 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Understands Point Cloud: Weakly Supervised 3D Semantic Segmentation via Association Learning
Paper and Code
Sep 16, 2022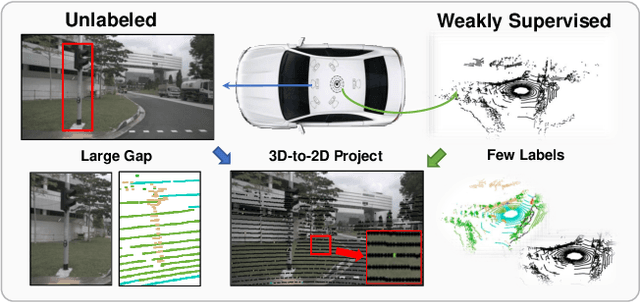
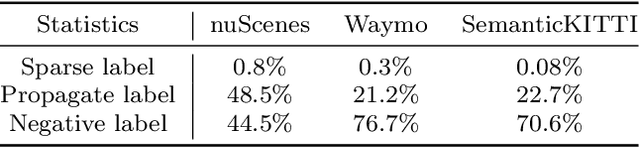

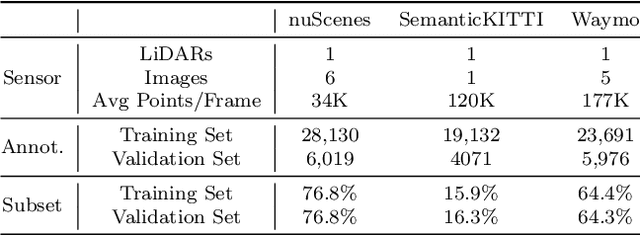
Weakly supervised point cloud semantic segmentation methods that require 1\% or fewer labels, hoping to realize almost the same performance as fully supervised approaches, which recently, have attracted extensive research attention. A typical solution in this framework is to use self-training or pseudo labeling to mine the supervision from the point cloud itself, but ignore the critical information from images. In fact, cameras widely exist in LiDAR scenarios and this complementary information seems to be greatly important for 3D applications. In this paper, we propose a novel cross-modality weakly supervised method for 3D segmentation, incorporating complementary information from unlabeled images. Basically, we design a dual-branch network equipped with an active labeling strategy, to maximize the power of tiny parts of labels and directly realize 2D-to-3D knowledge transfer. Afterwards, we establish a cross-modal self-training framework in an Expectation-Maximum (EM) perspective, which iterates between pseudo labels estimation and parameters updating. In the M-Step, we propose a cross-modal association learning to mine complementary supervision from images by reinforcing the cycle-consistency between 3D points and 2D superpixels. In the E-step, a pseudo label self-rectification mechanism is derived to filter noise labels thus providing more accurate labels for the networks to get fully trained. The extensive experimental results demonstrate that our method even outperforms the state-of-the-art fully supervised competitors with less than 1\% actively selected annotations.