 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
What's Different between Visual Question Answering for Machine "Understanding" Versus for Accessibility?
Oct 26, 2022

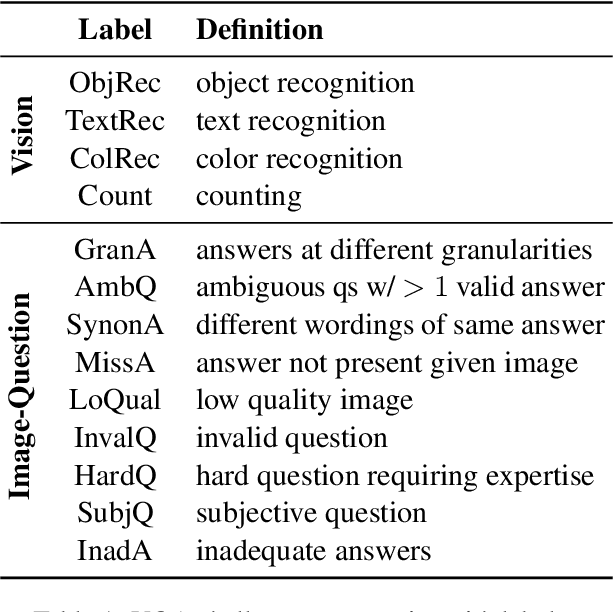
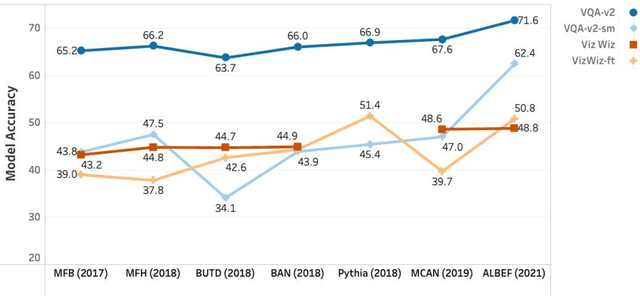
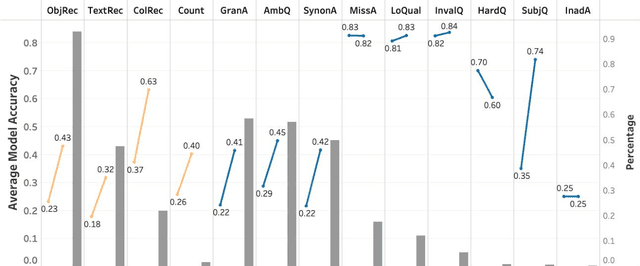
In visual question answering (VQA), a machine must answer a question given an associated image. Recently, accessibility researchers have explored whether VQA can be deployed in a real-world setting where users with visual impairments learn about their environment by capturing their visual surroundings and asking questions. However, most of the existing benchmarking datasets for VQA focus on machine "understanding" and it remains unclear how progress on those datasets corresponds to improvements in this real-world use case. We aim to answer this question by evaluating discrepancies between machine "understanding" datasets (VQA-v2) and accessibility datasets (VizWiz) by evaluating a variety of VQA models. Based on our findings, we discuss opportunities and challenges in VQA for accessibility and suggest directions for future work.
Data augmentation for NeRF: a geometric consistent solution based on view morphing
Oct 09, 2022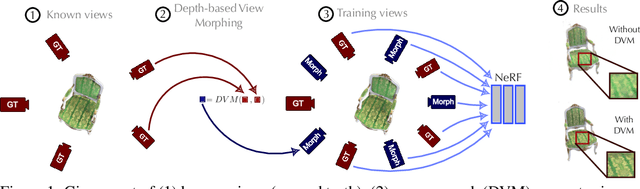
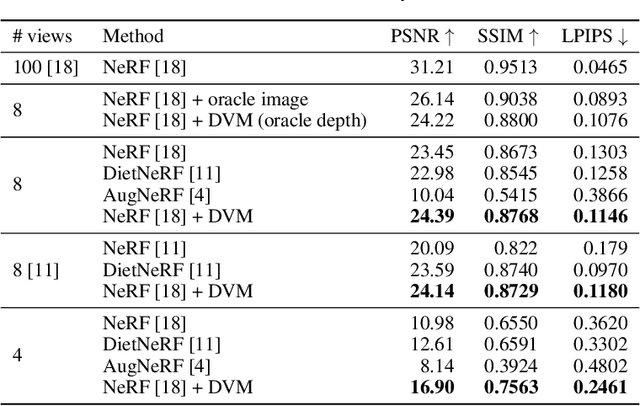
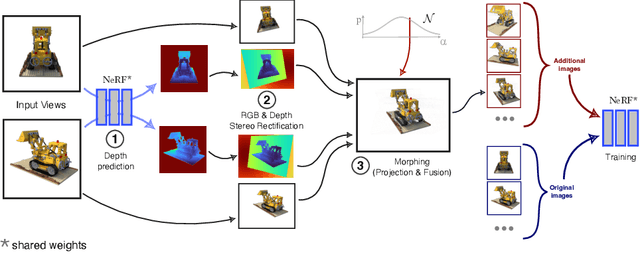
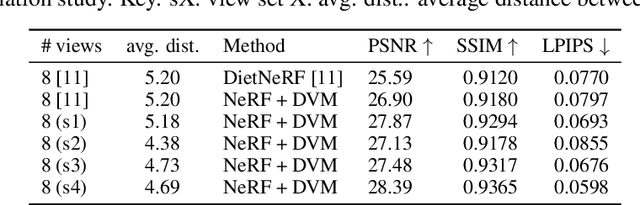
NeRF aims to learn a continuous neural scene representation by using a finite set of input images taken from different viewpoints. The fewer the number of viewpoints, the higher the likelihood of overfitting on them. This paper mitigates such limitation by presenting a novel data augmentation approach to generate geometrically consistent image transitions between viewpoints using view morphing. View morphing is a highly versatile technique that does not requires any prior knowledge about the 3D scene because it is based on general principles of projective geometry. A key novelty of our method is to use the very same depths predicted by NeRF to generate the image transitions that are then added to NeRF training. We experimentally show that this procedure enables NeRF to improve the quality of its synthesised novel views in the case of datasets with few training viewpoints. We improve PSNR up to 1.8dB and 10.5dB when eight and four views are used for training, respectively. To the best of our knowledge, this is the first data augmentation strategy for NeRF that explicitly synthesises additional new input images to improve the model generalisation.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022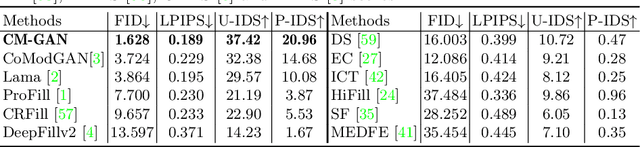
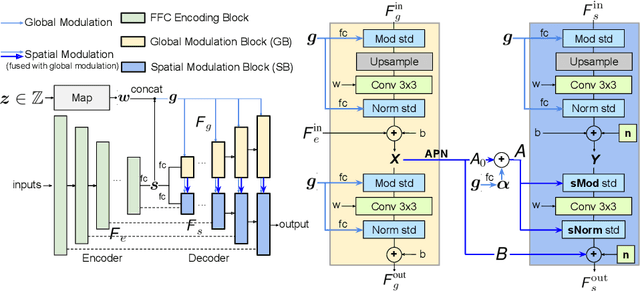
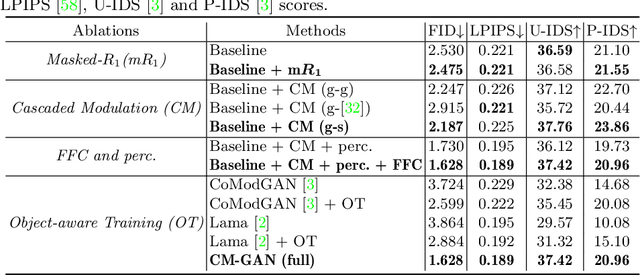

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
Data Efficient Visual Place Recognition Using Extremely JPEG-Compressed Images
Sep 17, 2022
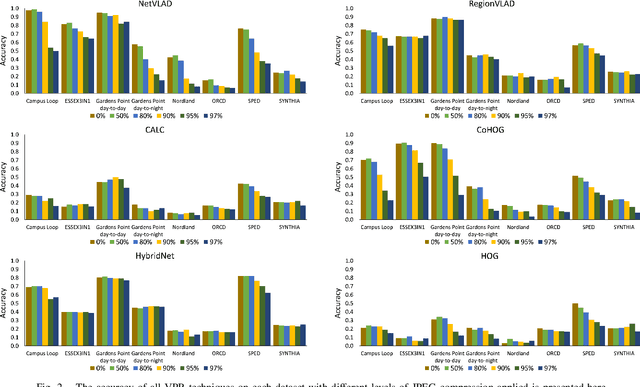
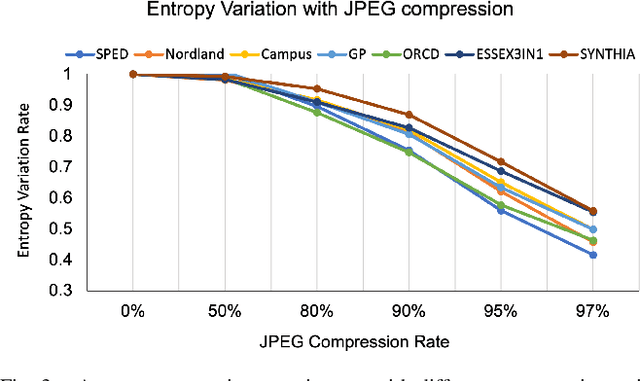

Visual Place Recognition (VPR) is the ability of a robotic platform to correctly interpret visual stimuli from its on-board cameras in order to determine whether it is currently located in a previously visited place, despite different viewpoint, illumination and appearance changes. JPEG is a widely used image compression standard that is capable of significantly reducing the size of an image at the cost of image clarity. For applications where several robotic platforms are simultaneously deployed, the visual data gathered must be transmitted remotely between each robot. Hence, JPEG compression can be employed to drastically reduce the amount of data transmitted over a communication channel, as working with limited bandwidth for VPR can be proven to be a challenging task. However, the effects of JPEG compression on the performance of current VPR techniques have not been previously studied. For this reason, this paper presents an in-depth study of JPEG compression in VPR related scenarios. We use a selection of well-established VPR techniques on 8 datasets with various amounts of compression applied. We show that by introducing compression, the VPR performance is drastically reduced, especially in the higher spectrum of compression. To overcome the negative effects of JPEG compression on the VPR performance, we present a fine-tuned CNN which is optimized for JPEG compressed data and show that it performs more consistently with the image transformations detected in extremely compressed JPEG images.
Learning-based and unrolled motion-compensated reconstruction for cardiac MR CINE imaging
Sep 08, 2022



Motion-compensated MR reconstruction (MCMR) is a powerful concept with considerable potential, consisting of two coupled sub-problems: Motion estimation, assuming a known image, and image reconstruction, assuming known motion. In this work, we propose a learning-based self-supervised framework for MCMR, to efficiently deal with non-rigid motion corruption in cardiac MR imaging. Contrary to conventional MCMR methods in which the motion is estimated prior to reconstruction and remains unchanged during the iterative optimization process, we introduce a dynamic motion estimation process and embed it into the unrolled optimization. We establish a cardiac motion estimation network that leverages temporal information via a group-wise registration approach, and carry out a joint optimization between the motion estimation and reconstruction. Experiments on 40 acquired 2D cardiac MR CINE datasets demonstrate that the proposed unrolled MCMR framework can reconstruct high quality MR images at high acceleration rates where other state-of-the-art methods fail. We also show that the joint optimization mechanism is mutually beneficial for both sub-tasks, i.e., motion estimation and image reconstruction, especially when the MR image is highly undersampled.
Landmark Tracking in Liver US images Using Cascade Convolutional Neural Networks with Long Short-Term Memory
Sep 14, 2022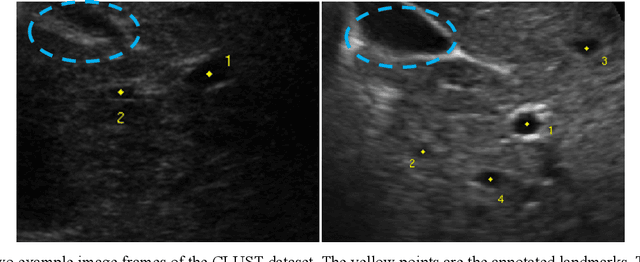
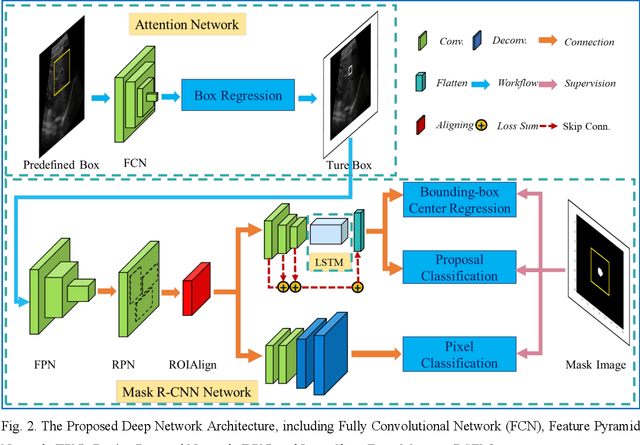
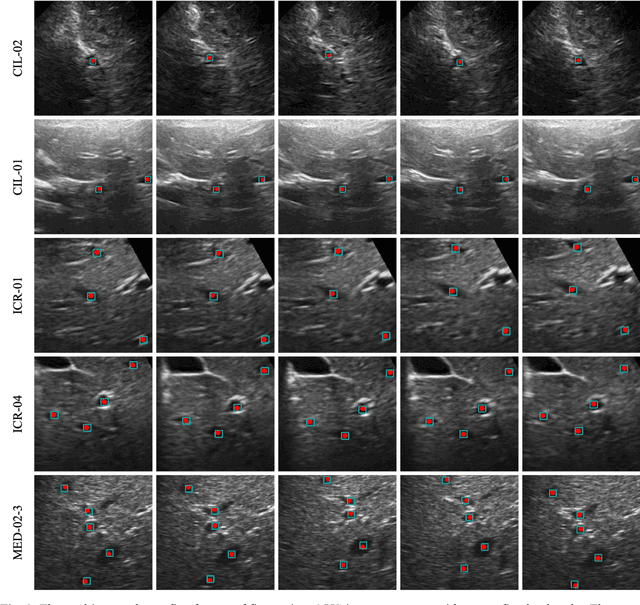
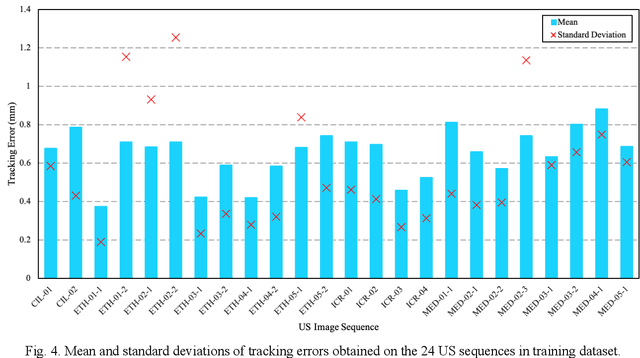
This study proposed a deep learning-based tracking method for ultrasound (US) image-guided radiation therapy. The proposed cascade deep learning model is composed of an attention network, a mask region-based convolutional neural network (mask R-CNN), and a long short-term memory (LSTM) network. The attention network learns a mapping from a US image to a suspected area of landmark motion in order to reduce the search region. The mask R-CNN then produces multiple region-of-interest (ROI) proposals in the reduced region and identifies the proposed landmark via three network heads: bounding box regression, proposal classification, and landmark segmentation. The LSTM network models the temporal relationship among the successive image frames for bounding box regression and proposal classification. To consolidate the final proposal, a selection method is designed according to the similarities between sequential frames. The proposed method was tested on the liver US tracking datasets used in the Medical Image Computing and Computer Assisted Interventions (MICCAI) 2015 challenges, where the landmarks were annotated by three experienced observers to obtain their mean positions. Five-fold cross-validation on the 24 given US sequences with ground truths shows that the mean tracking error for all landmarks is 0.65+/-0.56 mm, and the errors of all landmarks are within 2 mm. We further tested the proposed model on 69 landmarks from the testing dataset that has a similar image pattern to the training pattern, resulting in a mean tracking error of 0.94+/-0.83 mm. Our experimental results have demonstrated the feasibility and accuracy of our proposed method in tracking liver anatomic landmarks using US images, providing a potential solution for real-time liver tracking for active motion management during radiation therapy.
Single-image Defocus Deblurring by Integration of Defocus Map Prediction Tracing the Inverse Problem Computation
Jul 07, 2022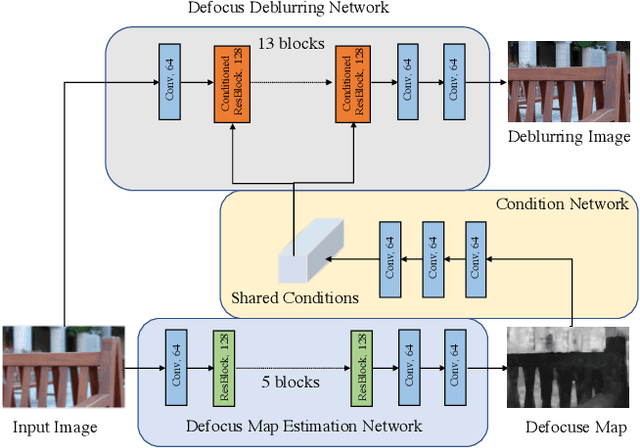
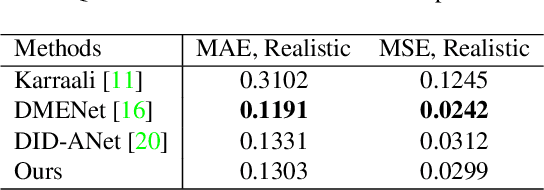
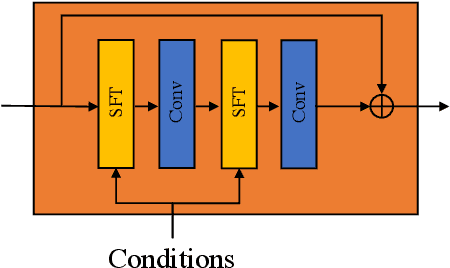
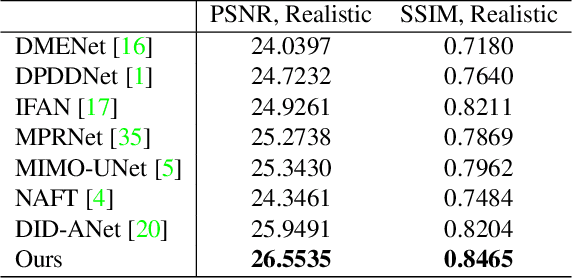
In this paper, we consider the problem in defocus image deblurring. Previous classical methods follow two-steps approaches, i.e., first defocus map estimation and then the non-blind deblurring. In the era of deep learning, some researchers have tried to address these two problems by CNN. However, the simple concatenation of defocus map, which represents the blur level, leads to suboptimal performance. Considering the spatial variant property of the defocus blur and the blur level indicated in the defocus map, we employ the defocus map as conditional guidance to adjust the features from the input blurring images instead of simple concatenation. Then we propose a simple but effective network with spatial modulation based on the defocus map. To achieve this, we design a network consisting of three sub-networks, including the defocus map estimation network, a condition network that encodes the defocus map into condition features, and the defocus deblurring network that performs spatially dynamic modulation based on the condition features. Moreover, the spatially dynamic modulation is based on an affine transform function to adjust the features from the input blurry images. Experimental results show that our method can achieve better quantitative and qualitative evaluation performance than the existing state-of-the-art methods on the commonly used public test datasets.
BATT: Backdoor Attack with Transformation-based Triggers
Nov 02, 2022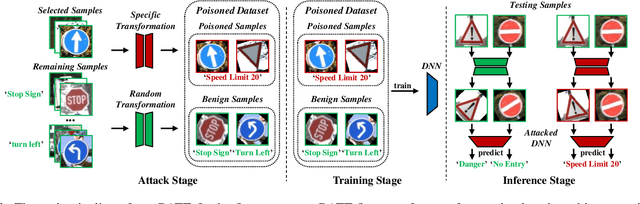

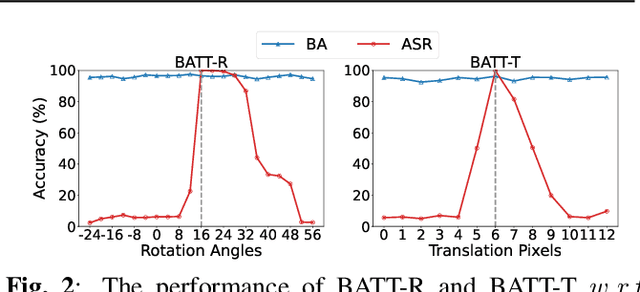
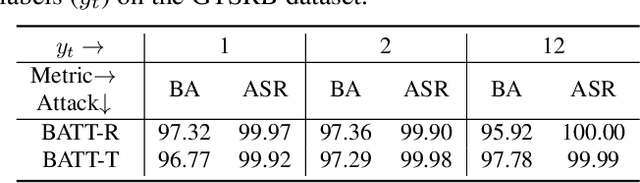
Deep neural networks (DNNs) are vulnerable to backdoor attacks. The backdoor adversaries intend to maliciously control the predictions of attacked DNNs by injecting hidden backdoors that can be activated by adversary-specified trigger patterns during the training process. One recent research revealed that most of the existing attacks failed in the real physical world since the trigger contained in the digitized test samples may be different from that of the one used for training. Accordingly, users can adopt spatial transformations as the image pre-processing to deactivate hidden backdoors. In this paper, we explore the previous findings from another side. We exploit classical spatial transformations (i.e. rotation and translation) with the specific parameter as trigger patterns to design a simple yet effective poisoning-based backdoor attack. For example, only images rotated to a particular angle can activate the embedded backdoor of attacked DNNs. Extensive experiments are conducted, verifying the effectiveness of our attack under both digital and physical settings and its resistance to existing backdoor defenses.
A comparison of uncertainty estimation approaches for DNN-based camera localization
Nov 02, 2022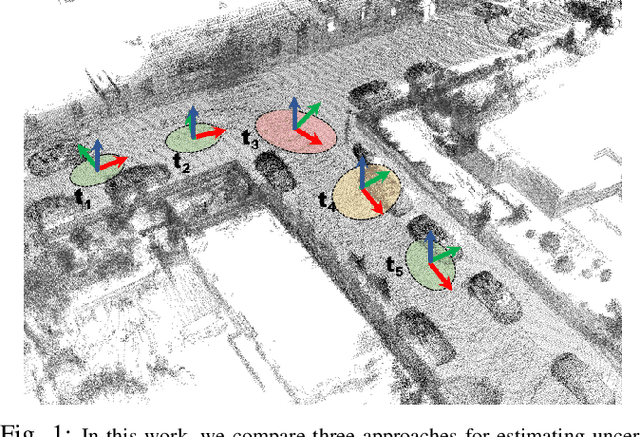
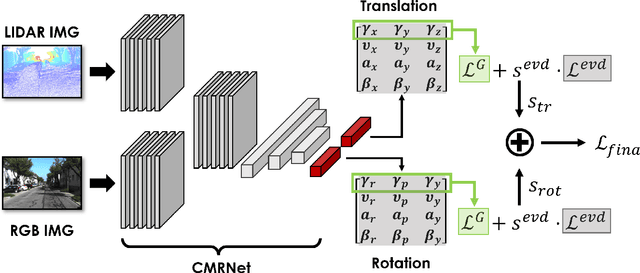
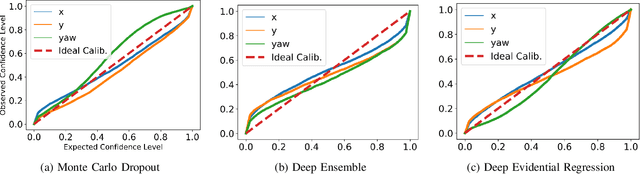
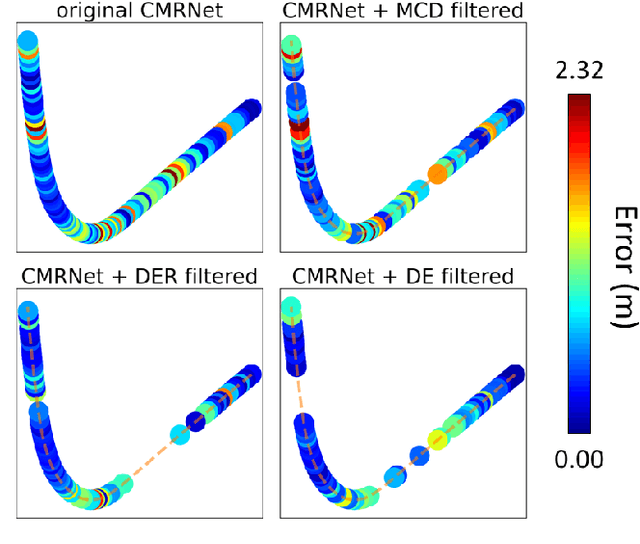
Camera localization, i.e., camera pose regression, represents a very important task in computer vision, since it has many practical applications, such as autonomous driving. A reliable estimation of the uncertainties in camera localization is also important, as it would allow to intercept localization failures, which would be dangerous. Even though the literature presents some uncertainty estimation methods, to the best of our knowledge their effectiveness has not been thoroughly examined. This work compares the performances of three consolidated epistemic uncertainty estimation methods: Monte Carlo Dropout (MCD), Deep Ensemble (DE), and Deep Evidential Regression (DER), in the specific context of camera localization. We exploited CMRNet, a DNN approach for multi-modal image to LiDAR map registration, by modifying its internal configuration to allow for an extensive experimental activity with the three methods on the KITTI dataset. Particularly significant has been the application of DER. We achieve accurate camera localization and a calibrated uncertainty, to the point that some method can be used for detecting localization failures.
Suppress with a Patch: Revisiting Universal Adversarial Patch Attacks against Object Detection
Sep 27, 2022
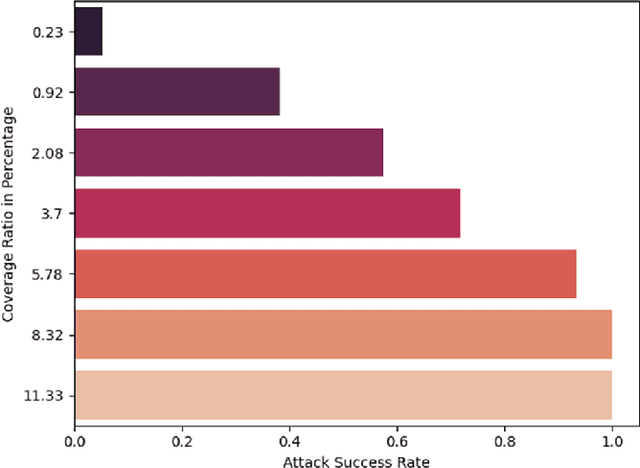

Adversarial patch-based attacks aim to fool a neural network with an intentionally generated noise, which is concentrated in a particular region of an input image. In this work, we perform an in-depth analysis of different patch generation parameters, including initialization, patch size, and especially positioning a patch in an image during training. We focus on the object vanishing attack and run experiments with YOLOv3 as a model under attack in a white-box setting and use images from the COCO dataset. Our experiments have shown, that inserting a patch inside a window of increasing size during training leads to a significant increase in attack strength compared to a fixed position. The best results were obtained when a patch was positioned randomly during training, while patch position additionally varied within a batch.