 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022
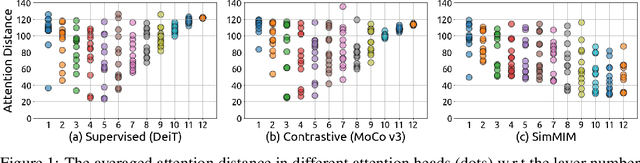

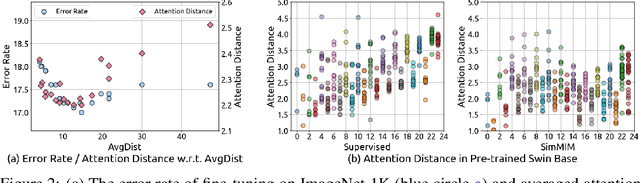
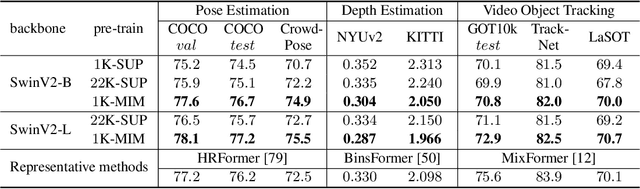
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
A Closer Look at Robustness to L-infinity and Spatial Perturbations and their Composition
Oct 05, 2022
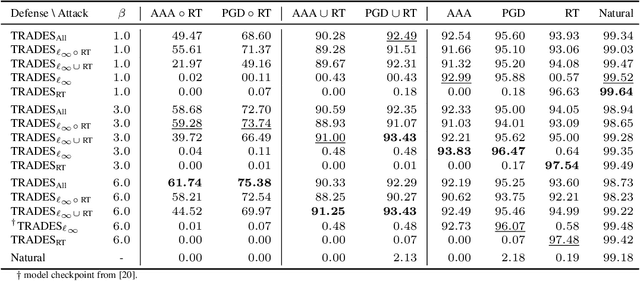
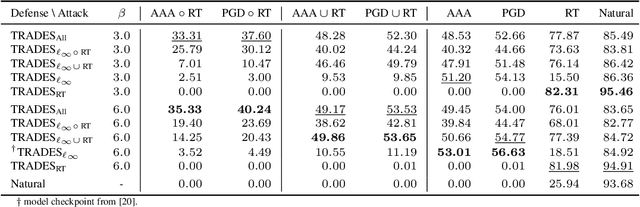
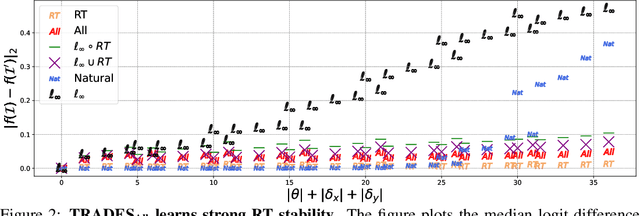
In adversarial machine learning, the popular $\ell_\infty$ threat model has been the focus of much previous work. While this mathematical definition of imperceptibility successfully captures an infinite set of additive image transformations that a model should be robust to, this is only a subset of all transformations which leave the semantic label of an image unchanged. Indeed, previous work also considered robustness to spatial attacks as well as other semantic transformations; however, designing defense methods against the composition of spatial and $\ell_{\infty}$ perturbations remains relatively underexplored. In the following, we improve the understanding of this seldom investigated compositional setting. We prove theoretically that no linear classifier can achieve more than trivial accuracy against a composite adversary in a simple statistical setting, illustrating its difficulty. We then investigate how state-of-the-art $\ell_{\infty}$ defenses can be adapted to this novel threat model and study their performance against compositional attacks. We find that our newly proposed TRADES$_{\text{All}}$ strategy performs the strongest of all. Analyzing its logit's Lipschitz constant for RT transformations of different sizes, we find that TRADES$_{\text{All}}$ remains stable over a wide range of RT transformations with and without $\ell_\infty$ perturbations.
Cross Modal Compression: Towards Human-comprehensible Semantic Compression
Sep 06, 2022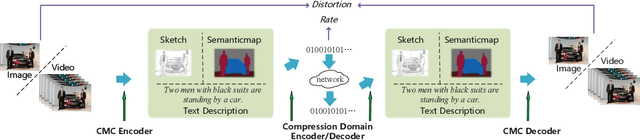
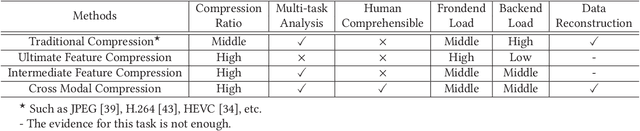
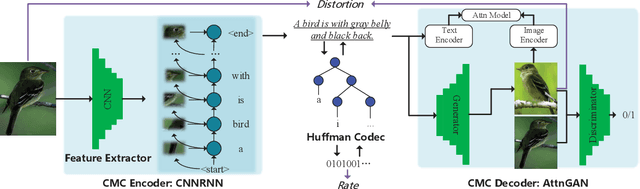

Traditional image/video compression aims to reduce the transmission/storage cost with signal fidelity as high as possible. However, with the increasing demand for machine analysis and semantic monitoring in recent years, semantic fidelity rather than signal fidelity is becoming another emerging concern in image/video compression. With the recent advances in cross modal translation and generation, in this paper, we propose the cross modal compression~(CMC), a semantic compression framework for visual data, to transform the high redundant visual data~(such as image, video, etc.) into a compact, human-comprehensible domain~(such as text, sketch, semantic map, attributions, etc.), while preserving the semantic. Specifically, we first formulate the CMC problem as a rate-distortion optimization problem. Secondly, we investigate the relationship with the traditional image/video compression and the recent feature compression frameworks, showing the difference between our CMC and these prior frameworks. Then we propose a novel paradigm for CMC to demonstrate its effectiveness. The qualitative and quantitative results show that our proposed CMC can achieve encouraging reconstructed results with an ultrahigh compression ratio, showing better compression performance than the widely used JPEG baseline.
Real-Time Dense Field Phase-to-Space Simulation of Imaging through Atmospheric Turbulence
Oct 13, 2022
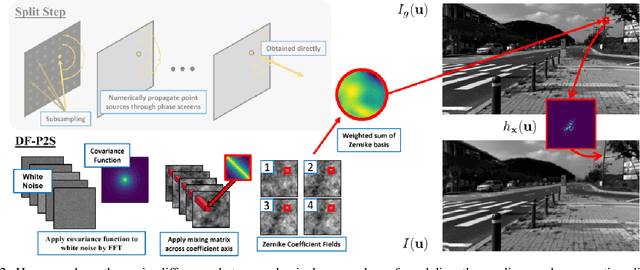
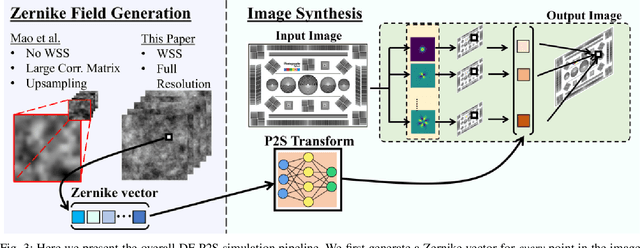
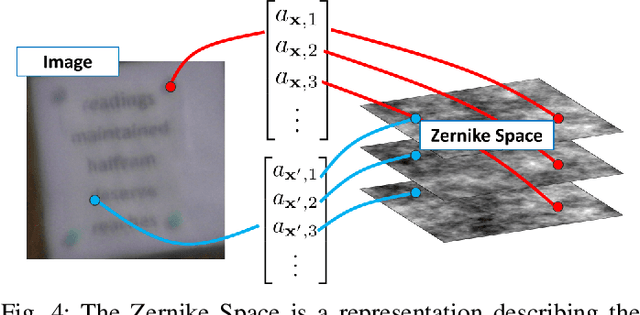
Numerical simulation of atmospheric turbulence is one of the biggest bottlenecks in developing computational techniques for solving the inverse problem in long-range imaging. The classical split-step method is based upon numerical wave propagation which splits the propagation path into many segments and propagates every pixel in each segment individually via the Fresnel integral. This repeated evaluation becomes increasingly time-consuming for larger images. As a result, the split-step simulation is often done only on a sparse grid of points followed by an interpolation to the other pixels. Even so, the computation is expensive for real-time applications. In this paper, we present a new simulation method that enables \emph{real-time} processing over a \emph{dense} grid of points. Building upon the recently developed multi-aperture model and the phase-to-space transform, we overcome the memory bottleneck in drawing random samples from the Zernike correlation tensor. We show that the cross-correlation of the Zernike modes has an insignificant contribution to the statistics of the random samples. By approximating these cross-correlation blocks in the Zernike tensor, we restore the homogeneity of the tensor which then enables Fourier-based random sampling. On a $512\times512$ image, the new simulator achieves 0.025 seconds per frame over a dense field. On a $3840 \times 2160$ image which would have taken 13 hours to simulate using the split-step method, the new simulator can run at approximately 60 seconds per frame.
Single-Image 3D Face Reconstruction under Perspective Projection
May 09, 2022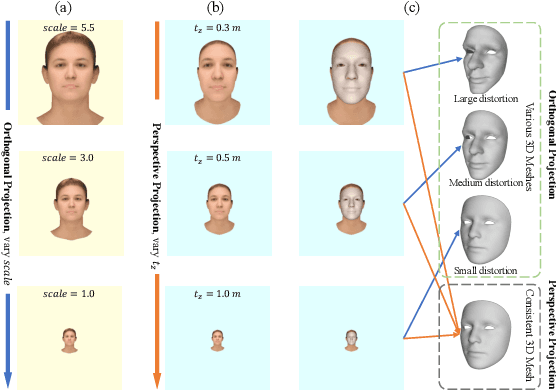
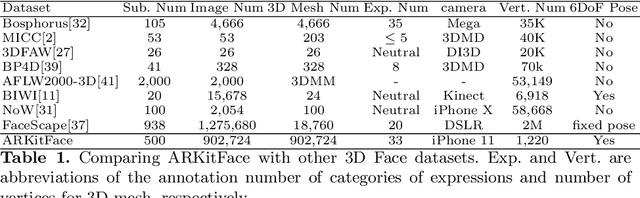
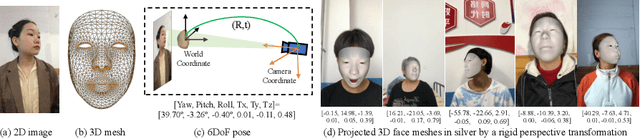

In 3D face reconstruction, orthogonal projection has been widely employed to substitute perspective projection to simplify the fitting process. This approximation performs well when the distance between camera and face is far enough. However, in some scenarios that the face is very close to camera or moving along the camera axis, the methods suffer from the inaccurate reconstruction and unstable temporal fitting due to the distortion under the perspective projection. In this paper, we aim to address the problem of single-image 3D face reconstruction under perspective projection. Specifically, a deep neural network, Perspective Network (PerspNet), is proposed to simultaneously reconstruct 3D face shape in canonical space and learn the correspondence between 2D pixels and 3D points, by which the 6DoF (6 Degrees of Freedom) face pose can be estimated to represent perspective projection. Besides, we contribute a large ARKitFace dataset to enable the training and evaluation of 3D face reconstruction solutions under the scenarios of perspective projection, which has 902,724 2D facial images with ground-truth 3D face mesh and annotated 6DoF pose parameters. Experimental results show that our approach outperforms current state-of-the-art methods by a significant margin.
Towards Better Guided Attention and Human Knowledge Insertion in Deep Convolutional Neural Networks
Oct 20, 2022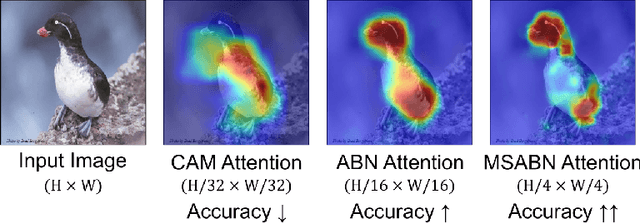

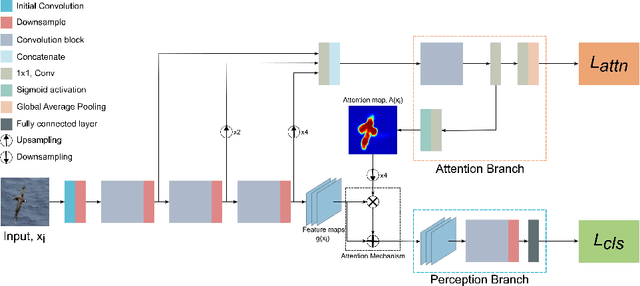
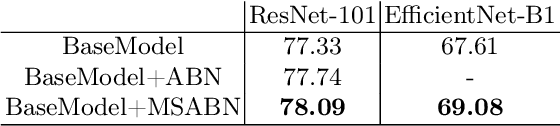
Attention Branch Networks (ABNs) have been shown to simultaneously provide visual explanation and improve the performance of deep convolutional neural networks (CNNs). In this work, we introduce Multi-Scale Attention Branch Networks (MSABN), which enhance the resolution of the generated attention maps, and improve the performance. We evaluate MSABN on benchmark image recognition and fine-grained recognition datasets where we observe MSABN outperforms ABN and baseline models. We also introduce a new data augmentation strategy utilizing the attention maps to incorporate human knowledge in the form of bounding box annotations of the objects of interest. We show that even with a limited number of edited samples, a significant performance gain can be achieved with this strategy.
Convolutional Simultaneous Sparse Approximation with Applications to RGB-NIR Image Fusion
Mar 18, 2022



Simultaneous sparse approximation (SSA) seeks to represent a set of dependent signals using sparse vectors with identical supports. The SSA model has been used in various signal and image processing applications involving multiple correlated input signals. In this paper, we propose algorithms for convolutional SSA (CSSA) based on the alternating direction method of multipliers. Specifically, we address the CSSA problem with different sparsity structures and the convolutional feature learning problem in multimodal data/signals based on the SSA model. We evaluate the proposed algorithms by applying them to multimodal and multifocus image fusion problems.
FIXED: Frustratingly Easy Domain Generalization with Mixup
Nov 07, 2022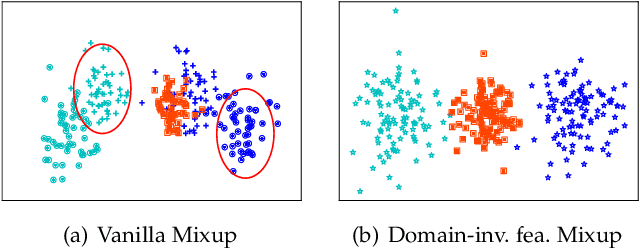

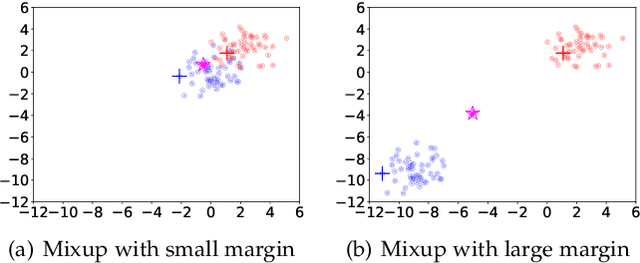
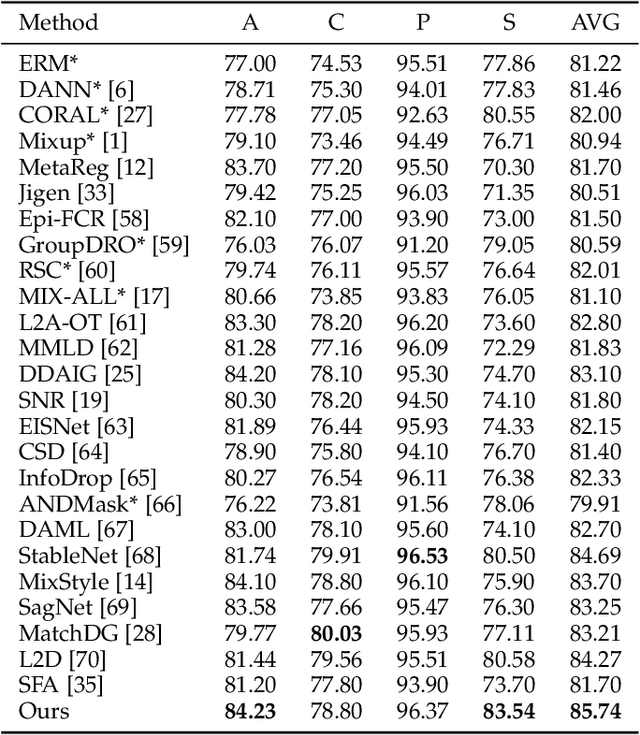
Domain generalization (DG) aims to learn a generalizable model from multiple training domains such that it can perform well on unseen target domains. A popular strategy is to augment training data to benefit generalization through methods such as Mixup~\cite{zhang2018mixup}. While the vanilla Mixup can be directly applied, theoretical and empirical investigations uncover several shortcomings that limit its performance. Firstly, Mixup cannot effectively identify the domain and class information that can be used for learning invariant representations. Secondly, Mixup may introduce synthetic noisy data points via random interpolation, which lowers its discrimination capability. Based on the analysis, we propose a simple yet effective enhancement for Mixup-based DG, namely domain-invariant Feature mIXup (FIX). It learns domain-invariant representations for Mixup. To further enhance discrimination, we leverage existing techniques to enlarge margins among classes to further propose the domain-invariant Feature MIXup with Enhanced Discrimination (FIXED) approach. We present theoretical insights about guarantees on its effectiveness. Extensive experiments on seven public datasets across two modalities including image classification (Digits-DG, PACS, Office-Home) and time series (DSADS, PAMAP2, UCI-HAR, and USC-HAD) demonstrate that our approach significantly outperforms nine state-of-the-art related methods, beating the best performing baseline by 6.5\% on average in terms of test accuracy.
A Robust Document Image Watermarking Scheme using Deep Neural Network
Feb 26, 2022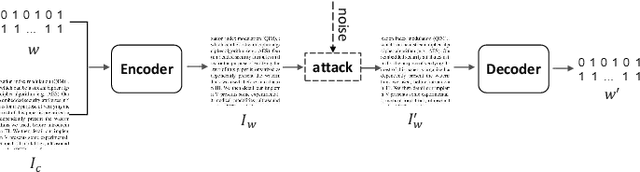



Watermarking is an important copyright protection technology which generally embeds the identity information into the carrier imperceptibly. Then the identity can be extracted to prove the copyright from the watermarked carrier even after suffering various attacks. Most of the existing watermarking technologies take the nature images as carriers. Different from the natural images, document images are not so rich in color and texture, and thus have less redundant information to carry watermarks. This paper proposes an end-to-end document image watermarking scheme using the deep neural network. Specifically, an encoder and a decoder are designed to embed and extract the watermark. A noise layer is added to simulate the various attacks that could be encountered in reality, such as the Cropout, Dropout, Gaussian blur, Gaussian noise, Resize, and JPEG Compression. A text-sensitive loss function is designed to limit the embedding modification on characters. An embedding strength adjustment strategy is proposed to improve the quality of watermarked image with little loss of extraction accuracy. Experimental results show that the proposed document image watermarking technology outperforms three state-of-the-arts in terms of the robustness and image quality.
Image Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
Sep 16, 2022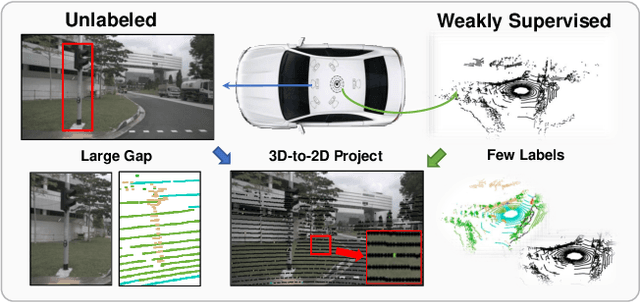
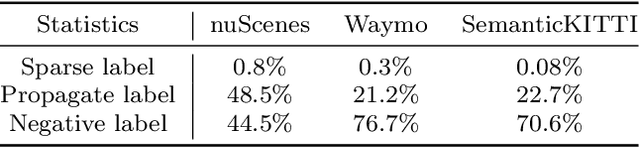

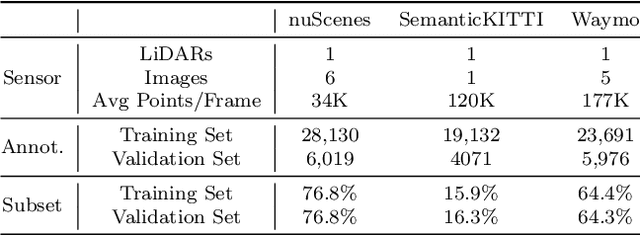
Weakly supervised point cloud semantic segmentation methods that require 1\% or fewer labels, hoping to realize almost the same performance as fully supervised approaches, which recently, have attracted extensive research attention. A typical solution in this framework is to use self-training or pseudo labeling to mine the supervision from the point cloud itself, but ignore the critical information from images. In fact, cameras widely exist in LiDAR scenarios and this complementary information seems to be greatly important for 3D applications. In this paper, we propose a novel cross-modality weakly supervised method for 3D segmentation, incorporating complementary information from unlabeled images. Basically, we design a dual-branch network equipped with an active labeling strategy, to maximize the power of tiny parts of labels and directly realize 2D-to-3D knowledge transfer. Afterwards, we establish a cross-modal self-training framework in an Expectation-Maximum (EM) perspective, which iterates between pseudo labels estimation and parameters updating. In the M-Step, we propose a cross-modal association learning to mine complementary supervision from images by reinforcing the cycle-consistency between 3D points and 2D superpixels. In the E-step, a pseudo label self-rectification mechanism is derived to filter noise labels thus providing more accurate labels for the networks to get fully trained. The extensive experimental results demonstrate that our method even outperforms the state-of-the-art fully supervised competitors with less than 1\% actively selected annotations.