 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented Vision-Language Agents for Persistent and Semantically Consistent Object Captioning
Mar 25, 2026Vision-Language Models (VLMs) often yield inconsistent descriptions of the same object across viewpoints, hindering the ability of embodied agents to construct consistent semantic representations over time. Previous methods resolved inconsistencies using offline multi-view aggregation or multi-stage pipelines that decouple exploration, data association, and caption learning, with limited capacity to reason over previously observed objects. In this paper, we introduce a unified, memory-augmented Vision-Language agent that simultaneously handles data association, object captioning, and exploration policy within a single autoregressive framework. The model processes the current RGB observation, a top-down explored map, and an object-level episodic memory serialized into object-level tokens, ensuring persistent object identity and semantic consistency across extended sequences. To train the model in a self-supervised manner, we collect a dataset in photorealistic 3D environments using a disagreement-based policy and a pseudo-captioning model that enforces consistency across multi-view caption histories. Extensive evaluation on a manually annotated object-level test set, demonstrate improvements of up to +11.86% in standard captioning scores and +7.39% in caption self-similarity over baseline models, while enabling scalable performance through a compact scene representation. Code, model weights, and data are available at https://github.com/hsp-iit/epos-vlm
GRASPLAT: Enabling dexterous grasping through novel view synthesis
Oct 22, 2025Achieving dexterous robotic grasping with multi-fingered hands remains a significant challenge. While existing methods rely on complete 3D scans to predict grasp poses, these approaches face limitations due to the difficulty of acquiring high-quality 3D data in real-world scenarios. In this paper, we introduce GRASPLAT, a novel grasping framework that leverages consistent 3D information while being trained solely on RGB images. Our key insight is that by synthesizing physically plausible images of a hand grasping an object, we can regress the corresponding hand joints for a successful grasp. To achieve this, we utilize 3D Gaussian Splatting to generate high-fidelity novel views of real hand-object interactions, enabling end-to-end training with RGB data. Unlike prior methods, our approach incorporates a photometric loss that refines grasp predictions by minimizing discrepancies between rendered and real images. We conduct extensive experiments on both synthetic and real-world grasping datasets, demonstrating that GRASPLAT improves grasp success rates up to 36.9% over existing image-based methods. Project page: https://mbortolon97.github.io/grasplat/
SplatFill: 3D Scene Inpainting via Depth-Guided Gaussian Splatting
Sep 09, 20253D Gaussian Splatting (3DGS) has enabled the creation of highly realistic 3D scene representations from sets of multi-view images. However, inpainting missing regions, whether due to occlusion or scene editing, remains a challenging task, often leading to blurry details, artifacts, and inconsistent geometry. In this work, we introduce SplatFill, a novel depth-guided approach for 3DGS scene inpainting that achieves state-of-the-art perceptual quality and improved efficiency. Our method combines two key ideas: (1) joint depth-based and object-based supervision to ensure inpainted Gaussians are accurately placed in 3D space and aligned with surrounding geometry, and (2) we propose a consistency-aware refinement scheme that selectively identifies and corrects inconsistent regions without disrupting the rest of the scene. Evaluations on the SPIn-NeRF dataset demonstrate that SplatFill not only surpasses existing NeRF-based and 3DGS-based inpainting methods in visual fidelity but also reduces training time by 24.5%. Qualitative results show our method delivers sharper details, fewer artifacts, and greater coherence across challenging viewpoints.
Learning to Evaluate Autonomous Behaviour in Human-Robot Interaction
Jul 08, 2025


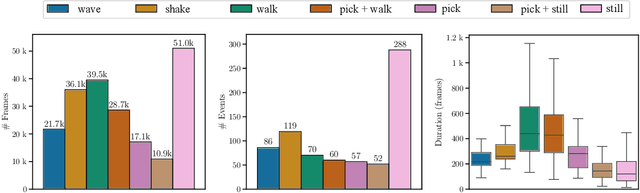
Evaluating and comparing the performance of autonomous Humanoid Robots is challenging, as success rate metrics are difficult to reproduce and fail to capture the complexity of robot movement trajectories, critical in Human-Robot Interaction and Collaboration (HRIC). To address these challenges, we propose a general evaluation framework that measures the quality of Imitation Learning (IL) methods by focusing on trajectory performance. We devise the Neural Meta Evaluator (NeME), a deep learning model trained to classify actions from robot joint trajectories. NeME serves as a meta-evaluator to compare the performance of robot control policies, enabling policy evaluation without requiring human involvement in the loop. We validate our framework on ergoCub, a humanoid robot, using teleoperation data and comparing IL methods tailored to the available platform. The experimental results indicate that our method is more aligned with the success rate obtained on the robot than baselines, offering a reproducible, systematic, and insightful means for comparing the performance of multimodal imitation learning approaches in complex HRI tasks.
ReassembleNet: Learnable Keypoints and Diffusion for 2D Fresco Reconstruction
May 29, 2025



The task of reassembly is a significant challenge across multiple domains, including archaeology, genomics, and molecular docking, requiring the precise placement and orientation of elements to reconstruct an original structure. In this work, we address key limitations in state-of-the-art Deep Learning methods for reassembly, namely i) scalability; ii) multimodality; and iii) real-world applicability: beyond square or simple geometric shapes, realistic and complex erosion, or other real-world problems. We propose ReassembleNet, a method that reduces complexity by representing each input piece as a set of contour keypoints and learning to select the most informative ones by Graph Neural Networks pooling inspired techniques. ReassembleNet effectively lowers computational complexity while enabling the integration of features from multiple modalities, including both geometric and texture data. Further enhanced through pretraining on a semi-synthetic dataset. We then apply diffusion-based pose estimation to recover the original structure. We improve on prior methods by 55% and 86% for RMSE Rotation and Translation, respectively.
Directed Semi-Simplicial Learning with Applications to Brain Activity Decoding
May 23, 2025



Graph Neural Networks (GNNs) excel at learning from pairwise interactions but often overlook multi-way and hierarchical relationships. Topological Deep Learning (TDL) addresses this limitation by leveraging combinatorial topological spaces. However, existing TDL models are restricted to undirected settings and fail to capture the higher-order directed patterns prevalent in many complex systems, e.g., brain networks, where such interactions are both abundant and functionally significant. To fill this gap, we introduce Semi-Simplicial Neural Networks (SSNs), a principled class of TDL models that operate on semi-simplicial sets -- combinatorial structures that encode directed higher-order motifs and their directional relationships. To enhance scalability, we propose Routing-SSNs, which dynamically select the most informative relations in a learnable manner. We prove that SSNs are strictly more expressive than standard graph and TDL models. We then introduce a new principled framework for brain dynamics representation learning, grounded in the ability of SSNs to provably recover topological descriptors shown to successfully characterize brain activity. Empirically, SSNs achieve state-of-the-art performance on brain dynamics classification tasks, outperforming the second-best model by up to 27%, and message passing GNNs by up to 50% in accuracy. Our results highlight the potential of principled topological models for learning from structured brain data, establishing a unique real-world case study for TDL. We also test SSNs on standard node classification and edge regression tasks, showing competitive performance. We will make the code and data publicly available.
Measuring Uncertainty in Shape Completion to Improve Grasp Quality
Apr 22, 2025



Shape completion networks have been used recently in real-world robotic experiments to complete the missing/hidden information in environments where objects are only observed in one or few instances where self-occlusions are bound to occur. Nowadays, most approaches rely on deep neural networks that handle rich 3D point cloud data that lead to more precise and realistic object geometries. However, these models still suffer from inaccuracies due to its nondeterministic/stochastic inferences which could lead to poor performance in grasping scenarios where these errors compound to unsuccessful grasps. We present an approach to calculate the uncertainty of a 3D shape completion model during inference of single view point clouds of an object on a table top. In addition, we propose an update to grasp pose algorithms quality score by introducing the uncertainty of the completed point cloud present in the grasp candidates. To test our full pipeline we perform real world grasping with a 7dof robotic arm with a 2 finger gripper on a large set of household objects and compare against previous approaches that do not measure uncertainty. Our approach ranks the grasp quality better, leading to higher grasp success rate for the rank 5 grasp candidates compared to state of the art.
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Apr 11, 2025



We present a self-supervised method to improve an agent's abilities in describing arbitrary objects while actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism. First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set. Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
Reasoning in visual navigation of end-to-end trained agents: a dynamical systems approach
Mar 12, 2025Progress in Embodied AI has made it possible for end-to-end-trained agents to navigate in photo-realistic environments with high-level reasoning and zero-shot or language-conditioned behavior, but benchmarks are still dominated by simulation. In this work, we focus on the fine-grained behavior of fast-moving real robots and present a large-scale experimental study involving \numepisodes{} navigation episodes in a real environment with a physical robot, where we analyze the type of reasoning emerging from end-to-end training. In particular, we study the presence of realistic dynamics which the agent learned for open-loop forecasting, and their interplay with sensing. We analyze the way the agent uses latent memory to hold elements of the scene structure and information gathered during exploration. We probe the planning capabilities of the agent, and find in its memory evidence for somewhat precise plans over a limited horizon. Furthermore, we show in a post-hoc analysis that the value function learned by the agent relates to long-term planning. Put together, our experiments paint a new picture on how using tools from computer vision and sequential decision making have led to new capabilities in robotics and control. An interactive tool is available at europe.naverlabs.com/research/publications/reasoning-in-visual-navigation-of-end-to-end-trained-agents.
A Mutual Information Perspective on Multiple Latent Variable Generative Models for Positive View Generation
Jan 23, 2025



In image generation, Multiple Latent Variable Generative Models (MLVGMs) employ multiple latent variables to gradually shape the final images, from global characteristics to finer and local details (e.g., StyleGAN, NVAE), emerging as powerful tools for diverse applications. Yet their generative dynamics and latent variable utilization remain only empirically observed. In this work, we propose a novel framework to systematically quantify the impact of each latent variable in MLVGMs, using Mutual Information (MI) as a guiding metric. Our analysis reveals underutilized variables and can guide the use of MLVGMs in downstream applications. With this foundation, we introduce a method for generating synthetic data for Self-Supervised Contrastive Representation Learning (SSCRL). By leveraging the hierarchical and disentangled variables of MLVGMs, and guided by the previous analysis, we apply tailored latent perturbations to produce diverse views for SSCRL, without relying on real data altogether. Additionally, we introduce a Continuous Sampling (CS) strategy, where the generator dynamically creates new samples during SSCRL training, greatly increasing data variability. Our comprehensive experiments demonstrate the effectiveness of these contributions, showing that MLVGMs' generated views compete on par with or even surpass views generated from real data. This work establishes a principled approach to understanding and exploiting MLVGMs, advancing both generative modeling and self-supervised learning.