 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ShadowDiffusion: When Degradation Prior Meets Diffusion Model for Shadow Removal
Dec 13, 2022

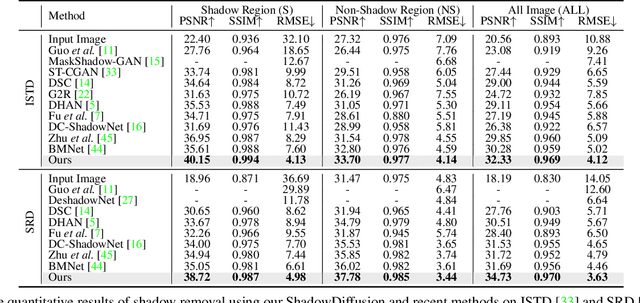
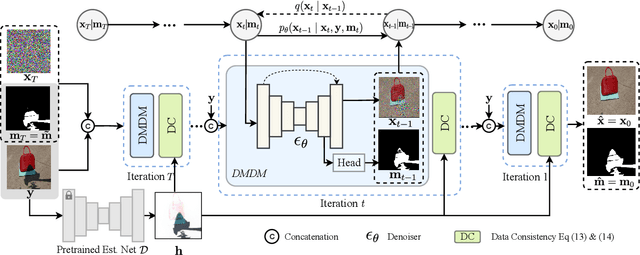
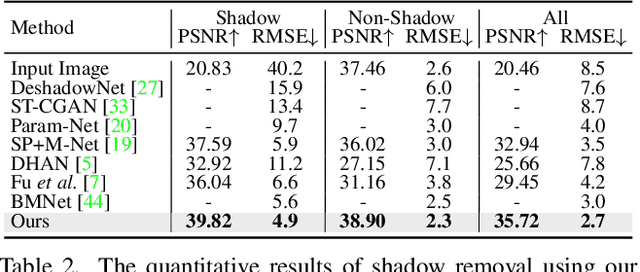
Recent deep learning methods have achieved promising results in image shadow removal. However, their restored images still suffer from unsatisfactory boundary artifacts, due to the lack of degradation prior embedding and the deficiency in modeling capacity. Our work addresses these issues by proposing a unified diffusion framework that integrates both the image and degradation priors for highly effective shadow removal. In detail, we first propose a shadow degradation model, which inspires us to build a novel unrolling diffusion model, dubbed ShandowDiffusion. It remarkably improves the model's capacity in shadow removal via progressively refining the desired output with both degradation prior and diffusive generative prior, which by nature can serve as a new strong baseline for image restoration. Furthermore, ShadowDiffusion progressively refines the estimated shadow mask as an auxiliary task of the diffusion generator, which leads to more accurate and robust shadow-free image generation. We conduct extensive experiments on three popular public datasets, including ISTD, ISTD+, and SRD, to validate our method's effectiveness. Compared to the state-of-the-art methods, our model achieves a significant improvement in terms of PSNR, increasing from 31.69dB to 34.73dB over SRD dataset.
M-VADER: A Model for Diffusion with Multimodal Context
Dec 07, 2022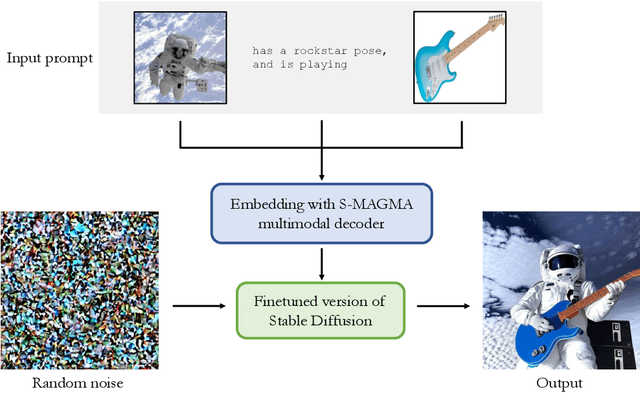
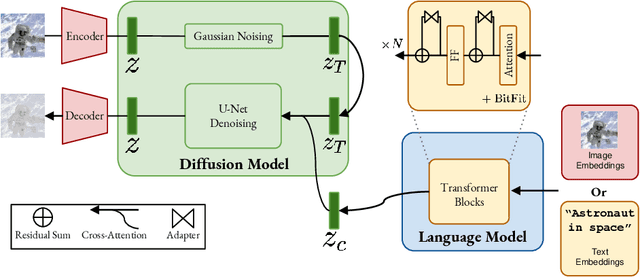

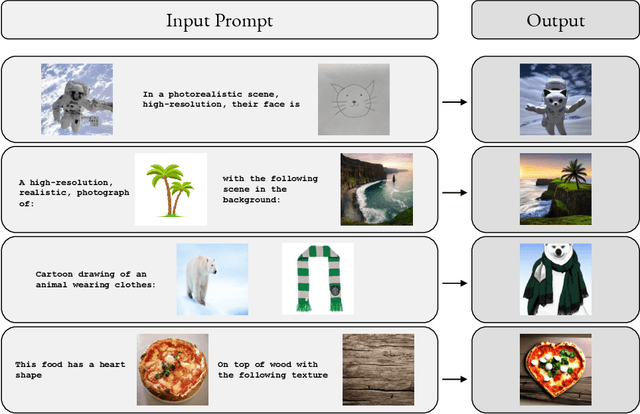
We introduce M-VADER: a diffusion model (DM) for image generation where the output can be specified using arbitrary combinations of images and text. We show how M-VADER enables the generation of images specified using combinations of image and text, and combinations of multiple images. Previously, a number of successful DM image generation algorithms have been introduced that make it possible to specify the output image using a text prompt. Inspired by the success of those models, and led by the notion that language was already developed to describe the elements of visual contexts that humans find most important, we introduce an embedding model closely related to a vision-language model. Specifically, we introduce the embedding model S-MAGMA: a 13 billion parameter multimodal decoder combining components from an autoregressive vision-language model MAGMA and biases finetuned for semantic search.
FLAIR: Federated Learning Annotated Image Repository
Jul 18, 2022
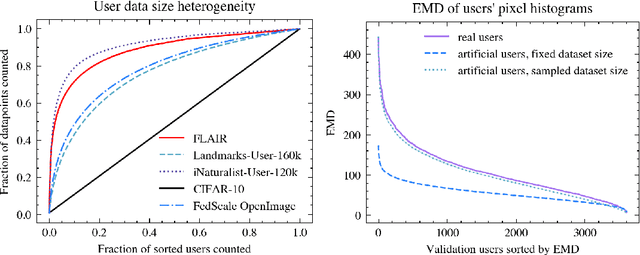
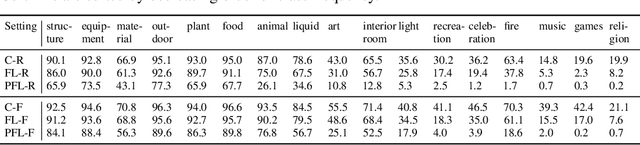
Cross-device federated learning is an emerging machine learning (ML) paradigm where a large population of devices collectively train an ML model while the data remains on the devices. This research field has a unique set of practical challenges, and to systematically make advances, new datasets curated to be compatible with this paradigm are needed. Existing federated learning benchmarks in the image domain do not accurately capture the scale and heterogeneity of many real-world use cases. We introduce FLAIR, a challenging large-scale annotated image dataset for multi-label classification suitable for federated learning. FLAIR has 429,078 images from 51,414 Flickr users and captures many of the intricacies typically encountered in federated learning, such as heterogeneous user data and a long-tailed label distribution. We implement multiple baselines in different learning setups for different tasks on this dataset. We believe FLAIR can serve as a challenging benchmark for advancing the state-of-the art in federated learning. Dataset access and the code for the benchmark are available at \url{https://github.com/apple/ml-flair}.
Triple-View Feature Learning for Medical Image Segmentation
Aug 12, 2022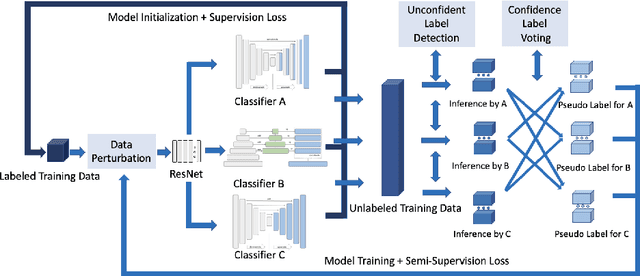
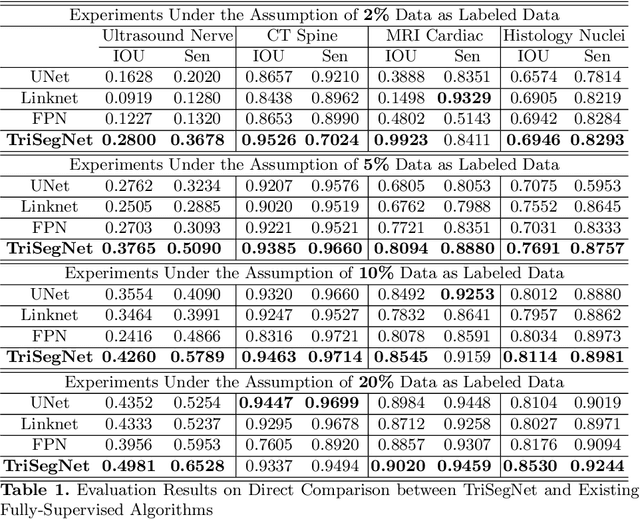
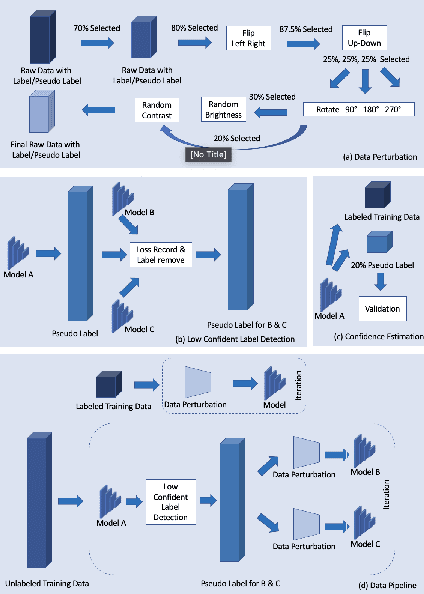
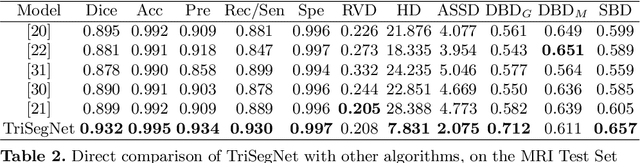
Deep learning models, e.g. supervised Encoder-Decoder style networks, exhibit promising performance in medical image segmentation, but come with a high labelling cost. We propose TriSegNet, a semi-supervised semantic segmentation framework. It uses triple-view feature learning on a limited amount of labelled data and a large amount of unlabeled data. The triple-view architecture consists of three pixel-level classifiers and a low-level shared-weight learning module. The model is first initialized with labelled data. Label processing, including data perturbation, confidence label voting and unconfident label detection for annotation, enables the model to train on labelled and unlabeled data simultaneously. The confidence of each model gets improved through the other two views of the feature learning. This process is repeated until each model reaches the same confidence level as its counterparts. This strategy enables triple-view learning of generic medical image datasets. Bespoke overlap-based and boundary-based loss functions are tailored to the different stages of the training. The segmentation results are evaluated on four publicly available benchmark datasets including Ultrasound, CT, MRI, and Histology images. Repeated experiments demonstrate the effectiveness of the proposed network compared against other semi-supervised algorithms, across a large set of evaluation measures.
A Provable Splitting Approach for Symmetric Nonnegative Matrix Factorization
Jan 25, 2023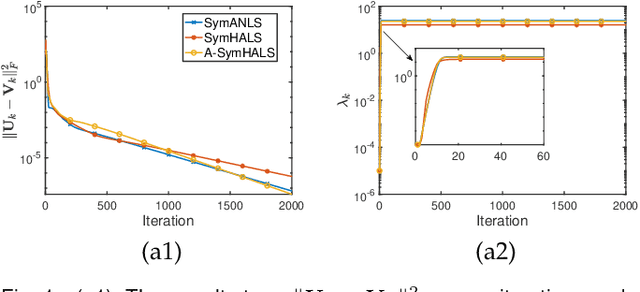
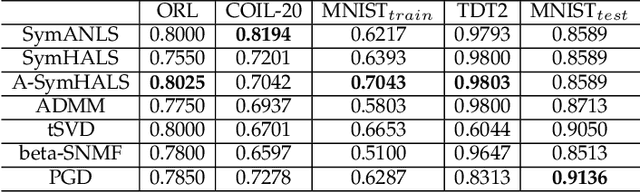
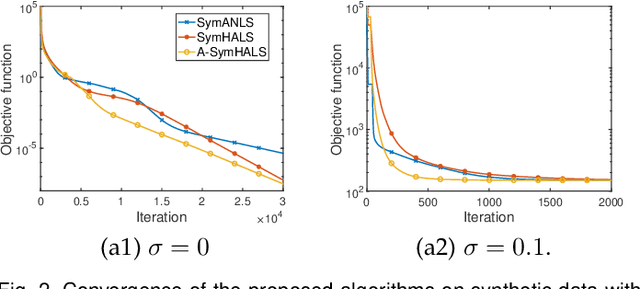
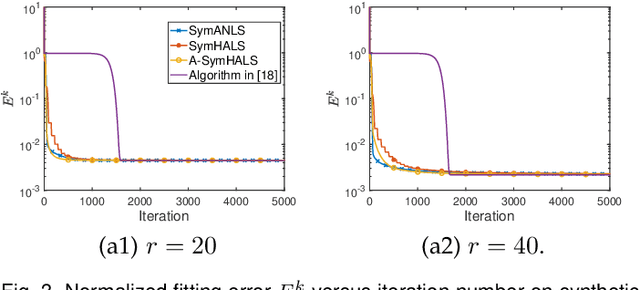
The symmetric Nonnegative Matrix Factorization (NMF), a special but important class of the general NMF, has found numerous applications in data analysis such as various clustering tasks. Unfortunately, designing fast algorithms for the symmetric NMF is not as easy as for its nonsymmetric counterpart, since the latter admits the splitting property that allows state-of-the-art alternating-type algorithms. To overcome this issue, we first split the decision variable and transform the symmetric NMF to a penalized nonsymmetric one, paving the way for designing efficient alternating-type algorithms. We then show that solving the penalized nonsymmetric reformulation returns a solution to the original symmetric NMF. Moreover, we design a family of alternating-type algorithms and show that they all admit strong convergence guarantee: the generated sequence of iterates is convergent and converges at least sublinearly to a critical point of the original symmetric NMF. Finally, we conduct experiments on both synthetic data and real image clustering to support our theoretical results and demonstrate the performance of the alternating-type algorithms.
Identifying Exoplanets with Deep Learning. V. Improved Light Curve Classification for TESS Full Frame Image Observations
Jan 03, 2023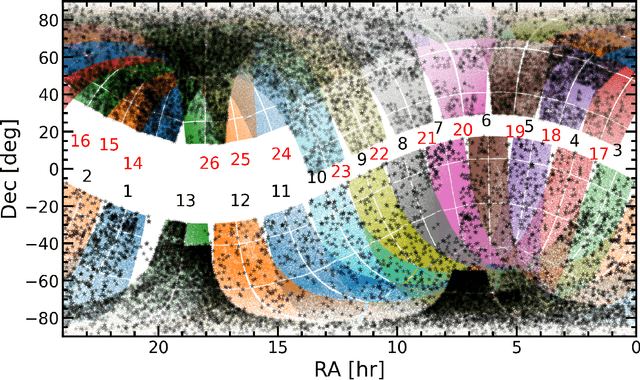
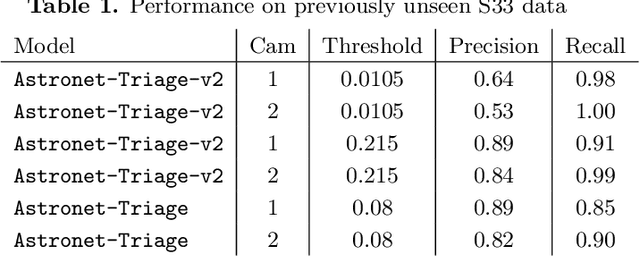
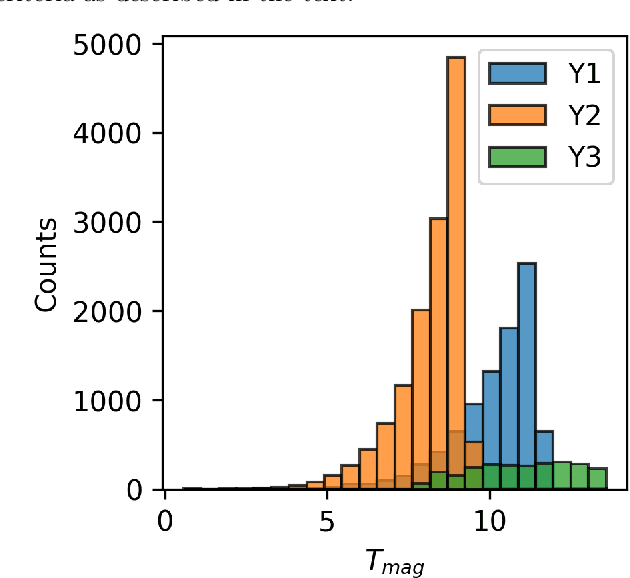
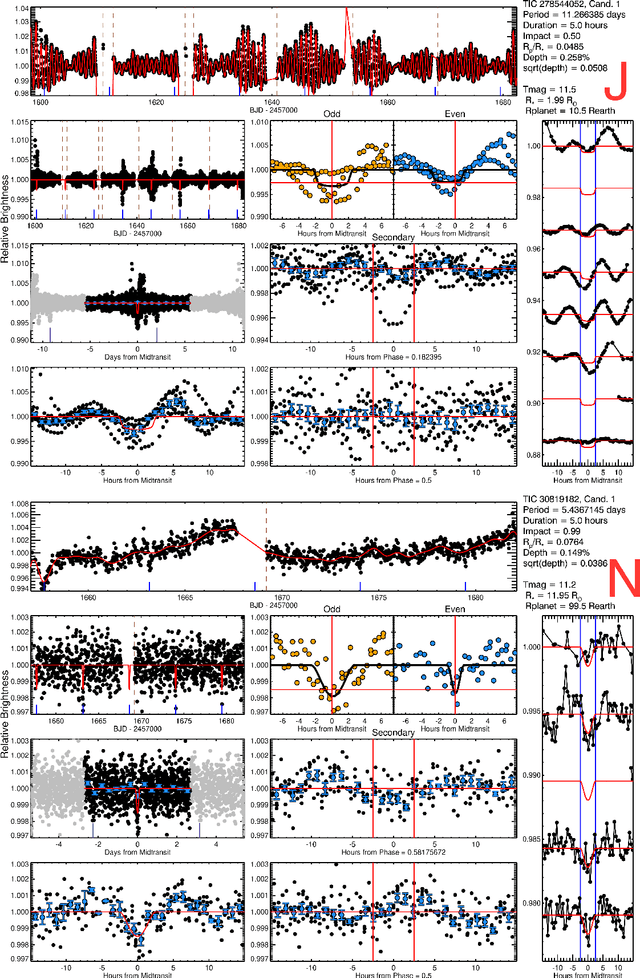
The TESS mission produces a large amount of time series data, only a small fraction of which contain detectable exoplanetary transit signals. Deep learning techniques such as neural networks have proved effective at differentiating promising astrophysical eclipsing candidates from other phenomena such as stellar variability and systematic instrumental effects in an efficient, unbiased and sustainable manner. This paper presents a high quality dataset containing light curves from the Primary Mission and 1st Extended Mission full frame images and periodic signals detected via Box Least Squares (Kov\'acs et al. 2002; Hartman 2012). The dataset was curated using a thorough manual review process then used to train a neural network called Astronet-Triage-v2. On our test set, for transiting/eclipsing events we achieve a 99.6% recall (true positives over all data with positive labels) at a precision of 75.7% (true positives over all predicted positives). Since 90% of our training data is from the Primary Mission, we also test our ability to generalize on held-out 1st Extended Mission data. Here, we find an area under the precision-recall curve of 0.965, a 4% improvement over Astronet-Triage (Yu et al. 2019). On the TESS Object of Interest (TOI) Catalog through April 2022, a shortlist of planets and planet candidates, Astronet-Triage-v2 is able to recover 3577 out of 4140 TOIs, while Astronet-Triage only recovers 3349 targets at an equal level of precision. In other words, upgrading to Astronet-Triage-v2 helps save at least 200 planet candidates from being lost. The new model is currently used for planet candidate triage in the Quick-Look Pipeline (Huang et al. 2020a,b; Kunimoto et al. 2021).
A Domain-specific Perceptual Metric via Contrastive Self-supervised Representation: Applications on Natural and Medical Images
Dec 03, 2022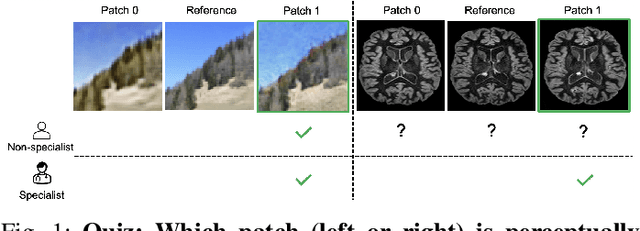
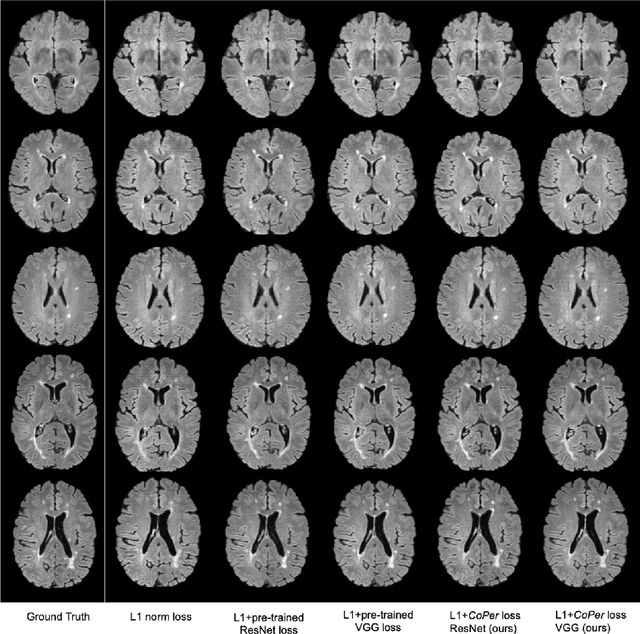
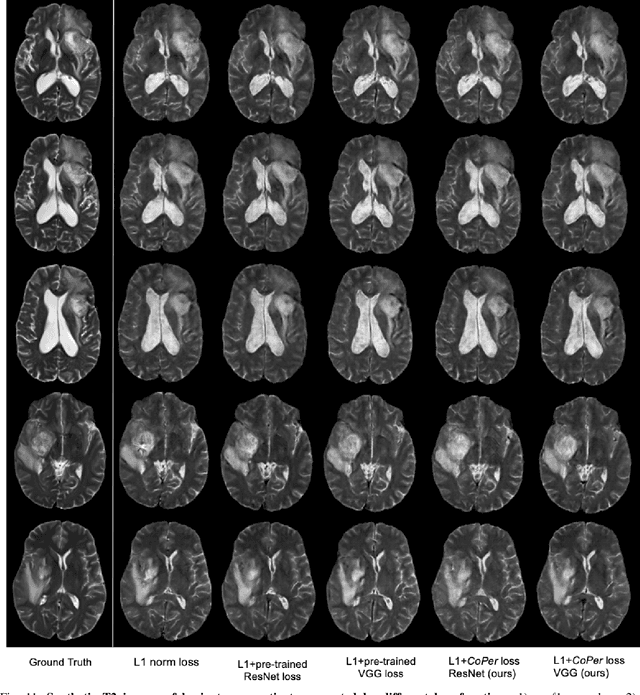
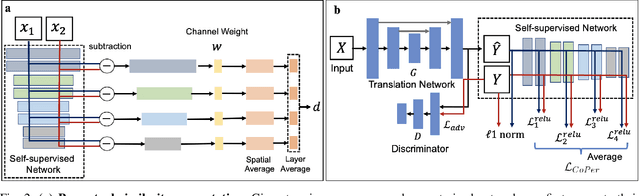
Quantifying the perceptual similarity of two images is a long-standing problem in low-level computer vision. The natural image domain commonly relies on supervised learning, e.g., a pre-trained VGG, to obtain a latent representation. However, due to domain shift, pre-trained models from the natural image domain might not apply to other image domains, such as medical imaging. Notably, in medical imaging, evaluating the perceptual similarity is exclusively performed by specialists trained extensively in diverse medical fields. Thus, medical imaging remains devoid of task-specific, objective perceptual measures. This work answers the question: Is it necessary to rely on supervised learning to obtain an effective representation that could measure perceptual similarity, or is self-supervision sufficient? To understand whether recent contrastive self-supervised representation (CSR) may come to the rescue, we start with natural images and systematically evaluate CSR as a metric across numerous contemporary architectures and tasks and compare them with existing methods. We find that in the natural image domain, CSR behaves on par with the supervised one on several perceptual tests as a metric, and in the medical domain, CSR better quantifies perceptual similarity concerning the experts' ratings. We also demonstrate that CSR can significantly improve image quality in two image synthesis tasks. Finally, our extensive results suggest that perceptuality is an emergent property of CSR, which can be adapted to many image domains without requiring annotations.
IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation
Feb 02, 2023
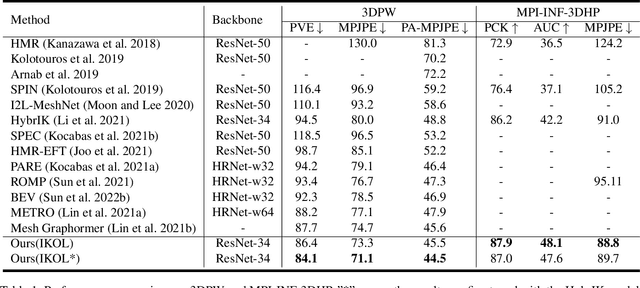
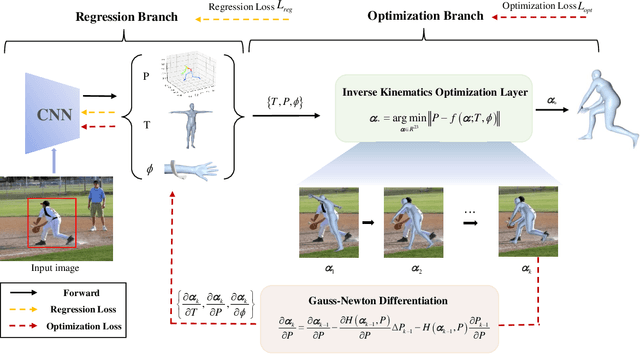
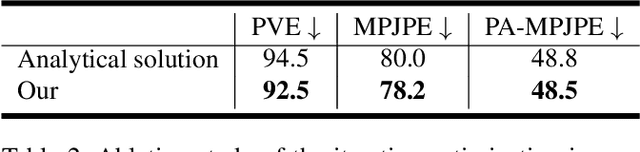
This paper presents an inverse kinematic optimization layer (IKOL) for 3D human pose and shape estimation that leverages the strength of both optimization- and regression-based methods within an end-to-end framework. IKOL involves a nonconvex optimization that establishes an implicit mapping from an image's 3D keypoints and body shapes to the relative body-part rotations. The 3D keypoints and the body shapes are the inputs and the relative body-part rotations are the solutions. However, this procedure is implicit and hard to make differentiable. So, to overcome this issue, we designed a Gauss-Newton differentiation (GN-Diff) procedure to differentiate IKOL. GN-Diff iteratively linearizes the nonconvex objective function to obtain Gauss-Newton directions with closed form solutions. Then, an automatic differentiation procedure is directly applied to generate a Jacobian matrix for end-to-end training. Notably, the GN-Diff procedure works fast because it does not rely on a time-consuming implicit differentiation procedure. The twist rotation and shape parameters are learned from the neural networks and, as a result, IKOL has a much lower computational overhead than most existing optimization-based methods. Additionally, compared to existing regression-based methods, IKOL provides a more accurate mesh-image correspondence. This is because it iteratively reduces the distance between the keypoints and also enhances the reliability of the pose structures. Extensive experiments demonstrate the superiority of our proposed framework over a wide range of 3D human pose and shape estimation methods.
Vision Aided Environment Semantics Extraction and Its Application in mmWave Beam Selection
Jan 21, 2023
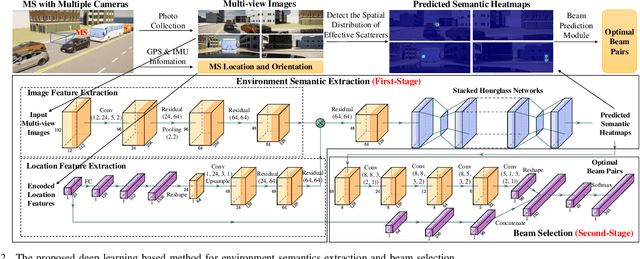
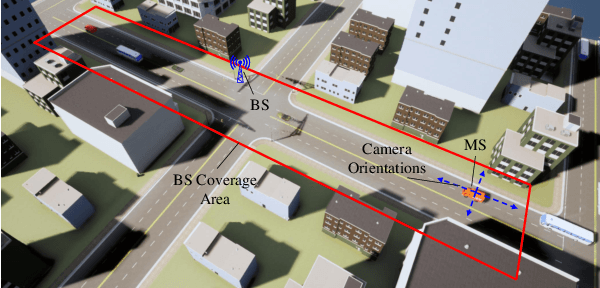
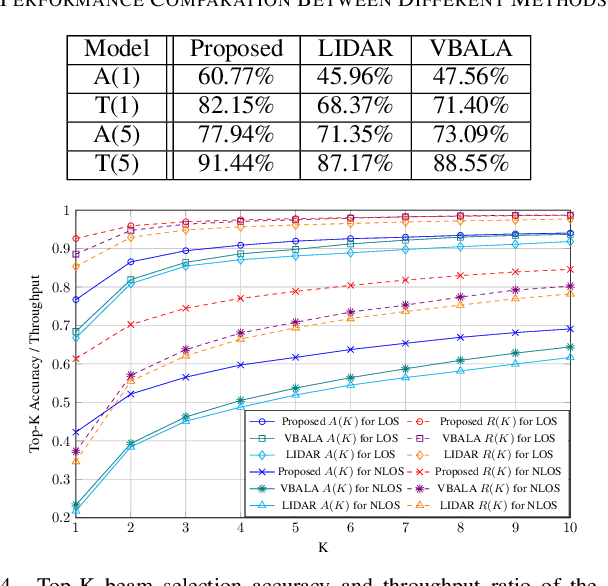
In this letter, we propose a novel mmWave beam selection method based on the environment semantics that are extracted from camera images taken at the user side. Specifically, we first define the environment semantics as the spatial distribution of the scatterers that affect the wireless propagation channels and utilize the keypoint detection technique to extract them from the input images. Then, we design a deep neural network with environment semantics as the input that can output the optimal beam pairs at UE and BS. Compared with the existing beam selection approaches that directly use images as the input, the proposed semantic-based method can explicitly obtain the environmental features that account for the propagation of wireless signals, and thus reduce the burden of storage and computation. Simulation results show that the proposed method can precisely estimate the location of the scatterers and outperform the existing image or LIDAR based works.
GoogLe2Net: Going Transverse with Convolutions
Jan 01, 2023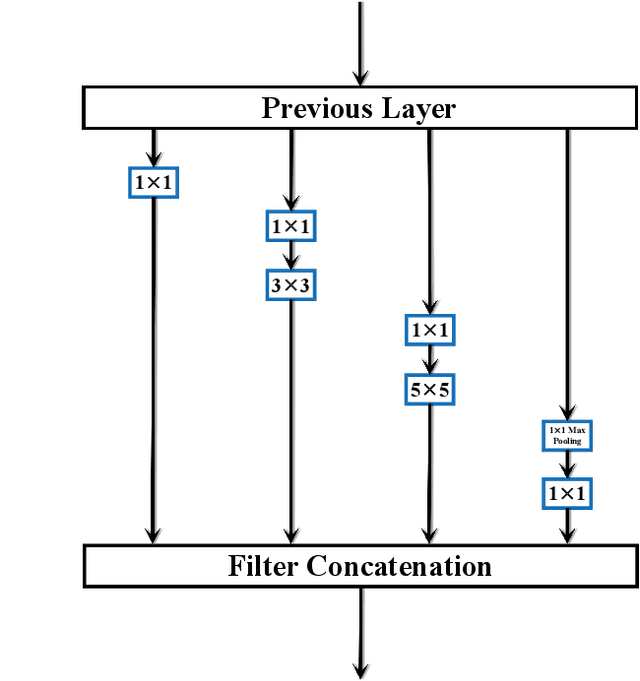
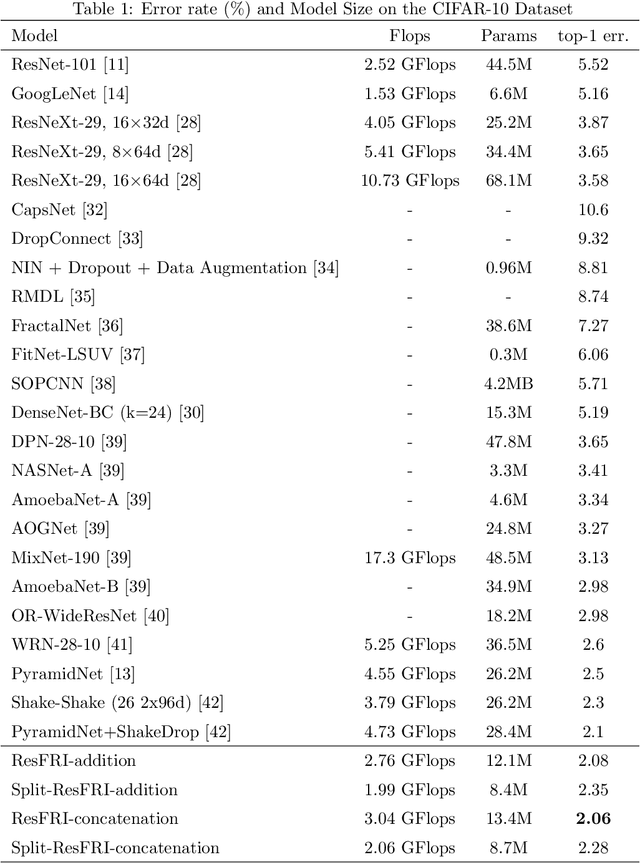
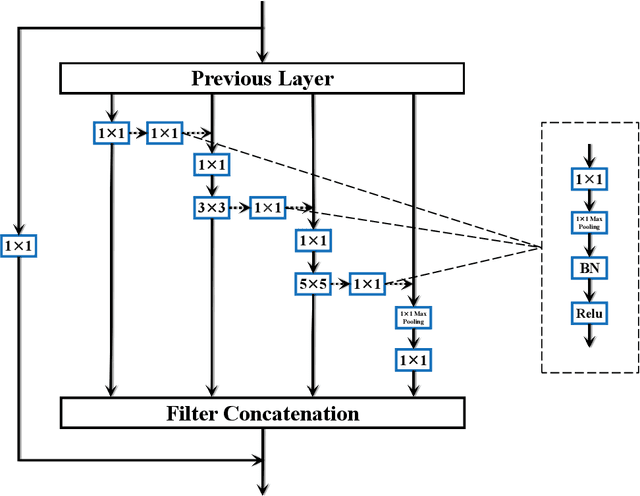
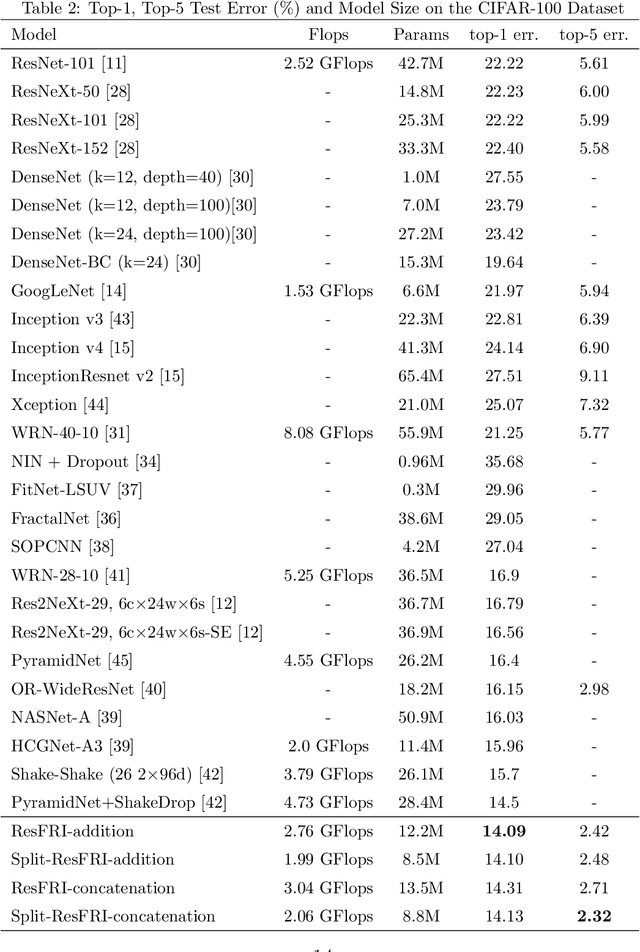
Capturing feature information effectively is of great importance in vision tasks. With the development of convolutional neural networks (CNNs), concepts like residual connection and multiple scales promote continual performance gains on diverse deep learning vision tasks. However, the existing methods do not organically combined advantages of these valid ideas. In this paper, we propose a novel CNN architecture called GoogLe2Net, it consists of residual feature-reutilization inceptions (ResFRI) or split residual feature-reutilization inceptions (Split-ResFRI) which create transverse passages between adjacent groups of convolutional layers to enable features flow to latter processing branches and possess residual connections to better process information. Our GoogLe2Net is able to reutilize information captured by foregoing groups of convolutional layers and express multi-scale features at a fine-grained level, which improves performances in image classification. And the inception we proposed could be embedded into inception-like networks directly without any migration costs. Moreover, in experiments based on popular vision datasets, such as CIFAR10 (97.94%), CIFAR100 (85.91%) and Tiny Imagenet (70.54%), we obtain better results on image classification task compared with other modern models.