 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DSES: an indoor Lidar point cloud segmentation dataset with real and pseudo-labels from a 3D model
Jan 29, 2025Semantic segmentation of indoor point clouds has found various applications in the creation of digital twins for robotics, navigation and building information modeling (BIM). However, most existing datasets of labeled indoor point clouds have been acquired by photogrammetry. In contrast, Terrestrial Laser Scanning (TLS) can acquire dense sub-centimeter point clouds and has become the standard for surveyors. We present 3DSES (3D Segmentation of ESGT point clouds), a new dataset of indoor dense TLS colorized point clouds covering 427 m 2 of an engineering school. 3DSES has a unique double annotation format: semantic labels annotated at the point level alongside a full 3D CAD model of the building. We introduce a model-to-cloud algorithm for automated labeling of indoor point clouds using an existing 3D CAD model. 3DSES has 3 variants of various semantic and geometrical complexities. We show that our model-to-cloud alignment can produce pseudo-labels on our point clouds with a \> 95% accuracy, allowing us to train deep models with significant time savings compared to manual labeling. First baselines on 3DSES show the difficulties encountered by existing models when segmenting objects relevant to BIM, such as light and safety utilities. We show that segmentation accuracy can be improved by leveraging pseudo-labels and Lidar intensity, an information rarely considered in current datasets. Code and data will be open sourced.
PANGAEA: A Global and Inclusive Benchmark for Geospatial Foundation Models
Dec 05, 2024Geospatial Foundation Models (GFMs) have emerged as powerful tools for extracting representations from Earth observation data, but their evaluation remains inconsistent and narrow. Existing works often evaluate on suboptimal downstream datasets and tasks, that are often too easy or too narrow, limiting the usefulness of the evaluations to assess the real-world applicability of GFMs. Additionally, there is a distinct lack of diversity in current evaluation protocols, which fail to account for the multiplicity of image resolutions, sensor types, and temporalities, which further complicates the assessment of GFM performance. In particular, most existing benchmarks are geographically biased towards North America and Europe, questioning the global applicability of GFMs. To overcome these challenges, we introduce PANGAEA, a standardized evaluation protocol that covers a diverse set of datasets, tasks, resolutions, sensor modalities, and temporalities. It establishes a robust and widely applicable benchmark for GFMs. We evaluate the most popular GFMs openly available on this benchmark and analyze their performance across several domains. In particular, we compare these models to supervised baselines (e.g. UNet and vanilla ViT), and assess their effectiveness when faced with limited labeled data. Our findings highlight the limitations of GFMs, under different scenarios, showing that they do not consistently outperform supervised models. PANGAEA is designed to be highly extensible, allowing for the seamless inclusion of new datasets, models, and tasks in future research. By releasing the evaluation code and benchmark, we aim to enable other researchers to replicate our experiments and build upon our work, fostering a more principled evaluation protocol for large pre-trained geospatial models. The code is available at https://github.com/VMarsocci/pangaea-bench.
Improved symbolic drum style classification with grammar-based hierarchical representations
Jul 24, 2024



Deep learning models have become a critical tool for analysis and classification of musical data. These models operate either on the audio signal, e.g. waveform or spectrogram, or on a symbolic representation, such as MIDI. In the latter, musical information is often reduced to basic features, i.e. durations, pitches and velocities. Most existing works then rely on generic tokenization strategies from classical natural language processing, or matrix representations, e.g. piano roll. In this work, we evaluate how enriched representations of symbolic data can impact deep models, i.e. Transformers and RNN, for music style classification. In particular, we examine representations that explicitly incorporate musical information implicitly present in MIDI-like encodings, such as rhythmic organization, and show that they outperform generic tokenization strategies. We introduce a new tree-based representation of MIDI data built upon a context-free musical grammar. We show that this grammar representation accurately encodes high-level rhythmic information and outperforms existing encodings on the GrooveMIDI Dataset for drumming style classification, while being more compact and parameter-efficient.
GalLoP: Learning Global and Local Prompts for Vision-Language Models
Jul 01, 2024



Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs), e.g. CLIP, for few-shot image classification. Despite their success, most prompt learning methods trade-off between classification accuracy and robustness, e.g. in domain generalization or out-of-distribution (OOD) detection. In this work, we introduce Global-Local Prompts (GalLoP), a new prompt learning method that learns multiple diverse prompts leveraging both global and local visual features. The training of the local prompts relies on local features with an enhanced vision-text alignment. To focus only on pertinent features, this local alignment is coupled with a sparsity strategy in the selection of the local features. We enforce diversity on the set of prompts using a new ``prompt dropout'' technique and a multiscale strategy on the local prompts. GalLoP outperforms previous prompt learning methods on accuracy on eleven datasets in different few shots settings and with various backbones. Furthermore, GalLoP shows strong robustness performances in both domain generalization and OOD detection, even outperforming dedicated OOD detection methods. Code and instructions to reproduce our results will be open-sourced.
Cross-sensor self-supervised training and alignment for remote sensing
May 16, 2024



Large-scale "foundation models" have gained traction as a way to leverage the vast amounts of unlabeled remote sensing data collected every day. However, due to the multiplicity of Earth Observation satellites, these models should learn "sensor agnostic" representations, that generalize across sensor characteristics with minimal fine-tuning. This is complicated by data availability, as low-resolution imagery, such as Sentinel-2 and Landsat-8 data, are available in large amounts, while very high-resolution aerial or satellite data is less common. To tackle these challenges, we introduce cross-sensor self-supervised training and alignment for remote sensing (X-STARS). We design a self-supervised training loss, the Multi-Sensor Alignment Dense loss (MSAD), to align representations across sensors, even with vastly different resolutions. Our X-STARS can be applied to train models from scratch, or to adapt large models pretrained on e.g low-resolution EO data to new high-resolution sensors, in a continual pretraining framework. We collect and release MSC-France, a new multi-sensor dataset, on which we train our X-STARS models, then evaluated on seven downstream classification and segmentation tasks. We demonstrate that X-STARS outperforms the state-of-the-art by a significant margin with less data across various conditions of data availability and resolutions.
Cross-sensor super-resolution of irregularly sampled Sentinel-2 time series
Apr 25, 2024



Satellite imaging generally presents a trade-off between the frequency of acquisitions and the spatial resolution of the images. Super-resolution is often advanced as a way to get the best of both worlds. In this work, we investigate multi-image super-resolution of satellite image time series, i.e. how multiple images of the same area acquired at different dates can help reconstruct a higher resolution observation. In particular, we extend state-of-the-art deep single and multi-image super-resolution algorithms, such as SRDiff and HighRes-net, to deal with irregularly sampled Sentinel-2 time series. We introduce BreizhSR, a new dataset for 4x super-resolution of Sentinel-2 time series using very high-resolution SPOT-6 imagery of Brittany, a French region. We show that using multiple images significantly improves super-resolution performance, and that a well-designed temporal positional encoding allows us to perform super-resolution for different times of the series. In addition, we observe a trade-off between spectral fidelity and perceptual quality of the reconstructed HR images, questioning future directions for super-resolution of Earth Observation data.
Detecting Out-Of-Distribution Earth Observation Images with Diffusion Models
Apr 19, 2024



Earth Observation imagery can capture rare and unusual events, such as disasters and major landscape changes, whose visual appearance contrasts with the usual observations. Deep models trained on common remote sensing data will output drastically different features for these out-of-distribution samples, compared to those closer to their training dataset. Detecting them could therefore help anticipate changes in the observations, either geographical or environmental. In this work, we show that the reconstruction error of diffusion models can effectively serve as unsupervised out-of-distribution detectors for remote sensing images, using them as a plausibility score. Moreover, we introduce ODEED, a novel reconstruction-based scorer using the probability-flow ODE of diffusion models. We validate it experimentally on SpaceNet 8 with various scenarios, such as classical OOD detection with geographical shift and near-OOD setups: pre/post-flood and non-flooded/flooded image recognition. We show that our ODEED scorer significantly outperforms other diffusion-based and discriminative baselines on the more challenging near-OOD scenarios of flood image detection, where OOD images are close to the distribution tail. We aim to pave the way towards better use of generative models for anomaly detection in remote sensing.
Optimization of Rank Losses for Image Retrieval
Sep 15, 2023In image retrieval, standard evaluation metrics rely on score ranking, \eg average precision (AP), recall at k (R@k), normalized discounted cumulative gain (NDCG). In this work we introduce a general framework for robust and decomposable rank losses optimization. It addresses two major challenges for end-to-end training of deep neural networks with rank losses: non-differentiability and non-decomposability. Firstly we propose a general surrogate for ranking operator, SupRank, that is amenable to stochastic gradient descent. It provides an upperbound for rank losses and ensures robust training. Secondly, we use a simple yet effective loss function to reduce the decomposability gap between the averaged batch approximation of ranking losses and their values on the whole training set. We apply our framework to two standard metrics for image retrieval: AP and R@k. Additionally we apply our framework to hierarchical image retrieval. We introduce an extension of AP, the hierarchical average precision $\mathcal{H}$-AP, and optimize it as well as the NDCG. Finally we create the first hierarchical landmarks retrieval dataset. We use a semi-automatic pipeline to create hierarchical labels, extending the large scale Google Landmarks v2 dataset. The hierarchical dataset is publicly available at https://github.com/cvdfoundation/google-landmark. Code will be released at https://github.com/elias-ramzi/SupRank.
Hierarchical Average Precision Training for Pertinent Image Retrieval
Jul 05, 2022
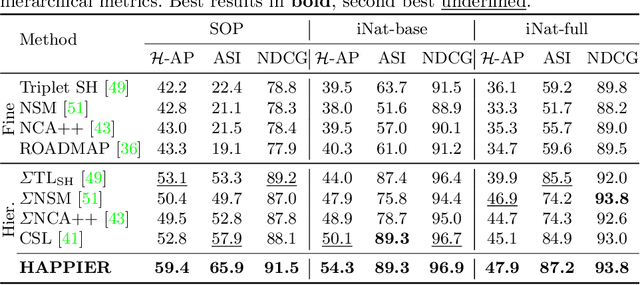
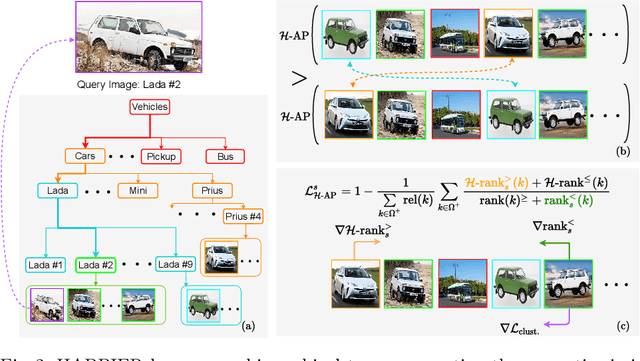
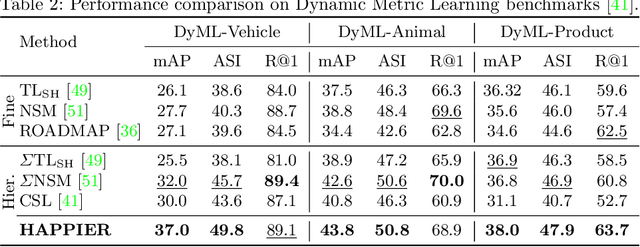
Image Retrieval is commonly evaluated with Average Precision (AP) or Recall@k. Yet, those metrics, are limited to binary labels and do not take into account errors' severity. This paper introduces a new hierarchical AP training method for pertinent image retrieval (HAP-PIER). HAPPIER is based on a new H-AP metric, which leverages a concept hierarchy to refine AP by integrating errors' importance and better evaluate rankings. To train deep models with H-AP, we carefully study the problem's structure and design a smooth lower bound surrogate combined with a clustering loss that ensures consistent ordering. Extensive experiments on 6 datasets show that HAPPIER significantly outperforms state-of-the-art methods for hierarchical retrieval, while being on par with the latest approaches when evaluating fine-grained ranking performances. Finally, we show that HAPPIER leads to better organization of the embedding space, and prevents most severe failure cases of non-hierarchical methods. Our code is publicly available at: https://github.com/elias-ramzi/HAPPIER.
Efficient Autoprecoder-based deep learning for massive MU-MIMO Downlink under PA Non-Linearities
Feb 03, 2022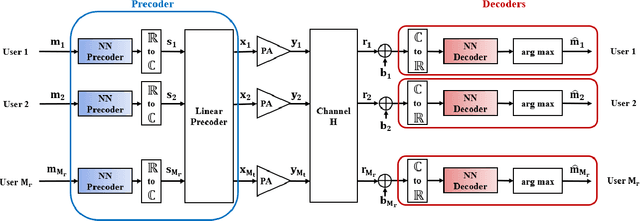

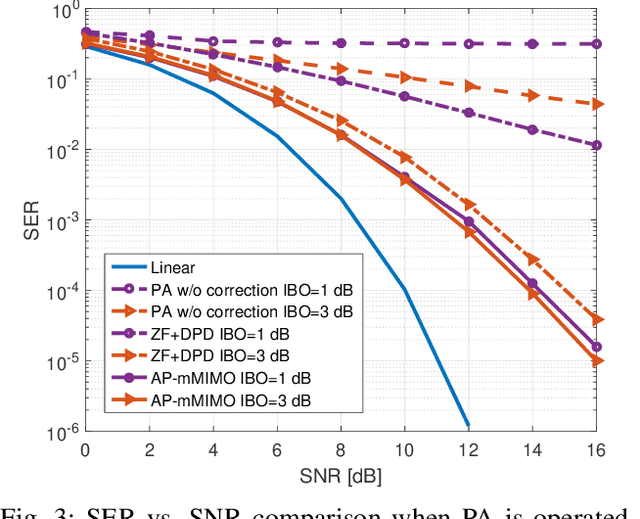
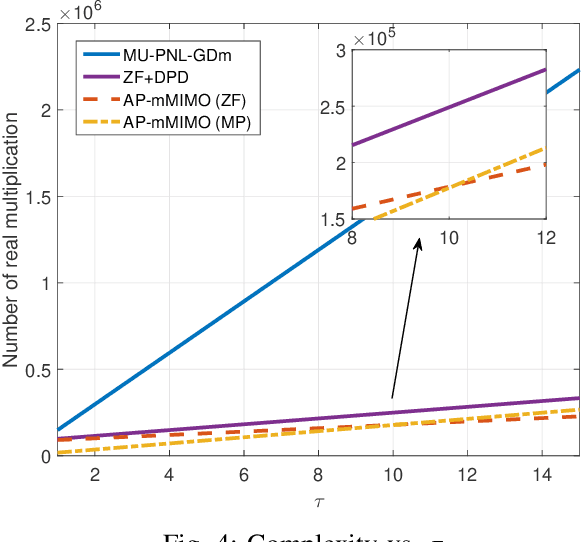
This paper introduces a new efficient autoprecoder (AP) based deep learning approach for massive multiple-input multiple-output (mMIMO) downlink systems in which the base station is equipped with a large number of antennas with energy-efficient power amplifiers (PAs) and serves multiple user terminals. We present AP-mMIMO, a new method that jointly eliminates the multiuser interference and compensates the severe nonlinear (NL) PA distortions. Unlike previous works, AP-mMIMO has a low computational complexity, making it suitable for a global energy-efficient system. Specifically, we aim to design the PA-aware precoder and the receive decoder by leveraging the concept of autoprecoder, whereas the end-to-end massive multiuser (MU)-MIMO downlink is designed using a deep neural network (NN). Most importantly, the proposed AP-mMIMO is suited for the varying block fading channel scenario. To deal with such scenarios, we consider a two-stage precoding scheme: 1) a NN-precoder is used to address the PA non-linearities and 2) a linear precoder is used to suppress the multiuser interference. The NN-precoder and the receive decoder are trained off-line and when the channel varies, only the linear precoder changes on-line. This latter is designed by using the widely used zero-forcing precoding scheme or its lowcomplexity version based on matrix polynomials. Numerical simulations show that the proposed AP-mMIMO approach achieves competitive performance with a significantly lower complexity compared to existing literature. Index Terms-multiuser (MU) precoding, massive multipleinput multiple-output (MIMO), energy-efficiency, hardware impairment, power amplifier (PA) nonlinearities, autoprecoder, deep learning, neural network (NN)