 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventFace: Event-Based Face Recognition via Structure-Driven Spatiotemporal Modeling
Apr 08, 2026Event cameras offer a promising sensing modality for face recognition due to their inherent advantages in illumination robustness and privacy-friendliness. However, because event streams lack the stable photometric appearance relied upon by conventional RGB-based face recognition systems, we argue that event-based face recognition should model structure-driven spatiotemporal identity representations shaped by rigid facial motion and individual facial geometry. Since dedicated datasets for event-based face recognition remain lacking, we construct EFace, a small-scale event-based face dataset captured under rigid facial motion. To learn effectively from this limited event data, we further propose EventFace, a framework for event-based face recognition that integrates spatial structure and temporal dynamics for identity modeling. Specifically, we employ Low-Rank Adaptation (LoRA) to transfer structural facial priors from pretrained RGB face models to the event domain, thereby establishing a reliable spatial basis for identity modeling. Building on this foundation, we further introduce a Motion Prompt Encoder (MPE) to explicitly encode temporal features and a Spatiotemporal Modulator (STM) to fuse them with spatial features, thereby enhancing the representation of identity-relevant event patterns. Extensive experiments demonstrate that EventFace achieves the best performance among the evaluated baselines, with a Rank-1 identification rate of 94.19% and an equal error rate (EER) of 5.35%. Results further indicate that EventFace exhibits stronger robustness under degraded illumination than the competing methods. In addition, the learned representations exhibit reduced template reconstructability.
UltraGS: Gaussian Splatting for Ultrasound Novel View Synthesis
Nov 11, 2025Ultrasound imaging is a cornerstone of non-invasive clinical diagnostics, yet its limited field of view complicates novel view synthesis. We propose \textbf{UltraGS}, a Gaussian Splatting framework optimized for ultrasound imaging. First, we introduce a depth-aware Gaussian splatting strategy, where each Gaussian is assigned a learnable field of view, enabling accurate depth prediction and precise structural representation. Second, we design SH-DARS, a lightweight rendering function combining low-order spherical harmonics with ultrasound-specific wave physics, including depth attenuation, reflection, and scattering, to model tissue intensity accurately. Third, we contribute the Clinical Ultrasound Examination Dataset, a benchmark capturing diverse anatomical scans under real-world clinical protocols. Extensive experiments on three datasets demonstrate UltraGS's superiority, achieving state-of-the-art results in PSNR (up to 29.55), SSIM (up to 0.89), and MSE (as low as 0.002) while enabling real-time synthesis at 64.69 fps. The code and dataset are open-sourced at: https://github.com/Bean-Young/UltraGS.
Auto-US: An Ultrasound Video Diagnosis Agent Using Video Classification Framework and LLMs
Nov 11, 2025AI-assisted ultrasound video diagnosis presents new opportunities to enhance the efficiency and accuracy of medical imaging analysis. However, existing research remains limited in terms of dataset diversity, diagnostic performance, and clinical applicability. In this study, we propose \textbf{Auto-US}, an intelligent diagnosis agent that integrates ultrasound video data with clinical diagnostic text. To support this, we constructed \textbf{CUV Dataset} of 495 ultrasound videos spanning five categories and three organs, aggregated from multiple open-access sources. We developed \textbf{CTU-Net}, which achieves state-of-the-art performance in ultrasound video classification, reaching an accuracy of 86.73\% Furthermore, by incorporating large language models, Auto-US is capable of generating clinically meaningful diagnostic suggestions. The final diagnostic scores for each case exceeded 3 out of 5 and were validated by professional clinicians. These results demonstrate the effectiveness and clinical potential of Auto-US in real-world ultrasound applications. Code and data are available at: https://github.com/Bean-Young/Auto-US.
Explicit and Implicit Representations in AI-based 3D Reconstruction for Radiology: A systematic literature review
Apr 15, 2025



The demand for high-quality medical imaging in clinical practice and assisted diagnosis has made 3D reconstruction in radiological imaging a key research focus. Artificial intelligence (AI) has emerged as a promising approach to enhancing reconstruction accuracy while reducing acquisition and processing time, thereby minimizing patient radiation exposure and discomfort and ultimately benefiting clinical diagnosis. This review explores state-of-the-art AI-based 3D reconstruction algorithms in radiological imaging, categorizing them into explicit and implicit approaches based on their underlying principles. Explicit methods include point-based, volume-based, and Gaussian representations, while implicit methods encompass implicit prior embedding and neural radiance fields. Additionally, we examine commonly used evaluation metrics and benchmark datasets. Finally, we discuss the current state of development, key challenges, and future research directions in this evolving field. Our project available on: https://github.com/Bean-Young/AI4Med.
Test-Time Domain Generalization via Universe Learning: A Multi-Graph Matching Approach for Medical Image Segmentation
Mar 17, 2025



Despite domain generalization (DG) has significantly addressed the performance degradation of pre-trained models caused by domain shifts, it often falls short in real-world deployment. Test-time adaptation (TTA), which adjusts a learned model using unlabeled test data, presents a promising solution. However, most existing TTA methods struggle to deliver strong performance in medical image segmentation, primarily because they overlook the crucial prior knowledge inherent to medical images. To address this challenge, we incorporate morphological information and propose a framework based on multi-graph matching. Specifically, we introduce learnable universe embeddings that integrate morphological priors during multi-source training, along with novel unsupervised test-time paradigms for domain adaptation. This approach guarantees cycle-consistency in multi-matching while enabling the model to more effectively capture the invariant priors of unseen data, significantly mitigating the effects of domain shifts. Extensive experiments demonstrate that our method outperforms other state-of-the-art approaches on two medical image segmentation benchmarks for both multi-source and single-source domain generalization tasks. The source code is available at https://github.com/Yore0/TTDG-MGM.
Video RWKV:Video Action Recognition Based RWKV
Nov 08, 2024



To address the challenges of high computational costs and long-distance dependencies in exist ing video understanding methods, such as CNNs and Transformers, this work introduces RWKV to the video domain in a novel way. We propose a LSTM CrossRWKV (LCR) framework, designed for spatiotemporal representation learning to tackle the video understanding task. Specifically, the proposed linear complexity LCR incorporates a novel Cross RWKV gate to facilitate interaction be tween current frame edge information and past features, enhancing the focus on the subject through edge features and globally aggregating inter-frame features over time. LCR stores long-term mem ory for video processing through an enhanced LSTM recurrent execution mechanism. By leveraging the Cross RWKV gate and recurrent execution, LCR effectively captures both spatial and temporal features. Additionally, the edge information serves as a forgetting gate for LSTM, guiding long-term memory management.Tube masking strategy reduces redundant information in food and reduces overfitting.These advantages enable LSTM CrossRWKV to set a new benchmark in video under standing, offering a scalable and efficient solution for comprehensive video analysis. All code and models are publicly available.
Face Reconstruction Transfer Attack as Out-of-Distribution Generalization
Jul 02, 2024



Understanding the vulnerability of face recognition systems to malicious attacks is of critical importance. Previous works have focused on reconstructing face images that can penetrate a targeted verification system. Even in the white-box scenario, however, naively reconstructed images misrepresent the identity information, hence the attacks are easily neutralized once the face system is updated or changed. In this paper, we aim to reconstruct face images which are capable of transferring face attacks on unseen encoders. We term this problem as Face Reconstruction Transfer Attack (FRTA) and show that it can be formulated as an out-of-distribution (OOD) generalization problem. Inspired by its OOD nature, we propose to solve FRTA by Averaged Latent Search and Unsupervised Validation with pseudo target (ALSUV). To strengthen the reconstruction attack on OOD unseen encoders, ALSUV reconstructs the face by searching the latent of amortized generator StyleGAN2 through multiple latent optimization, latent optimization trajectory averaging, and unsupervised validation with a pseudo target. We demonstrate the efficacy and generalization of our method on widely used face datasets, accompanying it with extensive ablation studies and visually, qualitatively, and quantitatively analyses. The source code will be released.
IFViT: Interpretable Fixed-Length Representation for Fingerprint Matching via Vision Transformer
Apr 12, 2024



Determining dense feature points on fingerprints used in constructing deep fixed-length representations for accurate matching, particularly at the pixel level, is of significant interest. To explore the interpretability of fingerprint matching, we propose a multi-stage interpretable fingerprint matching network, namely Interpretable Fixed-length Representation for Fingerprint Matching via Vision Transformer (IFViT), which consists of two primary modules. The first module, an interpretable dense registration module, establishes a Vision Transformer (ViT)-based Siamese Network to capture long-range dependencies and the global context in fingerprint pairs. It provides interpretable dense pixel-wise correspondences of feature points for fingerprint alignment and enhances the interpretability in the subsequent matching stage. The second module takes into account both local and global representations of the aligned fingerprint pair to achieve an interpretable fixed-length representation extraction and matching. It employs the ViTs trained in the first module with the additional fully connected layer and retrains them to simultaneously produce the discriminative fixed-length representation and interpretable dense pixel-wise correspondences of feature points. Extensive experimental results on diverse publicly available fingerprint databases demonstrate that the proposed framework not only exhibits superior performance on dense registration and matching but also significantly promotes the interpretability in deep fixed-length representations-based fingerprint matching.
On Computational Entanglement and Its Interpretation in Adversarial Machine Learning
Oct 04, 2023



Adversarial examples in machine learning has emerged as a focal point of research due to their remarkable ability to deceive models with seemingly inconspicuous input perturbations, potentially resulting in severe consequences. In this study, we embark on a comprehensive exploration of adversarial machine learning models, shedding light on their intrinsic complexity and interpretability. Our investigation reveals intriguing links between machine learning model complexity and Einstein's theory of special relativity, through the concept of entanglement. More specific, we define entanglement computationally and demonstrate that distant feature samples can exhibit strong correlations, akin to entanglement in quantum realm. This revelation challenges conventional perspectives in describing the phenomenon of adversarial transferability observed in contemporary machine learning models. By drawing parallels with the relativistic effects of time dilation and length contraction during computation, we gain deeper insights into adversarial machine learning, paving the way for more robust and interpretable models in this rapidly evolving field.
Reconstruct Face from Features Using GAN Generator as a Distribution Constraint
Jun 09, 2022
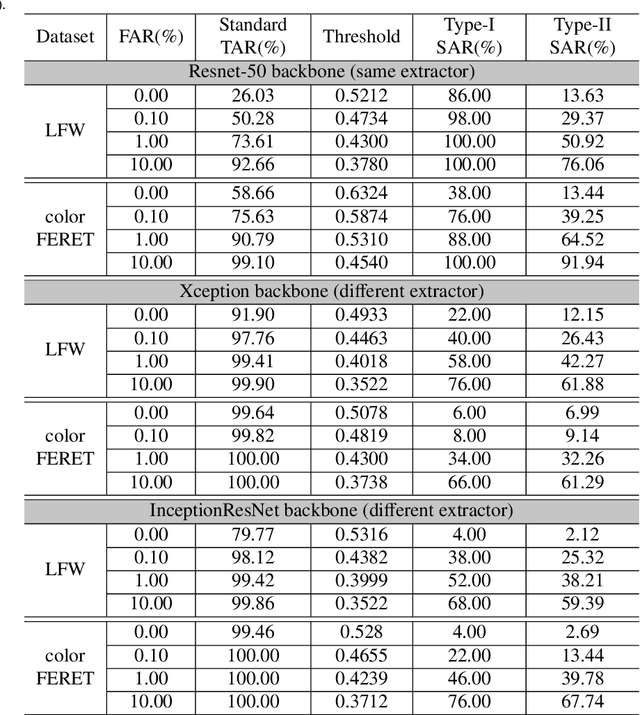
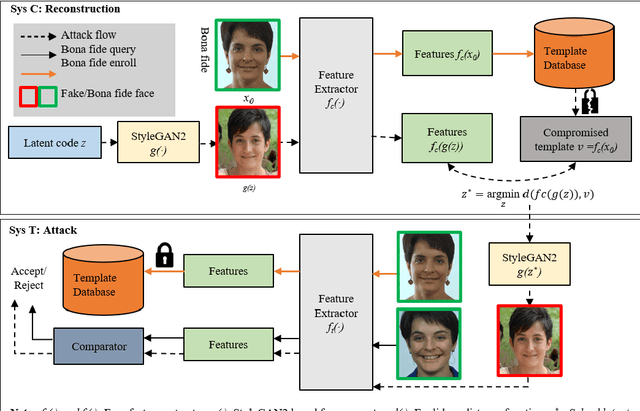
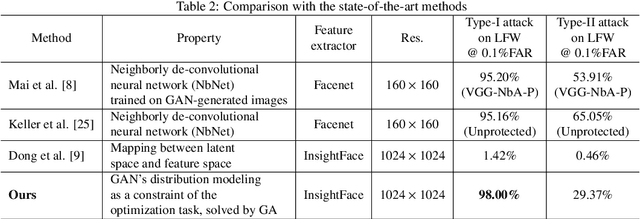
Face recognition based on the deep convolutional neural networks (CNN) shows superior accuracy performance attributed to the high discriminative features extracted. Yet, the security and privacy of the extracted features from deep learning models (deep features) have been often overlooked. This paper proposes the reconstruction of face images from deep features without accessing the CNN network configurations as a constrained optimization problem. Such optimization minimizes the distance between the features extracted from the original face image and the reconstructed face image. Instead of directly solving the optimization problem in the image space, we innovatively reformulate the problem by looking for a latent vector of a GAN generator, then use it to generate the face image. The GAN generator serves as a dual role in this novel framework, i.e., face distribution constraint of the optimization goal and a face generator. On top of the novel optimization task, we also propose an attack pipeline to impersonate the target user based on the generated face image. Our results show that the generated face images can achieve a state-of-the-art successful attack rate of 98.0\% on LFW under type-I attack @ FAR of 0.1\%. Our work sheds light on the biometric deployment to meet the privacy-preserving and security policies.