 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA High-accuracy Event-based Underwater SLAM System
Jun 18, 2026While event cameras offer immense potential for underwater SLAM, existing Time Surface (TS)-based methods prove highly unreliable when deployed underwater. Fluctuating camera velocities severely degrade TS imaging quality, while wide stereo baselines and repetitive underwater textures induce critical matching failures, frequently triggering system failure. To overcome these challenges, we develop the first high-accuracy event-based underwater stereo SLAM system. A structure-aware metric for TS is designed based on structure tensor coherence and gradients to quantitatively evaluate TS structural information density. By decoupling the optimal TS generation into two distinct stages based on system initialization, Bayesian Optimization(BO) first predicts an optimal prior TS sequentially before initialization while we set an asynchronous online local searching method periodically to obtain appropriate TS in real-time during the tracking stage. We use the prior disparity to guarantee precise data association and "latest-observation-first'' triangulation mechanism to realize stable triangulation. As a benchmark for these solutions and a resource for the community, we also contribute UWE, the first high-quality real-world underwater event dataset containing variable camera motions, complex textures and different trajectory features. Extensive evaluations on public datasets and UWE show the competitive accuracy performance of the proposed SLAM system compared to the state-of-the-art event-based method. The code and data will be open-sourced.
MLT-Dedup: Efficient Large-Scale Online Video Deduplication via Multi-Level Representations and Spatial-Temporal Matching
Jun 10, 2026The explosive growth of user-generated video content on online platforms is accompanied by the emergence of numerous near-duplicate videos--videos that are identical or highly similar but differ by partial edits. These duplicates degrade user experience and increase storage and bandwidth costs, making large-scale video deduplication a critical task. Existing video deduplication frameworks face a fundamental challenge in retrieving sufficient high-quality candidates under a limited index budget, as well as trade-offs between efficiency and precision. To address these issues, we propose MLT-Dedup, an efficient large-scale online video deduplication framework with Multi-Level representations and spatial-Temporal matching. Our approach employs a Multi-Level Video Encoder (ML-VE) to extract both fine-grained frame-level and sparse clip-level embeddings: sparse embeddings support efficient candidate retrieval, while fine-grained embeddings are loaded for precise pairwise matching. During matching, we introduce DiF-SiM, a Differential Feature-enhanced Similarity Module capable of locating duplicated temporal segments and providing reliable similarity evidence to support policy-driven deduplication decisions. Extensive experiments on a real-world large-scale platform demonstrate that MLT-Dedup reduces online repetition rates by 91% at 90% precision. Furthermore, our sparse retrieval design achieves a 5x increase in indexing capacity, enabling broader candidate coverage in real-world deployment.
Provably Guaranteed Polytopic Uncertainty Quantification for SLAM
May 27, 2026In safety-critical robotics applications, guaranteed and practical uncertainty quantification (UQ) in perception is vital. Many existing works either offer no formal containment guarantee, rely on restrictive modeling assumptions, or focus only on pose estimation rather than a complete SLAM pipeline. This paper presents provably guaranteed UQ algorithms for 3D-3D landmark-based SLAM. The algorithms consist of three basic UQ modules: forward UQ for mapping, backward UQ for pose tracking, and pose compound. Each module produces a certified uncertainty set; when the input uncertainty bounds are deterministic, the output sets inherit deterministic guarantees, i.e., they provably contain the true poses and landmarks. Specifically, we use polytopes to represent uncertainty sets, enabling tractable computations and a unified treatment of pose uncertainty. To enhance algorithms' practical usability, we incorporate conformal prediction to calibrate measurement uncertainty from data with prescribed probability. Simulations and experiments demonstrate that the proposed algorithms provide both strong theoretical guarantees and practical usability. The code is open-sourced at https://github.com/LIAS-CUHKSZ/Polytopic-SLAM-Uncertainty-Quantification.
Efficient Invariant Kalman Filter for Inertial-based Odometry with Large-sample Environmental Measurements
Feb 07, 2024



A filter for inertial-based odometry is a recursive method used to estimate the pose from measurements of ego-motion and relative pose. Currently, there is no known filter that guarantees the computation of a globally optimal solution for the non-linear measurement model. In this paper, we demonstrate that an innovative filter, with the state being $SE_2(3)$ and the $\sqrt{n}$-\textit{consistent} pose as the initialization, efficiently achieves \textit{asymptotic optimality} in terms of minimum mean square error. This approach is tailored for real-time SLAM and inertial-based odometry applications. Our first contribution is that we propose an iterative filtering method based on the Gauss-Newton method on Lie groups which is numerically to solve the estimation of states from a priori and non-linear measurements. The filtering stands out due to its iterative mechanism and adaptive initialization. Second, when dealing with environmental measurements of the surroundings, we utilize a $\sqrt{n}$-consistent pose as the initial value for the update step in a single iteration. The solution is closed in form and has computational complexity $O(n)$. Third, we theoretically show that the approach can achieve asymptotic optimality in the sense of minimum mean square error from the a priori and virtual relative pose measurements (see Problem~\ref{prob:new update problem}). Finally, to validate our method, we carry out extensive numerical and experimental evaluations. Our results consistently demonstrate that our approach outperforms other state-of-the-art filter-based methods, including the iterated extended Kalman filter and the invariant extended Kalman filter, in terms of accuracy and running time.
Deep Linear Array Pushbroom Image Restoration: A Degradation Pipeline and Jitter-Aware Restoration Network
Jan 16, 2024



Linear Array Pushbroom (LAP) imaging technology is widely used in the realm of remote sensing. However, images acquired through LAP always suffer from distortion and blur because of camera jitter. Traditional methods for restoring LAP images, such as algorithms estimating the point spread function (PSF), exhibit limited performance. To tackle this issue, we propose a Jitter-Aware Restoration Network (JARNet), to remove the distortion and blur in two stages. In the first stage, we formulate an Optical Flow Correction (OFC) block to refine the optical flow of the degraded LAP images, resulting in pre-corrected images where most of the distortions are alleviated. In the second stage, for further enhancement of the pre-corrected images, we integrate two jitter-aware techniques within the Spatial and Frequency Residual (SFRes) block: 1) introducing Coordinate Attention (CoA) to the SFRes block in order to capture the jitter state in orthogonal direction; 2) manipulating image features in both spatial and frequency domains to leverage local and global priors. Additionally, we develop a data synthesis pipeline, which applies Continue Dynamic Shooting Model (CDSM) to simulate realistic degradation in LAP images. Both the proposed JARNet and LAP image synthesis pipeline establish a foundation for addressing this intricate challenge. Extensive experiments demonstrate that the proposed two-stage method outperforms state-of-the-art image restoration models. Code is available at https://github.com/JHW2000/JARNet.
Adaptive Window Pruning for Efficient Local Motion Deblurring
Jun 25, 2023



Local motion blur commonly occurs in real-world photography due to the mixing between moving objects and stationary backgrounds during exposure. Existing image deblurring methods predominantly focus on global deblurring, inadvertently affecting the sharpness of backgrounds in locally blurred images and wasting unnecessary computation on sharp pixels, especially for high-resolution images. This paper aims to adaptively and efficiently restore high-resolution locally blurred images. We propose a local motion deblurring vision Transformer (LMD-ViT) built on adaptive window pruning Transformer blocks (AdaWPT). To focus deblurring on local regions and reduce computation, AdaWPT prunes unnecessary windows, only allowing the active windows to be involved in the deblurring processes. The pruning operation relies on the blurriness confidence predicted by a confidence predictor that is trained end-to-end using a reconstruction loss with Gumbel-Softmax re-parameterization and a pruning loss guided by annotated blur masks. Our method removes local motion blur effectively without distorting sharp regions, demonstrated by its exceptional perceptual and quantitative improvements (+0.24dB) compared to state-of-the-art methods. In addition, our approach substantially reduces FLOPs by 66% and achieves more than a twofold increase in inference speed compared to Transformer-based deblurring methods. We will make our code and annotated blur masks publicly available.
Real-world Deep Local Motion Deblurring
Apr 18, 2022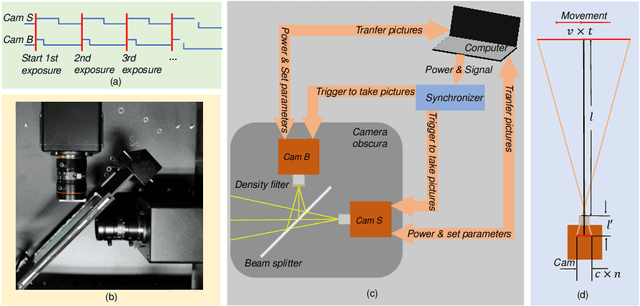



Most existing deblurring methods focus on removing global blur caused by camera shake, while they cannot well handle local blur caused by object movements. To fill the vacancy of local deblurring in real scenes, we establish the first real local motion blur dataset (ReLoBlur), which is captured by a synchronized beam-splitting photographing system and corrected by a post-progressing pipeline. Based on ReLoBlur, we propose a Local Blur-Aware Gated network (LBAG) and several local blur-aware techniques to bridge the gap between global and local deblurring: 1) a blur detection approach based on background subtraction to localize blurred regions; 2) a gate mechanism to guide our network to focus on blurred regions; and 3) a blur-aware patch cropping strategy to address data imbalance problem. Extensive experiments prove the reliability of ReLoBlur dataset, and demonstrate that LBAG achieves better performance than state-of-the-art global deblurring methods without our proposed local blur-aware techniques.
SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
May 18, 2021
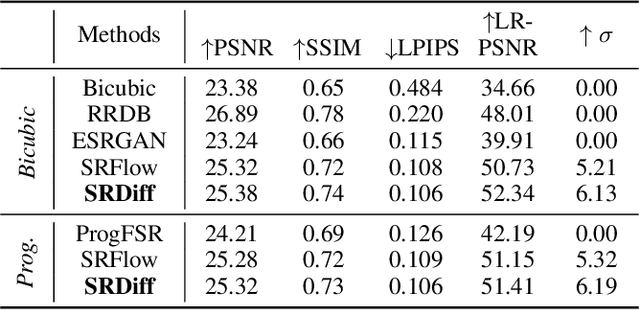
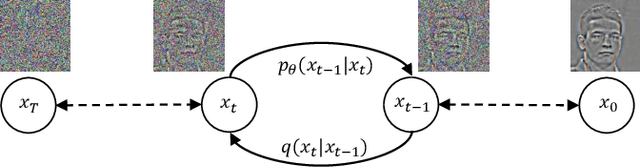
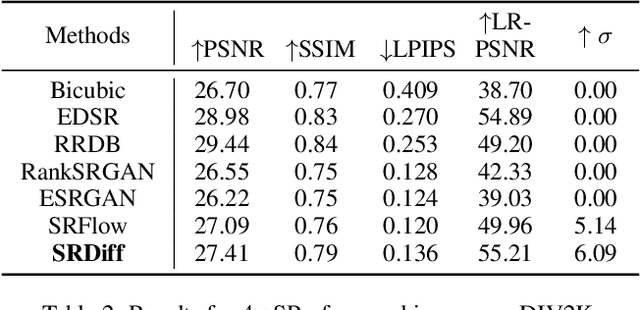
Single image super-resolution (SISR) aims to reconstruct high-resolution (HR) images from the given low-resolution (LR) ones, which is an ill-posed problem because one LR image corresponds to multiple HR images. Recently, learning-based SISR methods have greatly outperformed traditional ones, while suffering from over-smoothing, mode collapse or large model footprint issues for PSNR-oriented, GAN-driven and flow-based methods respectively. To solve these problems, we propose a novel single image super-resolution diffusion probabilistic model (SRDiff), which is the first diffusion-based model for SISR. SRDiff is optimized with a variant of the variational bound on the data likelihood and can provide diverse and realistic SR predictions by gradually transforming the Gaussian noise into a super-resolution (SR) image conditioned on an LR input through a Markov chain. In addition, we introduce residual prediction to the whole framework to speed up convergence. Our extensive experiments on facial and general benchmarks (CelebA and DIV2K datasets) show that 1) SRDiff can generate diverse SR results in rich details with state-of-the-art performance, given only one LR input; 2) SRDiff is easy to train with a small footprint; and 3) SRDiff can perform flexible image manipulation including latent space interpolation and content fusion.