 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridThinker: Efficient Chain-of-Thought Reasoning via Compressed Memory and Transient Thought Steps
Jun 02, 2026Extended chain-of-thought (CoT) traces improve LLM reasoning but incur substantial computational and memory costs. While existing CoT compression methods mitigate this by condensing thought steps into compact representations via memory tokens and retaining only these representations at inference time, the loss of fine-grained information makes subsequent steps more error-prone. To alleviate this, we propose \textbf{HybridThinker}, where in addition to preserved these representations, thought steps are also temporarily retained to provide fine-grained details. However, we observe that naively keeping thought steps accessible to subsequent steps \emph{during training} lets the model bypass memory tokens by retrieving information directly from these steps, leaving the model's ability to compress and retrieve information through memory tokens insufficiently trained. We therefore introduce a hybrid training scheme, in which only some thought steps are directly accessible through attention to subsequent steps, while the other thought steps are masked, forcing the model to use memory tokens for compression and retrieval. Across 4 reasoning benchmarks, HybridThinker matches the uncompressed baseline, advancing the state of the art in CoT compression by 5.8 points on average accuracy with similar inference time. Ablation studies confirm that both temporary thought-step retention and the hybrid training scheme contribute to these gains.
Cross-modal Identity Mapping: Minimizing Information Loss in Modality Conversion via Reinforcement Learning
Mar 02, 2026Large Vision-Language Models (LVLMs) often omit or misrepresent critical visual content in generated image captions. Minimizing such information loss will force LVLMs to focus on image details to generate precise descriptions. However, measuring information loss during modality conversion is inherently challenging due to the modal gap between visual content and text output. In this paper, we argue that the quality of an image caption is positively correlated with the similarity between images retrieved via text search using that caption. Based on this insight, we further propose Cross-modal Identity Mapping (CIM), a reinforcement learning framework that enhances image captioning without requiring additional annotations. Specifically, the method quantitatively evaluates the information loss from two perspectives: Gallery Representation Consistency and Query-gallery Image Relevance. Supervised under these metrics, LVLM minimizes information loss and aims to achieve identity mapping from images to captions. The experimental results demonstrate the superior performance of our method in image captioning, even when compared with Supervised Fine-Tuning. Particularly, on the COCO-LN500 benchmark, CIM achieves a 20% improvement in relation reasoning on Qwen2.5-VL-7B.The code will be released when the paper is accepted.
Forensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models
Mar 19, 2025



Recently, the rapid development of AIGC has significantly boosted the diversities of fake media spread in the Internet, posing unprecedented threats to social security, politics, law, and etc. To detect the ever-increasingly diverse malicious fake media in the new era of AIGC, recent studies have proposed to exploit Large Vision Language Models (LVLMs) to design robust forgery detectors due to their impressive performance on a wide range of multimodal tasks. However, it still lacks a comprehensive benchmark designed to comprehensively assess LVLMs' discerning capabilities on forgery media. To fill this gap, we present Forensics-Bench, a new forgery detection evaluation benchmark suite to assess LVLMs across massive forgery detection tasks, requiring comprehensive recognition, location and reasoning capabilities on diverse forgeries. Forensics-Bench comprises 63,292 meticulously curated multi-choice visual questions, covering 112 unique forgery detection types from 5 perspectives: forgery semantics, forgery modalities, forgery tasks, forgery types and forgery models. We conduct thorough evaluations on 22 open-sourced LVLMs and 3 proprietary models GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet, highlighting the significant challenges of comprehensive forgery detection posed by Forensics-Bench. We anticipate that Forensics-Bench will motivate the community to advance the frontier of LVLMs, striving for all-around forgery detectors in the era of AIGC. The deliverables will be updated at https://Forensics-Bench.github.io/.
3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
Aug 25, 2024



Data augmentation plays a crucial role in deep learning, enhancing the generalization and robustness of learning-based models. Standard approaches involve simple transformations like rotations and flips for generating extra data. However, these augmentations are limited by their initial dataset, lacking high-level diversity. Recently, large models such as language models and diffusion models have shown exceptional capabilities in perception and content generation. In this work, we propose a new paradigm to automatically generate 3D labeled training data by harnessing the power of pretrained large foundation models. For each target semantic class, we first generate 2D images of a single object in various structure and appearance via diffusion models and chatGPT generated text prompts. Beyond texture augmentation, we propose a method to automatically alter the shape of objects within 2D images. Subsequently, we transform these augmented images into 3D objects and construct virtual scenes by random composition. This method can automatically produce a substantial amount of 3D scene data without the need of real data, providing significant benefits in addressing few-shot learning challenges and mitigating long-tailed class imbalances. By providing a flexible augmentation approach, our work contributes to enhancing 3D data diversity and advancing model capabilities in scene understanding tasks.
Towards RGB-NIR Cross-modality Image Registration and Beyond
May 30, 2024



This paper focuses on the area of RGB(visible)-NIR(near-infrared) cross-modality image registration, which is crucial for many downstream vision tasks to fully leverage the complementary information present in visible and infrared images. In this field, researchers face two primary challenges - the absence of a correctly-annotated benchmark with viewpoint variations for evaluating RGB-NIR cross-modality registration methods and the problem of inconsistent local features caused by the appearance discrepancy between RGB-NIR cross-modality images. To address these challenges, we first present the RGB-NIR Image Registration (RGB-NIR-IRegis) benchmark, which, for the first time, enables fair and comprehensive evaluations for the task of RGB-NIR cross-modality image registration. Evaluations of previous methods highlight the significant challenges posed by our RGB-NIR-IRegis benchmark, especially on RGB-NIR image pairs with viewpoint variations. To analyze the causes of the unsatisfying performance, we then design several metrics to reveal the toxic impact of inconsistent local features between visible and infrared images on the model performance. This further motivates us to develop a baseline method named Semantic Guidance Transformer (SGFormer), which utilizes high-level semantic guidance to mitigate the negative impact of local inconsistent features. Despite the simplicity of our motivation, extensive experimental results show the effectiveness of our method.
Diagnosing the Compositional Knowledge of Vision Language Models from a Game-Theoretic View
May 27, 2024



Compositional reasoning capabilities are usually considered as fundamental skills to characterize human perception. Recent studies show that current Vision Language Models (VLMs) surprisingly lack sufficient knowledge with respect to such capabilities. To this end, we propose to thoroughly diagnose the composition representations encoded by VLMs, systematically revealing the potential cause for this weakness. Specifically, we propose evaluation methods from a novel game-theoretic view to assess the vulnerability of VLMs on different aspects of compositional understanding, e.g., relations and attributes. Extensive experimental results demonstrate and validate several insights to understand the incapabilities of VLMs on compositional reasoning, which provide useful and reliable guidance for future studies. The deliverables will be updated at https://vlms-compositionality-gametheory.github.io/.
Leveraging Large-Scale Pretrained Vision Foundation Models for Label-Efficient 3D Point Cloud Segmentation
Nov 06, 2023Recently, large-scale pre-trained models such as Segment-Anything Model (SAM) and Contrastive Language-Image Pre-training (CLIP) have demonstrated remarkable success and revolutionized the field of computer vision. These foundation vision models effectively capture knowledge from a large-scale broad data with their vast model parameters, enabling them to perform zero-shot segmentation on previously unseen data without additional training. While they showcase competence in 2D tasks, their potential for enhancing 3D scene understanding remains relatively unexplored. To this end, we present a novel framework that adapts various foundational models for the 3D point cloud segmentation task. Our approach involves making initial predictions of 2D semantic masks using different large vision models. We then project these mask predictions from various frames of RGB-D video sequences into 3D space. To generate robust 3D semantic pseudo labels, we introduce a semantic label fusion strategy that effectively combines all the results via voting. We examine diverse scenarios, like zero-shot learning and limited guidance from sparse 2D point labels, to assess the pros and cons of different vision foundation models. Our approach is experimented on ScanNet dataset for 3D indoor scenes, and the results demonstrate the effectiveness of adopting general 2D foundation models on solving 3D point cloud segmentation tasks.
Weakly Supervised 3D Instance Segmentation without Instance-level Annotations
Aug 03, 2023



3D semantic scene understanding tasks have achieved great success with the emergence of deep learning, but often require a huge amount of manually annotated training data. To alleviate the annotation cost, we propose the first weakly-supervised 3D instance segmentation method that only requires categorical semantic labels as supervision, and we do not need instance-level labels. The required semantic annotations can be either dense or extreme sparse (e.g. 0.02% of total points). Even without having any instance-related ground-truth, we design an approach to break point clouds into raw fragments and find the most confident samples for learning instance centroids. Furthermore, we construct a recomposed dataset using pseudo instances, which is used to learn our defined multilevel shape-aware objectness signal. An asymmetrical object inference algorithm is followed to process core points and boundary points with different strategies, and generate high-quality pseudo instance labels to guide iterative training. Experiments demonstrate that our method can achieve comparable results with recent fully supervised methods. By generating pseudo instance labels from categorical semantic labels, our designed approach can also assist existing methods for learning 3D instance segmentation at reduced annotation cost.
Towards A Robust Deepfake Detector:Common Artifact Deepfake Detection Model
Oct 26, 2022



Existing deepfake detection methods perform poorly on face forgeries generated by unseen face manipulation algorithms. The generalization ability of previous methods is mainly improved by modeling hand-crafted artifact features. Such properties, on the other hand, impede their further improvement. In this paper, we propose a novel deepfake detection method named Common Artifact Deepfake Detection Model, which aims to learn common artifact features in different face manipulation algorithms. To this end, we find that the main obstacle to learning common artifact features is that models are easily misled by the identity representation feature. We call this phenomenon Implicit Identity Leakage (IIL). Extensive experimental results demonstrate that, by learning the binary classifiers with the guidance of the Artifact Detection Module, our method effectively reduces the influence of IIL and outperforms the state-of-the-art by a large margin, proving that hand-crafted artifact feature detectors are not indispensable when tackling deepfake problems.
RWSeg: Cross-graph Competing Random Walks for Weakly Supervised 3D Instance Segmentation
Aug 11, 2022

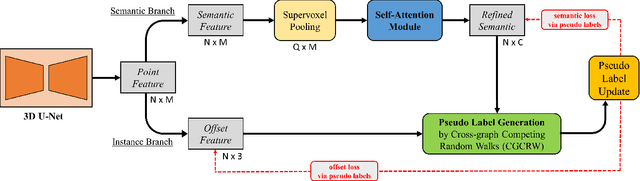

Instance segmentation on 3D point clouds has been attracting increasing attention due to its wide applications, especially in scene understanding areas. However, most existing methods require training data to be fully annotated. Manually preparing ground-truth labels at point-level is very cumbersome and labor-intensive. To address this issue, we propose a novel weakly supervised method RWSeg that only requires labeling one object with one point. With these sparse weak labels, we introduce a unified framework with two branches to propagate semantic and instance information respectively to unknown regions, using self-attention and random walk. Furthermore, we propose a Cross-graph Competing Random Walks (CGCRW) algorithm which encourages competition among different instance graphs to resolve ambiguities in closely placed objects and improve the performance on instance assignment. RWSeg can generate qualitative instance-level pseudo labels. Experimental results on ScanNet-v2 and S3DIS datasets show that our approach achieves comparable performance with fully-supervised methods and outperforms previous weakly-supervised methods by large margins. This is the first work that bridges the gap between weak and full supervision in the area.