 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Harmonization with Region-wise Contrastive Learning
May 27, 2022
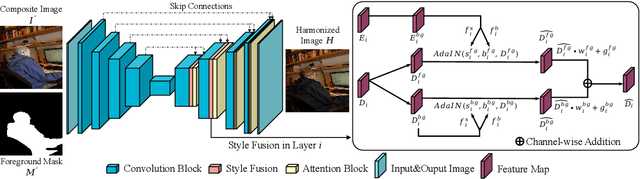
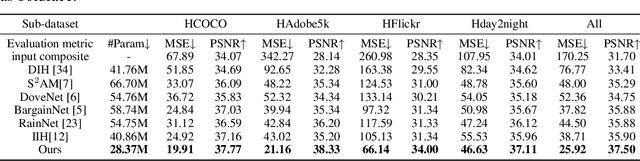
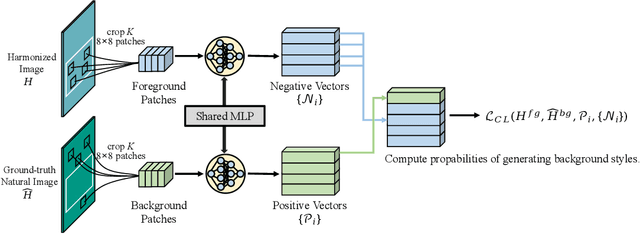
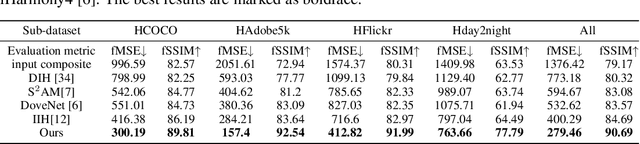
Image harmonization task aims at harmonizing different composite foreground regions according to specific background image. Previous methods would rather focus on improving the reconstruction ability of the generator by some internal enhancements such as attention, adaptive normalization and light adjustment, $etc.$. However, they pay less attention to discriminating the foreground and background appearance features within a restricted generator, which becomes a new challenge in image harmonization task. In this paper, we propose a novel image harmonization framework with external style fusion and region-wise contrastive learning scheme. For the external style fusion, we leverage the external background appearance from the encoder as the style reference to generate harmonized foreground in the decoder. This approach enhances the harmonization ability of the decoder by external background guidance. Moreover, for the contrastive learning scheme, we design a region-wise contrastive loss function for image harmonization task. Specifically, we first introduce a straight-forward samples generation method that selects negative samples from the output harmonized foreground region and selects positive samples from the ground-truth background region. Our method attempts to bring together corresponding positive and negative samples by maximizing the mutual information between the foreground and background styles, which desirably makes our harmonization network more robust to discriminate the foreground and background style features when harmonizing composite images. Extensive experiments on the benchmark datasets show that our method can achieve a clear improvement in harmonization quality and demonstrate the good generalization capability in real-scenario applications.
SolarDK: A high-resolution urban solar panel image classification and localization dataset
Dec 02, 2022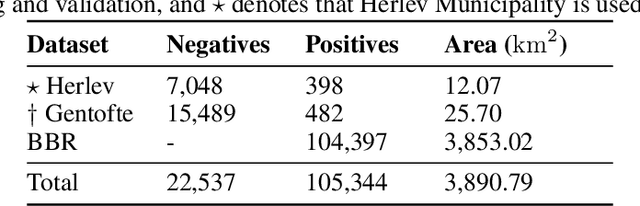

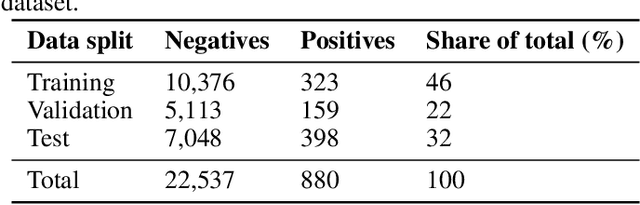

The body of research on classification of solar panel arrays from aerial imagery is increasing, yet there are still not many public benchmark datasets. This paper introduces two novel benchmark datasets for classifying and localizing solar panel arrays in Denmark: A human annotated dataset for classification and segmentation, as well as a classification dataset acquired using self-reported data from the Danish national building registry. We explore the performance of prior works on the new benchmark dataset, and present results after fine-tuning models using a similar approach as recent works. Furthermore, we train models of newer architectures and provide benchmark baselines to our datasets in several scenarios. We believe the release of these datasets may improve future research in both local and global geospatial domains for identifying and mapping of solar panel arrays from aerial imagery. The data is accessible at https://osf.io/aj539/.
Magic ELF: Image Deraining Meets Association Learning and Transformer
Jul 21, 2022
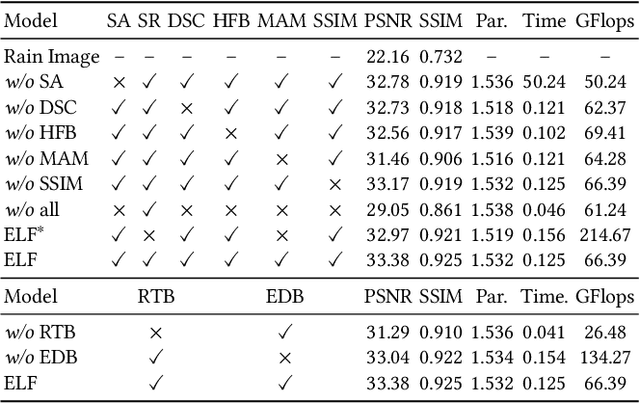
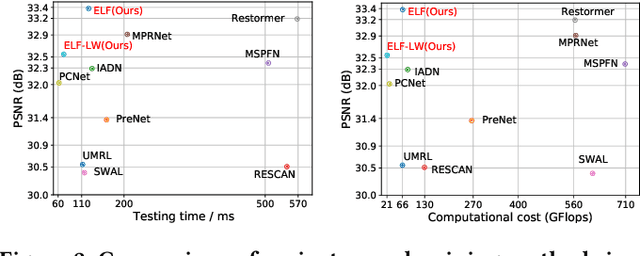
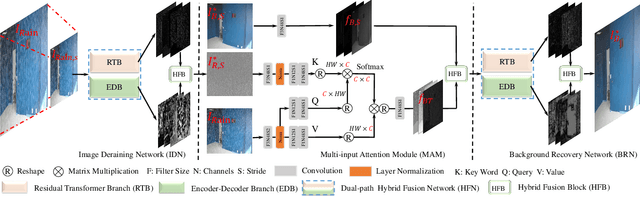
Convolutional neural network (CNN) and Transformer have achieved great success in multimedia applications. However, little effort has been made to effectively and efficiently harmonize these two architectures to satisfy image deraining. This paper aims to unify these two architectures to take advantage of their learning merits for image deraining. In particular, the local connectivity and translation equivariance of CNN and the global aggregation ability of self-attention (SA) in Transformer are fully exploited for specific local context and global structure representations. Based on the observation that rain distribution reveals the degradation location and degree, we introduce degradation prior to help background recovery and accordingly present the association refinement deraining scheme. A novel multi-input attention module (MAM) is proposed to associate rain perturbation removal and background recovery. Moreover, we equip our model with effective depth-wise separable convolutions to learn the specific feature representations and trade off computational complexity. Extensive experiments show that our proposed method (dubbed as ELF) outperforms the state-of-the-art approach (MPRNet) by 0.25 dB on average, but only accounts for 11.7\% and 42.1\% of its computational cost and parameters. The source code is available at https://github.com/kuijiang94/Magic-ELF.
Domino Denoise: An Accurate Blind Zero-Shot Denoiser using Domino Tilings
Dec 05, 2022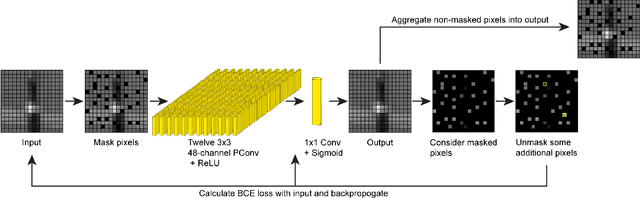
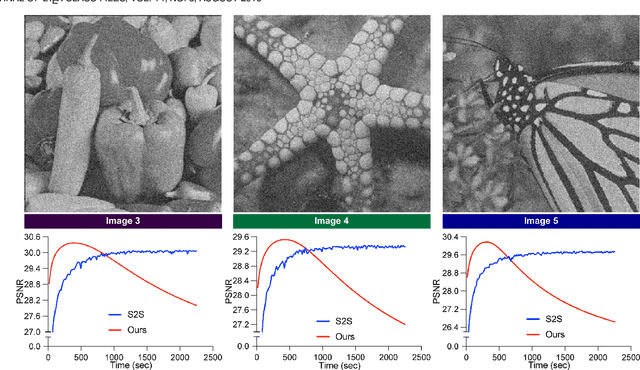
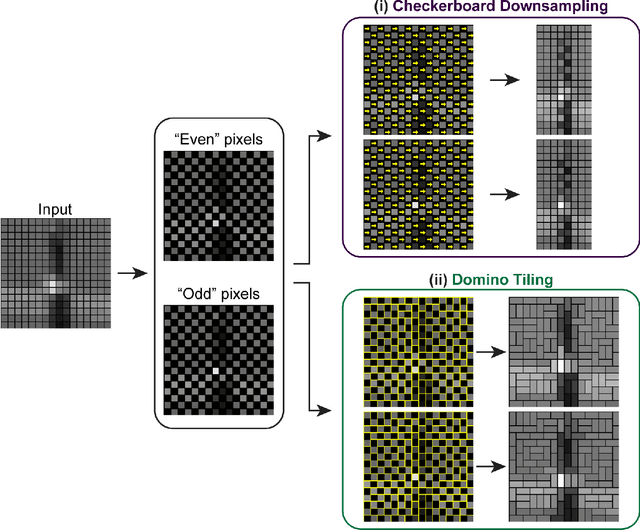

Because noise can interfere with downstream analysis, image denoising has come to occupy an important place in the image processing toolbox. The most accurate state-of-the-art denoisers typically train on a representative dataset. But gathering a training set is not always feasible, so interest has grown in blind zero-shot denoisers that train only on the image they are denoising. The most accurate blind-zero shot methods are blind-spot networks, which mask pixels and attempt to infer them from their surroundings. Other methods exist where all neurons participate in forward inference, however they are not as accurate and are susceptible to overfitting. Here we present a hybrid approach. We first introduce a semi blind-spot network where the network can see only a small percentage of inputs during gradient update. We then resolve overfitting by introducing a validation scheme where we split pixels into two groups and fill in pixel gaps using domino tilings. Our method achieves an average PSNR increase of $0.28$ and a three fold increase in speed over the current gold standard blind zero-shot denoiser Self2Self on synthetic Gaussian noise. We demonstrate the broader applicability of Pixel Domino Tiling by inserting it into a preciously published method.
A Unified Object Counting Network with Object Occupation Prior
Dec 29, 2022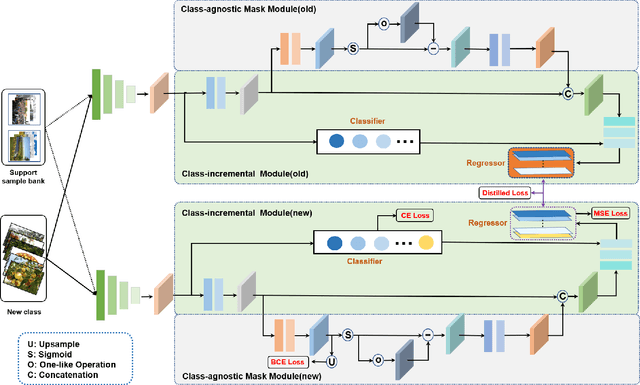

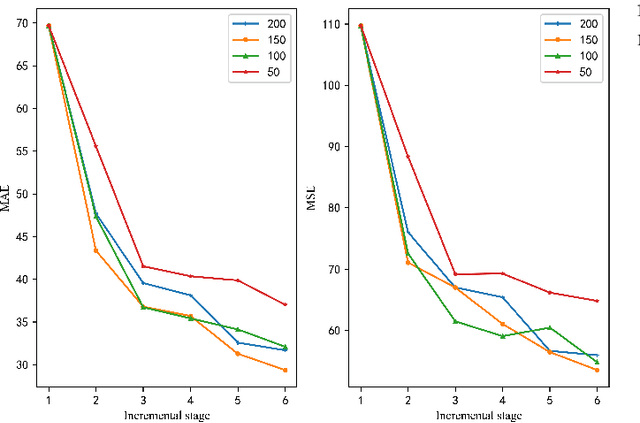
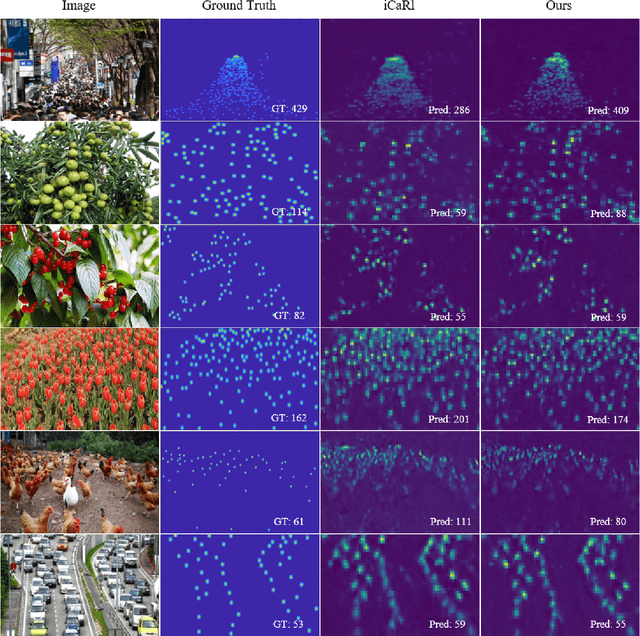
The counting task, which plays a fundamental rule in numerous applications (e.g., crowd counting, traffic statistics), aims to predict the number of objects with various densities. Existing object counting tasks are designed for a single object class. However, it is inevitable to encounter newly coming data with new classes in our real world. We name this scenario as \textit{evolving object counting}. In this paper, we build the first evolving object counting dataset and propose a unified object counting network as the first attempt to address this task. The proposed model consists of two key components: a class-agnostic mask module and a class-increment module. The class-agnostic mask module learns generic object occupation prior via predicting a class-agnostic binary mask (e.g., 1 denotes there exists an object at the considering position in an image and 0 otherwise). The class-increment module is used to handle new coming classes and provides discriminative class guidance for density map prediction. The combined outputs of class-agnostic mask module and image feature extractor are used to predict the final density map. When new classes come, we first add new neural nodes into the last regression and classification layers of this module. Then, instead of retraining the model from scratch, we utilize knowledge distilling to help the model remember what have already learned about previous object classes. We also employ a support sample bank to store a small number of typical training samples of each class, which are used to prevent the model from forgetting key information of old data. With this design, our model can efficiently and effectively adapt to new coming classes while keeping good performance on already seen data without large-scale retraining. Extensive experiments on the collected dataset demonstrate the favorable performance.
Quality Assessment of Image Super-Resolution: Balancing Deterministic and Statistical Fidelity
Jul 15, 2022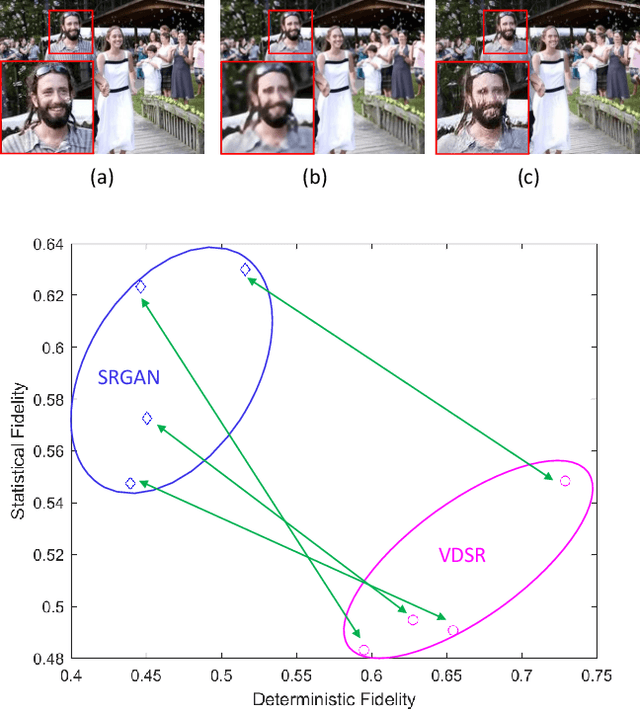
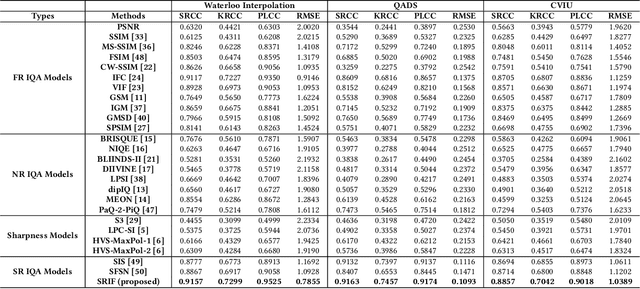
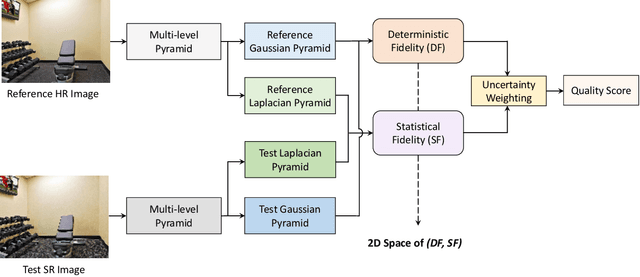

There has been a growing interest in developing image super-resolution (SR) algorithms that convert low-resolution (LR) to higher resolution images, but automatically evaluating the visual quality of super-resolved images remains a challenging problem. Here we look at the problem of SR image quality assessment (SR IQA) in a two-dimensional (2D) space of deterministic fidelity (DF) versus statistical fidelity (SF). This allows us to better understand the advantages and disadvantages of existing SR algorithms, which produce images at different clusters in the 2D space of (DF, SF). Specifically, we observe an interesting trend from more traditional SR algorithms that are typically inclined to optimize for DF while losing SF, to more recent generative adversarial network (GAN) based approaches that by contrast exhibit strong advantages in achieving high SF but sometimes appear weak at maintaining DF. Furthermore, we propose an uncertainty weighting scheme based on content-dependent sharpness and texture assessment that merges the two fidelity measures into an overall quality prediction named the Super Resolution Image Fidelity (SRIF) index, which demonstrates superior performance against state-of-the-art IQA models when tested on subject-rated datasets.
OA-BEV: Bringing Object Awareness to Bird's-Eye-View Representation for Multi-Camera 3D Object Detection
Jan 13, 2023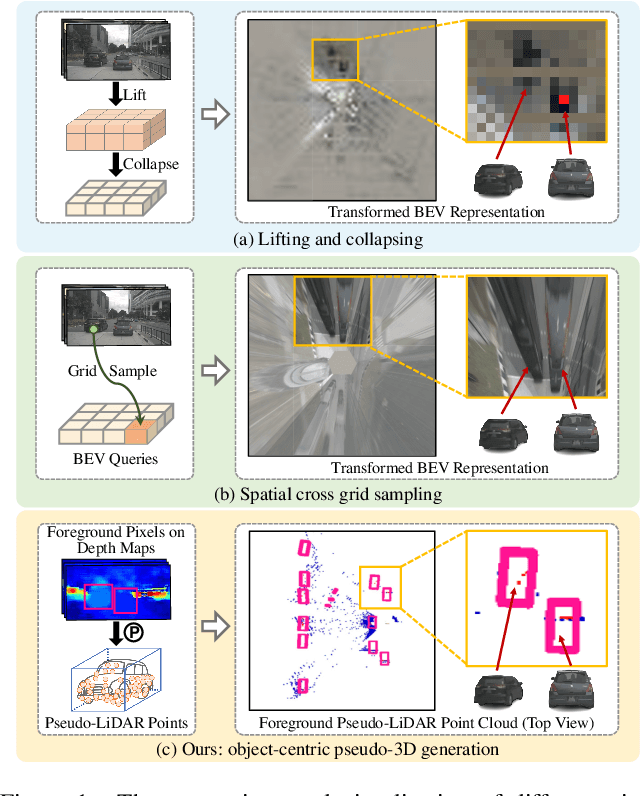
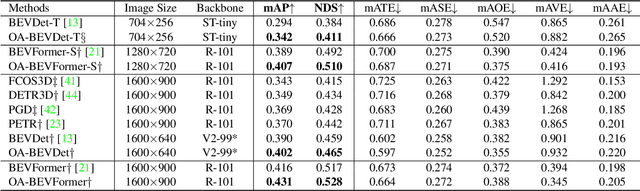
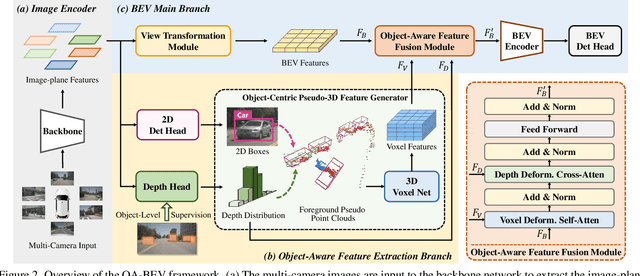
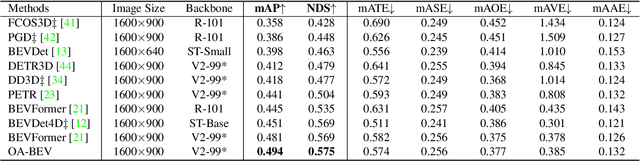
The recent trend for multi-camera 3D object detection is through the unified bird's-eye view (BEV) representation. However, directly transforming features extracted from the image-plane view to BEV inevitably results in feature distortion, especially around the objects of interest, making the objects blur into the background. To this end, we propose OA-BEV, a network that can be plugged into the BEV-based 3D object detection framework to bring out the objects by incorporating object-aware pseudo-3D features and depth features. Such features contain information about the object's position and 3D structures. First, we explicitly guide the network to learn the depth distribution by object-level supervision from each 3D object's center. Then, we select the foreground pixels by a 2D object detector and project them into 3D space for pseudo-voxel feature encoding. Finally, the object-aware depth features and pseudo-voxel features are incorporated into the BEV representation with a deformable attention mechanism. We conduct extensive experiments on the nuScenes dataset to validate the merits of our proposed OA-BEV. Our method achieves consistent improvements over the BEV-based baselines in terms of both average precision and nuScenes detection score. Our codes will be published.
Image Clustering with Contrastive Learning and Multi-scale Graph Convolutional Networks
Jul 14, 2022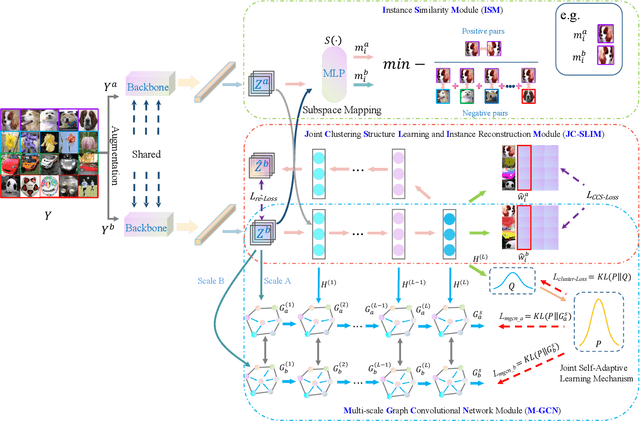

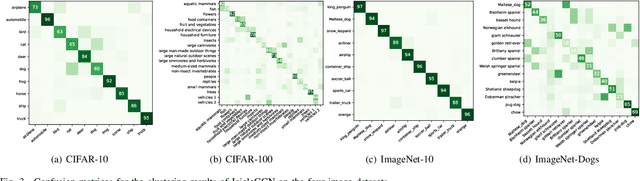

Deep clustering has recently attracted significant attention. Despite the remarkable progress, most of the previous deep clustering works still suffer from two limitations. First, many of them focus on some distribution-based clustering loss, lacking the ability to exploit sample-wise (or augmentation-wise) relationships via contrastive learning. Second, they often neglect the indirect sample-wise structure information, overlooking the rich possibilities of multi-scale neighborhood structure learning. In view of this, this paper presents a new deep clustering approach termed Image clustering with contrastive learning and multi-scale Graph Convolutional Networks (IcicleGCN), which bridges the gap between convolutional neural network (CNN) and graph convolutional network (GCN) as well as the gap between contrastive learning and multi-scale neighborhood structure learning for the image clustering task. The proposed IcicleGCN framework consists of four main modules, namely, the CNN-based backbone, the Instance Similarity Module (ISM), the Joint Cluster Structure Learning and Instance reconstruction Module (JC-SLIM), and the Multi-scale GCN module (M-GCN). Specifically, with two random augmentations performed on each image, the backbone network with two weight-sharing views is utilized to learn the representations for the augmented samples, which are then fed to ISM and JC-SLIM for instance-level and cluster-level contrastive learning, respectively. Further, to enforce multi-scale neighborhood structure learning, two streams of GCNs and an auto-encoder are simultaneously trained via (i) the layer-wise interaction with representation fusion and (ii) the joint self-adaptive learning that ensures their last-layer output distributions to be consistent. Experiments on multiple image datasets demonstrate the superior clustering performance of IcicleGCN over the state-of-the-art.
Hierarchical Average Precision Training for Pertinent Image Retrieval
Jul 05, 2022
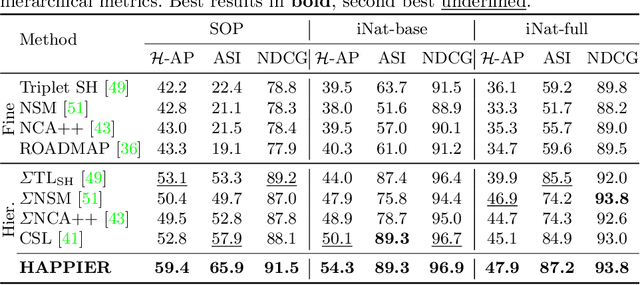
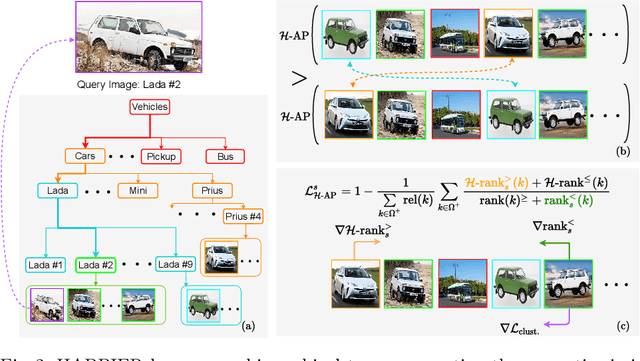
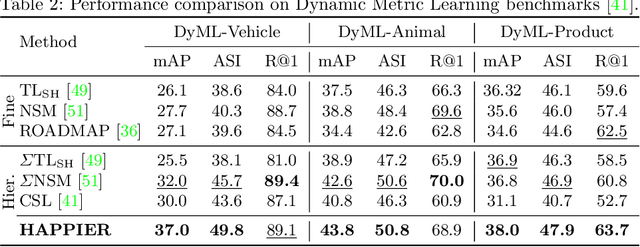
Image Retrieval is commonly evaluated with Average Precision (AP) or Recall@k. Yet, those metrics, are limited to binary labels and do not take into account errors' severity. This paper introduces a new hierarchical AP training method for pertinent image retrieval (HAP-PIER). HAPPIER is based on a new H-AP metric, which leverages a concept hierarchy to refine AP by integrating errors' importance and better evaluate rankings. To train deep models with H-AP, we carefully study the problem's structure and design a smooth lower bound surrogate combined with a clustering loss that ensures consistent ordering. Extensive experiments on 6 datasets show that HAPPIER significantly outperforms state-of-the-art methods for hierarchical retrieval, while being on par with the latest approaches when evaluating fine-grained ranking performances. Finally, we show that HAPPIER leads to better organization of the embedding space, and prevents most severe failure cases of non-hierarchical methods. Our code is publicly available at: https://github.com/elias-ramzi/HAPPIER.
Heterogeneous Graph Learning for Multi-modal Medical Data Analysis
Nov 28, 2022

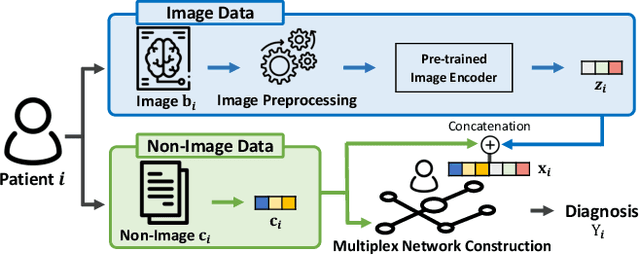

Routine clinical visits of a patient produce not only image data, but also non-image data containing clinical information regarding the patient, i.e., medical data is multi-modal in nature. Such heterogeneous modalities offer different and complementary perspectives on the same patient, resulting in more accurate clinical decisions when they are properly combined. However, despite its significance, how to effectively fuse the multi-modal medical data into a unified framework has received relatively little attention. In this paper, we propose an effective graph-based framework called HetMed (Heterogeneous Graph Learning for Multi-modal Medical Data Analysis) for fusing the multi-modal medical data. Specifically, we construct a multiplex network that incorporates multiple types of non-image features of patients to capture the complex relationship between patients in a systematic way, which leads to more accurate clinical decisions. Extensive experiments on various real-world datasets demonstrate the superiority and practicality of HetMed. The source code for HetMed is available at https://github.com/Sein-Kim/Multimodal-Medical.