 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-Caption Encoding for Improving Zero-Shot Generalization
Feb 05, 2024
Recent advances in vision-language models have combined contrastive approaches with generative methods to achieve state-of-the-art (SOTA) on downstream inference tasks like zero-shot image classification. However, a persistent issue of these models for image classification is their out-of-distribution (OOD) generalization capabilities. We first show that when an OOD data point is misclassified, the correct class can be typically found in the Top-K predicted classes. In order to steer the model prediction toward the correct class within the top predicted classes, we propose the Image-Caption Encoding (ICE) method, a straightforward approach that directly enforces consistency between the image-conditioned and caption-conditioned predictions at evaluation time only. Intuitively, we take advantage of unique properties of the generated captions to guide our local search for the correct class label within the Top-K predicted classes. We show that our method can be easily combined with other SOTA methods to enhance Top-1 OOD accuracies by 0.5% on average and up to 3% on challenging datasets. Our code: https://github.com/Chris210634/ice
ManiFPT: Defining and Analyzing Fingerprints of Generative Models
Feb 29, 2024Recent works have shown that generative models leave traces of their underlying generative process on the generated samples, broadly referred to as fingerprints of a generative model, and have studied their utility in detecting synthetic images from real ones. However, the extend to which these fingerprints can distinguish between various types of synthetic image and help identify the underlying generative process remain under-explored. In particular, the very definition of a fingerprint remains unclear, to our knowledge. To that end, in this work, we formalize the definition of artifact and fingerprint in generative models, propose an algorithm for computing them in practice, and finally study its effectiveness in distinguishing a large array of different generative models. We find that using our proposed definition can significantly improve the performance on the task of identifying the underlying generative process from samples (model attribution) compared to existing methods. Additionally, we study the structure of the fingerprints, and observe that it is very predictive of the effect of different design choices on the generative process.
DreamMatcher: Appearance Matching Self-Attention for Semantically-Consistent Text-to-Image Personalization
Feb 15, 2024The objective of text-to-image (T2I) personalization is to customize a diffusion model to a user-provided reference concept, generating diverse images of the concept aligned with the target prompts. Conventional methods representing the reference concepts using unique text embeddings often fail to accurately mimic the appearance of the reference. To address this, one solution may be explicitly conditioning the reference images into the target denoising process, known as key-value replacement. However, prior works are constrained to local editing since they disrupt the structure path of the pre-trained T2I model. To overcome this, we propose a novel plug-in method, called DreamMatcher, which reformulates T2I personalization as semantic matching. Specifically, DreamMatcher replaces the target values with reference values aligned by semantic matching, while leaving the structure path unchanged to preserve the versatile capability of pre-trained T2I models for generating diverse structures. We also introduce a semantic-consistent masking strategy to isolate the personalized concept from irrelevant regions introduced by the target prompts. Compatible with existing T2I models, DreamMatcher shows significant improvements in complex scenarios. Intensive analyses demonstrate the effectiveness of our approach.
GEA: Reconstructing Expressive 3D Gaussian Avatar from Monocular Video
Feb 26, 2024This paper presents GEA, a novel method for creating expressive 3D avatars with high-fidelity reconstructions of body and hands based on 3D Gaussians. The key contributions are twofold. First, we design a two-stage pose estimation method to obtain an accurate SMPL-X pose from input images, providing a correct mapping between the pixels of a training image and the SMPL-X model. It uses an attention-aware network and an optimization scheme to align the normal and silhouette between the estimated SMPL-X body and the real body in the image. Second, we propose an iterative re-initialization strategy to handle unbalanced aggregation and initialization bias faced by Gaussian representation. This strategy iteratively redistributes the avatar's Gaussian points, making it evenly distributed near the human body surface by applying meshing, resampling and re-Gaussian operations. As a result, higher-quality rendering can be achieved. Extensive experimental analyses validate the effectiveness of the proposed model, demonstrating that it achieves state-of-the-art performance in photorealistic novel view synthesis while offering fine-grained control over the human body and hand pose. Project page: https://3d-aigc.github.io/GEA/.
A Multispectral Automated Transfer Technique (MATT) for machine-driven image labeling utilizing the Segment Anything Model (SAM)
Feb 18, 2024Segment Anything Model (SAM) is drastically accelerating the speed and accuracy of automatically segmenting and labeling large Red-Green-Blue (RGB) imagery datasets. However, SAM is unable to segment and label images outside of the visible light spectrum, for example, for multispectral or hyperspectral imagery. Therefore, this paper outlines a method we call the Multispectral Automated Transfer Technique (MATT). By transposing SAM segmentation masks from RGB images we can automatically segment and label multispectral imagery with high precision and efficiency. For example, the results demonstrate that segmenting and labeling a 2,400-image dataset utilizing MATT achieves a time reduction of 87.8% in developing a trained model, reducing roughly 20 hours of manual labeling, to only 2.4 hours. This efficiency gain is associated with only a 6.7% decrease in overall mean average precision (mAP) when training multispectral models via MATT, compared to a manually labeled dataset. We consider this an acceptable level of precision loss when considering the time saved during training, especially for rapidly prototyping experimental modeling methods. This research greatly contributes to the study of multispectral object detection by providing a novel and open-source method to rapidly segment, label, and train multispectral object detection models with minimal human interaction. Future research needs to focus on applying these methods to (i) space-based multispectral, and (ii) drone-based hyperspectral imagery.
Understanding Likelihood of Normalizing Flow and Image Complexity through the Lens of Out-of-Distribution Detection
Feb 16, 2024Out-of-distribution (OOD) detection is crucial to safety-critical machine learning applications and has been extensively studied. While recent studies have predominantly focused on classifier-based methods, research on deep generative model (DGM)-based methods have lagged relatively. This disparity may be attributed to a perplexing phenomenon: DGMs often assign higher likelihoods to unknown OOD inputs than to their known training data. This paper focuses on explaining the underlying mechanism of this phenomenon. We propose a hypothesis that less complex images concentrate in high-density regions in the latent space, resulting in a higher likelihood assignment in the Normalizing Flow (NF). We experimentally demonstrate its validity for five NF architectures, concluding that their likelihood is untrustworthy. Additionally, we show that this problem can be alleviated by treating image complexity as an independent variable. Finally, we provide evidence of the potential applicability of our hypothesis in another DGM, PixelCNN++.
Semi-supervised Medical Image Segmentation Method Based on Cross-pseudo Labeling Leveraging Strong and Weak Data Augmentation Strategies
Feb 17, 2024Traditional supervised learning methods have historically encountered certain constraints in medical image segmentation due to the challenging collection process, high labeling cost, low signal-to-noise ratio, and complex features characterizing biomedical images. This paper proposes a semi-supervised model, DFCPS, which innovatively incorporates the Fixmatch concept. This significantly enhances the model's performance and generalizability through data augmentation processing, employing varied strategies for unlabeled data. Concurrently, the model design gives appropriate emphasis to the generation, filtration, and refinement processes of pseudo-labels. The novel concept of cross-pseudo-supervision is introduced, integrating consistency learning with self-training. This enables the model to fully leverage pseudo-labels from multiple perspectives, thereby enhancing training diversity. The DFCPS model is compared with both baseline and advanced models using the publicly accessible Kvasir-SEG dataset. Across all four subdivisions containing different proportions of unlabeled data, our model consistently exhibits superior performance. Our source code is available at https://github.com/JustlfC03/DFCPS.
* 5 pages, 2 figures, accept ISBI2024
Compressed image quality assessment using stacking
Feb 01, 2024It is well-known that there is no universal metric for image quality evaluation. In this case, distortion-specific metrics can be more reliable. The artifact imposed by image compression can be considered as a combination of various distortions. Depending on the image context, this combination can be different. As a result, Generalization can be regarded as the major challenge in compressed image quality assessment. In this approach, stacking is employed to provide a reliable method. Both semantic and low-level information are employed in the presented IQA to predict the human visual system. Moreover, the results of the Full-Reference (FR) and No-Reference (NR) models are aggregated to improve the proposed Full-Reference method for compressed image quality evaluation. The accuracy of the quality benchmark of the clic2024 perceptual image challenge was achieved 79.6\%, which illustrates the effectiveness of the proposed fusion-based approach.
TempCompass: Do Video LLMs Really Understand Videos?
Mar 01, 2024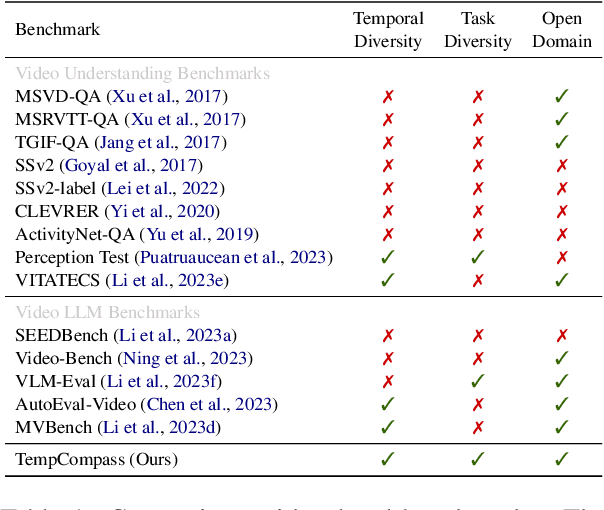
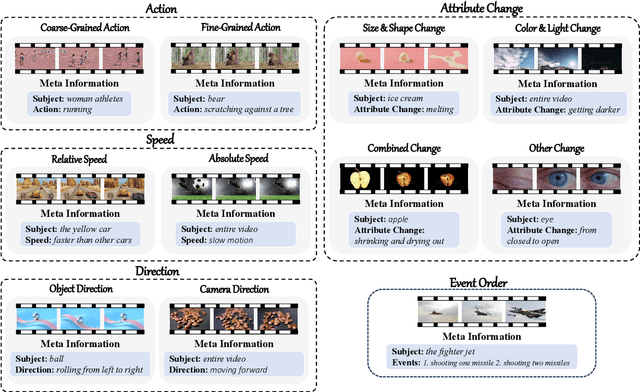
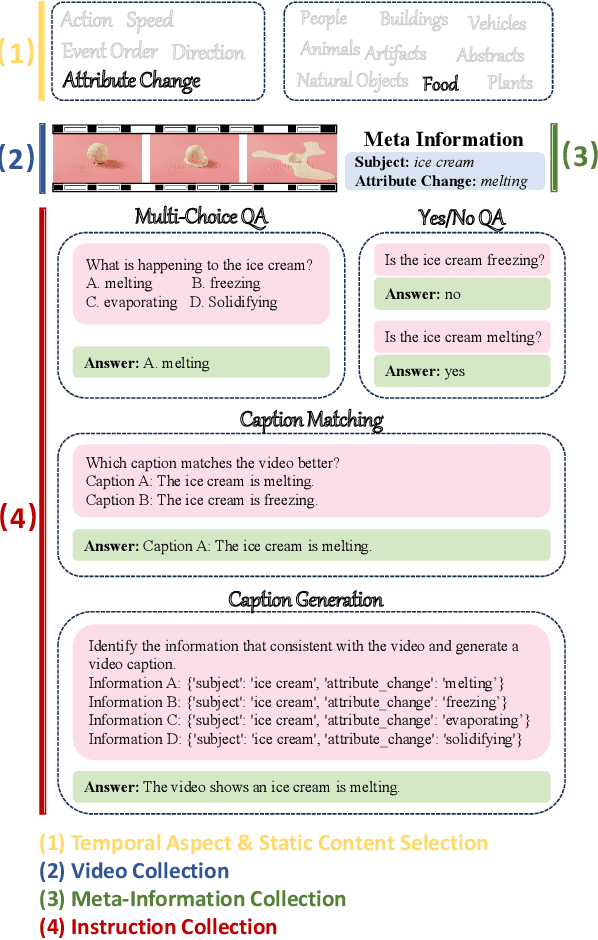
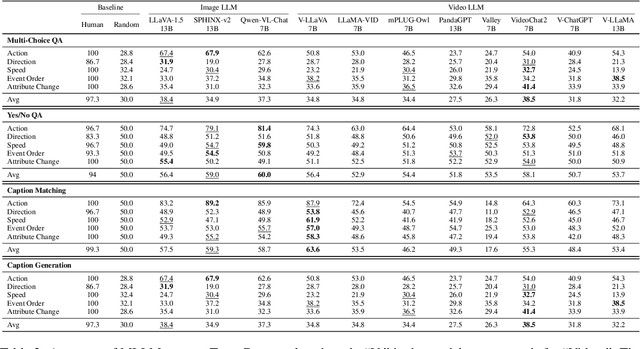
Recently, there is a surge in interest surrounding video large language models (Video LLMs). However, existing benchmarks fail to provide a comprehensive feedback on the temporal perception ability of Video LLMs. On the one hand, most of them are unable to distinguish between different temporal aspects (e.g., speed, direction) and thus cannot reflect the nuanced performance on these specific aspects. On the other hand, they are limited in the diversity of task formats (e.g., only multi-choice QA), which hinders the understanding of how temporal perception performance may vary across different types of tasks. Motivated by these two problems, we propose the \textbf{TempCompass} benchmark, which introduces a diversity of temporal aspects and task formats. To collect high-quality test data, we devise two novel strategies: (1) In video collection, we construct conflicting videos that share the same static content but differ in a specific temporal aspect, which prevents Video LLMs from leveraging single-frame bias or language priors. (2) To collect the task instructions, we propose a paradigm where humans first annotate meta-information for a video and then an LLM generates the instruction. We also design an LLM-based approach to automatically and accurately evaluate the responses from Video LLMs. Based on TempCompass, we comprehensively evaluate 8 state-of-the-art (SOTA) Video LLMs and 3 Image LLMs, and reveal the discerning fact that these models exhibit notably poor temporal perception ability. Our data will be available at \url{https://github.com/llyx97/TempCompass}.
Compact and De-biased Negative Instance Embedding for Multi-Instance Learning on Whole-Slide Image Classification
Feb 16, 2024Whole-slide image (WSI) classification is a challenging task because 1) patches from WSI lack annotation, and 2) WSI possesses unnecessary variability, e.g., stain protocol. Recently, Multiple-Instance Learning (MIL) has made significant progress, allowing for classification based on slide-level, rather than patch-level, annotations. However, existing MIL methods ignore that all patches from normal slides are normal. Using this free annotation, we introduce a semi-supervision signal to de-bias the inter-slide variability and to capture the common factors of variation within normal patches. Because our method is orthogonal to the MIL algorithm, we evaluate our method on top of the recently proposed MIL algorithms and also compare the performance with other semi-supervised approaches. We evaluate our method on two public WSI datasets including Camelyon-16 and TCGA lung cancer and demonstrate that our approach significantly improves the predictive performance of existing MIL algorithms and outperforms other semi-supervised algorithms. We release our code at https://github.com/AITRICS/pathology_mil.