 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Role of Data Uncertainty in Tabular Deep Learning
Sep 04, 2025



Recent advancements in tabular deep learning have demonstrated exceptional practical performance, yet the field often lacks a clear understanding of why these techniques actually succeed. To address this gap, our paper highlights the importance of the concept of data uncertainty for explaining the effectiveness of the recent tabular DL methods. In particular, we reveal that the success of many beneficial design choices in tabular DL, such as numerical feature embeddings, retrieval-augmented models and advanced ensembling strategies, can be largely attributed to their implicit mechanisms for managing high data uncertainty. By dissecting these mechanisms, we provide a unifying understanding of the recent performance improvements. Furthermore, the insights derived from this data-uncertainty perspective directly allowed us to develop more effective numerical feature embeddings as an immediate practical outcome of our analysis. Overall, our work paves the way to foundational understanding of the benefits introduced by modern tabular methods that results in the concrete advancements of existing techniques and outlines future research directions for tabular DL.
On Finetuning Tabular Foundation Models
Jun 11, 2025



Foundation models are an emerging research direction in tabular deep learning. Notably, TabPFNv2 recently claimed superior performance over traditional GBDT-based methods on small-scale datasets using an in-context learning paradigm, which does not adapt model parameters to target datasets. However, the optimal finetuning approach for adapting tabular foundational models, and how this adaptation reshapes their internal mechanisms, remains underexplored. While prior works studied finetuning for earlier foundational models, inconsistent findings and TabPFNv2's unique architecture necessitate fresh investigation. To address these questions, we first systematically evaluate various finetuning strategies on diverse datasets. Our findings establish full finetuning as the most practical solution for TabPFNv2 in terms of time-efficiency and effectiveness. We then investigate how finetuning alters TabPFNv2's inner mechanisms, drawing an analogy to retrieval-augmented models. We reveal that the success of finetuning stems from the fact that after gradient-based adaptation, the dot products of the query-representations of test objects and the key-representations of in-context training objects more accurately reflect their target similarity. This improved similarity allows finetuned TabPFNv2 to better approximate target dependency by appropriately weighting relevant in-context samples, improving the retrieval-based prediction logic. From the practical perspective, we managed to finetune TabPFNv2 on datasets with up to 50K objects, observing performance improvements on almost all tasks. More precisely, on academic datasets with I.I.D. splits, finetuning allows TabPFNv2 to achieve state-of-the-art results, while on datasets with gradual temporal shifts and rich feature sets, TabPFNv2 is less stable and prior methods remain better.
TabReD: A Benchmark of Tabular Machine Learning in-the-Wild
Jun 27, 2024



Benchmarks that closely reflect downstream application scenarios are essential for the streamlined adoption of new research in tabular machine learning (ML). In this work, we examine existing tabular benchmarks and find two common characteristics of industry-grade tabular data that are underrepresented in the datasets available to the academic community. First, tabular data often changes over time in real-world deployment scenarios. This impacts model performance and requires time-based train and test splits for correct model evaluation. Yet, existing academic tabular datasets often lack timestamp metadata to enable such evaluation. Second, a considerable portion of datasets in production settings stem from extensive data acquisition and feature engineering pipelines. For each specific dataset, this can have a different impact on the absolute and relative number of predictive, uninformative, and correlated features, which in turn can affect model selection. To fill the aforementioned gaps in academic benchmarks, we introduce TabReD -- a collection of eight industry-grade tabular datasets covering a wide range of domains from finance to food delivery services. We assess a large number of tabular ML models in the feature-rich, temporally-evolving data setting facilitated by TabReD. We demonstrate that evaluation on time-based data splits leads to different methods ranking, compared to evaluation on random splits more common in academic benchmarks. Furthermore, on the TabReD datasets, MLP-like architectures and GBDT show the best results, while more sophisticated DL models are yet to prove their effectiveness.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023



Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).
Shifts 2.0: Extending The Dataset of Real Distributional Shifts
Jun 30, 2022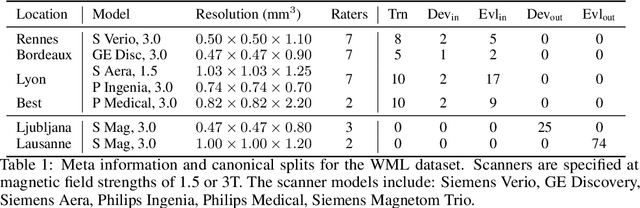
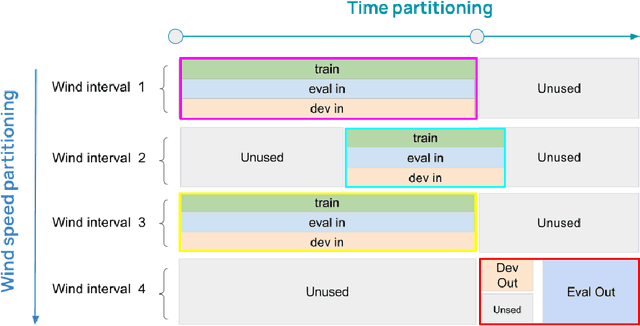
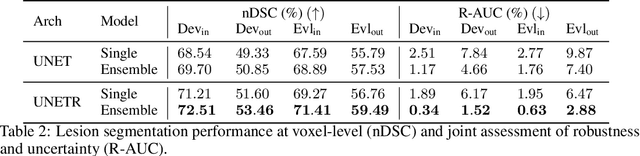
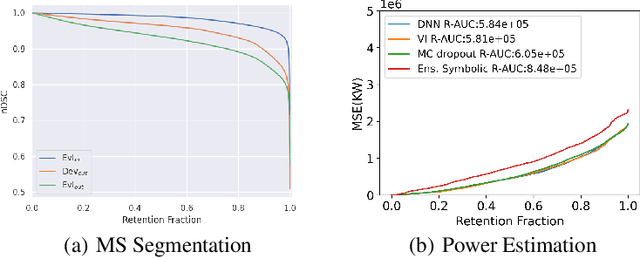
Distributional shift, or the mismatch between training and deployment data, is a significant obstacle to the usage of machine learning in high-stakes industrial applications, such as autonomous driving and medicine. This creates a need to be able to assess how robustly ML models generalize as well as the quality of their uncertainty estimates. Standard ML baseline datasets do not allow these properties to be assessed, as the training, validation and test data are often identically distributed. Recently, a range of dedicated benchmarks have appeared, featuring both distributionally matched and shifted data. Among these benchmarks, the Shifts dataset stands out in terms of the diversity of tasks as well as the data modalities it features. While most of the benchmarks are heavily dominated by 2D image classification tasks, Shifts contains tabular weather forecasting, machine translation, and vehicle motion prediction tasks. This enables the robustness properties of models to be assessed on a diverse set of industrial-scale tasks and either universal or directly applicable task-specific conclusions to be reached. In this paper, we extend the Shifts Dataset with two datasets sourced from industrial, high-risk applications of high societal importance. Specifically, we consider the tasks of segmentation of white matter Multiple Sclerosis lesions in 3D magnetic resonance brain images and the estimation of power consumption in marine cargo vessels. Both tasks feature ubiquitous distributional shifts and a strict safety requirement due to the high cost of errors. These new datasets will allow researchers to further explore robust generalization and uncertainty estimation in new situations. In this work, we provide a description of the dataset and baseline results for both tasks.