 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondenseNeXt: An Ultra-Efficient Deep Neural Network for Embedded Systems
Dec 01, 2021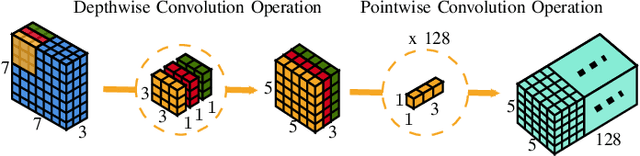
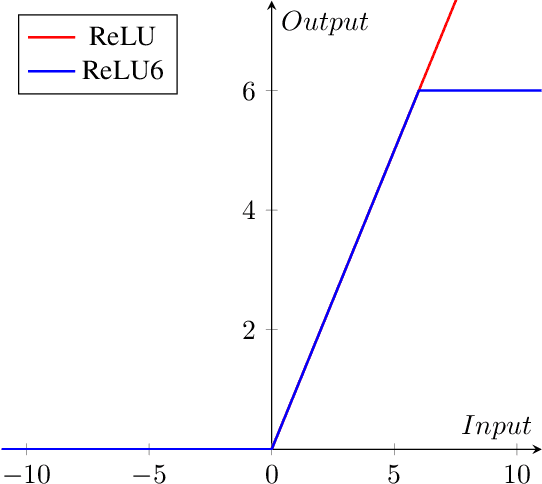
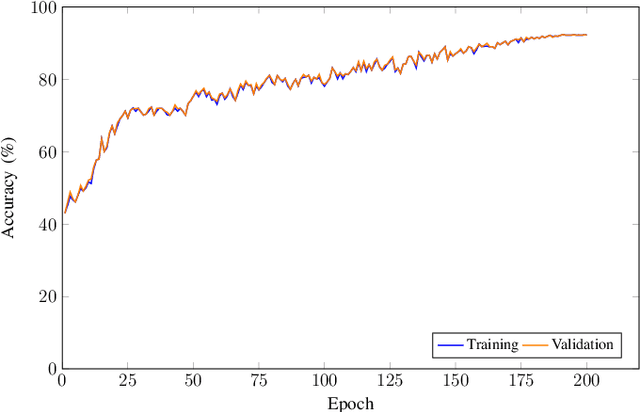

Due to the advent of modern embedded systems and mobile devices with constrained resources, there is a great demand for incredibly efficient deep neural networks for machine learning purposes. There is also a growing concern of privacy and confidentiality of user data within the general public when their data is processed and stored in an external server which has further fueled the need for developing such efficient neural networks for real-time inference on local embedded systems. The scope of our work presented in this paper is limited to image classification using a convolutional neural network. A Convolutional Neural Network (CNN) is a class of Deep Neural Network (DNN) widely used in the analysis of visual images captured by an image sensor, designed to extract information and convert it into meaningful representations for real-time inference of the input data. In this paper, we propose a neoteric variant of deep convolutional neural network architecture to ameliorate the performance of existing CNN architectures for real-time inference on embedded systems. We show that this architecture, dubbed CondenseNeXt, is remarkably efficient in comparison to the baseline neural network architecture, CondenseNet, by reducing trainable parameters and FLOPs required to train the network whilst maintaining a balance between the trained model size of less than 3.0 MB and accuracy trade-off resulting in an unprecedented computational efficiency.
EffCNet: An Efficient CondenseNet for Image Classification on NXP BlueBox
Nov 28, 2021

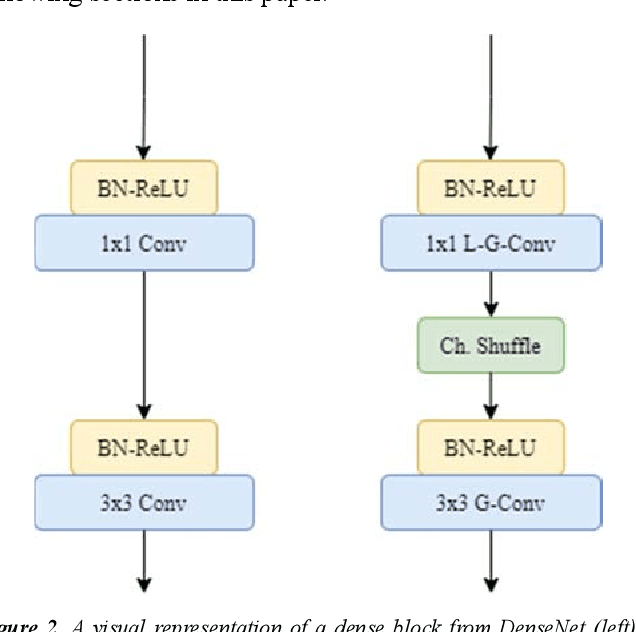
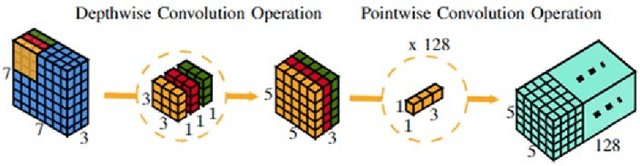
Intelligent edge devices with built-in processors vary widely in terms of capability and physical form to perform advanced Computer Vision (CV) tasks such as image classification and object detection, for example. With constant advances in the field of autonomous cars and UAVs, embedded systems and mobile devices, there has been an ever-growing demand for extremely efficient Artificial Neural Networks (ANN) for real-time inference on these smart edge devices with constrained computational resources. With unreliable network connections in remote regions and an added complexity of data transmission, it is of an utmost importance to capture and process data locally instead of sending the data to cloud servers for remote processing. Edge devices on the other hand, offer limited processing power due to their inexpensive hardware, and limited cooling and computational resources. In this paper, we propose a novel deep convolutional neural network architecture called EffCNet which is an improved and an efficient version of CondenseNet Convolutional Neural Network (CNN) for edge devices utilizing self-querying data augmentation and depthwise separable convolutional strategies to improve real-time inference performance as well as reduce the final trained model size, trainable parameters, and Floating-Point Operations (FLOPs) of EffCNet CNN. Furthermore, extensive supervised image classification analyses are conducted on two benchmarking datasets: CIFAR-10 and CIFAR-100, to verify real-time inference performance of our proposed CNN. Finally, we deploy these trained weights on NXP BlueBox which is an intelligent edge development platform designed for self-driving vehicles and UAVs, and conclusions will be extrapolated accordingly.
* 11 pages, 10 figures, published in American Journal of Electrical and Computer Engineering
Image Classification with CondenseNeXt for ARM-Based Computing Platforms
Jun 26, 2021
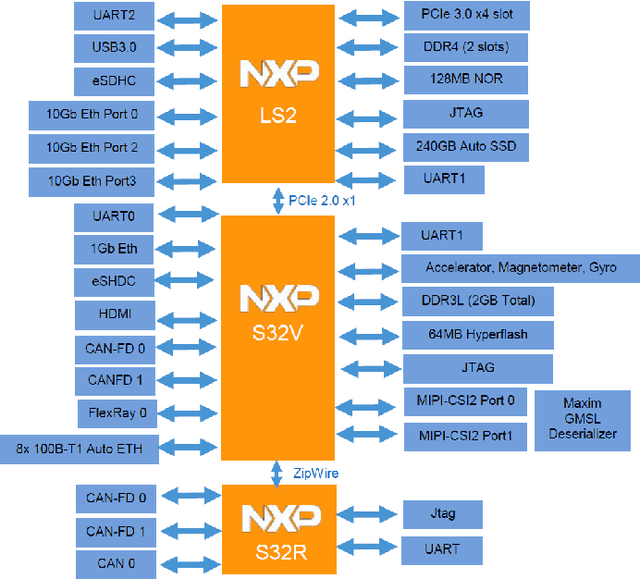
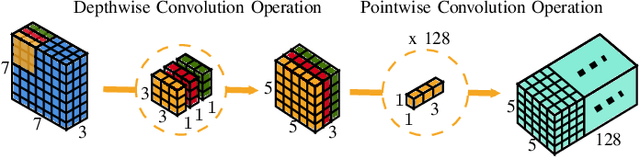
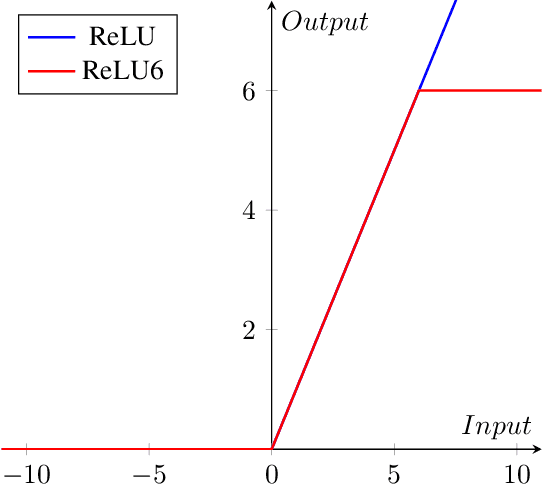
In this paper, we demonstrate the implementation of our ultra-efficient deep convolutional neural network architecture: CondenseNeXt on NXP BlueBox, an autonomous driving development platform developed for self-driving vehicles. We show that CondenseNeXt is remarkably efficient in terms of FLOPs, designed for ARM-based embedded computing platforms with limited computational resources and can perform image classification without the need of a CUDA enabled GPU. CondenseNeXt utilizes the state-of-the-art depthwise separable convolution and model compression techniques to achieve a remarkable computational efficiency. Extensive analyses are conducted on CIFAR-10, CIFAR-100 and ImageNet datasets to verify the performance of CondenseNeXt Convolutional Neural Network (CNN) architecture. It achieves state-of-the-art image classification performance on three benchmark datasets including CIFAR-10 (4.79% top-1 error), CIFAR-100 (21.98% top-1 error) and ImageNet (7.91% single model, single crop top-5 error). CondenseNeXt achieves final trained model size improvement of 2.9+ MB and up to 59.98% reduction in forward FLOPs compared to CondenseNet and can perform image classification on ARM-Based computing platforms without needing a CUDA enabled GPU support, with outstanding efficiency.