 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Hierarchical Attention Transformer for Efficient Particle Jet Tagging
May 20, 2026Real-time jet tagging is critical for identifying short-lived particle decays in the high-throughput detectors of the Large Hadron Collider, where real-time trigger systems responsible for deciding which collision events to store impose strict latency and accuracy constraints. While transformer architectures achieve the highest jet tagging accuracy when compute is unconstrained, their quadratic self-attention cost makes inference restrictive on trigger budget. Existing efficient variants reduce the computational cost, but hinder the classification performance. To address this limitation, we introduce the Patch Hierarchical Attention Transformer (PHAT-JeT), which combines two mechanisms: a physics-inspired geometric message-passing module that encodes local detector-plane structure, and a hierarchical patch-based attention scheme that computes exact attention within small particle groups while preserving global context through lightweight patch-token communication. Within a restricted budget, PHAT-JeT achieves state-of-the-art accuracy and background rejection among all resource-constrained jet tagging models on four benchmarks (\textsc{hls4ml}, JetClass, Top Tagging, and Quark--Gluon). Our code is available at https://github.com/aaronw5/PHAT-JeT.
Towards a Self-Driving Trigger at the LHC: Adaptive Response in Real Time
Jan 13, 2026Real-time data filtering and selection -- or trigger -- systems at high-throughput scientific facilities such as the experiments at the Large Hadron Collider (LHC) must process extremely high-rate data streams under stringent bandwidth, latency, and storage constraints. Yet these systems are typically designed as static, hand-tuned menus of selection criteria grounded in prior knowledge and simulation. In this work, we further explore the concept of a self-driving trigger, an autonomous data-filtering framework that reallocates resources and adjusts thresholds dynamically in real-time to optimize signal efficiency, rate stability, and computational cost as instrumentation and environmental conditions evolve. We introduce a benchmark ecosystem to emulate realistic collider scenarios and demonstrate real-time optimization of a menu including canonical energy sum triggers as well as modern anomaly-detection algorithms that target non-standard event topologies using machine learning. Using simulated data streams and publicly available collision data from the Compact Muon Solenoid (CMS) experiment, we demonstrate the capability to dynamically and automatically optimize trigger performance under specific cost objectives without manual retuning. Our adaptive strategy shifts trigger design from static menus with heuristic tuning to intelligent, automated, data-driven control, unlocking greater flexibility and discovery potential in future high-energy physics analyses.
An Evaluation of Representation Learning Methods in Particle Physics Foundation Models
Nov 16, 2025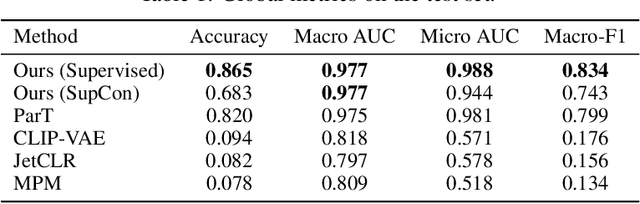
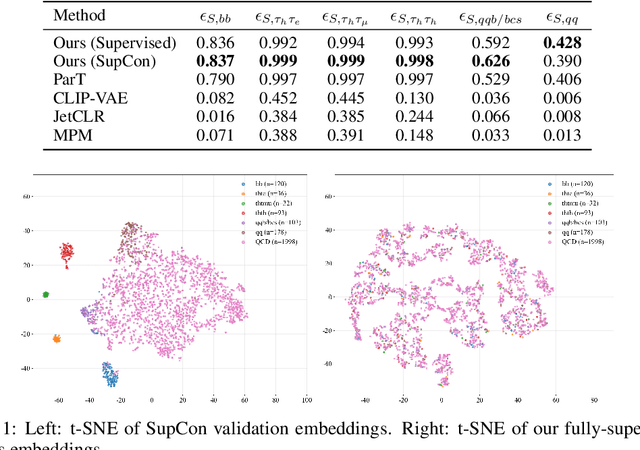
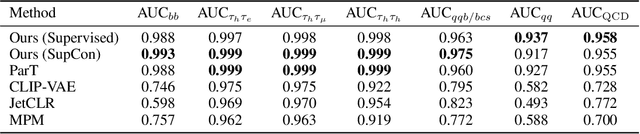
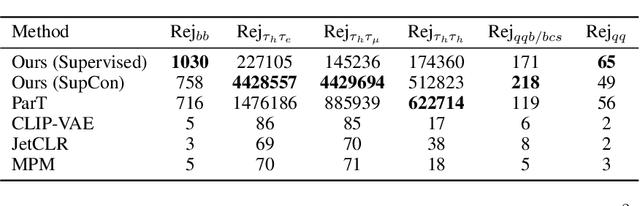
We present a systematic evaluation of representation learning objectives for particle physics within a unified framework. Our study employs a shared transformer-based particle-cloud encoder with standardized preprocessing, matched sampling, and a consistent evaluation protocol on a jet classification dataset. We compare contrastive (supervised and self-supervised), masked particle modeling, and generative reconstruction objectives under a common training regimen. In addition, we introduce targeted supervised architectural modifications that achieve state-of-the-art performance on benchmark evaluations. This controlled comparison isolates the contributions of the learning objective, highlights their respective strengths and limitations, and provides reproducible baselines. We position this work as a reference point for the future development of foundation models in particle physics, enabling more transparent and robust progress across the community.
Fast Jet Tagging with MLP-Mixers on FPGAs
Mar 05, 2025



We explore the innovative use of MLP-Mixer models for real-time jet tagging and establish their feasibility on resource-constrained hardware like FPGAs. MLP-Mixers excel in processing sequences of jet constituents, achieving state-of-the-art performance on datasets mimicking Large Hadron Collider conditions. By using advanced optimization techniques such as High-Granularity Quantization and Distributed Arithmetic, we achieve unprecedented efficiency. These models match or surpass the accuracy of previous architectures, reduce hardware resource usage by up to 97%, double the throughput, and half the latency. Additionally, non-permutation-invariant architectures enable smart feature prioritization and efficient FPGA deployment, setting a new benchmark for machine learning in real-time data processing at particle colliders.
Interpreting Transformers for Jet Tagging
Dec 04, 2024Machine learning (ML) algorithms, particularly attention-based transformer models, have become indispensable for analyzing the vast data generated by particle physics experiments like ATLAS and CMS at the CERN LHC. Particle Transformer (ParT), a state-of-the-art model, leverages particle-level attention to improve jet-tagging tasks, which are critical for identifying particles resulting from proton collisions. This study focuses on interpreting ParT by analyzing attention heat maps and particle-pair correlations on the $\eta$-$\phi$ plane, revealing a binary attention pattern where each particle attends to at most one other particle. At the same time, we observe that ParT shows varying focus on important particles and subjets depending on decay, indicating that the model learns traditional jet substructure observables. These insights enhance our understanding of the model's internal workings and learning process, offering potential avenues for improving the efficiency of transformer architectures in future high-energy physics applications.
Reliable edge machine learning hardware for scientific applications
Jun 27, 2024



Extreme data rate scientific experiments create massive amounts of data that require efficient ML edge processing. This leads to unique validation challenges for VLSI implementations of ML algorithms: enabling bit-accurate functional simulations for performance validation in experimental software frameworks, verifying those ML models are robust under extreme quantization and pruning, and enabling ultra-fine-grained model inspection for efficient fault tolerance. We discuss approaches to developing and validating reliable algorithms at the scientific edge under such strict latency, resource, power, and area requirements in extreme experimental environments. We study metrics for developing robust algorithms, present preliminary results and mitigation strategies, and conclude with an outlook of these and future directions of research towards the longer-term goal of developing autonomous scientific experimentation methods for accelerated scientific discovery.
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
May 01, 2024



Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
Sets are all you need: Ultrafast jet classification on FPGAs for HL-LHC
Feb 02, 2024



We study various machine learning based algorithms for performing accurate jet flavor classification on field-programmable gate arrays and demonstrate how latency and resource consumption scale with the input size and choice of algorithm. These architectures provide an initial design for models that could be used for tagging at the CERN LHC during its high-luminosity phase. The high-luminosity upgrade will lead to a five-fold increase in its instantaneous luminosity for proton-proton collisions and, in turn, higher data volume and complexity, such as the availability of jet constituents. Through quantization-aware training and efficient hardware implementations, we show that O(100) ns inference of complex architectures such as deep sets and interaction networks is feasible at a low computational resource cost.
Robust Anomaly Detection for Particle Physics Using Multi-Background Representation Learning
Jan 16, 2024Anomaly, or out-of-distribution, detection is a promising tool for aiding discoveries of new particles or processes in particle physics. In this work, we identify and address two overlooked opportunities to improve anomaly detection for high-energy physics. First, rather than train a generative model on the single most dominant background process, we build detection algorithms using representation learning from multiple background types, thus taking advantage of more information to improve estimation of what is relevant for detection. Second, we generalize decorrelation to the multi-background setting, thus directly enforcing a more complete definition of robustness for anomaly detection. We demonstrate the benefit of the proposed robust multi-background anomaly detection algorithms on a high-dimensional dataset of particle decays at the Large Hadron Collider.
Fast Particle-based Anomaly Detection Algorithm with Variational Autoencoder
Nov 28, 2023



Model-agnostic anomaly detection is one of the promising approaches in the search for new beyond the standard model physics. In this paper, we present Set-VAE, a particle-based variational autoencoder (VAE) anomaly detection algorithm. We demonstrate a 2x signal efficiency gain compared with traditional subjettiness-based jet selection. Furthermore, with an eye to the future deployment to trigger systems, we propose the CLIP-VAE, which reduces the inference-time cost of anomaly detection by using the KL-divergence loss as the anomaly score, resulting in a 2x acceleration in latency and reducing the caching requirement.