 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Enhanced Portable Ultra Low-Field Diffusion Tensor Imaging with Bayesian Artifact Correction and Deep Learning-Based Super-Resolution
Feb 11, 2026Portable, ultra-low-field (ULF) magnetic resonance imaging has the potential to expand access to neuroimaging but currently suffers from coarse spatial and angular resolutions and low signal-to-noise ratios. Diffusion tensor imaging (DTI), a sequence tailored to detect and reconstruct white matter tracts within the brain, is particularly prone to such imaging degradation due to inherent sequence design coupled with prolonged scan times. In addition, ULF DTI scans exhibit artifacting that spans both the space and angular domains, requiring a custom modelling algorithm for subsequent correction. We introduce a nine-direction, single-shell ULF DTI sequence, as well as a companion Bayesian bias field correction algorithm that possesses angular dependence and convolutional neural network-based superresolution algorithm that is generalizable across DTI datasets and does not require re-training (''DiffSR''). We show through a synthetic downsampling experiment and white matter assessment in real, matched ULF and high-field DTI scans that these algorithms can recover microstructural and volumetric white matter information at ULF. We also show that DiffSR can be directly applied to white matter-based Alzheimers disease classification in synthetically degraded scans, with notable improvements in agreement between DTI metrics, as compared to un-degraded scans. We freely disseminate the Bayesian bias correction algorithm and DiffSR with the goal of furthering progress on both ULF reconstruction methods and general DTI sequence harmonization. We release all code related to DiffSR for $\href{https://github.com/markolchanyi/DiffSR}{public \space use}$.
Improving Neuropathological Reconstruction Fidelity via AI Slice Imputation
Jan 31, 2026Neuropathological analyses benefit from spatially precise volumetric reconstructions that enhance anatomical delineation and improve morphometric accuracy. Our prior work has shown the feasibility of reconstructing 3D brain volumes from 2D dissection photographs. However these outputs sometimes exhibit coarse, overly smooth reconstructions of structures, especially under high anisotropy (i.e., reconstructions from thick slabs). Here, we introduce a computationally efficient super-resolution step that imputes slices to generate anatomically consistent isotropic volumes from anisotropic 3D reconstructions of dissection photographs. By training on domain-randomized synthetic data, we ensure that our method generalizes across dissection protocols and remains robust to large slab thicknesses. The imputed volumes yield improved automated segmentations, achieving higher Dice scores, particularly in cortical and white matter regions. Validation on surface reconstruction and atlas registration tasks demonstrates more accurate cortical surfaces and MRI registration. By enhancing the resolution and anatomical fidelity of photograph-based reconstructions, our approach strengthens the bridge between neuropathology and neuroimaging. Our method is publicly available at https://surfer.nmr.mgh.harvard.edu/fswiki/mri_3d_photo_recon
A large-scale heterogeneous 3D magnetic resonance brain imaging dataset for self-supervised learning
Jun 17, 2025We present FOMO60K, a large-scale, heterogeneous dataset of 60,529 brain Magnetic Resonance Imaging (MRI) scans from 13,900 sessions and 11,187 subjects, aggregated from 16 publicly available sources. The dataset includes both clinical- and research-grade images, multiple MRI sequences, and a wide range of anatomical and pathological variability, including scans with large brain anomalies. Minimal preprocessing was applied to preserve the original image characteristics while reducing barriers to entry for new users. Accompanying code for self-supervised pretraining and finetuning is provided. FOMO60K is intended to support the development and benchmarking of self-supervised learning methods in medical imaging at scale.
Conditional diffusion models for guided anomaly detection in brain images using fluid-driven anomaly randomization
Jun 11, 2025Supervised machine learning has enabled accurate pathology detection in brain MRI, but requires training data from diseased subjects that may not be readily available in some scenarios, for example, in the case of rare diseases. Reconstruction-based unsupervised anomaly detection, in particular using diffusion models, has gained popularity in the medical field as it allows for training on healthy images alone, eliminating the need for large disease-specific cohorts. These methods assume that a model trained on normal data cannot accurately represent or reconstruct anomalies. However, this assumption often fails with models failing to reconstruct healthy tissue or accurately reconstruct abnormal regions i.e., failing to remove anomalies. In this work, we introduce a novel conditional diffusion model framework for anomaly detection and healthy image reconstruction in brain MRI. Our weakly supervised approach integrates synthetically generated pseudo-pathology images into the modeling process to better guide the reconstruction of healthy images. To generate these pseudo-pathologies, we apply fluid-driven anomaly randomization to augment real pathology segmentation maps from an auxiliary dataset, ensuring that the synthetic anomalies are both realistic and anatomically coherent. We evaluate our model's ability to detect pathology, using both synthetic anomaly datasets and real pathology from the ATLAS dataset. In our extensive experiments, our model: (i) consistently outperforms variational autoencoders, and conditional and unconditional latent diffusion; and (ii) surpasses on most datasets, the performance of supervised inpainting methods with access to paired diseased/healthy images.
Scalable Segmentation for Ultra-High-Resolution Brain MR Images
May 27, 2025Although deep learning has shown great success in 3D brain MRI segmentation, achieving accurate and efficient segmentation of ultra-high-resolution brain images remains challenging due to the lack of labeled training data for fine-scale anatomical structures and high computational demands. In this work, we propose a novel framework that leverages easily accessible, low-resolution coarse labels as spatial references and guidance, without incurring additional annotation cost. Instead of directly predicting discrete segmentation maps, our approach regresses per-class signed distance transform maps, enabling smooth, boundary-aware supervision. Furthermore, to enhance scalability, generalizability, and efficiency, we introduce a scalable class-conditional segmentation strategy, where the model learns to segment one class at a time conditioned on a class-specific input. This novel design not only reduces memory consumption during both training and testing, but also allows the model to generalize to unseen anatomical classes. We validate our method through comprehensive experiments on both synthetic and real-world datasets, demonstrating its superior performance and scalability compared to conventional segmentation approaches.
End-to-end Cortical Surface Reconstruction from Clinical Magnetic Resonance Images
May 20, 2025Surface-based cortical analysis is valuable for a variety of neuroimaging tasks, such as spatial normalization, parcellation, and gray matter (GM) thickness estimation. However, most tools for estimating cortical surfaces work exclusively on scans with at least 1 mm isotropic resolution and are tuned to a specific magnetic resonance (MR) contrast, often T1-weighted (T1w). This precludes application using most clinical MR scans, which are very heterogeneous in terms of contrast and resolution. Here, we use synthetic domain-randomized data to train the first neural network for explicit estimation of cortical surfaces from scans of any contrast and resolution, without retraining. Our method deforms a template mesh to the white matter (WM) surface, which guarantees topological correctness. This mesh is further deformed to estimate the GM surface. We compare our method to recon-all-clinical (RAC), an implicit surface reconstruction method which is currently the only other tool capable of processing heterogeneous clinical MR scans, on ADNI and a large clinical dataset (n=1,332). We show a approximately 50 % reduction in cortical thickness error (from 0.50 to 0.24 mm) with respect to RAC and better recovery of the aging-related cortical thinning patterns detected by FreeSurfer on high-resolution T1w scans. Our method enables fast and accurate surface reconstruction of clinical scans, allowing studies (1) with sample sizes far beyond what is feasible in a research setting, and (2) of clinical populations that are difficult to enroll in research studies. The code is publicly available at https://github.com/simnibs/brainnet.
From Low Field to High Value: Robust Cortical Mapping from Low-Field MRI
May 18, 2025Three-dimensional reconstruction of cortical surfaces from MRI for morphometric analysis is fundamental for understanding brain structure. While high-field MRI (HF-MRI) is standard in research and clinical settings, its limited availability hinders widespread use. Low-field MRI (LF-MRI), particularly portable systems, offers a cost-effective and accessible alternative. However, existing cortical surface analysis tools are optimized for high-resolution HF-MRI and struggle with the lower signal-to-noise ratio and resolution of LF-MRI. In this work, we present a machine learning method for 3D reconstruction and analysis of portable LF-MRI across a range of contrasts and resolutions. Our method works "out of the box" without retraining. It uses a 3D U-Net trained on synthetic LF-MRI to predict signed distance functions of cortical surfaces, followed by geometric processing to ensure topological accuracy. We evaluate our method using paired HF/LF-MRI scans of the same subjects, showing that LF-MRI surface reconstruction accuracy depends on acquisition parameters, including contrast type (T1 vs T2), orientation (axial vs isotropic), and resolution. A 3mm isotropic T2-weighted scan acquired in under 4 minutes, yields strong agreement with HF-derived surfaces: surface area correlates at r=0.96, cortical parcellations reach Dice=0.98, and gray matter volume achieves r=0.93. Cortical thickness remains more challenging with correlations up to r=0.70, reflecting the difficulty of sub-mm precision with 3mm voxels. We further validate our method on challenging postmortem LF-MRI, demonstrating its robustness. Our method represents a step toward enabling cortical surface analysis on portable LF-MRI. Code is available at https://surfer.nmr.mgh.harvard.edu/fswiki/ReconAny
Analysis of the MICCAI Brain Tumor Segmentation -- Metastases (BraTS-METS) 2025 Lighthouse Challenge: Brain Metastasis Segmentation on Pre- and Post-treatment MRI
Apr 16, 2025Despite continuous advancements in cancer treatment, brain metastatic disease remains a significant complication of primary cancer and is associated with an unfavorable prognosis. One approach for improving diagnosis, management, and outcomes is to implement algorithms based on artificial intelligence for the automated segmentation of both pre- and post-treatment MRI brain images. Such algorithms rely on volumetric criteria for lesion identification and treatment response assessment, which are still not available in clinical practice. Therefore, it is critical to establish tools for rapid volumetric segmentations methods that can be translated to clinical practice and that are trained on high quality annotated data. The BraTS-METS 2025 Lighthouse Challenge aims to address this critical need by establishing inter-rater and intra-rater variability in dataset annotation by generating high quality annotated datasets from four individual instances of segmentation by neuroradiologists while being recorded on video (two instances doing "from scratch" and two instances after AI pre-segmentation). This high-quality annotated dataset will be used for testing phase in 2025 Lighthouse challenge and will be publicly released at the completion of the challenge. The 2025 Lighthouse challenge will also release the 2023 and 2024 segmented datasets that were annotated using an established pipeline of pre-segmentation, student annotation, two neuroradiologists checking, and one neuroradiologist finalizing the process. It builds upon its previous edition by including post-treatment cases in the dataset. Using these high-quality annotated datasets, the 2025 Lighthouse challenge plans to test benchmark algorithms for automated segmentation of pre-and post-treatment brain metastases (BM), trained on diverse and multi-institutional datasets of MRI images obtained from patients with brain metastases.
Reference-Free 3D Reconstruction of Brain Dissection Photographs with Machine Learning
Mar 13, 2025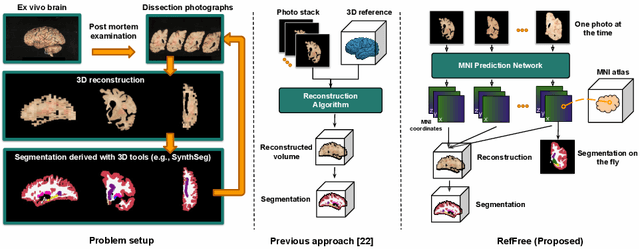
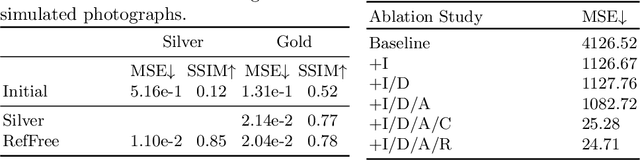
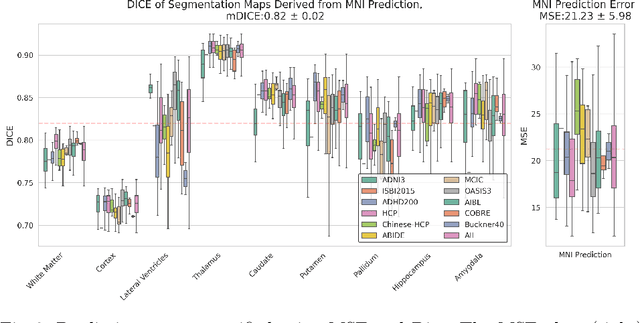
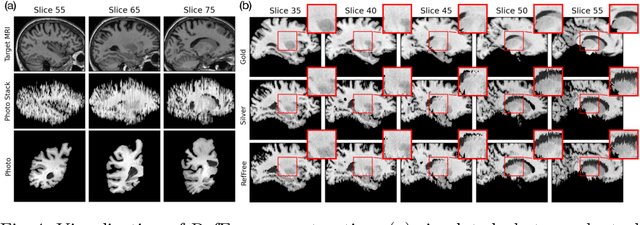
Correlation of neuropathology with MRI has the potential to transfer microscopic signatures of pathology to invivo scans. Recently, a classical registration method has been proposed, to build these correlations from 3D reconstructed stacks of dissection photographs, which are routinely taken at brain banks. These photographs bypass the need for exvivo MRI, which is not widely accessible. However, this method requires a full stack of brain slabs and a reference mask (e.g., acquired with a surface scanner), which severely limits the applicability of the technique. Here we propose RefFree, a dissection photograph reconstruction method without external reference. RefFree is a learning approach that estimates the 3D coordinates in the atlas space for every pixel in every photograph; simple least-squares fitting can then be used to compute the 3D reconstruction. As a by-product, RefFree also produces an atlas-based segmentation of the reconstructed stack. RefFree is trained on synthetic photographs generated from digitally sliced 3D MRI data, with randomized appearance for enhanced generalization ability. Experiments on simulated and real data show that RefFree achieves performance comparable to the baseline method without an explicit reference while also enabling reconstruction of partial stacks. Our code is available at https://github.com/lintian-a/reffree.