 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Swiss Army Knife for Image-to-Image Translation: Multi-Task Diffusion Models
Apr 06, 2022
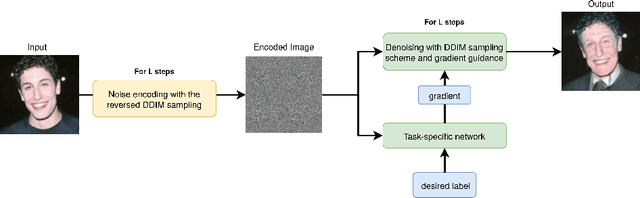



Recently, diffusion models were applied to a wide range of image analysis tasks. We build on a method for image-to-image translation using denoising diffusion implicit models and include a regression problem and a segmentation problem for guiding the image generation to the desired output. The main advantage of our approach is that the guidance during the denoising process is done by an external gradient. Consequently, the diffusion model does not need to be retrained for the different tasks on the same dataset. We apply our method to simulate the aging process on facial photos using a regression task, as well as on a brain magnetic resonance (MR) imaging dataset for the simulation of brain tumor growth. Furthermore, we use a segmentation model to inpaint tumors at the desired location in healthy slices of brain MR images. We achieve convincing results for all problems.
Explaining Deepfake Detection by Analysing Image Matching
Jul 20, 2022
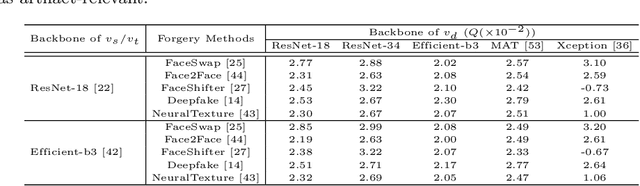
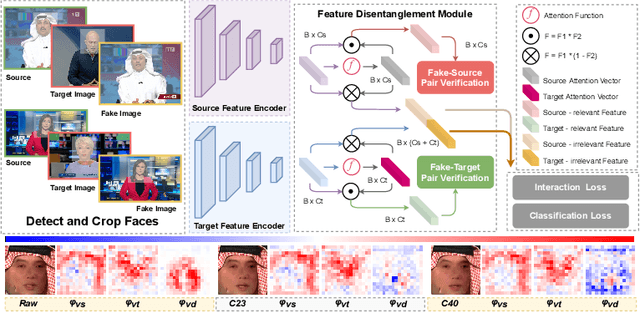
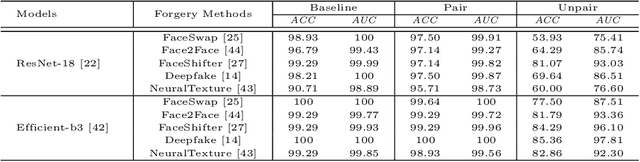
This paper aims to interpret how deepfake detection models learn artifact features of images when just supervised by binary labels. To this end, three hypotheses from the perspective of image matching are proposed as follows. 1. Deepfake detection models indicate real/fake images based on visual concepts that are neither source-relevant nor target-relevant, that is, considering such visual concepts as artifact-relevant. 2. Besides the supervision of binary labels, deepfake detection models implicitly learn artifact-relevant visual concepts through the FST-Matching (i.e. the matching fake, source, target images) in the training set. 3. Implicitly learned artifact visual concepts through the FST-Matching in the raw training set are vulnerable to video compression. In experiments, the above hypotheses are verified among various DNNs. Furthermore, based on this understanding, we propose the FST-Matching Deepfake Detection Model to boost the performance of forgery detection on compressed videos. Experiment results show that our method achieves great performance, especially on highly-compressed (e.g. c40) videos.
X$^2$-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
Nov 22, 2022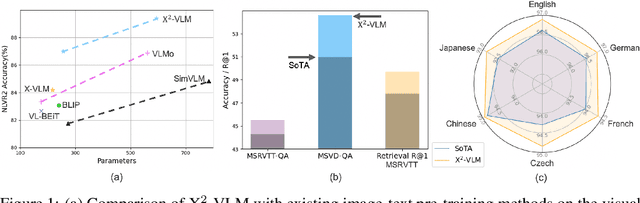
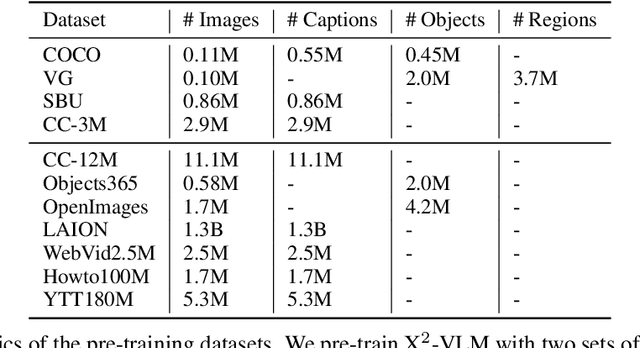
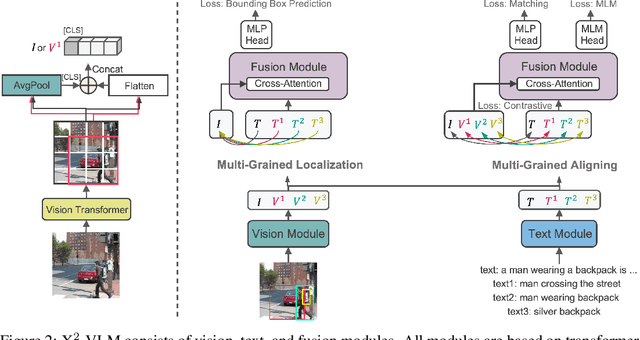

Vision language pre-training aims to learn alignments between vision and language from a large amount of data. We proposed multi-grained vision language pre-training, a unified approach which can learn vision language alignments in multiple granularity. This paper advances the proposed method by unifying image and video encoding in one model and scaling up the model with large-scale data. We present X$^2$-VLM, a pre-trained VLM with a modular architecture for both image-text tasks and video-text tasks. Experiment results show that X$^2$-VLM performs the best on base and large scale for both image-text and video-text tasks, making a good trade-off between performance and model scale. Moreover, we show that the modular design of X$^2$-VLM results in high transferability for X$^2$-VLM to be utilized in any language or domain. For example, by simply replacing the text encoder with XLM-R, X$^2$-VLM outperforms state-of-the-art multilingual multi-modal pre-trained models without any multilingual pre-training. The code and pre-trained models will be available at github.com/zengyan-97/X2-VLM.
PCCT: Progressive Class-Center Triplet Loss for Imbalanced Medical Image Classification
Jul 11, 2022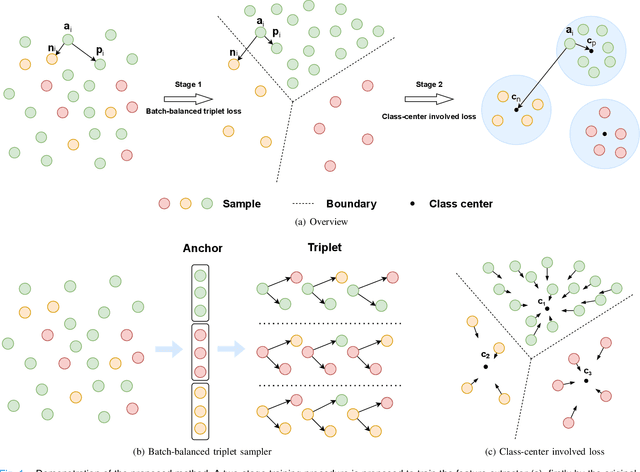
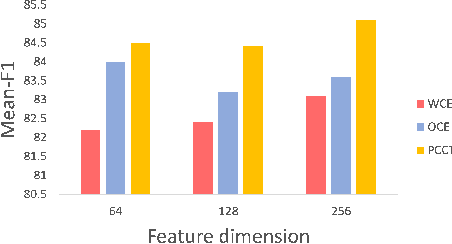

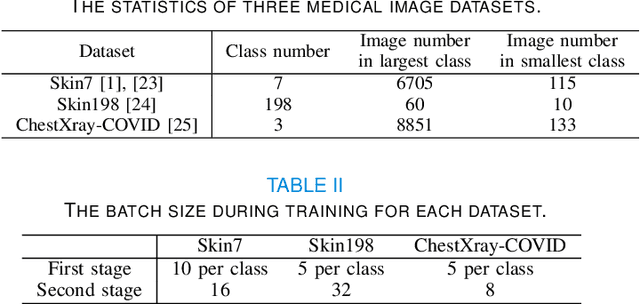
Imbalanced training data is a significant challenge for medical image classification. In this study, we propose a novel Progressive Class-Center Triplet (PCCT) framework to alleviate the class imbalance issue particularly for diagnosis of rare diseases, mainly by carefully designing the triplet sampling strategy and the triplet loss formation. Specifically, the PCCT framework includes two successive stages. In the first stage, PCCT trains the diagnosis system via a class-balanced triplet loss to coarsely separate distributions of different classes. In the second stage, the PCCT framework further improves the diagnosis system via a class-center involved triplet loss to cause a more compact distribution for each class. For the class-balanced triplet loss, triplets are sampled equally for each class at each training iteration, thus alleviating the imbalanced data issue. For the class-center involved triplet loss, the positive and negative samples in each triplet are replaced by their corresponding class centers, which enforces data representations of the same class closer to the class center. Furthermore, the class-center involved triplet loss is extended to the pair-wise ranking loss and the quadruplet loss, which demonstrates the generalization of the proposed framework. Extensive experiments support that the PCCT framework works effectively for medical image classification with imbalanced training images. On two skin image datasets and one chest X-ray dataset, the proposed approach respectively obtains the mean F1 score 86.2, 65.2, and 90.66 over all classes and 81.4, 63.87, and 81.92 for rare classes, achieving state-of-the-art performance and outperforming the widely used methods for the class imbalance issue.
Elevation Estimation-Driven Building 3D Reconstruction from Single-View Remote Sensing Imagery
Jan 11, 2023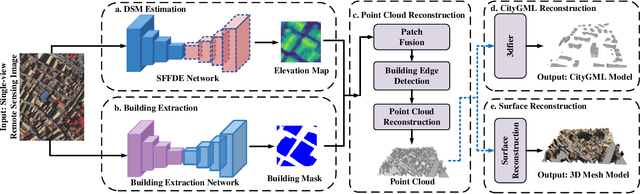


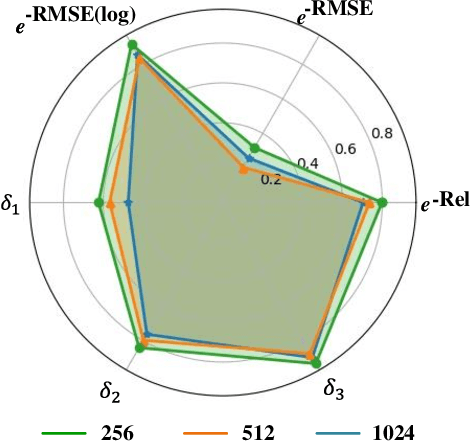
Building 3D reconstruction from remote sensing images has a wide range of applications in smart cities, photogrammetry and other fields. Methods for automatic 3D urban building modeling typically employ multi-view images as input to algorithms to recover point clouds and 3D models of buildings. However, such models rely heavily on multi-view images of buildings, which are time-intensive and limit the applicability and practicality of the models. To solve these issues, we focus on designing an efficient DSM estimation-driven reconstruction framework (Building3D), which aims to reconstruct 3D building models from the input single-view remote sensing image. First, we propose a Semantic Flow Field-guided DSM Estimation (SFFDE) network, which utilizes the proposed concept of elevation semantic flow to achieve the registration of local and global features. Specifically, in order to make the network semantics globally aware, we propose an Elevation Semantic Globalization (ESG) module to realize the semantic globalization of instances. Further, in order to alleviate the semantic span of global features and original local features, we propose a Local-to-Global Elevation Semantic Registration (L2G-ESR) module based on elevation semantic flow. Our Building3D is rooted in the SFFDE network for building elevation prediction, synchronized with a building extraction network for building masks, and then sequentially performs point cloud reconstruction, surface reconstruction (or CityGML model reconstruction). On this basis, our Building3D can optionally generate CityGML models or surface mesh models of the buildings. Extensive experiments on ISPRS Vaihingen and DFC2019 datasets on the DSM estimation task show that our SFFDE significantly improves upon state-of-the-arts. Furthermore, our Building3D achieves impressive results in the 3D point cloud and 3D model reconstruction process.
Self-Supervised Consistent Quantization for Fully Unsupervised Image Retrieval
Jun 20, 2022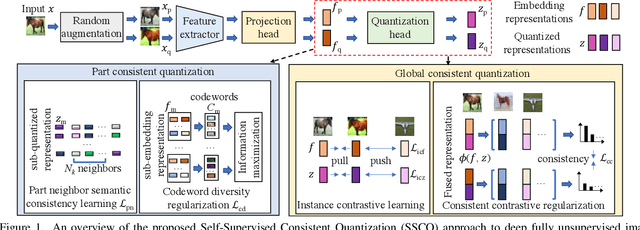
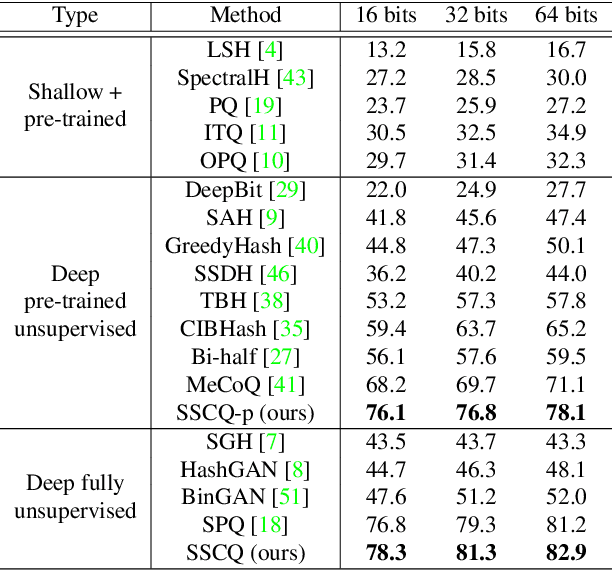
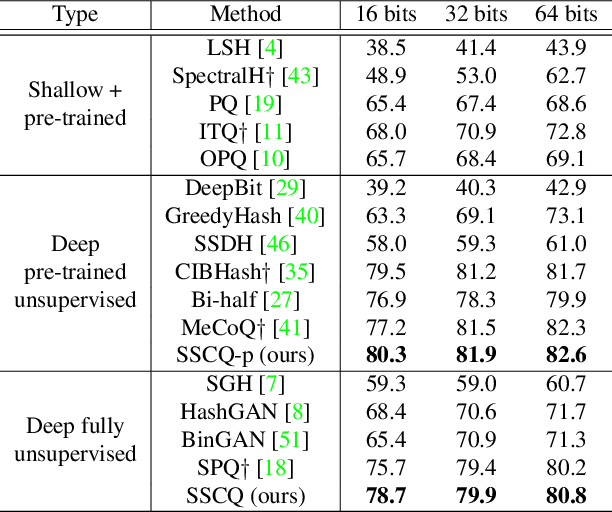
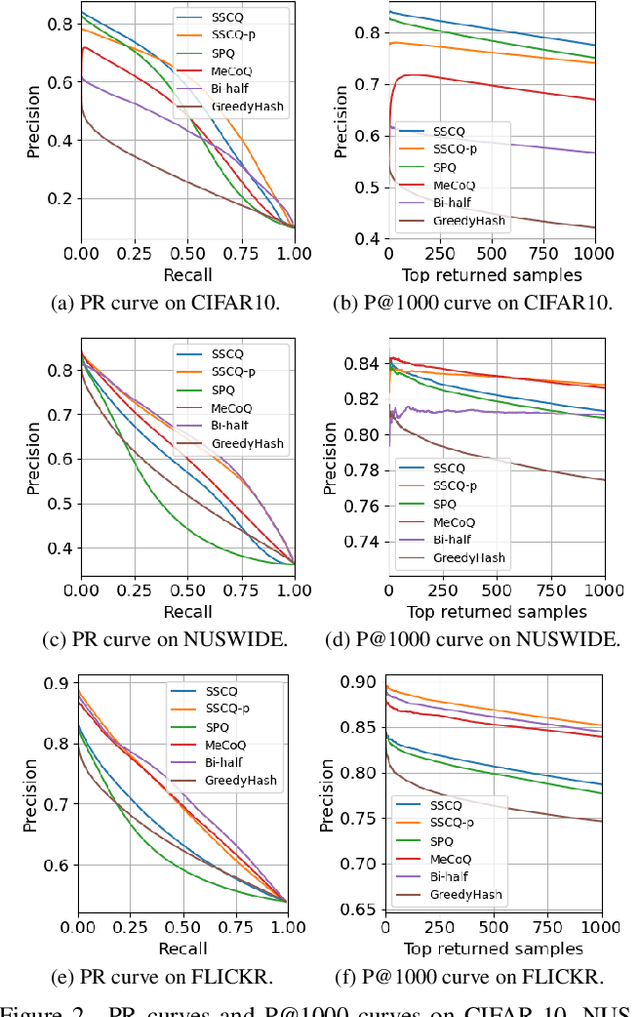
Unsupervised image retrieval aims to learn an efficient retrieval system without expensive data annotations, but most existing methods rely heavily on handcrafted feature descriptors or pre-trained feature extractors. To minimize human supervision, recent advance proposes deep fully unsupervised image retrieval aiming at training a deep model from scratch to jointly optimize visual features and quantization codes. However, existing approach mainly focuses on instance contrastive learning without considering underlying semantic structure information, resulting in sub-optimal performance. In this work, we propose a novel self-supervised consistent quantization approach to deep fully unsupervised image retrieval, which consists of part consistent quantization and global consistent quantization. In part consistent quantization, we devise part neighbor semantic consistency learning with codeword diversity regularization. This allows to discover underlying neighbor structure information of sub-quantized representations as self-supervision. In global consistent quantization, we employ contrastive learning for both embedding and quantized representations and fuses these representations for consistent contrastive regularization between instances. This can make up for the loss of useful representation information during quantization and regularize consistency between instances. With a unified learning objective of part and global consistent quantization, our approach exploits richer self-supervision cues to facilitate model learning. Extensive experiments on three benchmark datasets show the superiority of our approach over the state-of-the-art methods.
MPT: Mesh Pre-Training with Transformers for Human Pose and Mesh Reconstruction
Nov 24, 2022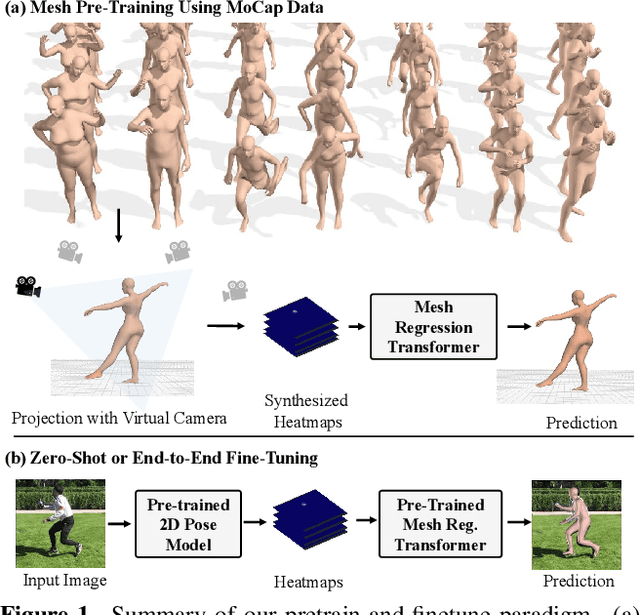
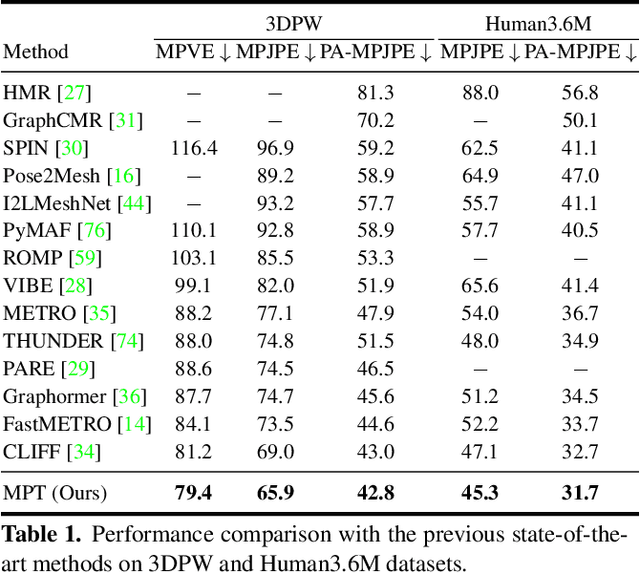
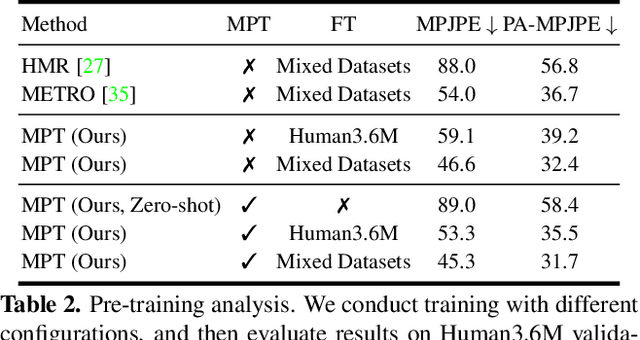
We present Mesh Pre-Training (MPT), a new pre-training framework that leverages 3D mesh data such as MoCap data for human pose and mesh reconstruction from a single image. Existing work in 3D pose and mesh reconstruction typically requires image-mesh pairs as the training data, but the acquisition of 2D-to-3D annotations is difficult. In this paper, we explore how to leverage 3D mesh data such as MoCap data, that does not have RGB images, for pre-training. The key idea is that even though 3D mesh data cannot be used for end-to-end training due to a lack of the corresponding RGB images, it can be used to pre-train the mesh regression transformer subnetwork. We observe that such pre-training not only improves the accuracy of mesh reconstruction from a single image, but also enables zero-shot capability. We conduct mesh pre-training using 2 million meshes. Experimental results show that MPT advances the state-of-the-art results on Human3.6M and 3DPW datasets. We also show that MPT enables transformer models to have zero-shot capability of human mesh reconstruction from real images. In addition, we demonstrate the generalizability of MPT to 3D hand reconstruction, achieving state-of-the-art results on FreiHAND dataset.
High-resolution Solar Image Reconstruction Based on Non-rigid Alignment
Jul 01, 2022
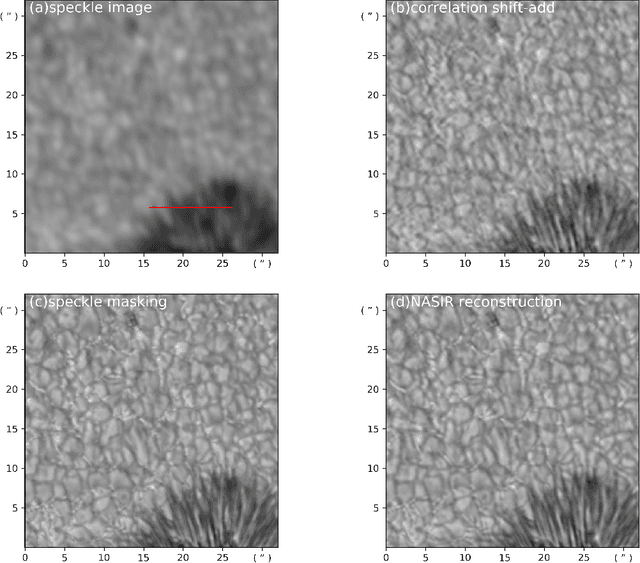
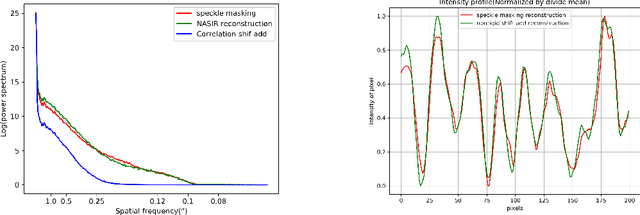
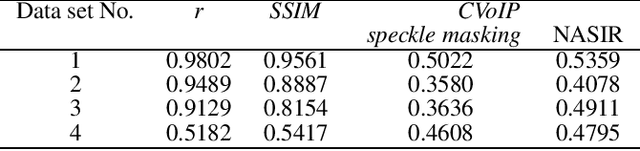
Suppressing the interference of atmospheric turbulence and obtaining observation data with a high spatial resolution is an issue to be solved urgently for ground observations. One way to solve this problem is to perform a statistical reconstruction of short-exposure speckle images. Combining the rapidity of Shift-Add and the accuracy of speckle masking, this paper proposes a novel reconstruction algorithm-NASIR (Non-rigid Alignment based Solar Image Reconstruction). NASIR reconstructs the phase of the object image at each frequency by building a computational model between geometric distortion and intensity distribution and reconstructs the modulus of the object image on the aligned speckle images by speckle interferometry. We analyzed the performance of NASIR by using the correlation coefficient, power spectrum, and coefficient of variation of intensity profile (CVoIP) in processing data obtained by the NVST (1m New Vacuum Solar Telescope). The reconstruction experiments and analysis results show that the quality of images reconstructed by NASIR is close to speckle masking when the seeing is good, while NASIR has excellent robustness when the seeing condition becomes worse. Furthermore, NASIR reconstructs the entire field of view in parallel in one go, without phase recursion and block-by-block reconstruction, so its computation time is less than half that of speckle masking. Therefore, we consider NASIR is a robust and high-quality fast reconstruction method that can serve as an effective tool for data filtering and quick look.
Saccade Mechanisms for Image Classification, Object Detection and Tracking
Jun 10, 2022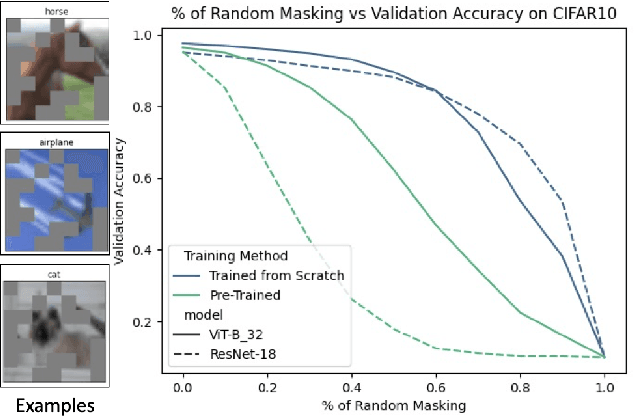
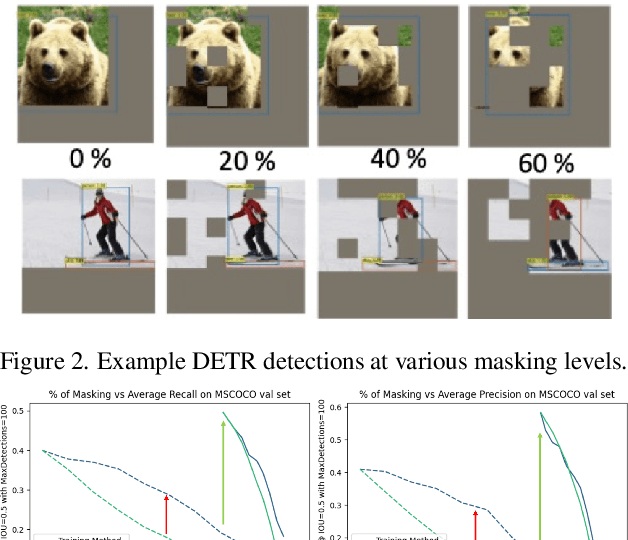

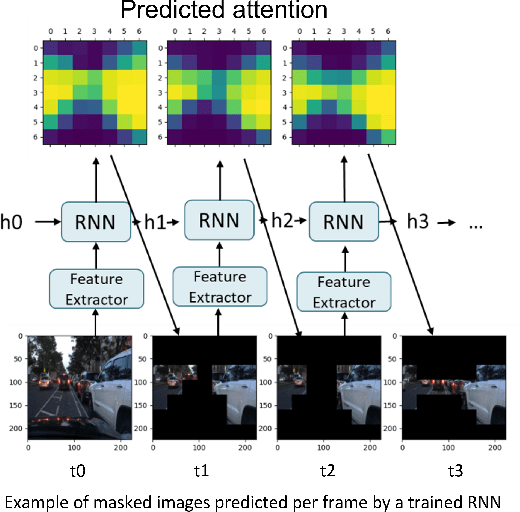
We examine how the saccade mechanism from biological vision can be used to make deep neural networks more efficient for classification and object detection problems. Our proposed approach is based on the ideas of attention-driven visual processing and saccades, miniature eye movements influenced by attention. We conduct experiments by analyzing: i) the robustness of different deep neural network (DNN) feature extractors to partially-sensed images for image classification and object detection, and ii) the utility of saccades in masking image patches for image classification and object tracking. Experiments with convolutional nets (ResNet-18) and transformer-based models (ViT, DETR, TransTrack) are conducted on several datasets (CIFAR-10, DAVSOD, MSCOCO, and MOT17). Our experiments show intelligent data reduction via learning to mimic human saccades when used in conjunction with state-of-the-art DNNs for classification, detection, and tracking tasks. We observed minimal drop in performance for the classification and detection tasks while only using about 30\% of the original sensor data. We discuss how the saccade mechanism can inform hardware design via ``in-pixel'' processing.
Masked autoencoders are effective solution to transformer data-hungry
Dec 13, 2022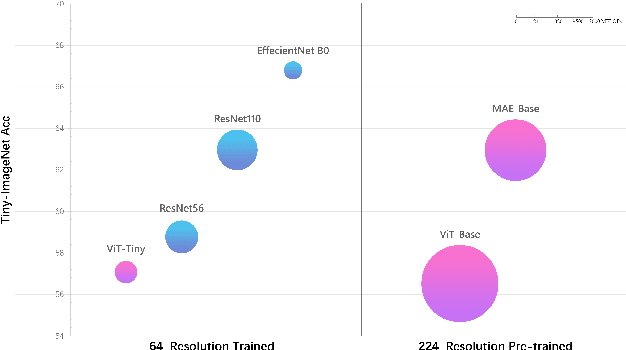
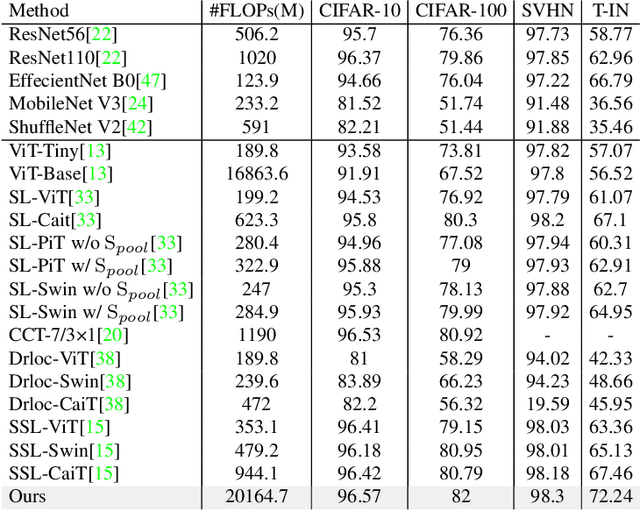
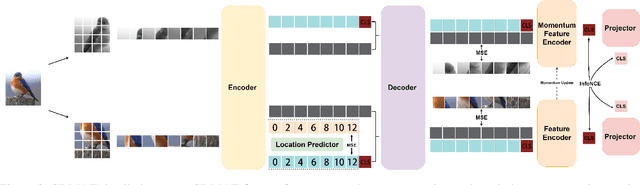
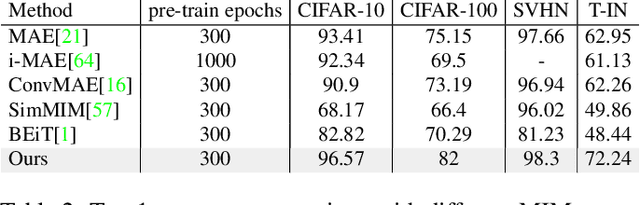
Vision Transformers (ViTs) outperforms convolutional neural networks (CNNs) in several vision tasks with its global modeling capabilities. However, ViT lacks the inductive bias inherent to convolution making it require a large amount of data for training. This results in ViT not performing as well as CNNs on small datasets like medicine and science. We experimentally found that masked autoencoders (MAE) can make the transformer focus more on the image itself, thus alleviating the data-hungry issue of ViT to some extent. Yet the current MAE model is too complex resulting in over-fitting problems on small datasets. This leads to a gap between MAEs trained on small datasets and advanced CNNs models still. Therefore, we investigated how to reduce the decoder complexity in MAE and found a more suitable architectural configuration for it with small datasets. Besides, we additionally designed a location prediction task and a contrastive learning task to introduce localization and invariance characteristics for MAE. Our contrastive learning task not only enables the model to learn high-level visual information but also allows the training of MAE's class token. This is something that most MAE improvement efforts do not consider. Extensive experiments have shown that our method shows state-of-the-art performance on standard small datasets as well as medical datasets with few samples compared to the current popular masked image modeling (MIM) and vision transformers for small datasets.The code and models are available at https://github.com/Talented-Q/SDMAE.