 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Voxel-based 3D Detection and Reconstruction of Multiple Objects from a Single Image
Nov 04, 2021

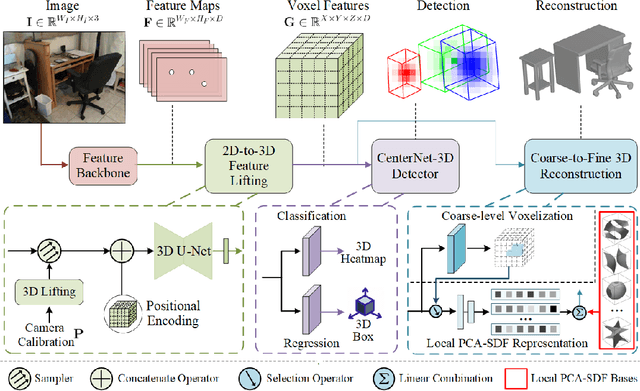
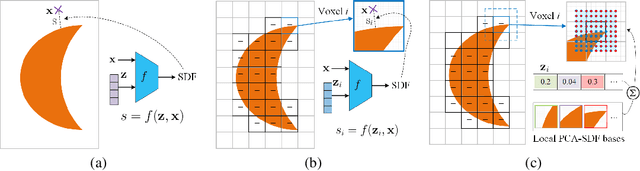
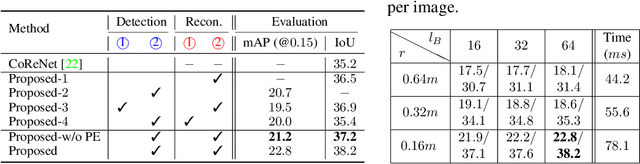
Inferring 3D locations and shapes of multiple objects from a single 2D image is a long-standing objective of computer vision. Most of the existing works either predict one of these 3D properties or focus on solving both for a single object. One fundamental challenge lies in how to learn an effective representation of the image that is well-suited for 3D detection and reconstruction. In this work, we propose to learn a regular grid of 3D voxel features from the input image which is aligned with 3D scene space via a 3D feature lifting operator. Based on the 3D voxel features, our novel CenterNet-3D detection head formulates the 3D detection as keypoint detection in the 3D space. Moreover, we devise an efficient coarse-to-fine reconstruction module, including coarse-level voxelization and a novel local PCA-SDF shape representation, which enables fine detail reconstruction and one order of magnitude faster inference than prior methods. With complementary supervision from both 3D detection and reconstruction, one enables the 3D voxel features to be geometry and context preserving, benefiting both tasks.The effectiveness of our approach is demonstrated through 3D detection and reconstruction in single object and multiple object scenarios.
EffCNet: An Efficient CondenseNet for Image Classification on NXP BlueBox
Nov 28, 2021

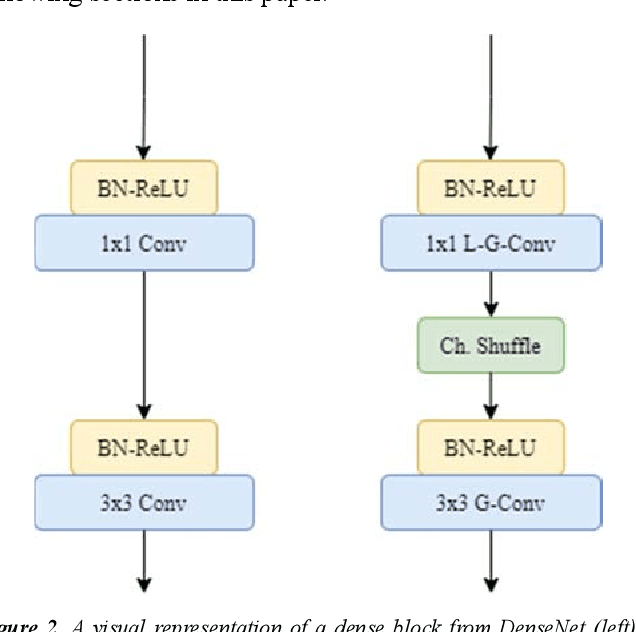
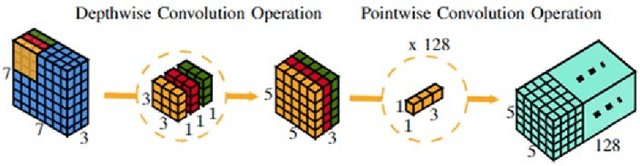
Intelligent edge devices with built-in processors vary widely in terms of capability and physical form to perform advanced Computer Vision (CV) tasks such as image classification and object detection, for example. With constant advances in the field of autonomous cars and UAVs, embedded systems and mobile devices, there has been an ever-growing demand for extremely efficient Artificial Neural Networks (ANN) for real-time inference on these smart edge devices with constrained computational resources. With unreliable network connections in remote regions and an added complexity of data transmission, it is of an utmost importance to capture and process data locally instead of sending the data to cloud servers for remote processing. Edge devices on the other hand, offer limited processing power due to their inexpensive hardware, and limited cooling and computational resources. In this paper, we propose a novel deep convolutional neural network architecture called EffCNet which is an improved and an efficient version of CondenseNet Convolutional Neural Network (CNN) for edge devices utilizing self-querying data augmentation and depthwise separable convolutional strategies to improve real-time inference performance as well as reduce the final trained model size, trainable parameters, and Floating-Point Operations (FLOPs) of EffCNet CNN. Furthermore, extensive supervised image classification analyses are conducted on two benchmarking datasets: CIFAR-10 and CIFAR-100, to verify real-time inference performance of our proposed CNN. Finally, we deploy these trained weights on NXP BlueBox which is an intelligent edge development platform designed for self-driving vehicles and UAVs, and conclusions will be extrapolated accordingly.
* 11 pages, 10 figures, published in American Journal of Electrical and Computer Engineering
Multimodal Masked Autoencoders Learn Transferable Representations
May 31, 2022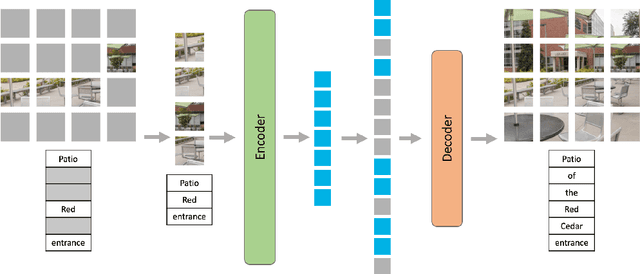
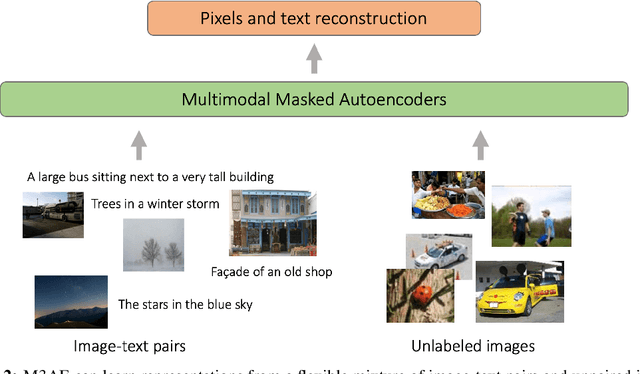
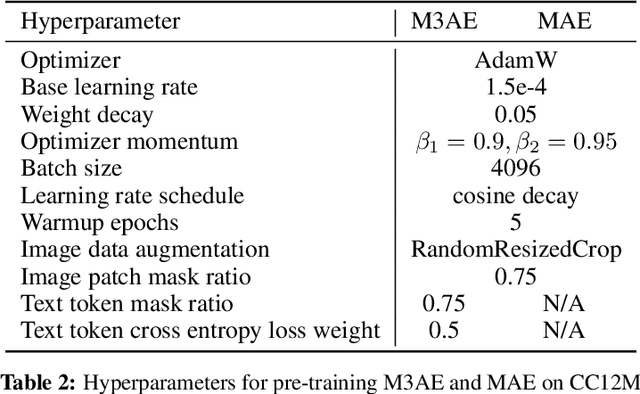
Building scalable models to learn from diverse, multimodal data remains an open challenge. For vision-language data, the dominant approaches are based on contrastive learning objectives that train a separate encoder for each modality. While effective, contrastive learning approaches introduce sampling bias depending on the data augmentations used, which can degrade performance on downstream tasks. Moreover, these methods are limited to paired image-text data, and cannot leverage widely-available unpaired data. In this paper, we investigate whether a large multimodal model trained purely via masked token prediction, without using modality-specific encoders or contrastive learning, can learn transferable representations for downstream tasks. We propose a simple and scalable network architecture, the Multimodal Masked Autoencoder (M3AE), which learns a unified encoder for both vision and language data via masked token prediction. We provide an empirical study of M3AE trained on a large-scale image-text dataset, and find that M3AE is able to learn generalizable representations that transfer well to downstream tasks. Surprisingly, we find that M3AE benefits from a higher text mask ratio (50-90%), in contrast to BERT whose standard masking ratio is 15%, due to the joint training of two data modalities. We also provide qualitative analysis showing that the learned representation incorporates meaningful information from both image and language. Lastly, we demonstrate the scalability of M3AE with larger model size and training time, and its flexibility to train on both paired image-text data as well as unpaired data.
Localization supervision of chest x-ray classifiers using label-specific eye-tracking annotation
Jul 20, 2022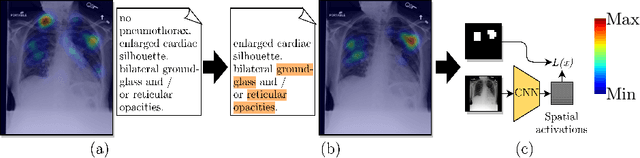
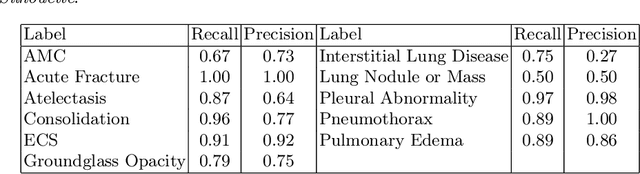
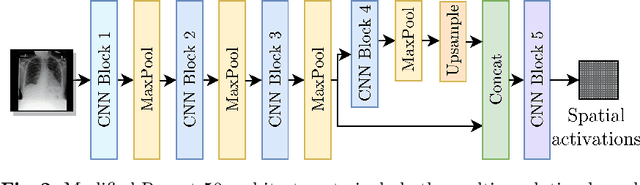
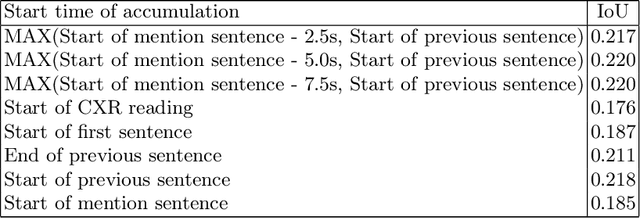
Convolutional neural networks (CNNs) have been successfully applied to chest x-ray (CXR) images. Moreover, annotated bounding boxes have been shown to improve the interpretability of a CNN in terms of localizing abnormalities. However, only a few relatively small CXR datasets containing bounding boxes are available, and collecting them is very costly. Opportunely, eye-tracking (ET) data can be collected in a non-intrusive way during the clinical workflow of a radiologist. We use ET data recorded from radiologists while dictating CXR reports to train CNNs. We extract snippets from the ET data by associating them with the dictation of keywords and use them to supervise the localization of abnormalities. We show that this method improves a model's interpretability without impacting its image-level classification.
CCRL: Contrastive Cell Representation Learning
Aug 12, 2022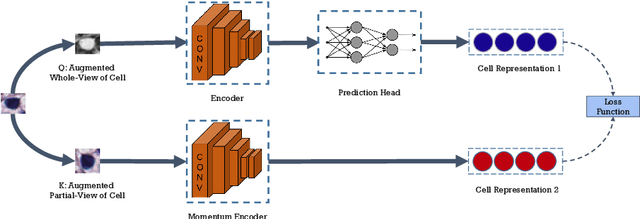
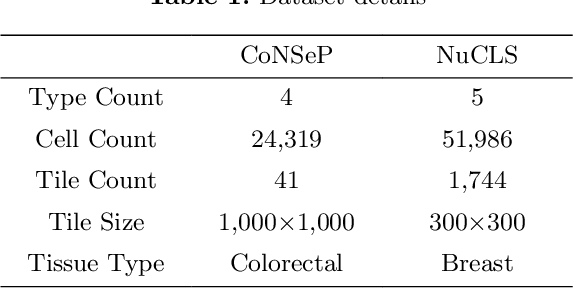
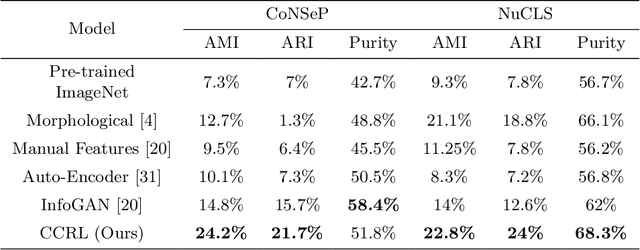
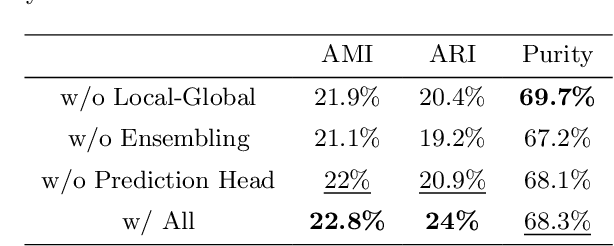
Cell identification within the H&E slides is an essential prerequisite that can pave the way towards further pathology analyses including tissue classification, cancer grading, and phenotype prediction. However, performing such a task using deep learning techniques requires a large cell-level annotated dataset. Although previous studies have investigated the performance of contrastive self-supervised methods in tissue classification, the utility of this class of algorithms in cell identification and clustering is still unknown. In this work, we investigated the utility of Self-Supervised Learning (SSL) in cell clustering by proposing the Contrastive Cell Representation Learning (CCRL) model. Through comprehensive comparisons, we show that this model can outperform all currently available cell clustering models by a large margin across two datasets from different tissue types. More interestingly, the results show that our proposed model worked well with a few number of cell categories while the utility of SSL models has been mainly shown in the context of natural image datasets with large numbers of classes (e.g., ImageNet). The unsupervised representation learning approach proposed in this research eliminates the time-consuming step of data annotation in cell classification tasks, which enables us to train our model on a much larger dataset compared to previous methods. Therefore, considering the promising outcome, this approach can open a new avenue to automatic cell representation learning.
Benchmarking Scientific Image Forgery Detectors
May 26, 2021The scientific image integrity area presents a challenging research bottleneck, the lack of available datasets to design and evaluate forensic techniques. Its data sensitivity creates a legal hurdle that prevents one to rely on real tampered cases to build any sort of accessible forensic benchmark. To mitigate this bottleneck, we present an extendable open-source library that reproduces the most common image forgery operations reported by the research integrity community: duplication, retouching, and cleaning. Using this library and realistic scientific images, we create a large scientific forgery image benchmark (39,423 images) with an enriched ground-truth. In addition, concerned about the high number of retracted papers due to image duplication, this work evaluates the state-of-the-art copy-move detection methods in the proposed dataset, using a new metric that asserts consistent match detection between the source and the copied region. The dataset and source-code will be freely available upon acceptance of the paper.
AFE-CNN: 3D Skeleton-based Action Recognition with Action Feature Enhancement
Aug 06, 2022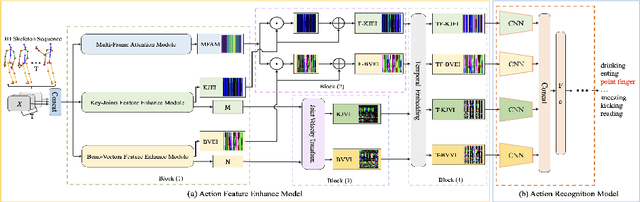
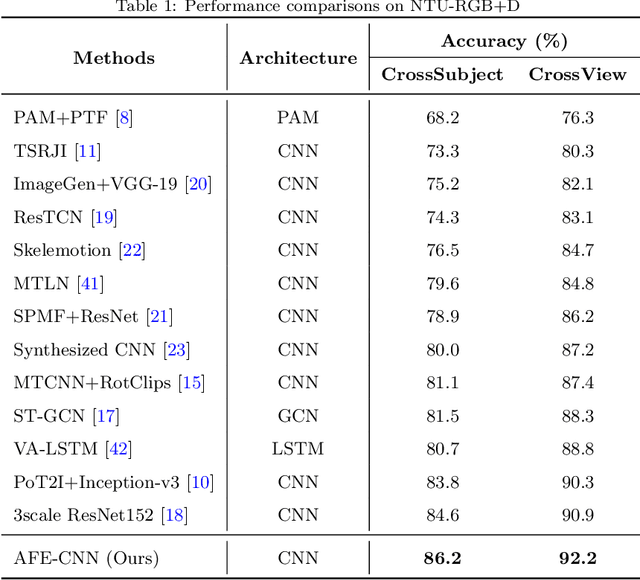
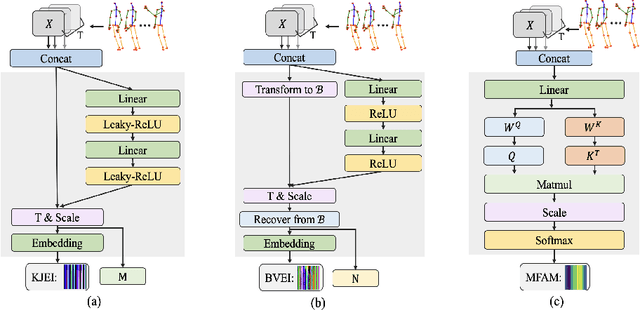
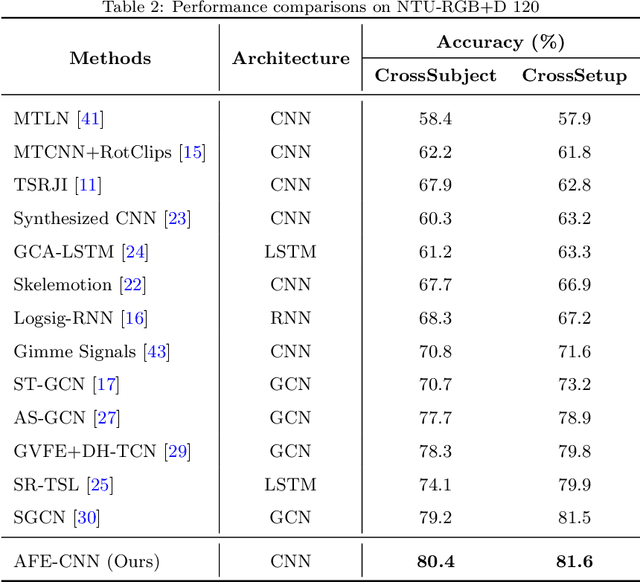
Existing 3D skeleton-based action recognition approaches reach impressive performance by encoding handcrafted action features to image format and decoding by CNNs. However, such methods are limited in two ways: a) the handcrafted action features are difficult to handle challenging actions, and b) they generally require complex CNN models to improve action recognition accuracy, which usually occur heavy computational burden. To overcome these limitations, we introduce a novel AFE-CNN, which devotes to enhance the features of 3D skeleton-based actions to adapt to challenging actions. We propose feature enhance modules from key joint, bone vector, key frame and temporal perspectives, thus the AFE-CNN is more robust to camera views and body sizes variation, and significantly improve the recognition accuracy on challenging actions. Moreover, our AFE-CNN adopts a light-weight CNN model to decode images with action feature enhanced, which ensures a much lower computational burden than the state-of-the-art methods. We evaluate the AFE-CNN on three benchmark skeleton-based action datasets: NTU RGB+D, NTU RGB+D 120, and UTKinect-Action3D, with extensive experimental results demonstrate our outstanding performance of AFE-CNN.
Resisting Adversarial Attacks in Deep Neural Networks using Diverse Decision Boundaries
Aug 18, 2022
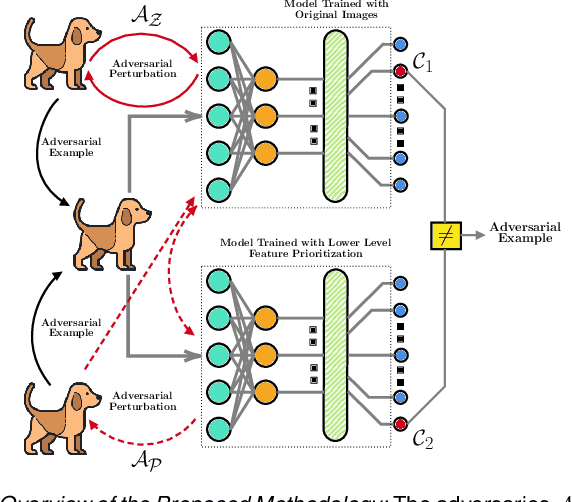

The security of deep learning (DL) systems is an extremely important field of study as they are being deployed in several applications due to their ever-improving performance to solve challenging tasks. Despite overwhelming promises, the deep learning systems are vulnerable to crafted adversarial examples, which may be imperceptible to the human eye, but can lead the model to misclassify. Protections against adversarial perturbations on ensemble-based techniques have either been shown to be vulnerable to stronger adversaries or shown to lack an end-to-end evaluation. In this paper, we attempt to develop a new ensemble-based solution that constructs defender models with diverse decision boundaries with respect to the original model. The ensemble of classifiers constructed by (1) transformation of the input by a method called Split-and-Shuffle, and (2) restricting the significant features by a method called Contrast-Significant-Features are shown to result in diverse gradients with respect to adversarial attacks, which reduces the chance of transferring adversarial examples from the original to the defender model targeting the same class. We present extensive experimentations using standard image classification datasets, namely MNIST, CIFAR-10 and CIFAR-100 against state-of-the-art adversarial attacks to demonstrate the robustness of the proposed ensemble-based defense. We also evaluate the robustness in the presence of a stronger adversary targeting all the models within the ensemble simultaneously. Results for the overall false positives and false negatives have been furnished to estimate the overall performance of the proposed methodology.
Revisiting lp-constrained Softmax Loss: A Comprehensive Study
Jun 20, 2022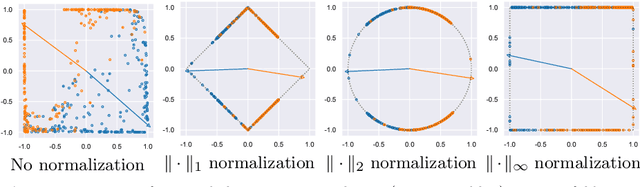
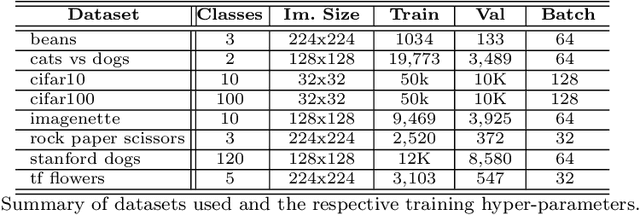

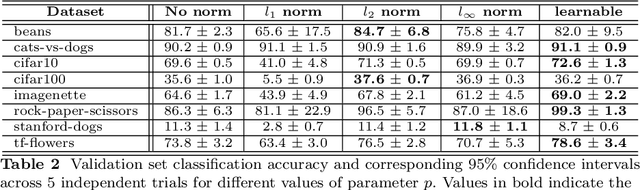
Normalization is a vital process for any machine learning task as it controls the properties of data and affects model performance at large. The impact of particular forms of normalization, however, has so far been investigated in limited domain-specific classification tasks and not in a general fashion. Motivated by the lack of such a comprehensive study, in this paper we investigate the performance of lp-constrained softmax loss classifiers across different norm orders, magnitudes, and data dimensions in both proof-of-concept classification problems and real-world popular image classification tasks. Experimental results suggest collectively that lp-constrained softmax loss classifiers not only can achieve more accurate classification results but, at the same time, appear to be less prone to overfitting. The core findings hold across the three popular deep learning architectures tested and eight datasets examined, and suggest that lp normalization is a recommended data representation practice for image classification in terms of performance and convergence, and against overfitting.
Where is VALDO? VAscular Lesions Detection and segmentatiOn challenge at MICCAI 2021
Aug 15, 2022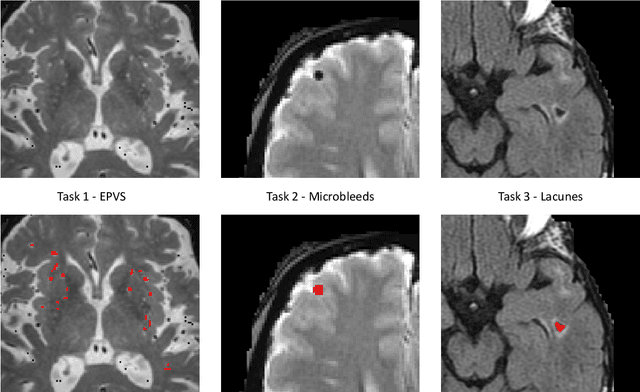
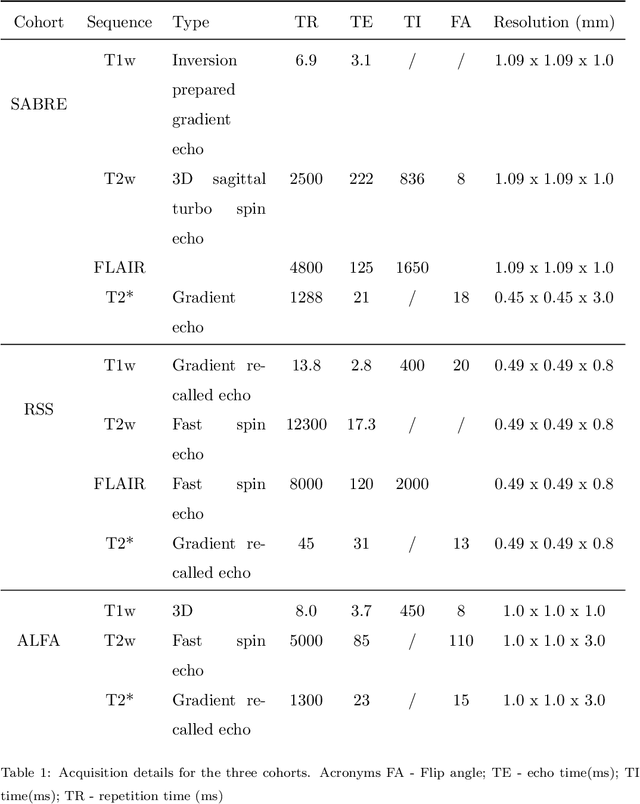
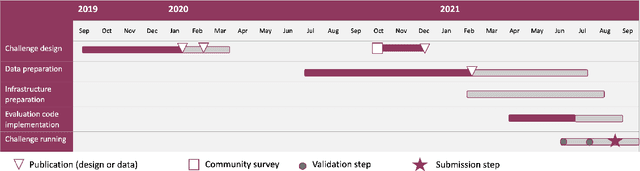
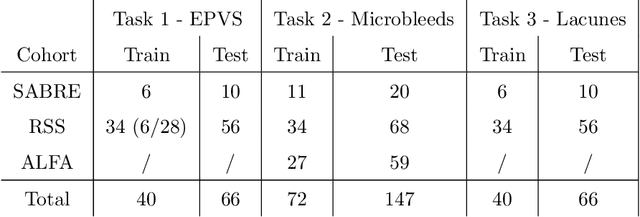
Imaging markers of cerebral small vessel disease provide valuable information on brain health, but their manual assessment is time-consuming and hampered by substantial intra- and interrater variability. Automated rating may benefit biomedical research, as well as clinical assessment, but diagnostic reliability of existing algorithms is unknown. Here, we present the results of the \textit{VAscular Lesions DetectiOn and Segmentation} (\textit{Where is VALDO?}) challenge that was run as a satellite event at the international conference on Medical Image Computing and Computer Aided Intervention (MICCAI) 2021. This challenge aimed to promote the development of methods for automated detection and segmentation of small and sparse imaging markers of cerebral small vessel disease, namely enlarged perivascular spaces (EPVS) (Task 1), cerebral microbleeds (Task 2) and lacunes of presumed vascular origin (Task 3) while leveraging weak and noisy labels. Overall, 12 teams participated in the challenge proposing solutions for one or more tasks (4 for Task 1 - EPVS, 9 for Task 2 - Microbleeds and 6 for Task 3 - Lacunes). Multi-cohort data was used in both training and evaluation. Results showed a large variability in performance both across teams and across tasks, with promising results notably for Task 1 - EPVS and Task 2 - Microbleeds and not practically useful results yet for Task 3 - Lacunes. It also highlighted the performance inconsistency across cases that may deter use at an individual level, while still proving useful at a population level.