 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Intrinsic Image Captioning Evaluation
Dec 14, 2020
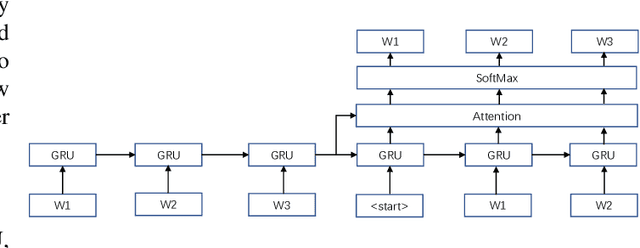
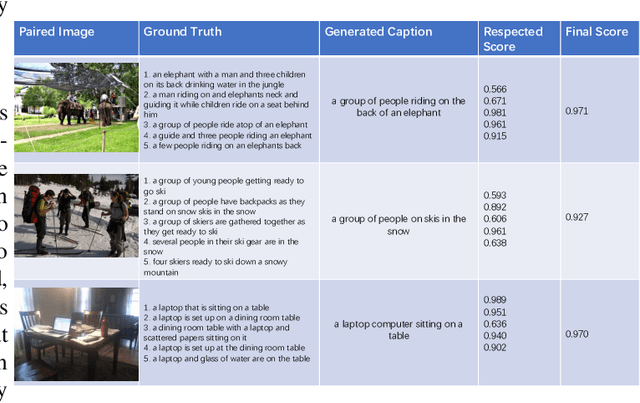
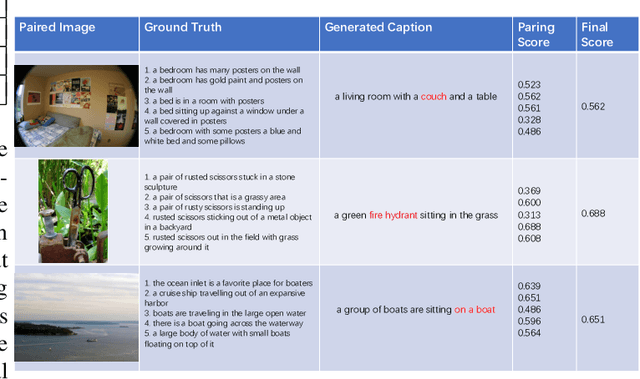
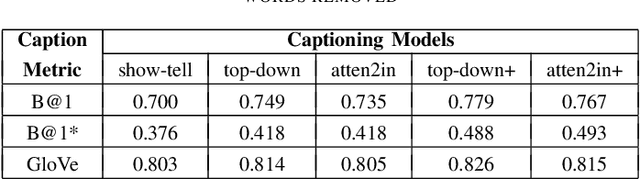
The image captioning task is about to generate suitable descriptions from images. For this task there can be several challenges such as accuracy, fluency and diversity. However there are few metrics that can cover all these properties while evaluating results of captioning models.In this paper we first conduct a comprehensive investigation on contemporary metrics. Motivated by the auto-encoder mechanism and the research advances of word embeddings we propose a learning based metrics for image captioning, which we call Intrinsic Image Captioning Evaluation(I2CE). We select several state-of-the-art image captioning models and test their performances on MS COCO dataset with respects to both contemporary metrics and the proposed I2CE. Experiment results show that our proposed method can keep robust performance and give more flexible scores to candidate captions when encountered with semantic similar expression or less aligned semantics. On this concern the proposed metric could serve as a novel indicator on the intrinsic information between captions, which may be complementary to the existing ones.
Shifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022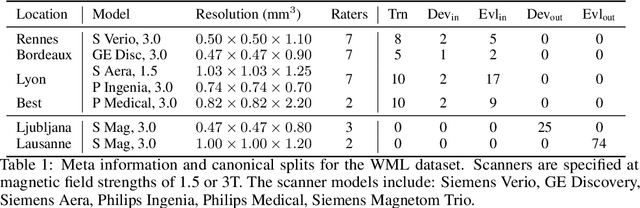
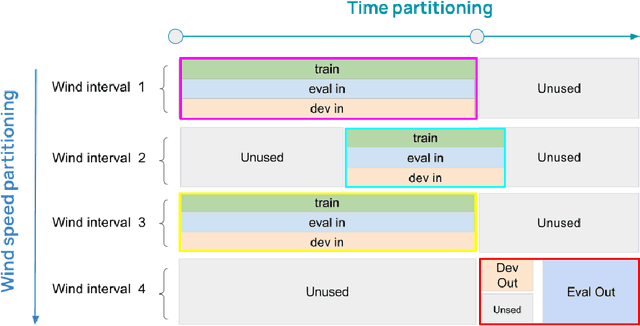
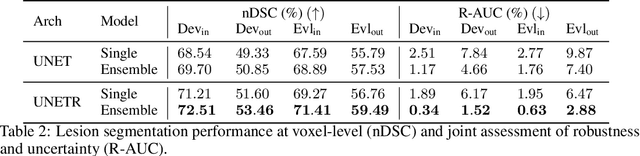
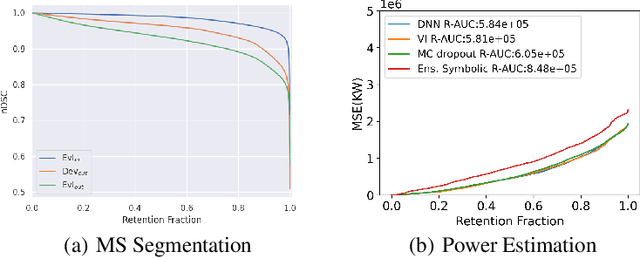
Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.
All the attention you need: Global-local, spatial-channel attention for image retrieval
Jul 16, 2021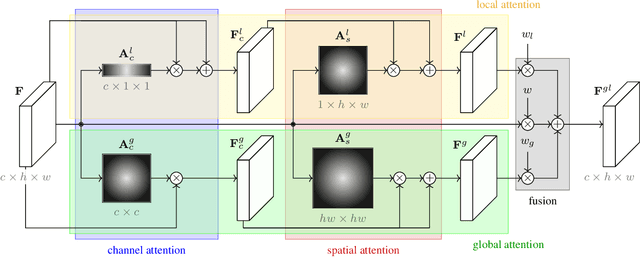
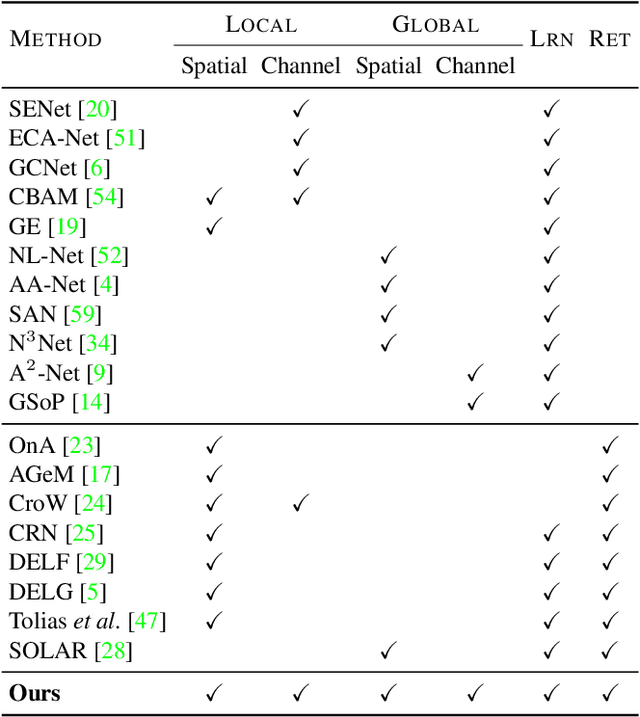
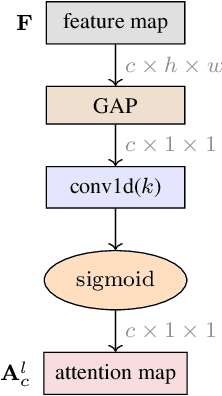
We address representation learning for large-scale instance-level image retrieval. Apart from backbone, training pipelines and loss functions, popular approaches have focused on different spatial pooling and attention mechanisms, which are at the core of learning a powerful global image representation. There are different forms of attention according to the interaction of elements of the feature tensor (local and global) and the dimensions where it is applied (spatial and channel). Unfortunately, each study addresses only one or two forms of attention and applies it to different problems like classification, detection or retrieval. We present global-local attention module (GLAM), which is attached at the end of a backbone network and incorporates all four forms of attention: local and global, spatial and channel. We obtain a new feature tensor and, by spatial pooling, we learn a powerful embedding for image retrieval. Focusing on global descriptors, we provide empirical evidence of the interaction of all forms of attention and improve the state of the art on standard benchmarks.
Cross-modal Image Retrieval with Deep Mutual Information Maximization
Mar 10, 2021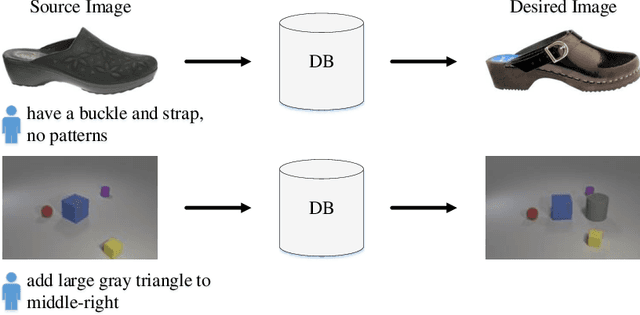
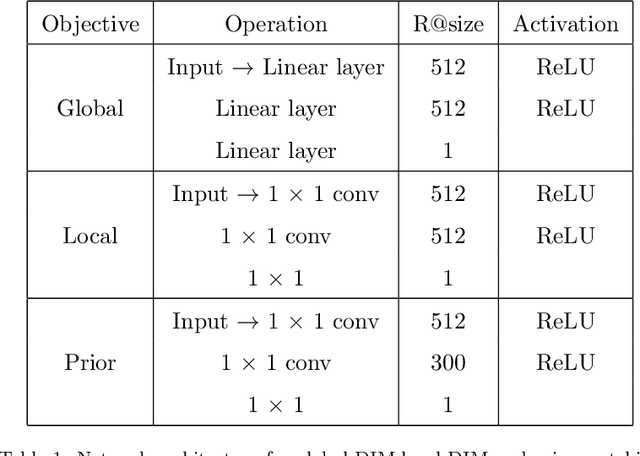
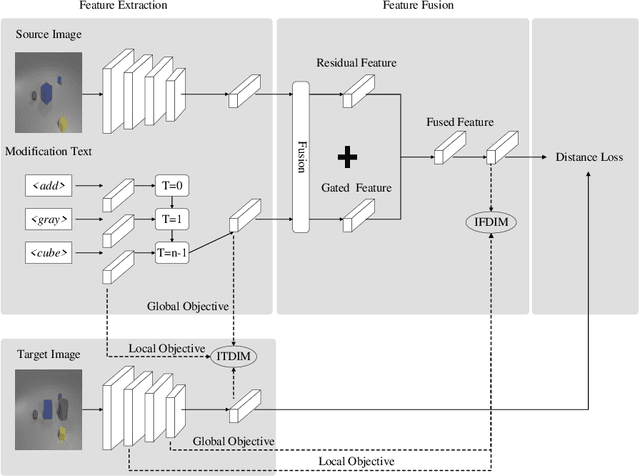
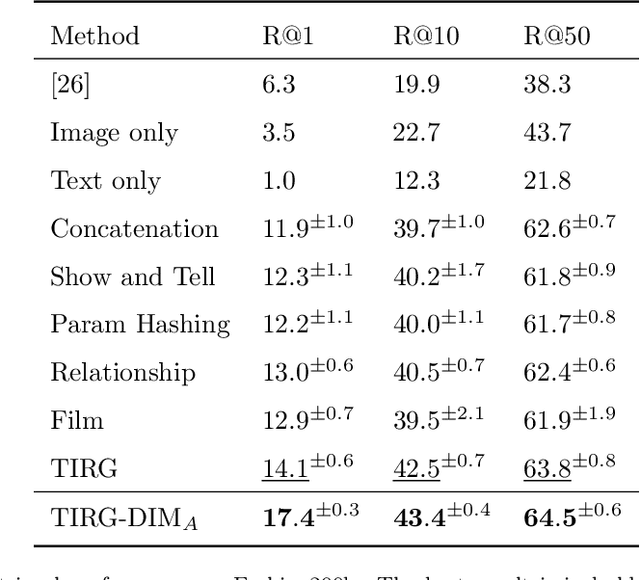
In this paper, we study the cross-modal image retrieval, where the inputs contain a source image plus some text that describes certain modifications to this image and the desired image. Prior work usually uses a three-stage strategy to tackle this task: 1) extract the features of the inputs; 2) fuse the feature of the source image and its modified text to obtain fusion feature; 3) learn a similarity metric between the desired image and the source image + modified text by using deep metric learning. Since classical image/text encoders can learn the useful representation and common pair-based loss functions of distance metric learning are enough for cross-modal retrieval, people usually improve retrieval accuracy by designing new fusion networks. However, these methods do not successfully handle the modality gap caused by the inconsistent distribution and representation of the features of different modalities, which greatly influences the feature fusion and similarity learning. To alleviate this problem, we adopt the contrastive self-supervised learning method Deep InforMax (DIM) to our approach to bridge this gap by enhancing the dependence between the text, the image, and their fusion. Specifically, our method narrows the modality gap between the text modality and the image modality by maximizing mutual information between their not exactly semantically identical representation. Moreover, we seek an effective common subspace for the semantically same fusion feature and desired image's feature by utilizing Deep InforMax between the low-level layer of the image encoder and the high-level layer of the fusion network. Extensive experiments on three large-scale benchmark datasets show that we have bridged the modality gap between different modalities and achieve state-of-the-art retrieval performance.
Multifocus microscopy with optically sectioned axial superresolution
Jun 02, 2022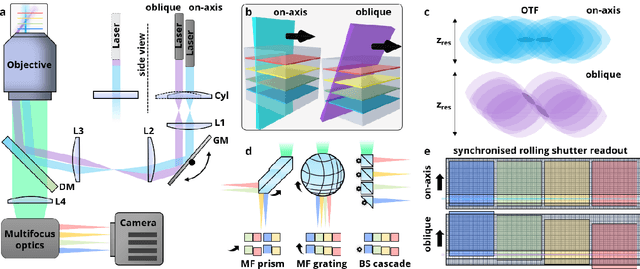
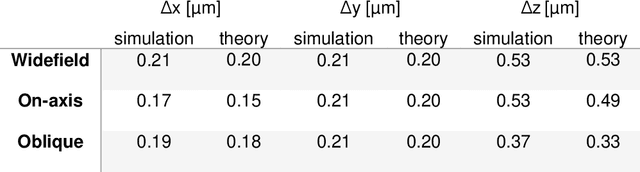
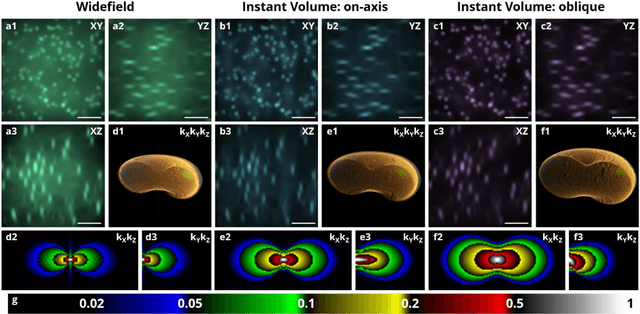
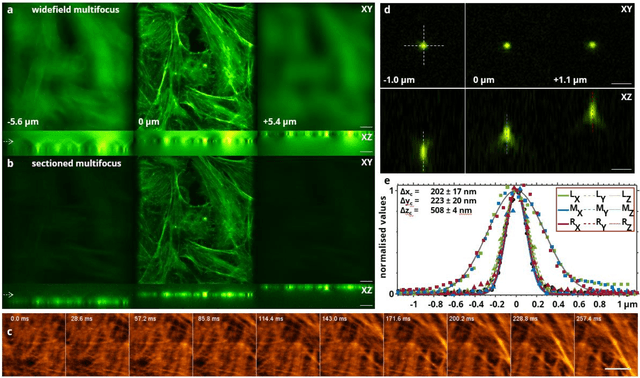
Multifocus microscopy enables recording of entire volumes in a single camera exposure. In dense samples, multifocus microscopy is severely hampered by background haze. Here, we introduce a scalable multifocus method that incorporates optical sectioning and offers axial superresolution capabilities. In our method, a dithered oblique light-sheet scans the sample volume during a single exposure, while generated fluorescence is linearised onto the camera with a multifocus optical element. A synchronised rolling shutter readout realised optical sectioning. We describe the technique theoretically and verify its optical sectioning and superresolution capabilities. We demonstrate a prototype system with a multifocus beam splitter cascade and record monolayers of endothelial cells at 35 volumes per second. We furthermore image uncleared engineered human heart tissue and visualise the distribution of mitochondria at axial superresolution. Our method manages to capture sub-diffraction sized mitochondria-derived vesicles up to 30 um deep into the tissue.
Learning to Erase the Bayer-Filter to See in the Dark
Mar 08, 2022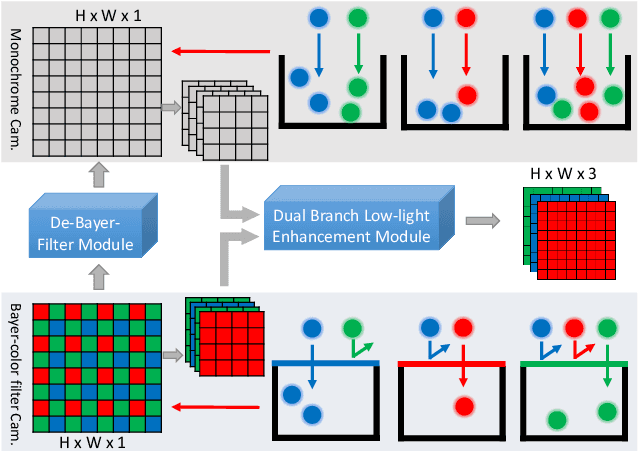


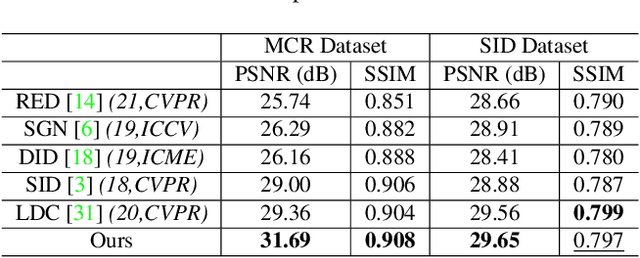
Low-light image enhancement - a pervasive but challenging problem, plays a central role in enhancing the visibility of an image captured in a poor illumination environment. Due to the fact that not all photons can pass the Bayer-Filter on the sensor of the color camera, in this work, we first present a De-Bayer-Filter simulator based on deep neural networks to generate a monochrome raw image from the colored raw image. Next, a fully convolutional network is proposed to achieve the low-light image enhancement by fusing colored raw data with synthesized monochrome raw data. Channel-wise attention is also introduced to the fusion process to establish a complementary interaction between features from colored and monochrome raw images. To train the convolutional networks, we propose a dataset with monochrome and color raw pairs named Mono-Colored Raw paired dataset (MCR) collected by using a monochrome camera without Bayer-Filter and a color camera with Bayer-Filter. The proposed pipeline take advantages of the fusion of the virtual monochrome and the color raw images and our extensive experiments indicate that significant improvement can be achieved by leveraging raw sensor data and data-driven learning.
A Comparative Study of Feature Expansion Unit for 3D Point Cloud Upsampling
May 19, 2022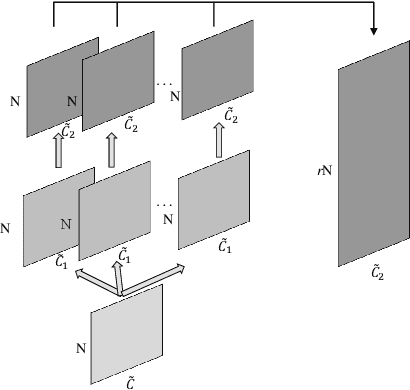
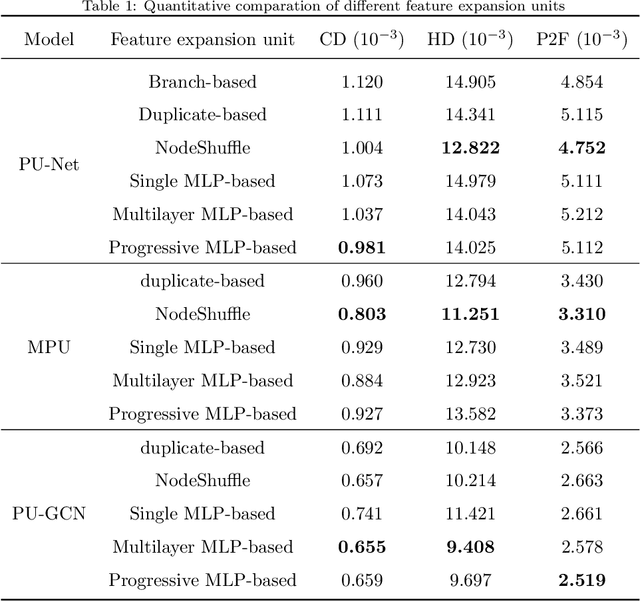
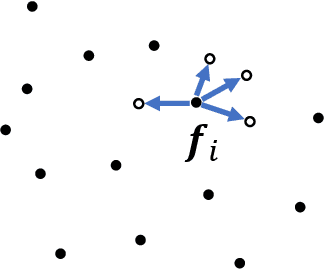
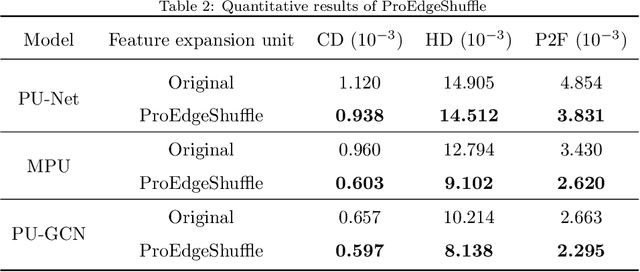
Recently, deep learning methods have shown great success in 3D point cloud upsampling. Among these methods, many feature expansion units were proposed to complete point expansion at the end. In this paper, we compare various feature expansion units by both theoretical analysis and quantitative experiments. We show that most of the existing feature expansion units process each point feature independently, while ignoring the feature interaction among different points. Further, inspired by upsampling module of image super-resolution and recent success of dynamic graph CNN on point clouds, we propose a novel feature expansion units named ProEdgeShuffle. Experiments show that our proposed method can achieve considerable improvement over previous feature expansion units.
Split Hierarchical Variational Compression
Apr 05, 2022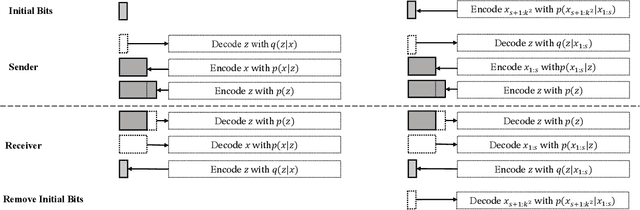
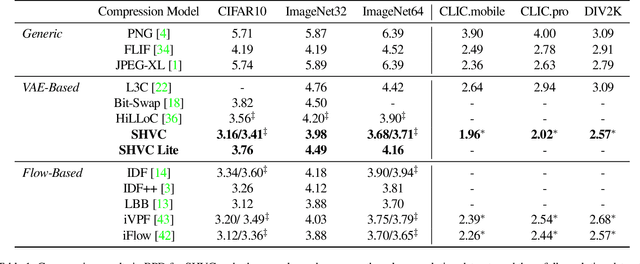
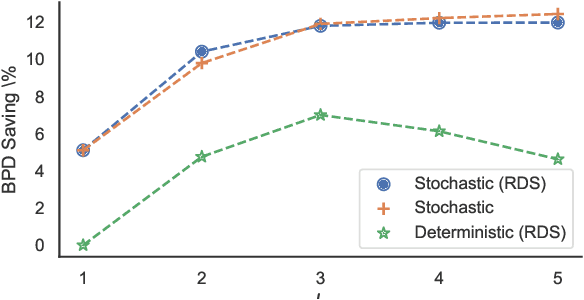
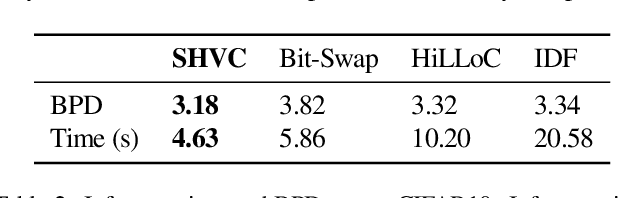
Variational autoencoders (VAEs) have witnessed great success in performing the compression of image datasets. This success, made possible by the bits-back coding framework, has produced competitive compression performance across many benchmarks. However, despite this, VAE architectures are currently limited by a combination of coding practicalities and compression ratios. That is, not only do state-of-the-art methods, such as normalizing flows, often demonstrate out-performance, but the initial bits required in coding makes single and parallel image compression challenging. To remedy this, we introduce Split Hierarchical Variational Compression (SHVC). SHVC introduces two novelties. Firstly, we propose an efficient autoregressive prior, the autoregressive sub-pixel convolution, that allows a generalisation between per-pixel autoregressions and fully factorised probability models. Secondly, we define our coding framework, the autoregressive initial bits, that flexibly supports parallel coding and avoids -- for the first time -- many of the practicalities commonly associated with bits-back coding. In our experiments, we demonstrate SHVC is able to achieve state-of-the-art compression performance across full-resolution lossless image compression tasks, with up to 100x fewer model parameters than competing VAE approaches.
Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
Apr 30, 2022

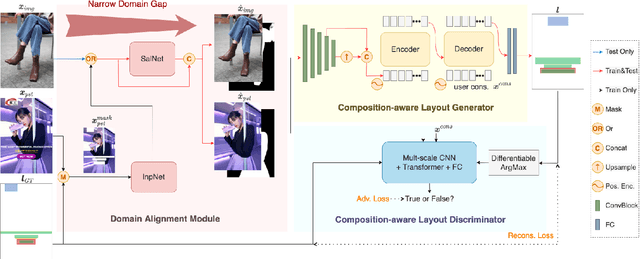

In this paper, we study the graphic layout generation problem of producing high-quality visual-textual presentation designs for given images. We note that image compositions, which contain not only global semantics but also spatial information, would largely affect layout results. Hence, we propose a deep generative model, dubbed as composition-aware graphic layout GAN (CGL-GAN), to synthesize layouts based on the global and spatial visual contents of input images. To obtain training images from images that already contain manually designed graphic layout data, previous work suggests masking design elements (e.g., texts and embellishments) as model inputs, which inevitably leaves hint of the ground truth. We study the misalignment between the training inputs (with hint masks) and test inputs (without masks), and design a novel domain alignment module (DAM) to narrow this gap. For training, we built a large-scale layout dataset which consists of 60,548 advertising posters with annotated layout information. To evaluate the generated layouts, we propose three novel metrics according to aesthetic intuitions. Through both quantitative and qualitative evaluations, we demonstrate that the proposed model can synthesize high-quality graphic layouts according to image compositions.
Multiple EffNet/ResNet Architectures for Melanoma Classification
Apr 21, 2022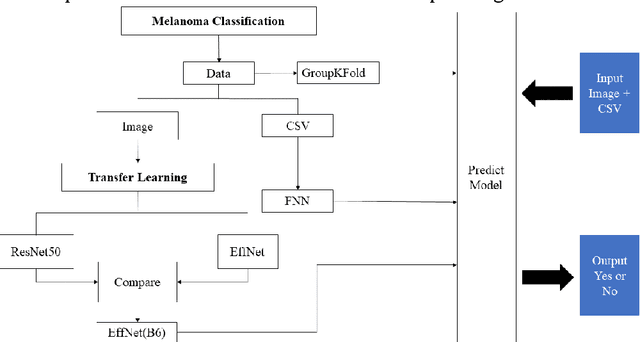

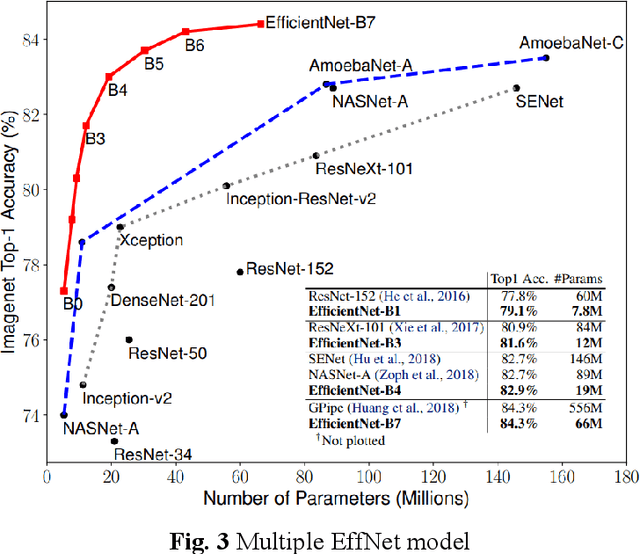
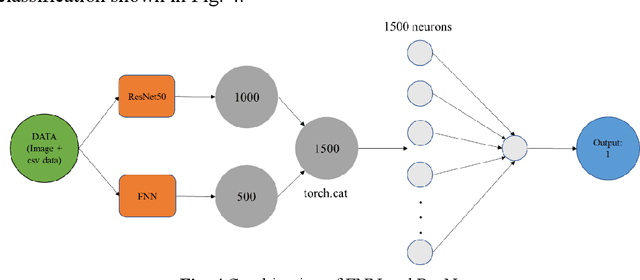
Melanoma is the most malignant skin tumor and usually cancerates from normal moles, which is difficult to distinguish benign from malignant in the early stage. Therefore, many machine learning methods are trying to make auxiliary prediction. However, these methods attach more attention to the image data of suspected tumor, and focus on improving the accuracy of image classification, but ignore the significance of patient-level contextual information for disease diagnosis in actual clinical diagnosis. To make more use of patient information and improve the accuracy of diagnosis, we propose a new melanoma classification model based on EffNet and Resnet. Our model not only uses images within the same patient but also consider patient-level contextual information for better cancer prediction. The experimental results demonstrated that the proposed model achieved 0.981 ACC. Furthermore, we note that the overall ROC value of the model is 0.976 which is better than the previous state-of-the-art approaches.
* 16 pages,20 figures