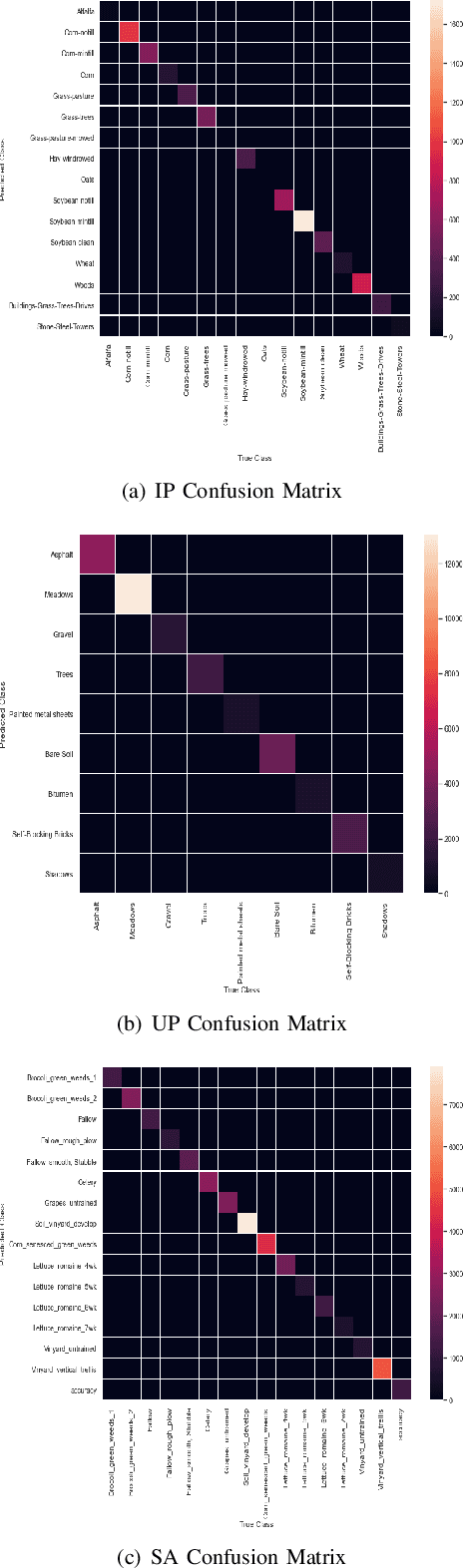

Hyperspectral Image (HSI) classification using Convolutional Neural Networks (CNN) is widely found in the current literature. Approaches vary from using SVMs to 2D CNNs, 3D CNNs, 3D-2D CNNs. Besides 3D-2D CNNs and FuSENet, the other approaches do not consider both the spectral and spatial features together for HSI classification task, thereby resulting in poor performances. 3D CNNs are computationally heavy and are not widely used, while 2D CNNs do not consider multi-resolution processing of images, and only limits itself to the spatial features. Even though 3D-2D CNNs try to model the spectral and spatial features their performance seems limited when applied over multiple dataset. In this article, we propose SpectralNET, a wavelet CNN, which is a variation of 2D CNN for multi-resolution HSI classification. A wavelet CNN uses layers of wavelet transform to bring out spectral features. Computing a wavelet transform is lighter than computing 3D CNN. The spectral features extracted are then connected to the 2D CNN which bring out the spatial features, thereby creating a spatial-spectral feature vector for classification. Overall a better model is achieved that can classify multi-resolution HSI data with high accuracy. Experiments performed with SpectralNET on benchmark dataset, i.e. Indian Pines, University of Pavia, and Salinas Scenes confirm the superiority of proposed SpectralNET with respect to the state-of-the-art methods. The code is publicly available in https://github.com/tanmay-ty/SpectralNET.
Learning Multi-Object Dynamics with Compositional Neural Radiance Fields
Mar 04, 2022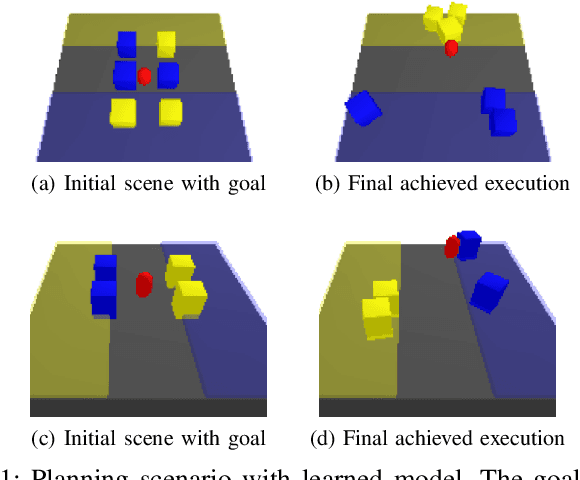
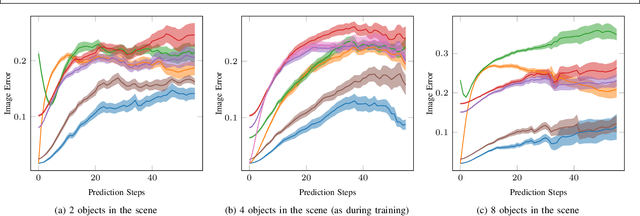
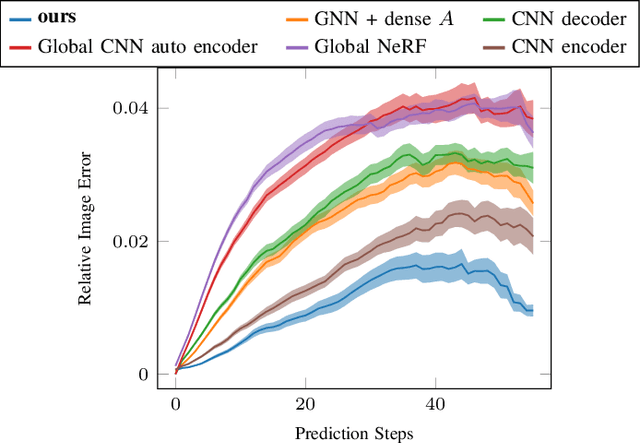
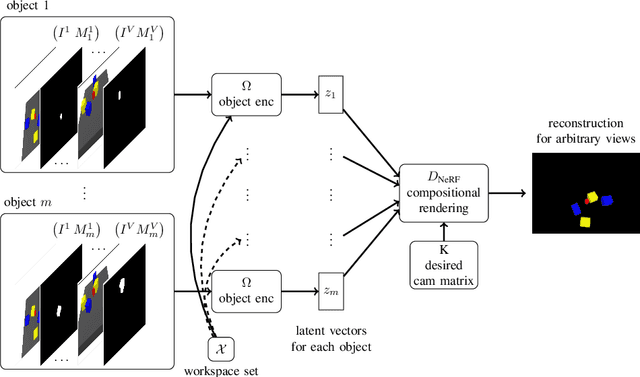
We present a method to learn compositional predictive models from image observations based on implicit object encoders, Neural Radiance Fields (NeRFs), and graph neural networks. A central question in learning dynamic models from sensor observations is on which representations predictions should be performed. NeRFs have become a popular choice for representing scenes due to their strong 3D prior. However, most NeRF approaches are trained on a single scene, representing the whole scene with a global model, making generalization to novel scenes, containing different numbers of objects, challenging. Instead, we present a compositional, object-centric auto-encoder framework that maps multiple views of the scene to a \emph{set} of latent vectors representing each object separately. The latent vectors parameterize individual NeRF models from which the scene can be reconstructed and rendered from novel viewpoints. We train a graph neural network dynamics model in the latent space to achieve compositionality for dynamics prediction. A key feature of our approach is that the learned 3D information of the scene through the NeRF model enables us to incorporate structural priors in learning the dynamics models, making long-term predictions more stable. The model can further be used to synthesize new scenes from individual object observations. For planning, we utilize RRTs in the learned latent space, where we can exploit our model and the implicit object encoder to make sampling the latent space informative and more efficient. In the experiments, we show that the model outperforms several baselines on a pushing task containing many objects. Video: https://dannydriess.github.io/compnerfdyn/
Voxelmorph++ Going beyond the cranial vault with keypoint supervision and multi-channel instance optimisation
Feb 28, 2022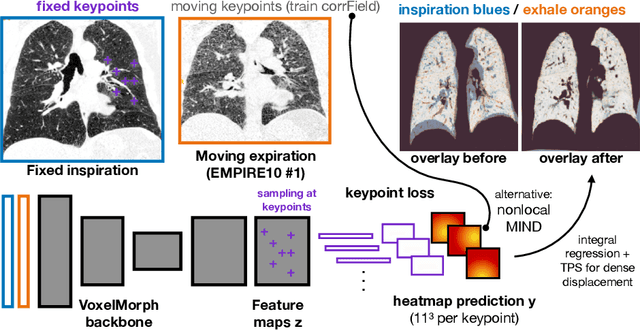
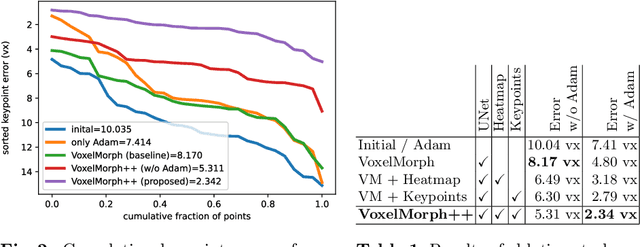
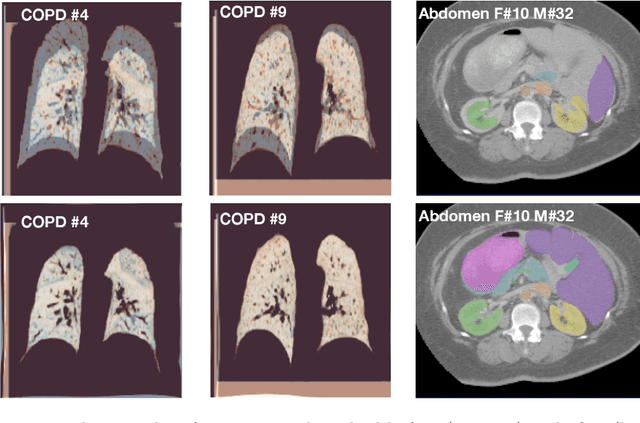
The majority of current research in deep learning based image registration addresses inter-patient brain registration with moderate deformation magnitudes. The recent Learn2Reg medical registration benchmark has demonstrated that single-scale U-Net architectures, such as VoxelMorph that directly employ a spatial transformer loss, often do not generalise well beyond the cranial vault and fall short of state-of-the-art performance for abdominal or intra-patient lung registration. Here, we propose two straightforward steps that greatly reduce this gap in accuracy. First, we employ keypoint self-supervision with a novel network head that predicts a discretised heatmap and robustly reduces large deformations for better robustness. Second, we replace multiple learned fine-tuning steps by a single instance optimisation with hand-crafted features and the Adam optimiser. Different to other related work, including FlowNet or PDD-Net, our approach does not require a fully discretised architecture with correlation layer. Our ablation study demonstrates the importance of keypoints in both self-supervised and unsupervised (using only a MIND metric) settings. On a multi-centric inspiration-exhale lung CT dataset, including very challenging COPD scans, our method outperforms VoxelMorph by improving nonlinear alignment by 77% compared to 19% - reaching target registration errors of 2 mm that outperform all but one learning methods published to date. Extending the method to semantic features sets new stat-of-the-art performance on inter-subject abdominal CT registration.
Image inpainting: A review
Sep 13, 2019
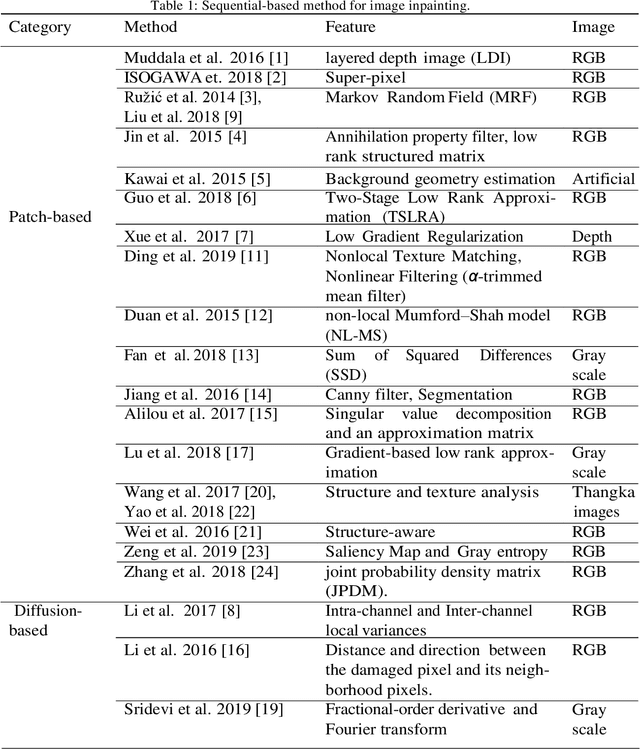

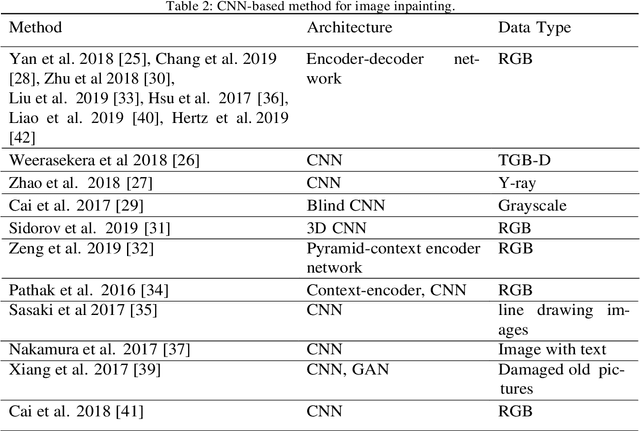
Although image inpainting, or the art of repairing the old and deteriorated images, has been around for many years, it has gained even more popularity because of the recent development in image processing techniques. With the improvement of image processing tools and the flexibility of digital image editing, automatic image inpainting has found important applications in computer vision and has also become an important and challenging topic of research in image processing. This paper is a brief review of the existing image inpainting approaches we first present a global vision on the existing methods for image inpainting. We attempt to collect most of the existing approaches and classify them into three categories, namely, sequential-based, CNN-based and GAN-based methods. In addition, for each category, a list of methods for the different types of distortion on the images is presented. Furthermore, collect a list of the available datasets and discuss these in our paper. This is a contribution for digital image inpainting researchers trying to look for the available datasets because there is a lack of datasets available for image inpainting. As the final step in this overview, we present the results of real evaluations of the three categories of image inpainting methods performed on the datasets used, for the different types of image distortion. In the end, we also present the evaluations metrics and discuss the performance of these methods in terms of these metrics. This overview can be used as a reference for image inpainting researchers, and it can also facilitate the comparison of the methods as well as the datasets used. The main contribution of this paper is the presentation of the three categories of image inpainting methods along with a list of available datasets that the researchers can use to evaluate their proposed methodology against.
Spatial Dependency Networks: Neural Layers for Improved Generative Image Modeling
Mar 16, 2021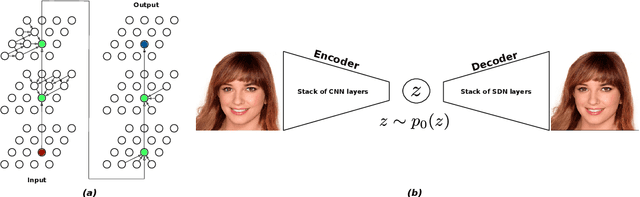
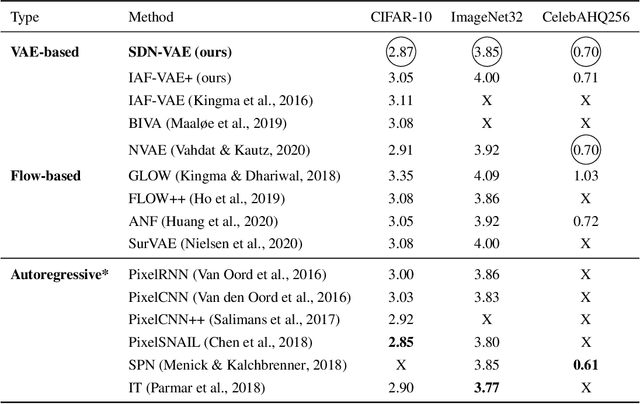
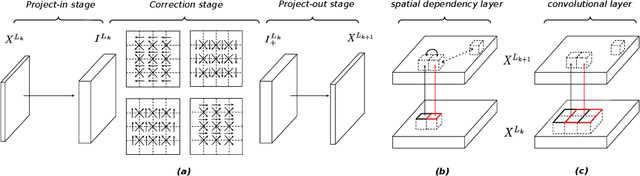
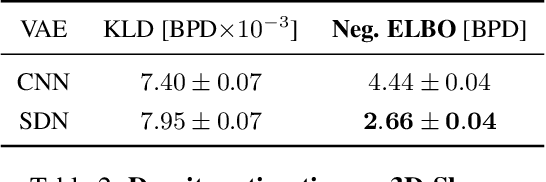
How to improve generative modeling by better exploiting spatial regularities and coherence in images? We introduce a novel neural network for building image generators (decoders) and apply it to variational autoencoders (VAEs). In our spatial dependency networks (SDNs), feature maps at each level of a deep neural net are computed in a spatially coherent way, using a sequential gating-based mechanism that distributes contextual information across 2-D space. We show that augmenting the decoder of a hierarchical VAE by spatial dependency layers considerably improves density estimation over baseline convolutional architectures and the state-of-the-art among the models within the same class. Furthermore, we demonstrate that SDN can be applied to large images by synthesizing samples of high quality and coherence. In a vanilla VAE setting, we find that a powerful SDN decoder also improves learning disentangled representations, indicating that neural architectures play an important role in this task. Our results suggest favoring spatial dependency over convolutional layers in various VAE settings. The accompanying source code is given at https://github.com/djordjemila/sdn.