 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Unsupervised Domain Adaptation Model based on Dual-module Adversarial Training
Dec 31, 2021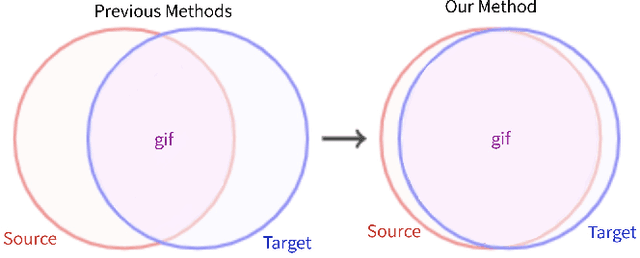
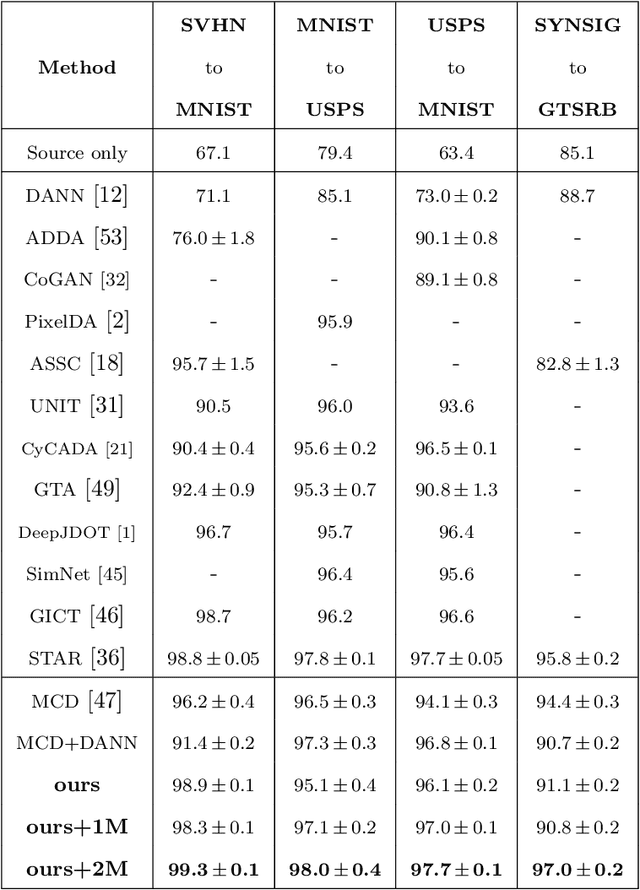
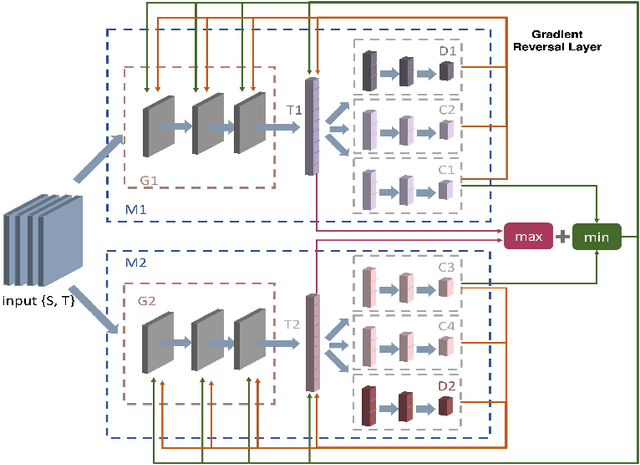
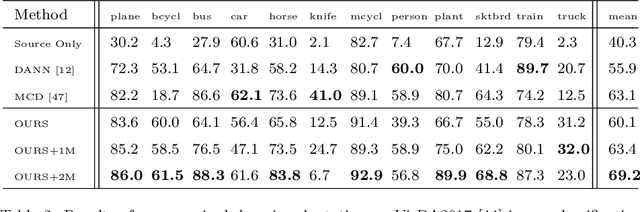
In this paper, we propose a dual-module network architecture that employs a domain discriminative feature module to encourage the domain invariant feature module to learn more domain invariant features. The proposed architecture can be applied to any model that utilizes domain invariant features for unsupervised domain adaptation to improve its ability to extract domain invariant features. We conduct experiments with the Domain-Adversarial Training of Neural Networks (DANN) model as a representative algorithm. In the training process, we supply the same input to the two modules and then extract their feature distribution and prediction results respectively. We propose a discrepancy loss to find the discrepancy of the prediction results and the feature distribution between the two modules. Through the adversarial training by maximizing the loss of their feature distribution and minimizing the discrepancy of their prediction results, the two modules are encouraged to learn more domain discriminative and domain invariant features respectively. Extensive comparative evaluations are conducted and the proposed approach outperforms the state-of-the-art in most unsupervised domain adaptation tasks.
Multiple Classifiers Based Maximum Classifier Discrepancy for Unsupervised Domain Adaptation
Aug 02, 2021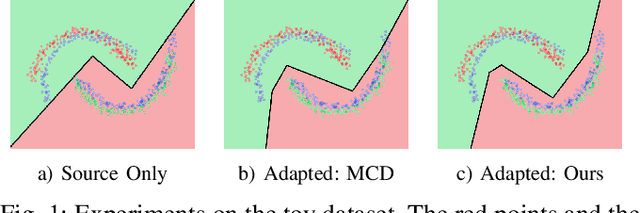
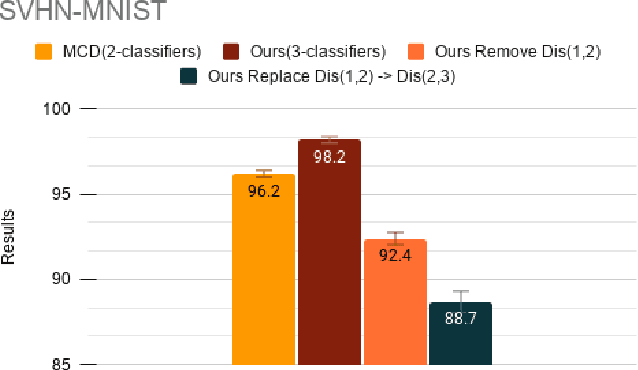
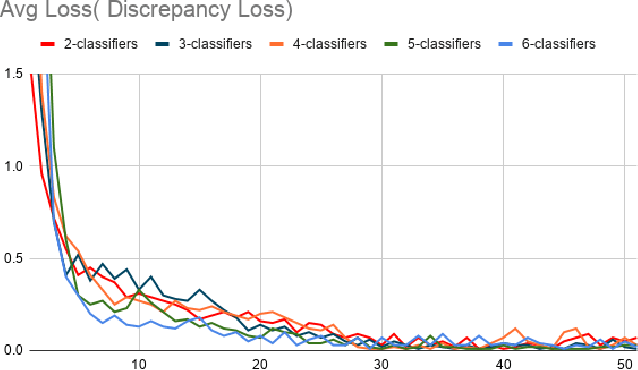
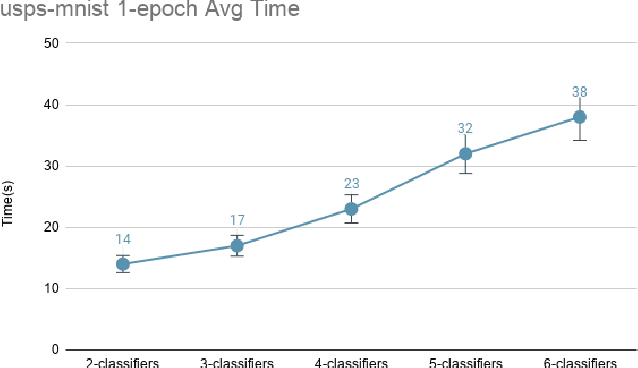
Adversarial training based on the maximum classifier discrepancy between the two classifier structures has achieved great success in unsupervised domain adaptation tasks for image classification. The approach adopts the structure of two classifiers, though simple and intuitive, the learned classification boundary may not well represent the data property in the new domain. In this paper, we propose to extend the structure to multiple classifiers to further boost its performance. To this end, we propose a very straightforward approach to adding more classifiers. We employ the principle that the classifiers are different from each other to construct a discrepancy loss function for multiple classifiers. Through the loss function construction method, we make it possible to add any number of classifiers to the original framework. The proposed approach is validated through extensive experimental evaluations. We demonstrate that, on average, adopting the structure of three classifiers normally yields the best performance as a trade-off between the accuracy and efficiency. With minimum extra computational costs, the proposed approach can significantly improve the original algorithm.
SGNet: A Super-class Guided Network for Image Classification and Object Detection
Apr 26, 2021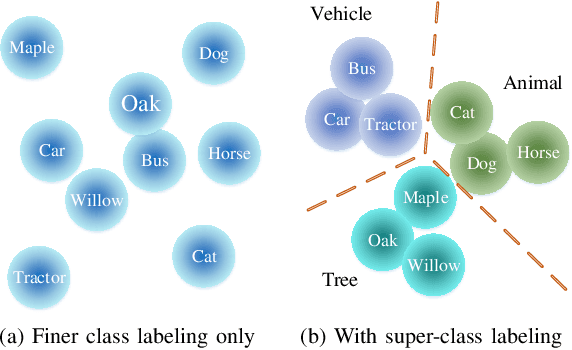
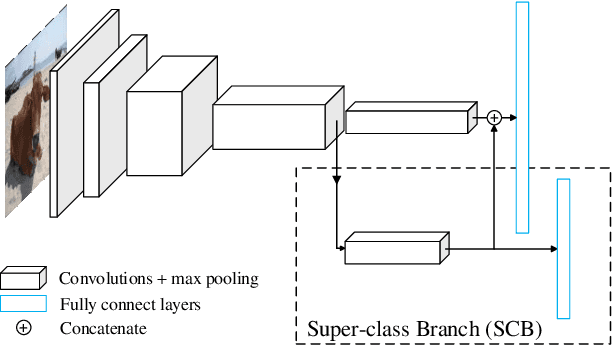
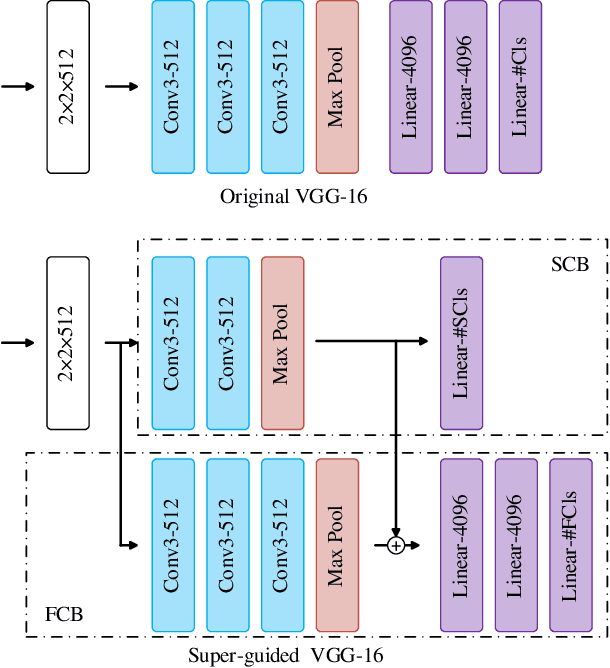
Most classification models treat different object classes in parallel and the misclassifications between any two classes are treated equally. In contrast, human beings can exploit high-level information in making a prediction of an unknown object. Inspired by this observation, the paper proposes a super-class guided network (SGNet) to integrate the high-level semantic information into the network so as to increase its performance in inference. SGNet takes two-level class annotations that contain both super-class and finer class labels. The super-classes are higher-level semantic categories that consist of a certain amount of finer classes. A super-class branch (SCB), trained on super-class labels, is introduced to guide finer class prediction. At the inference time, we adopt two different strategies: Two-step inference (TSI) and direct inference (DI). TSI first predicts the super-class and then makes predictions of the corresponding finer class. On the other hand, DI directly generates predictions from the finer class branch (FCB). Extensive experiments have been performed on CIFAR-100 and MS COCO datasets. The experimental results validate the proposed approach and demonstrate its superior performance on image classification and object detection.
Efficient Golf Ball Detection and Tracking Based on Convolutional Neural Networks and Kalman Filter
Dec 17, 2020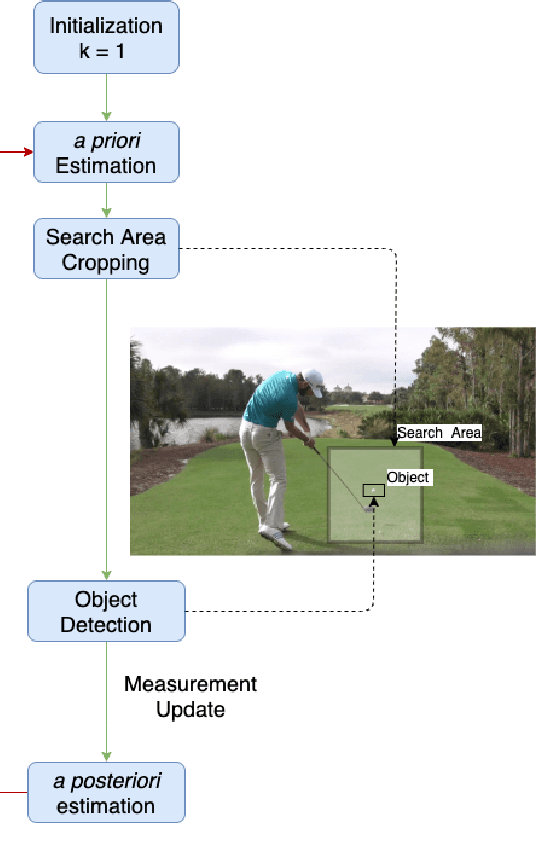

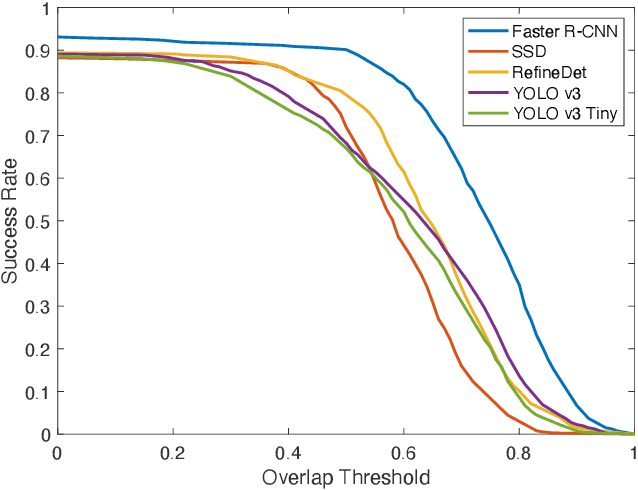
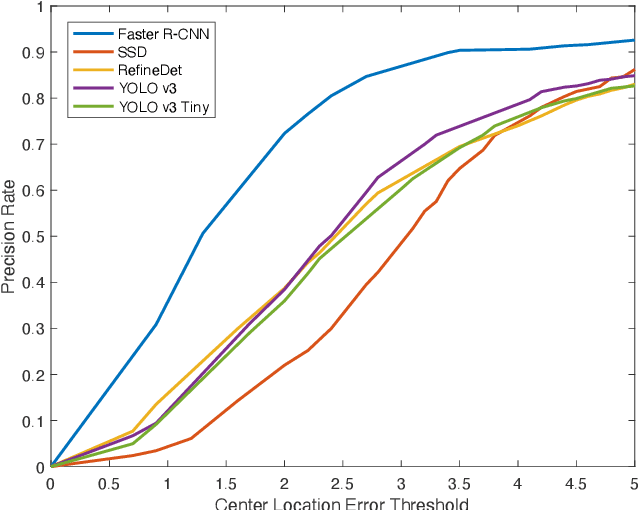
This paper focuses on the problem of online golf ball detection and tracking from image sequences. An efficient real-time approach is proposed by exploiting convolutional neural networks (CNN) based object detection and a Kalman filter based prediction. Five classical deep learning-based object detection networks are implemented and evaluated for ball detection, including YOLO v3 and its tiny version, YOLO v4, Faster R-CNN, SSD, and RefineDet. The detection is performed on small image patches instead of the entire image to increase the performance of small ball detection. At the tracking stage, a discrete Kalman filter is employed to predict the location of the ball and a small image patch is cropped based on the prediction. Then, the object detector is utilized to refine the location of the ball and update the parameters of Kalman filter. In order to train the detection models and test the tracking algorithm, a collection of golf ball dataset is created and annotated. Extensive comparative experiments are performed to demonstrate the effectiveness and superior tracking performance of the proposed scheme.