 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-Occ: Satellite-Assisted 3D Occupancy Prediction in Real World
Mar 20, 2025



Existing vision-based 3D occupancy prediction methods are inherently limited in accuracy due to their exclusive reliance on street-view imagery, neglecting the potential benefits of incorporating satellite views. We propose SA-Occ, the first Satellite-Assisted 3D occupancy prediction model, which leverages GPS & IMU to integrate historical yet readily available satellite imagery into real-time applications, effectively mitigating limitations of ego-vehicle perceptions, involving occlusions and degraded performance in distant regions. To address the core challenges of cross-view perception, we propose: 1) Dynamic-Decoupling Fusion, which resolves inconsistencies in dynamic regions caused by the temporal asynchrony between satellite and street views; 2) 3D-Proj Guidance, a module that enhances 3D feature extraction from inherently 2D satellite imagery; and 3) Uniform Sampling Alignment, which aligns the sampling density between street and satellite views. Evaluated on Occ3D-nuScenes, SA-Occ achieves state-of-the-art performance, especially among single-frame methods, with a 39.05% mIoU (a 6.97% improvement), while incurring only 6.93 ms of additional latency per frame. Our code and newly curated dataset are available at https://github.com/chenchen235/SA-Occ.
SemStereo: Semantic-Constrained Stereo Matching Network for Remote Sensing
Dec 17, 2024



Semantic segmentation and 3D reconstruction are two fundamental tasks in remote sensing, typically treated as separate or loosely coupled tasks. Despite attempts to integrate them into a unified network, the constraints between the two heterogeneous tasks are not explicitly modeled, since the pioneering studies either utilize a loosely coupled parallel structure or engage in only implicit interactions, failing to capture the inherent connections. In this work, we explore the connections between the two tasks and propose a new network that imposes semantic constraints on the stereo matching task, both implicitly and explicitly. Implicitly, we transform the traditional parallel structure to a new cascade structure termed Semantic-Guided Cascade structure, where the deep features enriched with semantic information are utilized for the computation of initial disparity maps, enhancing semantic guidance. Explicitly, we propose a Semantic Selective Refinement (SSR) module and a Left-Right Semantic Consistency (LRSC) module. The SSR refines the initial disparity map under the guidance of the semantic map. The LRSC ensures semantic consistency between two views via reducing the semantic divergence after transforming the semantic map from one view to the other using the disparity map. Experiments on the US3D and WHU datasets demonstrate that our method achieves state-of-the-art performance for both semantic segmentation and stereo matching.
Twin Deformable Point Convolutions for Point Cloud Semantic Segmentation in Remote Sensing Scenes
May 30, 2024



Thanks to the application of deep learning technology in point cloud processing of the remote sensing field, point cloud segmentation has become a research hotspot in recent years, which can be applied to real-world 3D, smart cities, and other fields. Although existing solutions have made unprecedented progress, they ignore the inherent characteristics of point clouds in remote sensing fields that are strictly arranged according to latitude, longitude, and altitude, which brings great convenience to the segmentation of point clouds in remote sensing fields. To consider this property cleverly, we propose novel convolution operators, termed Twin Deformable point Convolutions (TDConvs), which aim to achieve adaptive feature learning by learning deformable sampling points in the latitude-longitude plane and altitude direction, respectively. First, to model the characteristics of the latitude-longitude plane, we propose a Cylinder-wise Deformable point Convolution (CyDConv) operator, which generates a two-dimensional cylinder map by constructing a cylinder-like grid in the latitude-longitude direction. Furthermore, to better integrate the features of the latitude-longitude plane and the spatial geometric features, we perform a multi-scale fusion of the extracted latitude-longitude features and spatial geometric features, and realize it through the aggregation of adjacent point features of different scales. In addition, a Sphere-wise Deformable point Convolution (SpDConv) operator is introduced to adaptively offset the sampling points in three-dimensional space by constructing a sphere grid structure, aiming at modeling the characteristics in the altitude direction. Experiments on existing popular benchmarks conclude that our TDConvs achieve the best segmentation performance, surpassing the existing state-of-the-art methods.
SDL-MVS: View Space and Depth Deformable Learning Paradigm for Multi-View Stereo Reconstruction in Remote Sensing
May 27, 2024



Research on multi-view stereo based on remote sensing images has promoted the development of large-scale urban 3D reconstruction. However, remote sensing multi-view image data suffers from the problems of occlusion and uneven brightness between views during acquisition, which leads to the problem of blurred details in depth estimation. To solve the above problem, we re-examine the deformable learning method in the Multi-View Stereo task and propose a novel paradigm based on view Space and Depth deformable Learning (SDL-MVS), aiming to learn deformable interactions of features in different view spaces and deformably model the depth ranges and intervals to enable high accurate depth estimation. Specifically, to solve the problem of view noise caused by occlusion and uneven brightness, we propose a Progressive Space deformable Sampling (PSS) mechanism, which performs deformable learning of sampling points in the 3D frustum space and the 2D image space in a progressive manner to embed source features to the reference feature adaptively. To further optimize the depth, we introduce Depth Hypothesis deformable Discretization (DHD), which achieves precise positioning of the depth prior by adaptively adjusting the depth range hypothesis and performing deformable discretization of the depth interval hypothesis. Finally, our SDL-MVS achieves explicit modeling of occlusion and uneven brightness faced in multi-view stereo through the deformable learning paradigm of view space and depth, achieving accurate multi-view depth estimation. Extensive experiments on LuoJia-MVS and WHU datasets show that our SDL-MVS reaches state-of-the-art performance. It is worth noting that our SDL-MVS achieves an MAE error of 0.086, an accuracy of 98.9% for <0.6m, and 98.9% for <3-interval on the LuoJia-MVS dataset under the premise of three views as input.
RingMo-lite: A Remote Sensing Multi-task Lightweight Network with CNN-Transformer Hybrid Framework
Sep 16, 2023



In recent years, remote sensing (RS) vision foundation models such as RingMo have emerged and achieved excellent performance in various downstream tasks. However, the high demand for computing resources limits the application of these models on edge devices. It is necessary to design a more lightweight foundation model to support on-orbit RS image interpretation. Existing methods face challenges in achieving lightweight solutions while retaining generalization in RS image interpretation. This is due to the complex high and low-frequency spectral components in RS images, which make traditional single CNN or Vision Transformer methods unsuitable for the task. Therefore, this paper proposes RingMo-lite, an RS multi-task lightweight network with a CNN-Transformer hybrid framework, which effectively exploits the frequency-domain properties of RS to optimize the interpretation process. It is combined by the Transformer module as a low-pass filter to extract global features of RS images through a dual-branch structure, and the CNN module as a stacked high-pass filter to extract fine-grained details effectively. Furthermore, in the pretraining stage, the designed frequency-domain masked image modeling (FD-MIM) combines each image patch's high-frequency and low-frequency characteristics, effectively capturing the latent feature representation in RS data. As shown in Fig. 1, compared with RingMo, the proposed RingMo-lite reduces the parameters over 60% in various RS image interpretation tasks, the average accuracy drops by less than 2% in most of the scenes and achieves SOTA performance compared to models of the similar size. In addition, our work will be integrated into the MindSpore computing platform in the near future.
DCP-Net: A Distributed Collaborative Perception Network for Remote Sensing Semantic Segmentation
Sep 05, 2023



Onboard intelligent processing is widely applied in emergency tasks in the field of remote sensing. However, it is predominantly confined to an individual platform with a limited observation range as well as susceptibility to interference, resulting in limited accuracy. Considering the current state of multi-platform collaborative observation, this article innovatively presents a distributed collaborative perception network called DCP-Net. Firstly, the proposed DCP-Net helps members to enhance perception performance by integrating features from other platforms. Secondly, a self-mutual information match module is proposed to identify collaboration opportunities and select suitable partners, prioritizing critical collaborative features and reducing redundant transmission cost. Thirdly, a related feature fusion module is designed to address the misalignment between local and collaborative features, improving the quality of fused features for the downstream task. We conduct extensive experiments and visualization analyses using three semantic segmentation datasets, including Potsdam, iSAID and DFC23. The results demonstrate that DCP-Net outperforms the existing methods comprehensively, improving mIoU by 2.61%~16.89% at the highest collaboration efficiency, which promotes the performance to a state-of-the-art level.
LIGHT: Joint Individual Building Extraction and Height Estimation from Satellite Images through a Unified Multitask Learning Network
Apr 03, 2023



Building extraction and height estimation are two important basic tasks in remote sensing image interpretation, which are widely used in urban planning, real-world 3D construction, and other fields. Most of the existing research regards the two tasks as independent studies. Therefore the height information cannot be fully used to improve the accuracy of building extraction and vice versa. In this work, we combine the individuaL buIlding extraction and heiGHt estimation through a unified multiTask learning network (LIGHT) for the first time, which simultaneously outputs a height map, bounding boxes, and a segmentation mask map of buildings. Specifically, LIGHT consists of an instance segmentation branch and a height estimation branch. In particular, so as to effectively unify multi-scale feature branches and alleviate feature spans between branches, we propose a Gated Cross Task Interaction (GCTI) module that can efficiently perform feature interaction between branches. Experiments on the DFC2023 dataset show that our LIGHT can achieve superior performance, and our GCTI module with ResNet101 as the backbone can significantly improve the performance of multitask learning by 2.8% AP50 and 6.5% delta1, respectively.
SiamTHN: Siamese Target Highlight Network for Visual Tracking
Mar 22, 2023



Siamese network based trackers develop rapidly in the field of visual object tracking in recent years. The majority of siamese network based trackers now in use treat each channel in the feature maps generated by the backbone network equally, making the similarity response map sensitive to background influence and hence challenging to focus on the target region. Additionally, there are no structural links between the classification and regression branches in these trackers, and the two branches are optimized separately during training. Therefore, there is a misalignment between the classification and regression branches, which results in less accurate tracking results. In this paper, a Target Highlight Module is proposed to help the generated similarity response maps to be more focused on the target region. To reduce the misalignment and produce more precise tracking results, we propose a corrective loss to train the model. The two branches of the model are jointly tuned with the use of corrective loss to produce more reliable prediction results. Experiments on 5 challenging benchmark datasets reveal that the method outperforms current models in terms of performance, and runs at 38 fps, proving its effectiveness and efficiency.
Elevation Estimation-Driven Building 3D Reconstruction from Single-View Remote Sensing Imagery
Jan 11, 2023



Building 3D reconstruction from remote sensing images has a wide range of applications in smart cities, photogrammetry and other fields. Methods for automatic 3D urban building modeling typically employ multi-view images as input to algorithms to recover point clouds and 3D models of buildings. However, such models rely heavily on multi-view images of buildings, which are time-intensive and limit the applicability and practicality of the models. To solve these issues, we focus on designing an efficient DSM estimation-driven reconstruction framework (Building3D), which aims to reconstruct 3D building models from the input single-view remote sensing image. First, we propose a Semantic Flow Field-guided DSM Estimation (SFFDE) network, which utilizes the proposed concept of elevation semantic flow to achieve the registration of local and global features. Specifically, in order to make the network semantics globally aware, we propose an Elevation Semantic Globalization (ESG) module to realize the semantic globalization of instances. Further, in order to alleviate the semantic span of global features and original local features, we propose a Local-to-Global Elevation Semantic Registration (L2G-ESR) module based on elevation semantic flow. Our Building3D is rooted in the SFFDE network for building elevation prediction, synchronized with a building extraction network for building masks, and then sequentially performs point cloud reconstruction, surface reconstruction (or CityGML model reconstruction). On this basis, our Building3D can optionally generate CityGML models or surface mesh models of the buildings. Extensive experiments on ISPRS Vaihingen and DFC2019 datasets on the DSM estimation task show that our SFFDE significantly improves upon state-of-the-arts. Furthermore, our Building3D achieves impressive results in the 3D point cloud and 3D model reconstruction process.
Beyond single receptive field: A receptive field fusion-and-stratification network for airborne laser scanning point cloud classification
Jul 21, 2022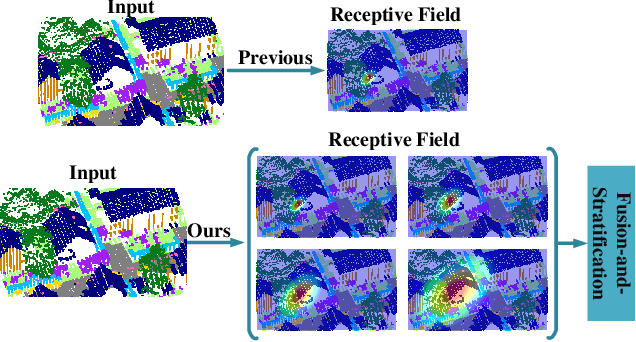
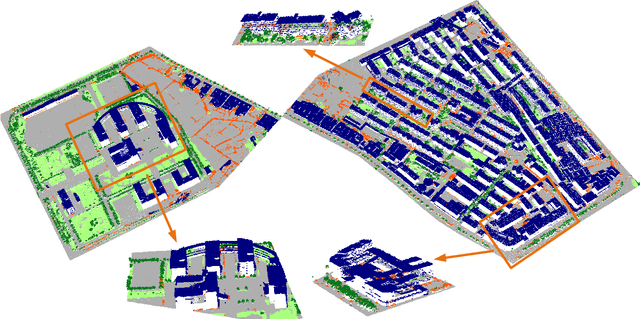

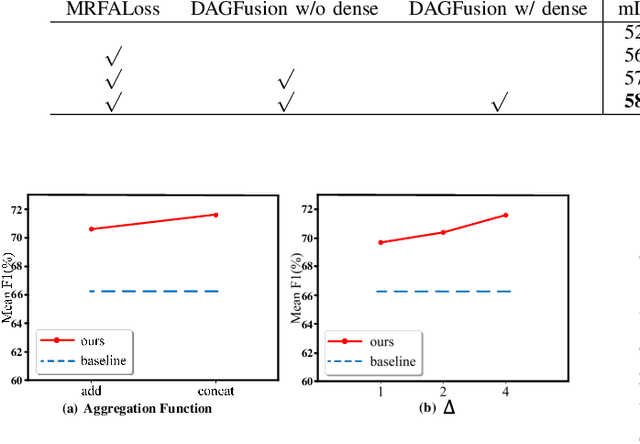
The classification of airborne laser scanning (ALS) point clouds is a critical task of remote sensing and photogrammetry fields. Although recent deep learning-based methods have achieved satisfactory performance, they have ignored the unicity of the receptive field, which makes the ALS point cloud classification remain challenging for the distinguishment of the areas with complex structures and extreme scale variations. In this article, for the objective of configuring multi-receptive field features, we propose a novel receptive field fusion-and-stratification network (RFFS-Net). With a novel dilated graph convolution (DGConv) and its extension annular dilated convolution (ADConv) as basic building blocks, the receptive field fusion process is implemented with the dilated and annular graph fusion (DAGFusion) module, which obtains multi-receptive field feature representation through capturing dilated and annular graphs with various receptive regions. The stratification of the receptive fields with point sets of different resolutions as the calculation bases is performed with Multi-level Decoders nested in RFFS-Net and driven by the multi-level receptive field aggregation loss (MRFALoss) to drive the network to learn in the direction of the supervision labels with different resolutions. With receptive field fusion-and-stratification, RFFS-Net is more adaptable to the classification of regions with complex structures and extreme scale variations in large-scale ALS point clouds. Evaluated on the ISPRS Vaihingen 3D dataset, our RFFS-Net significantly outperforms the baseline approach by 5.3% on mF1 and 5.4% on mIoU, accomplishing an overall accuracy of 82.1%, an mF1 of 71.6%, and an mIoU of 58.2%. Furthermore, experiments on the LASDU dataset and the 2019 IEEE-GRSS Data Fusion Contest dataset show that RFFS-Net achieves a new state-of-the-art classification performance.