 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
Apr 30, 2021

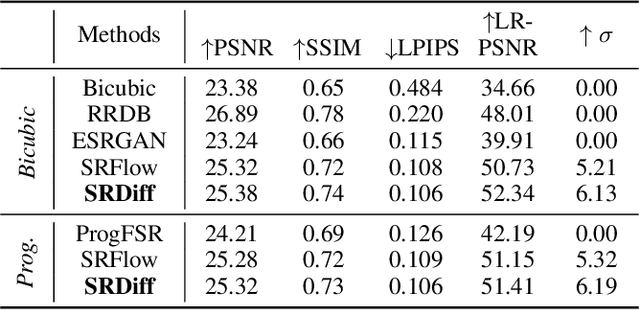
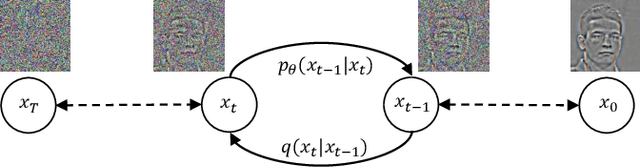
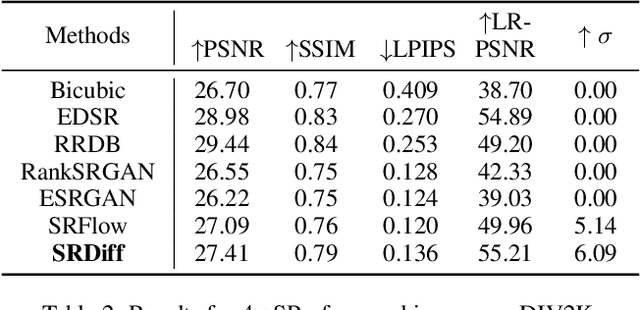
Single image super-resolution (SISR) aims to reconstruct high-resolution (HR) images from the given low-resolution (LR) ones, which is an ill-posed problem because one LR image corresponds to multiple HR images. Recently, learning-based SISR methods have greatly outperformed traditional ones, while suffering from over-smoothing, mode collapse or large model footprint issues for PSNR-oriented, GAN-driven and flow-based methods respectively. To solve these problems, we propose a novel single image super-resolution diffusion probabilistic model (SRDiff), which is the first diffusion-based model for SISR. SRDiff is optimized with a variant of the variational bound on the data likelihood and can provide diverse and realistic SR predictions by gradually transforming the Gaussian noise into a super-resolution (SR) image conditioned on an LR input through a Markov chain. In addition, we introduce residual prediction to the whole framework to speed up convergence. Our extensive experiments on facial and general benchmarks (CelebA and DIV2K datasets) show that 1) SRDiff can generate diverse SR results in rich details with state-of-the-art performance, given only one LR input; 2) SRDiff is easy to train with a small footprint; and 3) SRDiff can perform flexible image manipulation including latent space interpolation and content fusion.
Hierarchical Sampling based Particle Filter for Visual-inertial Gimbal in the Wild
Jun 22, 2022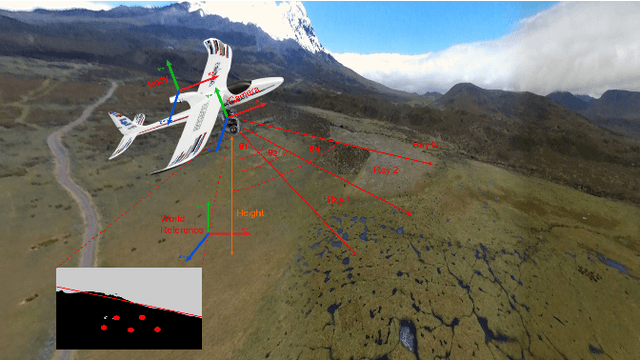
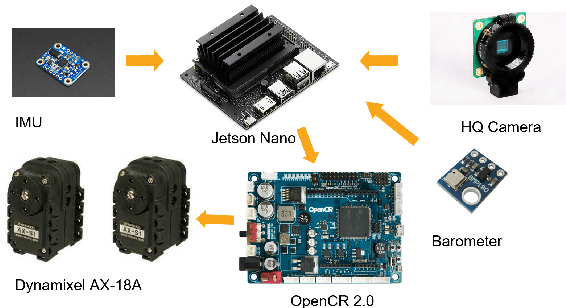
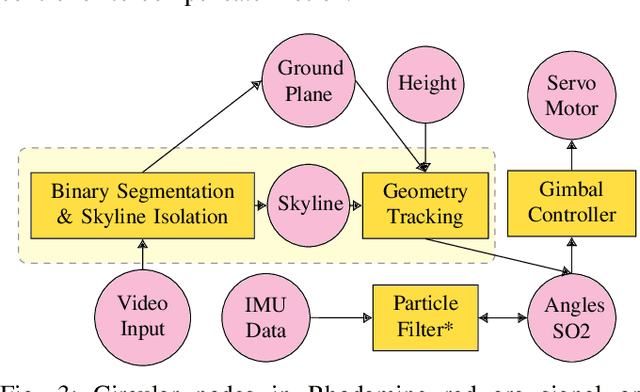

The gimbal platform has been widely used in photogrammetry and robot perceptual module to stabilize the camera pose, thereby improving the captured video quality. Usually a gimbal is mainly composed of sensors and actuator parts. The orientation measurements from sensor can be inputted directly to actuator to steer camera towards proper pose. But the off-the-shelf custom product is either quite expensive, or depending on highly precise IMU and Brushless DC motor with hall sensor to estimate angles, which is prone to suffer from accumulative drift over long-term operation. In this paper, a CV based new tracking and fusion algorithm dedicated for gimbal system on drones operating in nature is proposed, main contributions are listed as below: a) a light-weight Resnet -18 backbone based network model was trained from scratch, and deployed onto Jetson Nano platform to segment the image into binary parts (ground and sky). b) geometric primitives tracking of the skyline and ground plane in 3D as cues, along with orientation estimation from IMU can provide multiple guesses for orientation. c) spherical surface based adaptive particle sampling can fuse orientation from aforementioned sensor sources efficiently. The final prototyping algorithm is tested on the real-time embedded system, and with both simulation on ground and real functional tests in the air.
3D Face Parsing via Surface Parameterization and 2D Semantic Segmentation Network
Jun 18, 2022
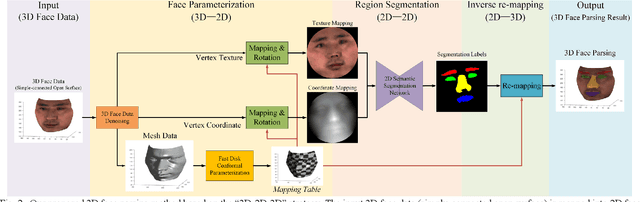
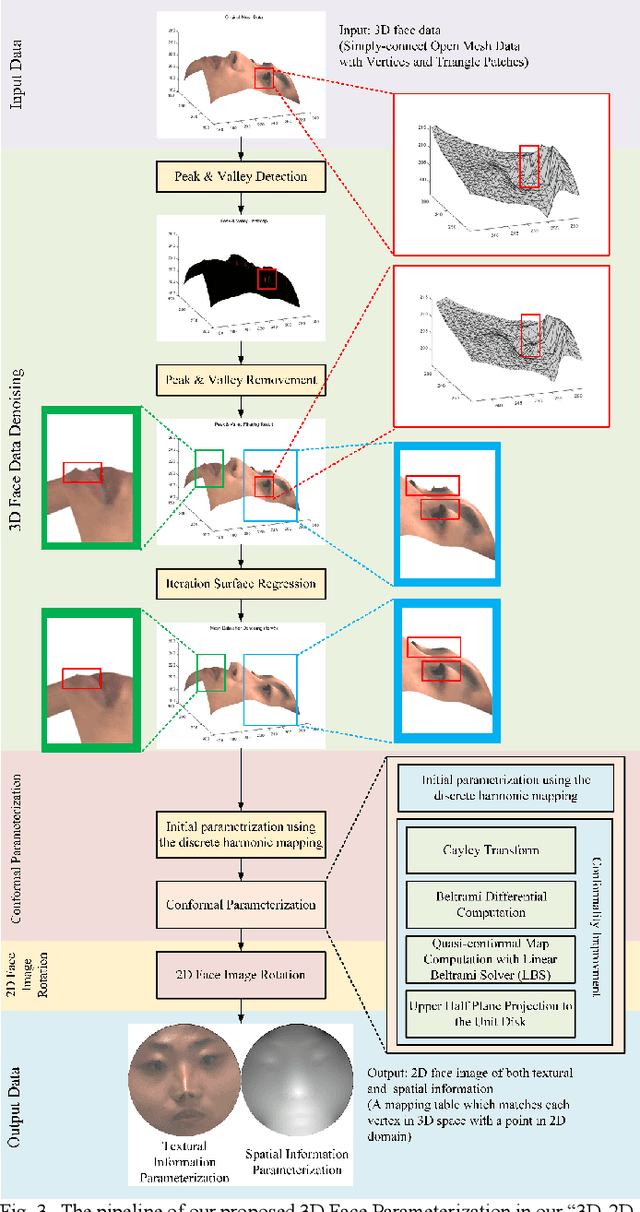
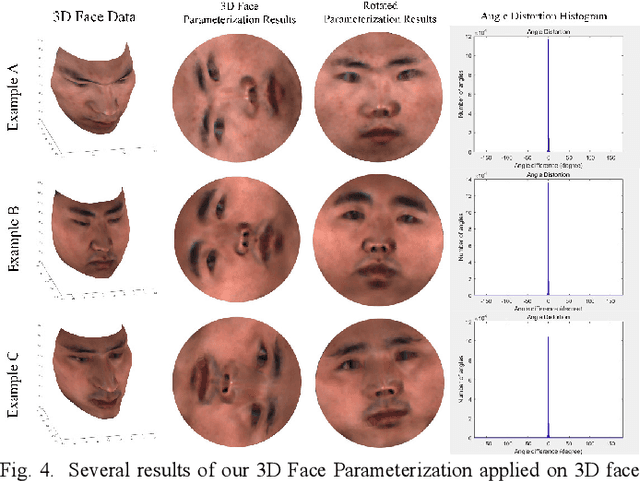
Face parsing assigns pixel-wise semantic labels as the face representation for computers, which is the fundamental part of many advanced face technologies. Compared with 2D face parsing, 3D face parsing shows more potential to achieve better performance and further application, but it is still challenging due to 3D mesh data computation. Recent works introduced different methods for 3D surface segmentation, while the performance is still limited. In this paper, we propose a method based on the "3D-2D-3D" strategy to accomplish 3D face parsing. The topological disk-like 2D face image containing spatial and textural information is transformed from the sampled 3D face data through the face parameterization algorithm, and a specific 2D network called CPFNet is proposed to achieve the semantic segmentation of the 2D parameterized face data with multi-scale technologies and feature aggregation. The 2D semantic result is then inversely re-mapped to 3D face data, which finally achieves the 3D face parsing. Experimental results show that both CPFNet and the "3D-2D-3D" strategy accomplish high-quality 3D face parsing and outperform state-of-the-art 2D networks as well as 3D methods in both qualitative and quantitative comparisons.
MCUa: Multi-level Context and Uncertainty aware Dynamic Deep Ensemble for Breast Cancer Histology Image Classification
Aug 24, 2021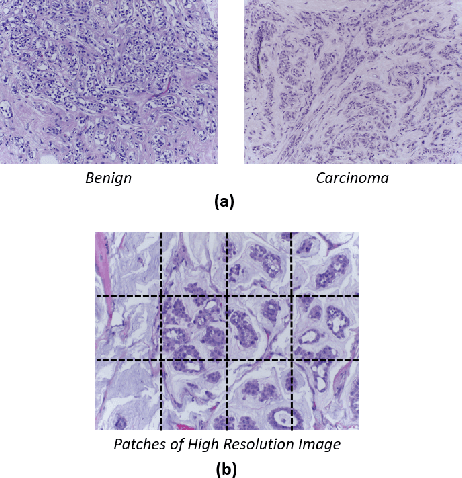
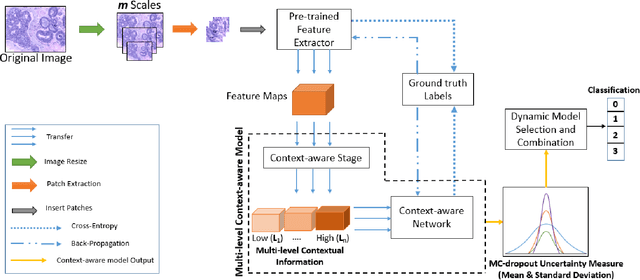

Breast histology image classification is a crucial step in the early diagnosis of breast cancer. In breast pathological diagnosis, Convolutional Neural Networks (CNNs) have demonstrated great success using digitized histology slides. However, tissue classification is still challenging due to the high visual variability of the large-sized digitized samples and the lack of contextual information. In this paper, we propose a novel CNN, called Multi-level Context and Uncertainty aware (MCUa) dynamic deep learning ensemble model.MCUamodel consists of several multi-level context-aware models to learn the spatial dependency between image patches in a layer-wise fashion. It exploits the high sensitivity to the multi-level contextual information using an uncertainty quantification component to accomplish a novel dynamic ensemble model.MCUamodelhas achieved a high accuracy of 98.11% on a breast cancer histology image dataset. Experimental results show the superior effectiveness of the proposed solution compared to the state-of-the-art histology classification models.
* accepted by IEEE Transactions on Biomedical Engineering
Transductive image segmentation: Self-training and effect of uncertainty estimation
Aug 02, 2021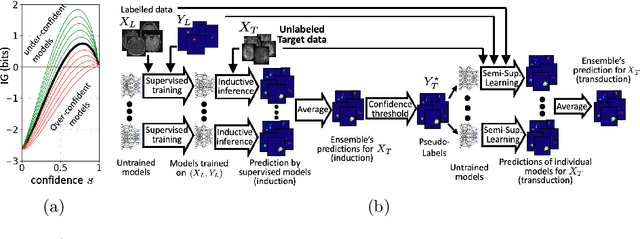

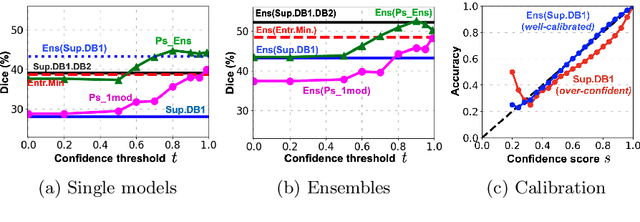
Semi-supervised learning (SSL) uses unlabeled data during training to learn better models. Previous studies on SSL for medical image segmentation focused mostly on improving model generalization to unseen data. In some applications, however, our primary interest is not generalization but to obtain optimal predictions on a specific unlabeled database that is fully available during model development. Examples include population studies for extracting imaging phenotypes. This work investigates an often overlooked aspect of SSL, transduction. It focuses on the quality of predictions made on the unlabeled data of interest when they are included for optimization during training, rather than improving generalization. We focus on the self-training framework and explore its potential for transduction. We analyze it through the lens of Information Gain and reveal that learning benefits from the use of calibrated or under-confident models. Our extensive experiments on a large MRI database for multi-class segmentation of traumatic brain lesions shows promising results when comparing transductive with inductive predictions. We believe this study will inspire further research on transductive learning, a well-suited paradigm for medical image analysis.
EMMT: A simultaneous eye-tracking, 4-electrode EEG and audio corpus for multi-modal reading and translation scenarios
Apr 06, 2022



We present the Eyetracked Multi-Modal Translation (EMMT) corpus, a dataset containing monocular eye movement recordings, audio and 4-electrode electroencephalogram (EEG) data of 43 participants. The objective was to collect cognitive signals as responses of participants engaged in a number of language intensive tasks involving different text-image stimuli settings when translating from English to Czech. Each participant was exposed to 32 text-image stimuli pairs and asked to (1) read the English sentence, (2) translate it into Czech, (3) consult the image, (4) translate again, either updating or repeating the previous translation. The text stimuli consisted of 200 unique sentences with 616 unique words coupled with 200 unique images as the visual stimuli. The recordings were collected over a two week period and all the participants included in the study were Czech natives with strong English skills. Due to the nature of the tasks involved in the study and the relatively large number of participants involved, the corpus is well suited for research in Translation Process Studies, Cognitive Sciences among other disciplines.
Utility of Equivariant Message Passing in Cortical Mesh Segmentation
Jun 07, 2022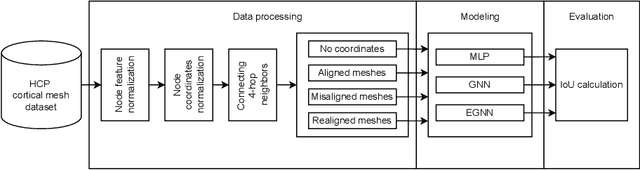
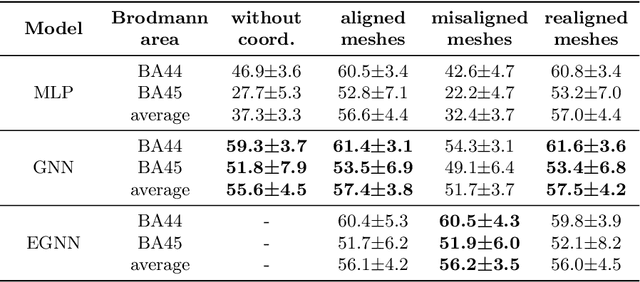
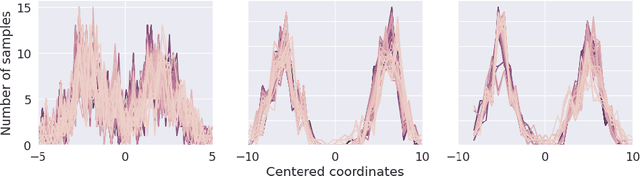
The automated segmentation of cortical areas has been a long-standing challenge in medical image analysis. The complex geometry of the cortex is commonly represented as a polygon mesh, whose segmentation can be addressed by graph-based learning methods. When cortical meshes are misaligned across subjects, current methods produce significantly worse segmentation results, limiting their ability to handle multi-domain data. In this paper, we investigate the utility of E(n)-equivariant graph neural networks (EGNNs), comparing their performance against plain graph neural networks (GNNs). Our evaluation shows that GNNs outperform EGNNs on aligned meshes, due to their ability to leverage the presence of a global coordinate system. On misaligned meshes, the performance of plain GNNs drop considerably, while E(n)-equivariant message passing maintains the same segmentation results. The best results can also be obtained by using plain GNNs on realigned data (co-registered meshes in a global coordinate system).
Image-based material analysis of ancient historical documents
Mar 02, 2022



Researchers continually perform corroborative tests to classify ancient historical documents based on the physical materials of their writing surfaces. However, these tests, often performed on-site, requires actual access to the manuscript objects. The procedures involve a considerable amount of time and cost, and can damage the manuscripts. Developing a technique to classify such documents using only digital images can be very useful and efficient. In order to tackle this problem, this study uses images of a famous historical collection, the Dead Sea Scrolls, to propose a novel method to classify the materials of the manuscripts. The proposed classifier uses the two-dimensional Fourier Transform to identify patterns within the manuscript surfaces. Combining a binary classification system employing the transform with a majority voting process is shown to be effective for this classification task. This pilot study shows a successful classification percentage of up to 97% for a confined amount of manuscripts produced from either parchment or papyrus material. Feature vectors based on Fourier-space grid representation outperformed a concentric Fourier-space format.
Smart Scribbles for Image Mating
Mar 31, 2021
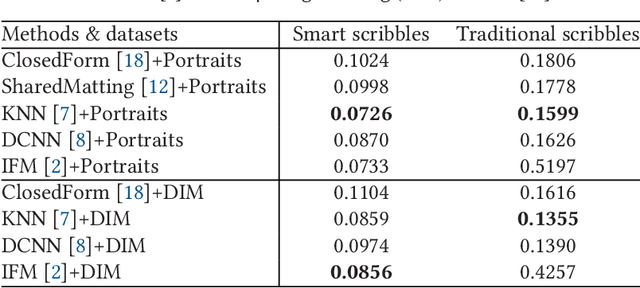
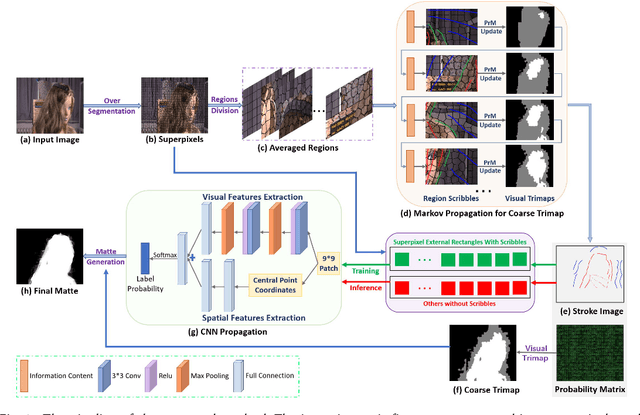
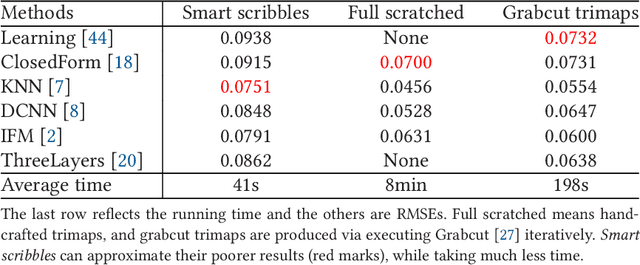
Image matting is an ill-posed problem that usually requires additional user input, such as trimaps or scribbles. Drawing a fne trimap requires a large amount of user effort, while using scribbles can hardly obtain satisfactory alpha mattes for non-professional users. Some recent deep learning-based matting networks rely on large-scale composite datasets for training to improve performance, resulting in the occasional appearance of obvious artifacts when processing natural images. In this article, we explore the intrinsic relationship between user input and alpha mattes and strike a balance between user effort and the quality of alpha mattes. In particular, we propose an interactive framework, referred to as smart scribbles, to guide users to draw few scribbles on the input images to produce high-quality alpha mattes. It frst infers the most informative regions of an image for drawing scribbles to indicate different categories (foreground, background, or unknown) and then spreads these scribbles (i.e., the category labels) to the rest of the image via our well-designed two-phase propagation. Both neighboring low-level afnities and high-level semantic features are considered during the propagation process. Our method can be optimized without large-scale matting datasets and exhibits more universality in real situations. Extensive experiments demonstrate that smart scribbles can produce more accurate alpha mattes with reduced additional input, compared to the state-of-the-art matting methods.
Practical Blind Denoising via Swin-Conv-UNet and Data Synthesis
Mar 28, 2022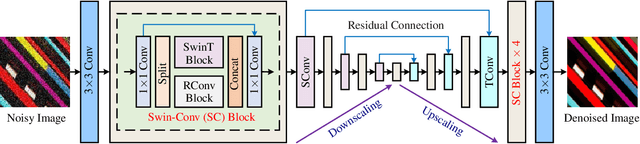
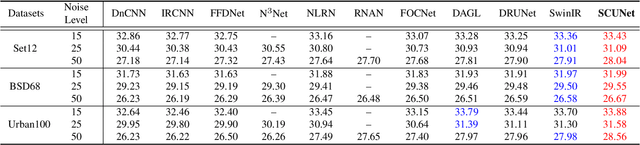
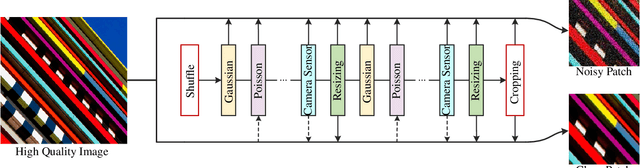

While recent years have witnessed a dramatic upsurge of exploiting deep neural networks toward solving image denoising, existing methods mostly rely on simple noise assumptions, such as additive white Gaussian noise (AWGN), JPEG compression noise and camera sensor noise, and a general-purpose blind denoising method for real images remains unsolved. In this paper, we attempt to solve this problem from the perspective of network architecture design and training data synthesis. Specifically, for the network architecture design, we propose a swin-conv block to incorporate the local modeling ability of residual convolutional layer and non-local modeling ability of swin transformer block, and then plug it as the main building block into the widely-used image-to-image translation UNet architecture. For the training data synthesis, we design a practical noise degradation model which takes into consideration different kinds of noise (including Gaussian, Poisson, speckle, JPEG compression, and processed camera sensor noises) and resizing, and also involves a random shuffle strategy and a double degradation strategy. Extensive experiments on AGWN removal and real image denoising demonstrate that the new network architecture design achieves state-of-the-art performance and the new degradation model can help to significantly improve the practicability. We believe our work can provide useful insights into current denoising research.