 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Substitutional Neural Image Compression
May 16, 2021

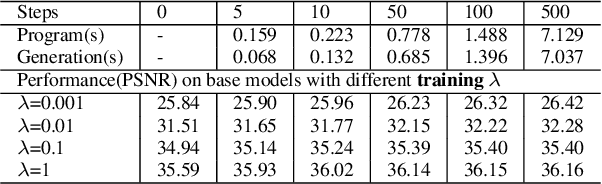
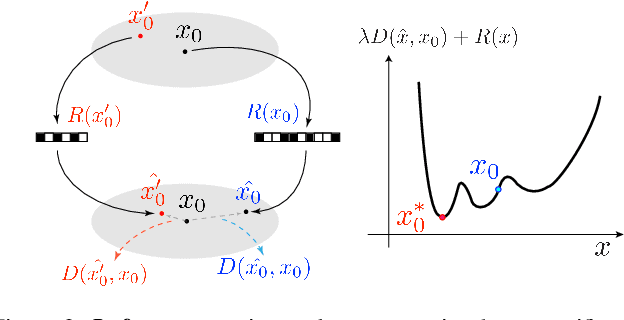
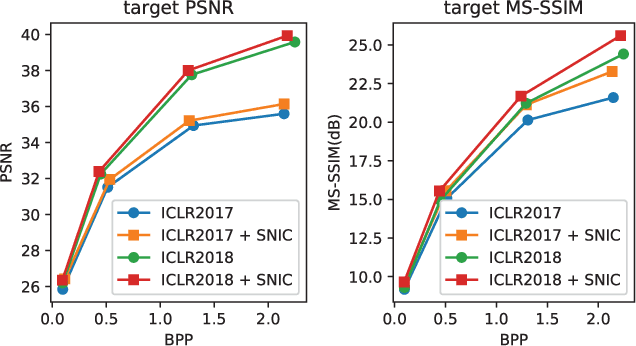
We describe Substitutional Neural Image Compression (SNIC), a general approach for enhancing any neural image compression model, that requires no data or additional tuning of the trained model. It boosts compression performance toward a flexible distortion metric and enables bit-rate control using a single model instance. The key idea is to replace the image to be compressed with a substitutional one that outperforms the original one in a desired way. Finding such a substitute is inherently difficult for conventional codecs, yet surprisingly favorable for neural compression models thanks to their fully differentiable structures. With gradients of a particular loss backpropogated to the input, a desired substitute can be efficiently crafted iteratively. We demonstrate the effectiveness of SNIC, when combined with various neural compression models and target metrics, in improving compression quality and performing bit-rate control measured by rate-distortion curves. Empirical results of control precision and generation speed are also discussed.
Solving Image PDEs with a Shallow Network
Oct 15, 2021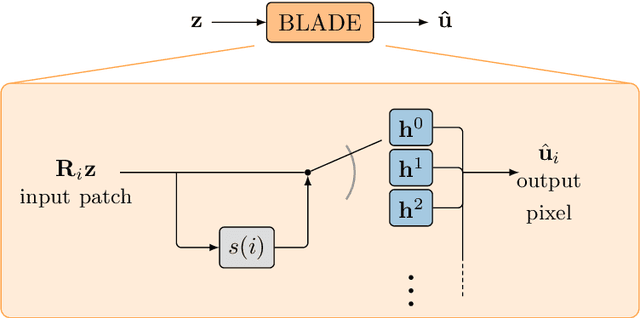
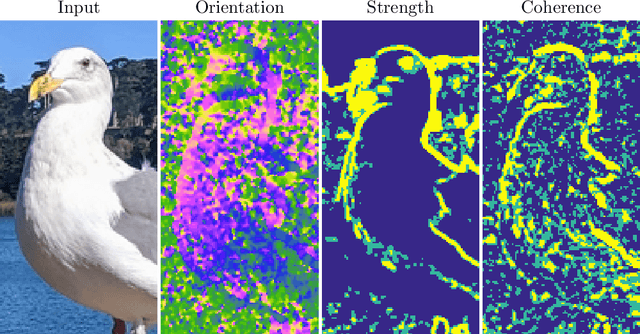
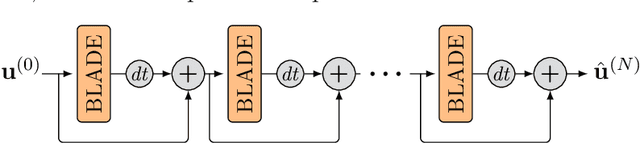
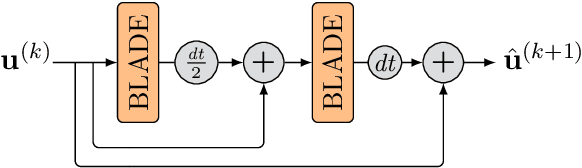
Partial differential equations (PDEs) are typically used as models of physical processes but are also of great interest in PDE-based image processing. However, when it comes to their use in imaging, conventional numerical methods for solving PDEs tend to require very fine grid resolution for stability, and as a result have impractically high computational cost. This work applies BLADE (Best Linear Adaptive Enhancement), a shallow learnable filtering framework, to PDE solving, and shows that the resulting approach is efficient and accurate, operating more reliably at coarse grid resolutions than classical methods. As such, the model can be flexibly used for a wide variety of problems in imaging.
HyperSegNAS: Bridging One-Shot Neural Architecture Search with 3D Medical Image Segmentation using HyperNet
Dec 20, 2021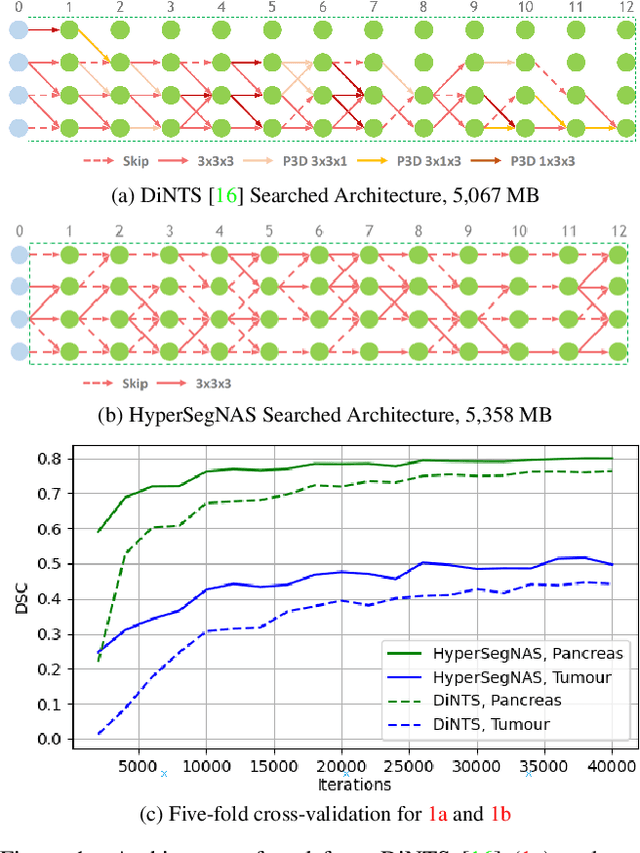
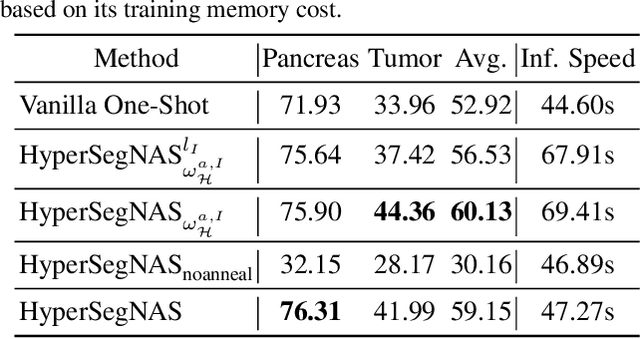
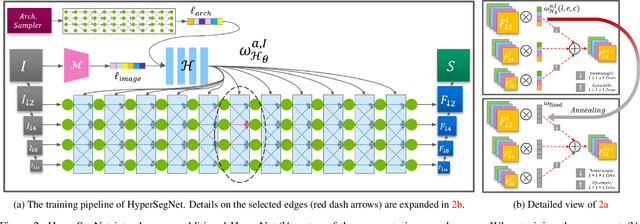
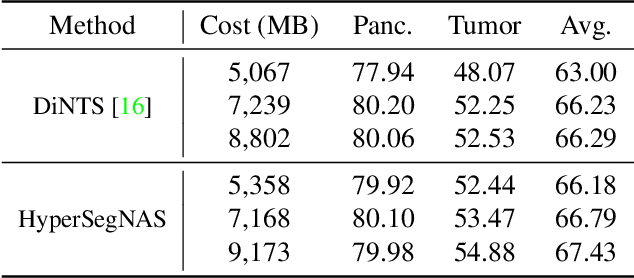
Semantic segmentation of 3D medical images is a challenging task due to the high variability of the shape and pattern of objects (such as organs or tumors). Given the recent success of deep learning in medical image segmentation, Neural Architecture Search (NAS) has been introduced to find high-performance 3D segmentation network architectures. However, because of the massive computational requirements of 3D data and the discrete optimization nature of architecture search, previous NAS methods require a long search time or necessary continuous relaxation, and commonly lead to sub-optimal network architectures. While one-shot NAS can potentially address these disadvantages, its application in the segmentation domain has not been well studied in the expansive multi-scale multi-path search space. To enable one-shot NAS for medical image segmentation, our method, named HyperSegNAS, introduces a HyperNet to assist super-net training by incorporating architecture topology information. Such a HyperNet can be removed once the super-net is trained and introduces no overhead during architecture search. We show that HyperSegNAS yields better performing and more intuitive architectures compared to the previous state-of-the-art (SOTA) segmentation networks; furthermore, it can quickly and accurately find good architecture candidates under different computing constraints. Our method is evaluated on public datasets from the Medical Segmentation Decathlon (MSD) challenge, and achieves SOTA performances.
Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 08, 2022
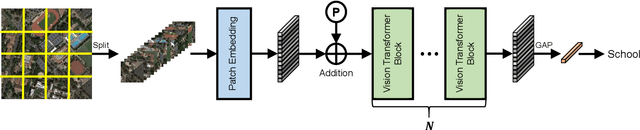
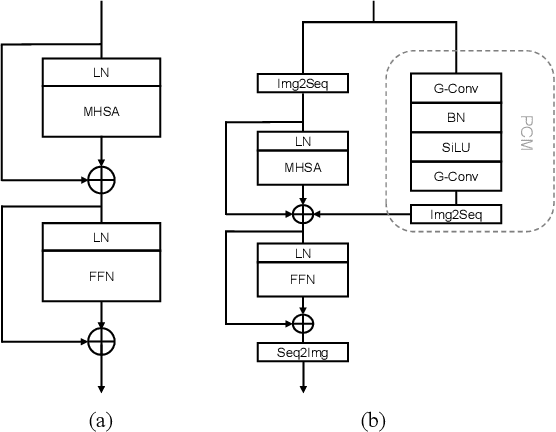
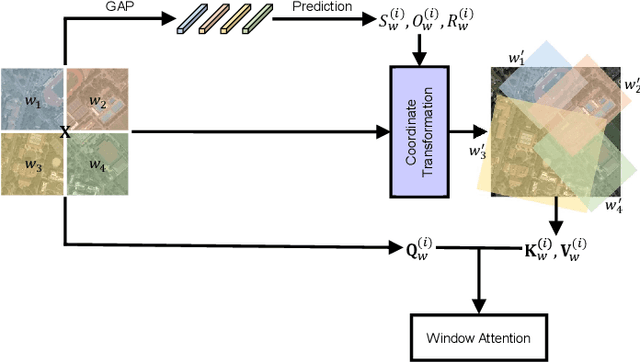
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16\% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning. The code and models will be released at https://github.com/ViTAE-Transformer/Remote-Sensing-RVSA
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
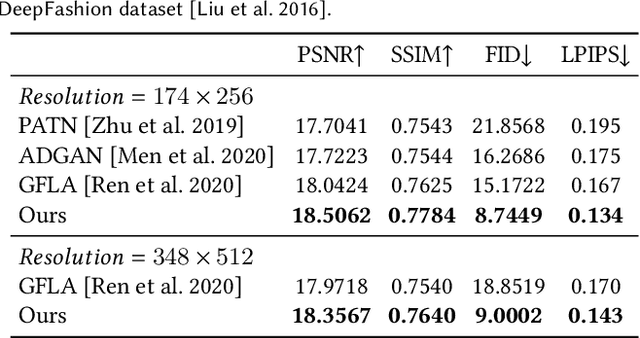


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Augment to Detect Anomalies with Continuous Labelling
Jul 03, 2022
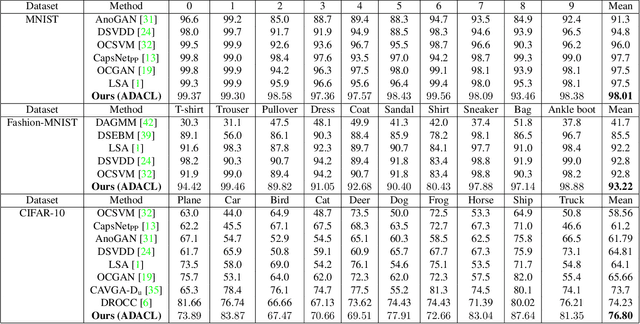
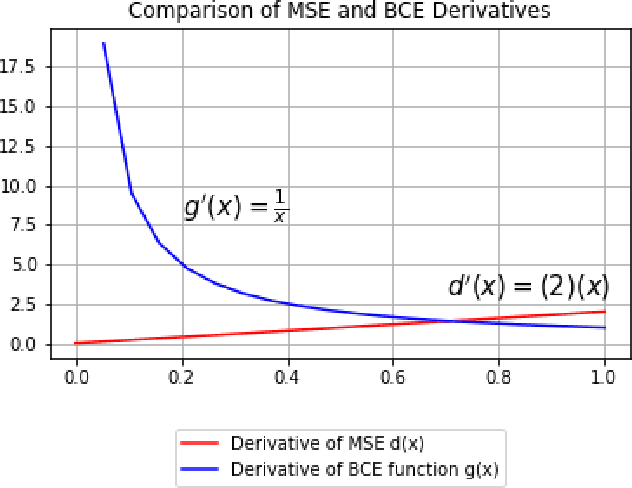

Anomaly detection is to recognize samples that differ in some respect from the training observations. These samples which do not conform to the distribution of normal data are called outliers or anomalies. In real-world anomaly detection problems, the outliers are absent, not well defined, or have a very limited number of instances. Recent state-of-the-art deep learning-based anomaly detection methods suffer from high computational cost, complexity, unstable training procedures, and non-trivial implementation, making them difficult to deploy in real-world applications. To combat this problem, we leverage a simple learning procedure that trains a lightweight convolutional neural network, reaching state-of-the-art performance in anomaly detection. In this paper, we propose to solve anomaly detection as a supervised regression problem. We label normal and anomalous data using two separable distributions of continuous values. To compensate for the unavailability of anomalous samples during training time, we utilize straightforward image augmentation techniques to create a distinct set of samples as anomalies. The distribution of the augmented set is similar but slightly deviated from the normal data, whereas real anomalies are expected to have an even further distribution. Therefore, training a regressor on these augmented samples will result in more separable distributions of labels for normal and real anomalous data points. Anomaly detection experiments on image and video datasets show the superiority of the proposed method over the state-of-the-art approaches.
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
May 24, 2022
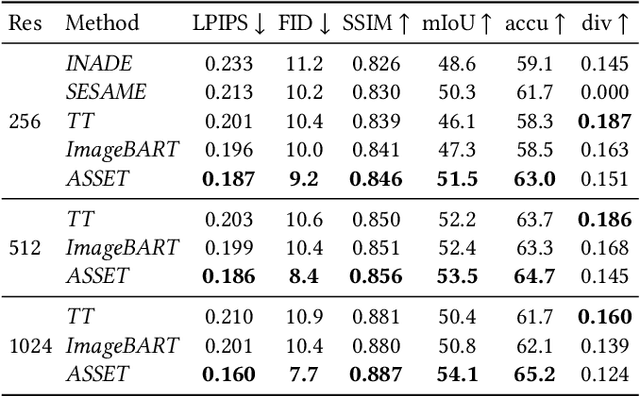
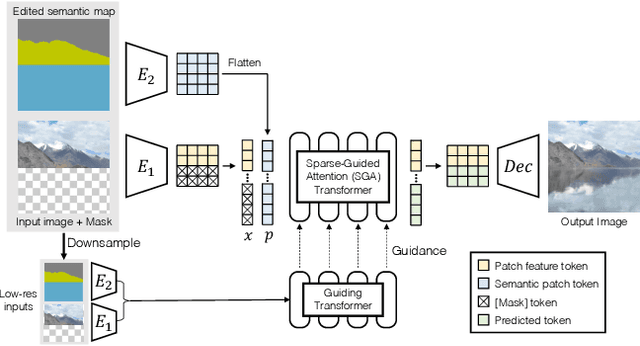
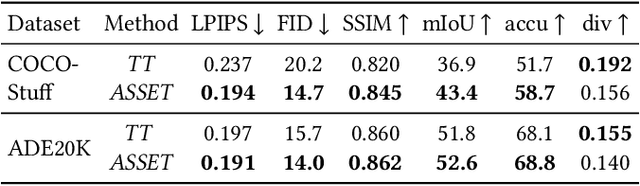
We present ASSET, a neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map. Our architecture is based on a transformer with a novel attention mechanism. Our key idea is to sparsify the transformer's attention matrix at high resolutions, guided by dense attention extracted at lower image resolutions. While previous attention mechanisms are computationally too expensive for handling high-resolution images or are overly constrained within specific image regions hampering long-range interactions, our novel attention mechanism is both computationally efficient and effective. Our sparsified attention mechanism is able to capture long-range interactions and context, leading to synthesizing interesting phenomena in scenes, such as reflections of landscapes onto water or flora consistent with the rest of the landscape, that were not possible to generate reliably with previous convnets and transformer approaches. We present qualitative and quantitative results, along with user studies, demonstrating the effectiveness of our method.
On the Out-of-distribution Generalization of Probabilistic Image Modelling
Sep 04, 2021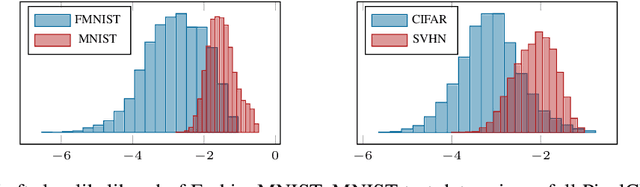


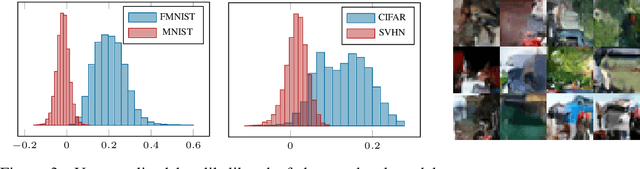
Out-of-distribution (OOD) detection and lossless compression constitute two problems that can be solved by the training of probabilistic models on a first dataset with subsequent likelihood evaluation on a second dataset, where data distributions differ. By defining the generalization of probabilistic models in terms of likelihood we show that, in the case of image models, the OOD generalization ability is dominated by local features. This motivates our proposal of a Local Autoregressive model that exclusively models local image features towards improving OOD performance. We apply the proposed model to OOD detection tasks and achieve state-of-the-art unsupervised OOD detection performance without the introduction of additional data. Additionally, we employ our model to build a new lossless image compressor: NeLLoC (Neural Local Lossless Compressor) and report state-of-the-art compression rates and model size.
AWEncoder: Adversarial Watermarking Pre-trained Encoders in Contrastive Learning
Aug 08, 2022

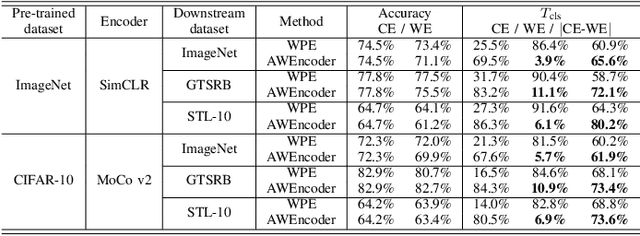
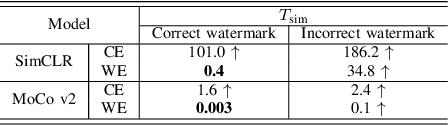
As a self-supervised learning paradigm, contrastive learning has been widely used to pre-train a powerful encoder as an effective feature extractor for various downstream tasks. This process requires numerous unlabeled training data and computational resources, which makes the pre-trained encoder become valuable intellectual property of the owner. However, the lack of a priori knowledge of downstream tasks makes it non-trivial to protect the intellectual property of the pre-trained encoder by applying conventional watermarking methods. To deal with this problem, in this paper, we introduce AWEncoder, an adversarial method for watermarking the pre-trained encoder in contrastive learning. First, as an adversarial perturbation, the watermark is generated by enforcing the training samples to be marked to deviate respective location and surround a randomly selected key image in the embedding space. Then, the watermark is embedded into the pre-trained encoder by further optimizing a joint loss function. As a result, the watermarked encoder not only performs very well for downstream tasks, but also enables us to verify its ownership by analyzing the discrepancy of output provided using the encoder as the backbone under both white-box and black-box conditions. Extensive experiments demonstrate that the proposed work enjoys pretty good effectiveness and robustness on different contrastive learning algorithms and downstream tasks, which has verified the superiority and applicability of the proposed work.
PPMN: Pixel-Phrase Matching Network for One-Stage Panoptic Narrative Grounding
Aug 11, 2022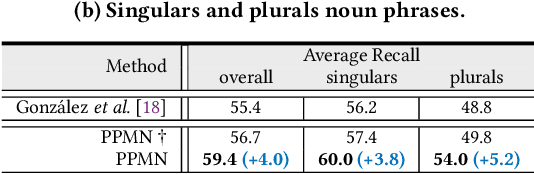
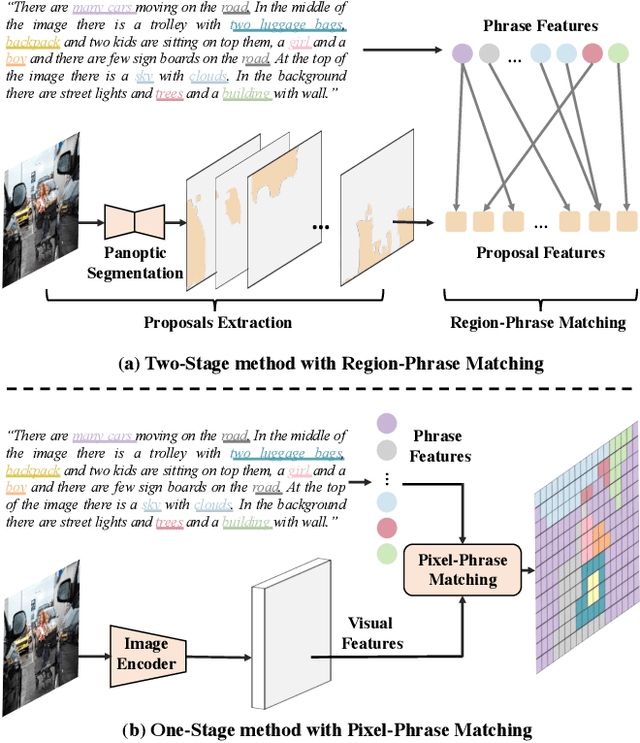
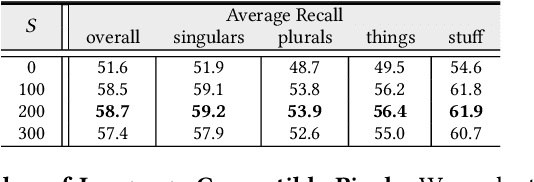
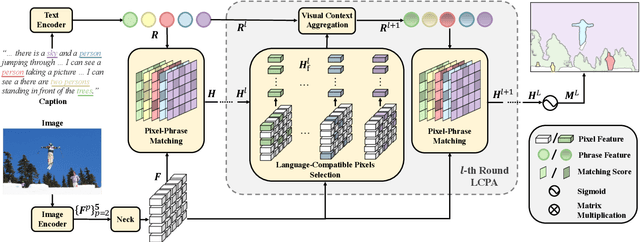
Panoptic Narrative Grounding (PNG) is an emerging task whose goal is to segment visual objects of things and stuff categories described by dense narrative captions of a still image. The previous two-stage approach first extracts segmentation region proposals by an off-the-shelf panoptic segmentation model, then conducts coarse region-phrase matching to ground the candidate regions for each noun phrase. However, the two-stage pipeline usually suffers from the performance limitation of low-quality proposals in the first stage and the loss of spatial details caused by region feature pooling, as well as complicated strategies designed for things and stuff categories separately. To alleviate these drawbacks, we propose a one-stage end-to-end Pixel-Phrase Matching Network (PPMN), which directly matches each phrase to its corresponding pixels instead of region proposals and outputs panoptic segmentation by simple combination. Thus, our model can exploit sufficient and finer cross-modal semantic correspondence from the supervision of densely annotated pixel-phrase pairs rather than sparse region-phrase pairs. In addition, we also propose a Language-Compatible Pixel Aggregation (LCPA) module to further enhance the discriminative ability of phrase features through multi-round refinement, which selects the most compatible pixels for each phrase to adaptively aggregate the corresponding visual context. Extensive experiments show that our method achieves new state-of-the-art performance on the PNG benchmark with 4.0 absolute Average Recall gains.