 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Object Detection Models for Electrical Substation Component Mapping
Dec 27, 2025Electrical substations are a significant component of an electrical grid. Indeed, the assets at these substations (e.g., transformers) are prone to disruption from many hazards, including hurricanes, flooding, earthquakes, and geomagnetically induced currents (GICs). As electrical grids are considered critical national infrastructure, any failure can have significant economic and public safety implications. To help prevent and mitigate these failures, it is thus essential that we identify key substation components to quantify vulnerability. Unfortunately, traditional manual mapping of substation infrastructure is time-consuming and labor-intensive. Therefore, an autonomous solution utilizing computer vision models is preferable, as it allows for greater convenience and efficiency. In this research paper, we train and compare the outputs of 3 models (YOLOv8, YOLOv11, RF-DETR) on a manually labeled dataset of US substation images. Each model is evaluated for detection accuracy, precision, and efficiency. We present the key strengths and limitations of each model, identifying which provides reliable and large-scale substation component mapping. Additionally, we utilize these models to effectively map the various substation components in the United States, showcasing a use case for machine learning in substation mapping.
Evaluating an Adaptive Multispectral Turret System for Autonomous Tracking Across Variable Illumination Conditions
Dec 24, 2025Autonomous robotic platforms are playing a growing role across the emergency services sector, supporting missions such as search and rescue operations in disaster zones and reconnaissance. However, traditional red-green-blue (RGB) detection pipelines struggle in low-light environments, and thermal-based systems lack color and texture information. To overcome these limitations, we present an adaptive framework that fuses RGB and long-wave infrared (LWIR) video streams at multiple fusion ratios and dynamically selects the optimal detection model for each illumination condition. We trained 33 You Only Look Once (YOLO) models on over 22,000 annotated images spanning three light levels: no-light (<10 lux), dim-light (10-1000 lux), and full-light (>1000 lux). To integrate both modalities, fusion was performed by blending aligned RGB and LWIR frames at eleven ratios, from full RGB (100/0) to full LWIR (0/100) in 10% increments. Evaluation showed that the best full-light model (80/20 RGB-LWIR) and dim-light model (90/10 fusion) achieved 92.8% and 92.0% mean confidence; both significantly outperformed the YOLOv5 nano (YOLOv5n) and YOLOv11 nano (YOLOv11n) baselines. Under no-light conditions, the top 40/60 fusion reached 71.0%, exceeding baselines though not statistically significant. Adaptive RGB-LWIR fusion improved detection confidence and reliability across all illumination conditions, enhancing autonomous robotic vision performance.
Multi-temporal Adaptive Red-Green-Blue and Long-Wave Infrared Fusion for You Only Look Once-Based Landmine Detection from Unmanned Aerial Systems
Dec 23, 2025



Landmines remain a persistent humanitarian threat, with 110 million actively deployed mines across 60 countries, claiming 26,000 casualties annually. This research evaluates adaptive Red-Green-Blue (RGB) and Long-Wave Infrared (LWIR) fusion for Unmanned Aerial Systems (UAS)-based detection of surface-laid landmines, leveraging the thermal contrast between the ordnance and the surrounding soil to enhance feature extraction. Using You Only Look Once (YOLO) architectures (v8, v10, v11) across 114 test images, generating 35,640 model-condition evaluations, YOLOv11 achieved optimal performance (86.8% mAP), with 10 to 30% thermal fusion at 5 to 10m altitude identified as the optimal detection parameters. A complementary architectural comparison revealed that while RF-DETR achieved the highest accuracy (69.2% mAP), followed by Faster R-CNN (67.6%), YOLOv11 (64.2%), and RetinaNet (50.2%), YOLOv11 trained 17.7 times faster than the transformer-based RF-DETR (41 minutes versus 12 hours), presenting a critical accuracy-efficiency tradeoff for operational deployment. Aggregated multi-temporal training datasets outperformed season-specific approaches by 1.8 to 9.6%, suggesting that models benefit from exposure to diverse thermal conditions. Anti-Tank (AT) mines achieved 61.9% detection accuracy, compared with 19.2% for Anti-Personnel (AP) mines, reflecting both the size differential and thermal-mass differences between these ordnance classes. As this research examined surface-laid mines where thermal contrast is maximized, future research should quantify thermal contrast effects for mines buried at varying depths across heterogeneous soil types.
AMLID: An Adaptive Multispectral Landmine Identification Dataset for Drone-Based Detection
Dec 21, 2025Landmines remain a persistent humanitarian threat, with an estimated 110 million mines deployed across 60 countries, claiming approximately 26,000 casualties annually. Current detection methods are hazardous, inefficient, and prohibitively expensive. We present the Adaptive Multispectral Landmine Identification Dataset (AMLID), the first open-source dataset combining Red-Green-Blue (RGB) and Long-Wave Infrared (LWIR) imagery for Unmanned Aerial Systems (UAS)-based landmine detection. AMLID comprises of 12,078 labeled images featuring 21 globally deployed landmine types across anti-personnel and anti-tank categories in both metal and plastic compositions. The dataset spans 11 RGB-LWIR fusion levels, four sensor altitudes, two seasonal periods, and three daily illumination conditions. By providing comprehensive multispectral coverage across diverse environmental variables, AMLID enables researchers to develop and benchmark adaptive detection algorithms without requiring access to live ordnance or expensive data collection infrastructure, thereby democratizing humanitarian demining research.
VORTEX: A Spatial Computing Framework for Optimized Drone Telemetry Extraction from First-Person View Flight Data
Dec 24, 2024



This paper presents the Visual Optical Recognition Telemetry EXtraction (VORTEX) system for extracting and analyzing drone telemetry data from First Person View (FPV) Uncrewed Aerial System (UAS) footage. VORTEX employs MMOCR, a PyTorch-based Optical Character Recognition (OCR) toolbox, to extract telemetry variables from drone Heads Up Display (HUD) recordings, utilizing advanced image preprocessing techniques, including CLAHE enhancement and adaptive thresholding. The study optimizes spatial accuracy and computational efficiency through systematic investigation of temporal sampling rates (1s, 5s, 10s, 15s, 20s) and coordinate processing methods. Results demonstrate that the 5-second sampling rate, utilizing 4.07% of available frames, provides the optimal balance with a point retention rate of 64% and mean speed accuracy within 4.2% of the 1-second baseline while reducing computational overhead by 80.5%. Comparative analysis of coordinate processing methods reveals that while UTM Zone 33N projection and Haversine calculations provide consistently similar results (within 0.1% difference), raw WGS84 coordinates underestimate distances by 15-30% and speeds by 20-35%. Altitude measurements showed unexpected resilience to sampling rate variations, with only 2.1% variation across all intervals. This research is the first of its kind, providing quantitative benchmarks for establishing a robust framework for drone telemetry extraction and analysis using open-source tools and spatial libraries.
A Multispectral Automated Transfer Technique (MATT) for machine-driven image labeling utilizing the Segment Anything Model (SAM)
Feb 18, 2024



Segment Anything Model (SAM) is drastically accelerating the speed and accuracy of automatically segmenting and labeling large Red-Green-Blue (RGB) imagery datasets. However, SAM is unable to segment and label images outside of the visible light spectrum, for example, for multispectral or hyperspectral imagery. Therefore, this paper outlines a method we call the Multispectral Automated Transfer Technique (MATT). By transposing SAM segmentation masks from RGB images we can automatically segment and label multispectral imagery with high precision and efficiency. For example, the results demonstrate that segmenting and labeling a 2,400-image dataset utilizing MATT achieves a time reduction of 87.8% in developing a trained model, reducing roughly 20 hours of manual labeling, to only 2.4 hours. This efficiency gain is associated with only a 6.7% decrease in overall mean average precision (mAP) when training multispectral models via MATT, compared to a manually labeled dataset. We consider this an acceptable level of precision loss when considering the time saved during training, especially for rapidly prototyping experimental modeling methods. This research greatly contributes to the study of multispectral object detection by providing a novel and open-source method to rapidly segment, label, and train multispectral object detection models with minimal human interaction. Future research needs to focus on applying these methods to (i) space-based multispectral, and (ii) drone-based hyperspectral imagery.
Surveying 5G Techno-Economic Research to Inform the Evaluation of 6G Wireless Technologies
Jan 10, 2022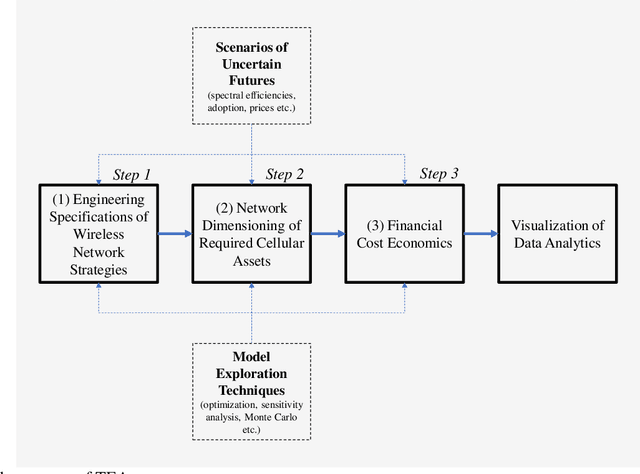
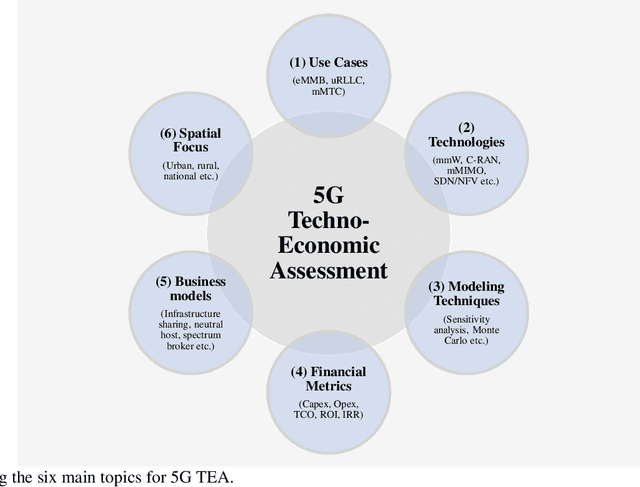
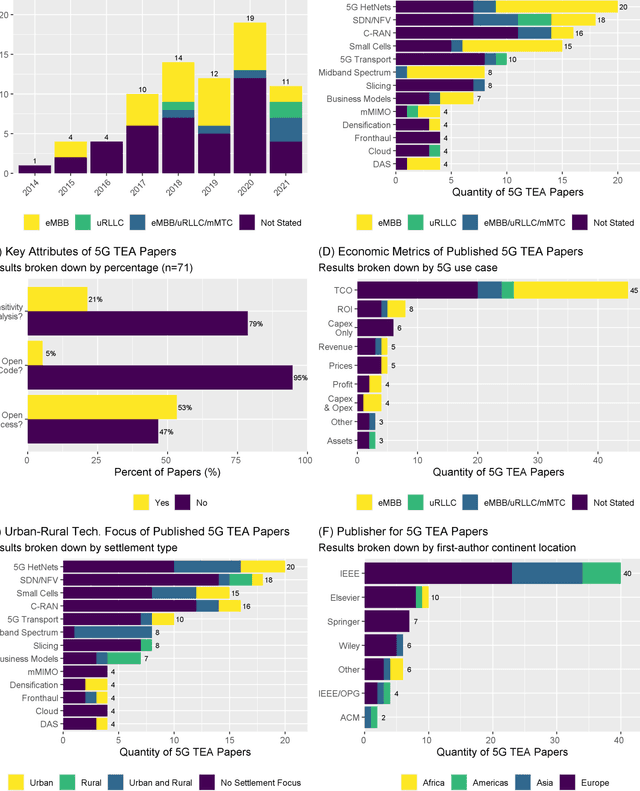
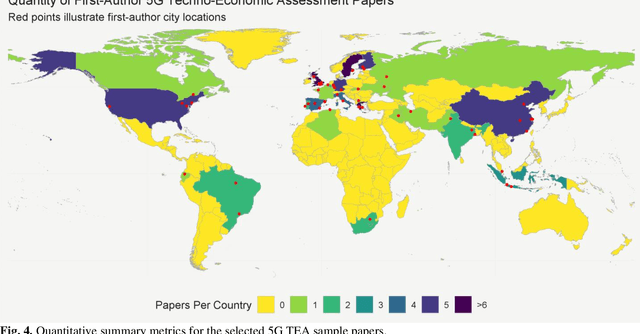
Techno-economic assessment is a fundamental technique engineers use for evaluating new communications technologies. However, despite the techno-economics of the fifth cellular generation (5G) being an active research area, it is surprising there are few comprehensive evaluations of this growing literature. With mobile network operators deploying 5G across their networks, it is therefore an opportune time to appraise current accomplishments and review the state-of-the-art. Such insight can inform the flurry of 6G research papers currently underway and help engineers in their mission to provide affordable high-capacity, low-latency broadband connectivity, globally. The survey discusses emerging trends from the 5G techno-economic literature and makes five key recommendations for the design and standardization of Next Generation 6G wireless technologies.