 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ConGeo: Robust Cross-view Geo-localization across Ground View Variations
Mar 20, 2024
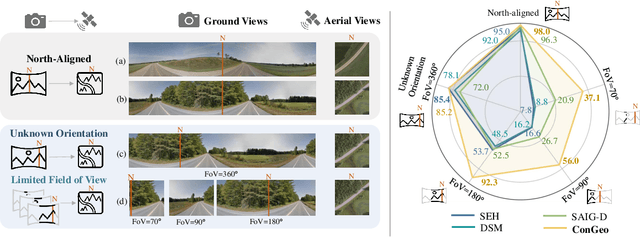

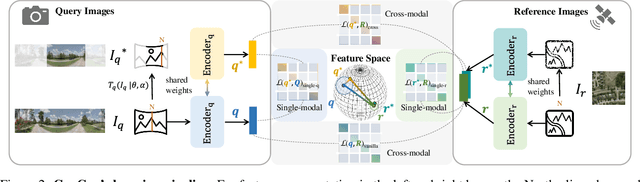
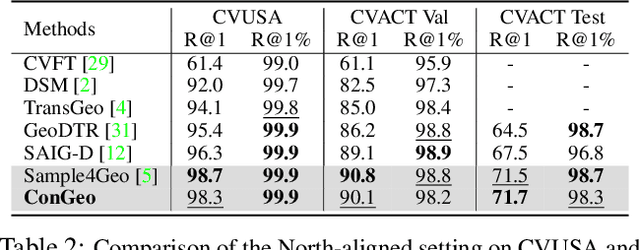
Cross-view geo-localization aims at localizing a ground-level query image by matching it to its corresponding geo-referenced aerial view. In real-world scenarios, the task requires accommodating diverse ground images captured by users with varying orientations and reduced field of views (FoVs). However, existing learning pipelines are orientation-specific or FoV-specific, demanding separate model training for different ground view variations. Such models heavily depend on the North-aligned spatial correspondence and predefined FoVs in the training data, compromising their robustness across different settings. To tackle this challenge, we propose ConGeo, a single- and cross-modal Contrastive method for Geo-localization: it enhances robustness and consistency in feature representations to improve a model's invariance to orientation and its resilience to FoV variations, by enforcing proximity between ground view variations of the same location. As a generic learning objective for cross-view geo-localization, when integrated into state-of-the-art pipelines, ConGeo significantly boosts the performance of three base models on four geo-localization benchmarks for diverse ground view variations and outperforms competing methods that train separate models for each ground view variation.
SPTNet: An Efficient Alternative Framework for Generalized Category Discovery with Spatial Prompt Tuning
Mar 20, 2024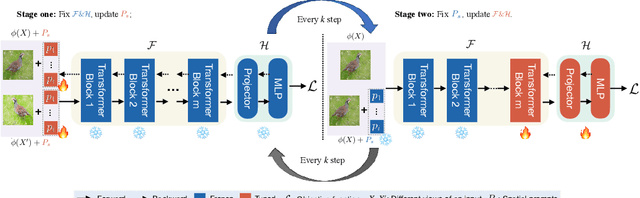
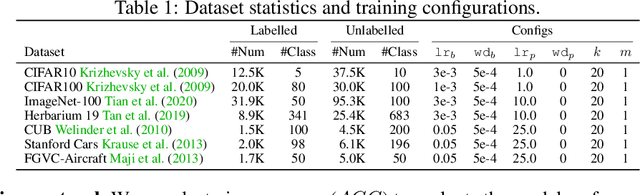
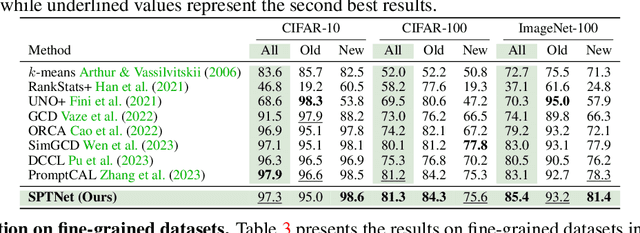
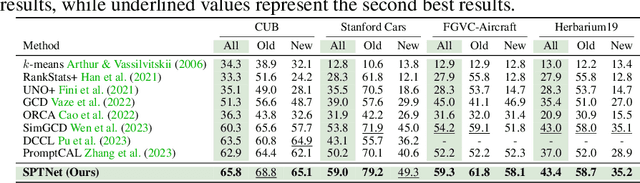
Generalized Category Discovery (GCD) aims to classify unlabelled images from both `seen' and `unseen' classes by transferring knowledge from a set of labelled `seen' class images. A key theme in existing GCD approaches is adapting large-scale pre-trained models for the GCD task. An alternate perspective, however, is to adapt the data representation itself for better alignment with the pre-trained model. As such, in this paper, we introduce a two-stage adaptation approach termed SPTNet, which iteratively optimizes model parameters (i.e., model-finetuning) and data parameters (i.e., prompt learning). Furthermore, we propose a novel spatial prompt tuning method (SPT) which considers the spatial property of image data, enabling the method to better focus on object parts, which can transfer between seen and unseen classes. We thoroughly evaluate our SPTNet on standard benchmarks and demonstrate that our method outperforms existing GCD methods. Notably, we find our method achieves an average accuracy of 61.4% on the SSB, surpassing prior state-of-the-art methods by approximately 10%. The improvement is particularly remarkable as our method yields extra parameters amounting to only 0.117% of those in the backbone architecture. Project page: https://visual-ai.github.io/sptnet.
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 20, 2024
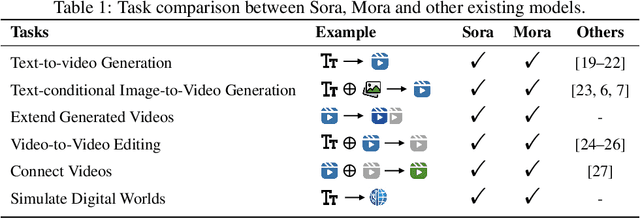
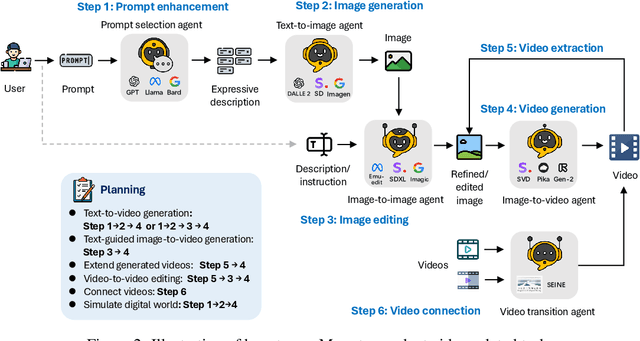
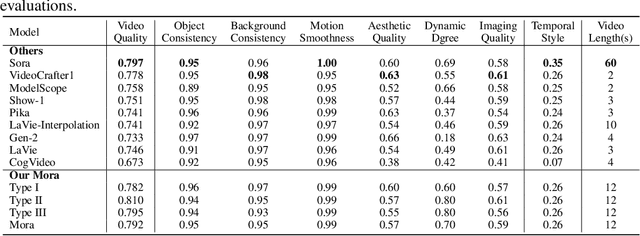
Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
Learning Novel View Synthesis from Heterogeneous Low-light Captures
Mar 20, 2024

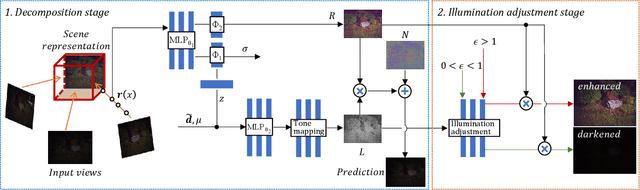
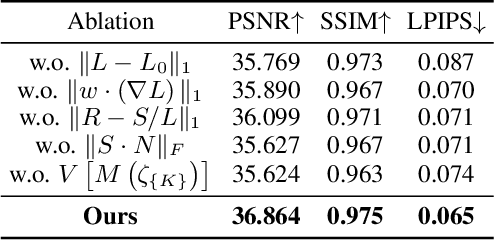
Neural radiance field has achieved fundamental success in novel view synthesis from input views with the same brightness level captured under fixed normal lighting. Unfortunately, synthesizing novel views remains to be a challenge for input views with heterogeneous brightness level captured under low-light condition. The condition is pretty common in the real world. It causes low-contrast images where details are concealed in the darkness and camera sensor noise significantly degrades the image quality. To tackle this problem, we propose to learn to decompose illumination, reflectance, and noise from input views according to that reflectance remains invariant across heterogeneous views. To cope with heterogeneous brightness and noise levels across multi-views, we learn an illumination embedding and optimize a noise map individually for each view. To allow intuitive editing of the illumination, we design an illumination adjustment module to enable either brightening or darkening of the illumination component. Comprehensive experiments demonstrate that this approach enables effective intrinsic decomposition for low-light multi-view noisy images and achieves superior visual quality and numerical performance for synthesizing novel views compared to state-of-the-art methods.
MusicHiFi: Fast High-Fidelity Stereo Vocoding
Mar 20, 2024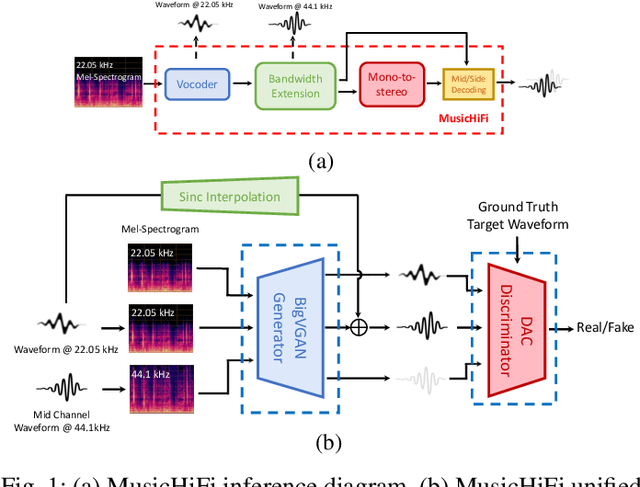
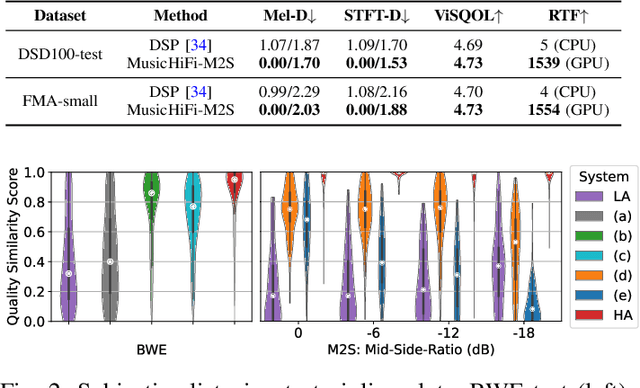
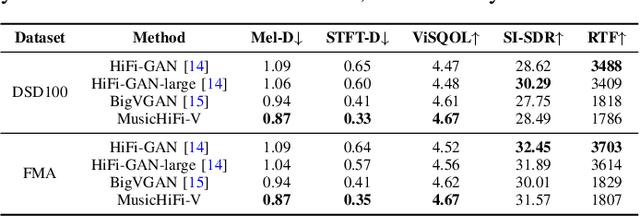
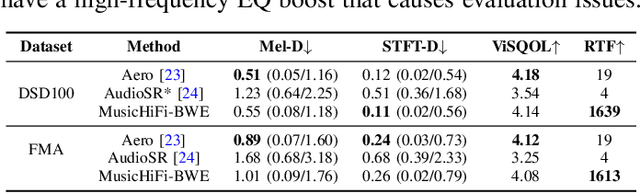
Diffusion-based audio and music generation models commonly generate music by constructing an image representation of audio (e.g., a mel-spectrogram) and then converting it to audio using a phase reconstruction model or vocoder. Typical vocoders, however, produce monophonic audio at lower resolutions (e.g., 16-24 kHz), which limits their effectiveness. We propose MusicHiFi -- an efficient high-fidelity stereophonic vocoder. Our method employs a cascade of three generative adversarial networks (GANs) that convert low-resolution mel-spectrograms to audio, upsamples to high-resolution audio via bandwidth expansion, and upmixes to stereophonic audio. Compared to previous work, we propose 1) a unified GAN-based generator and discriminator architecture and training procedure for each stage of our cascade, 2) a new fast, near downsampling-compatible bandwidth extension module, and 3) a new fast downmix-compatible mono-to-stereo upmixer that ensures the preservation of monophonic content in the output. We evaluate our approach using both objective and subjective listening tests and find our approach yields comparable or better audio quality, better spatialization control, and significantly faster inference speed compared to past work. Sound examples are at https://MusicHiFi.github.io/web/.
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024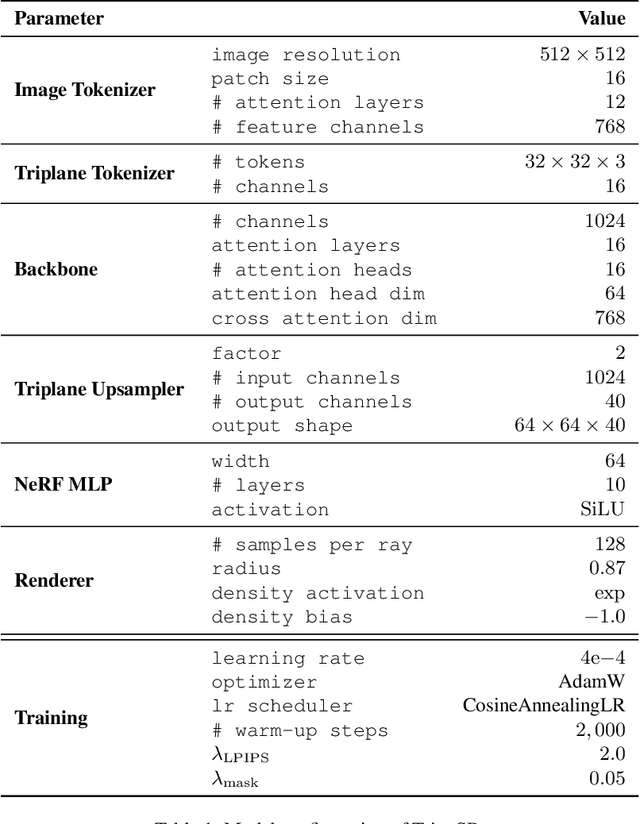
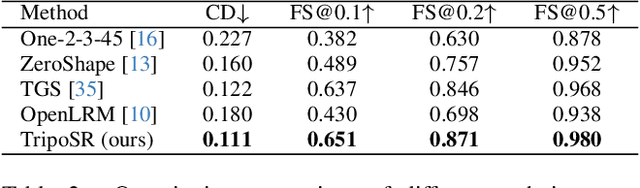
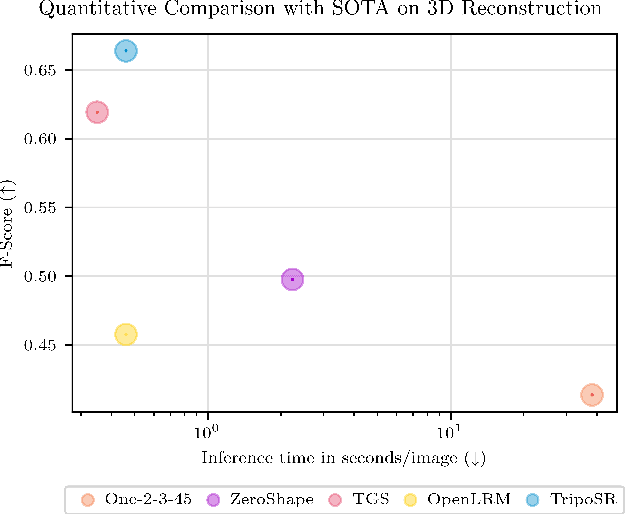
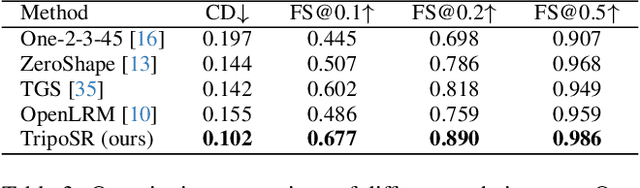
This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
Dual-Context Aggregation for Universal Image Matting
Feb 28, 2024Natural image matting aims to estimate the alpha matte of the foreground from a given image. Various approaches have been explored to address this problem, such as interactive matting methods that use guidance such as click or trimap, and automatic matting methods tailored to specific objects. However, existing matting methods are designed for specific objects or guidance, neglecting the common requirement of aggregating global and local contexts in image matting. As a result, these methods often encounter challenges in accurately identifying the foreground and generating precise boundaries, which limits their effectiveness in unforeseen scenarios. In this paper, we propose a simple and universal matting framework, named Dual-Context Aggregation Matting (DCAM), which enables robust image matting with arbitrary guidance or without guidance. Specifically, DCAM first adopts a semantic backbone network to extract low-level features and context features from the input image and guidance. Then, we introduce a dual-context aggregation network that incorporates global object aggregators and local appearance aggregators to iteratively refine the extracted context features. By performing both global contour segmentation and local boundary refinement, DCAM exhibits robustness to diverse types of guidance and objects. Finally, we adopt a matting decoder network to fuse the low-level features and the refined context features for alpha matte estimation. Experimental results on five matting datasets demonstrate that the proposed DCAM outperforms state-of-the-art matting methods in both automatic matting and interactive matting tasks, which highlights the strong universality and high performance of DCAM. The source code is available at \url{https://github.com/Windaway/DCAM}.
Pooling Image Datasets With Multiple Covariate Shift and Imbalance
Mar 14, 2024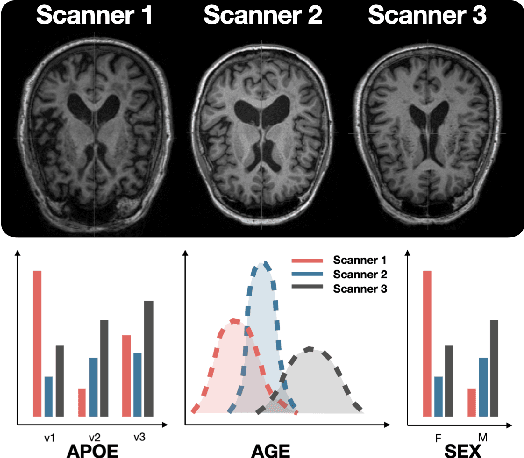
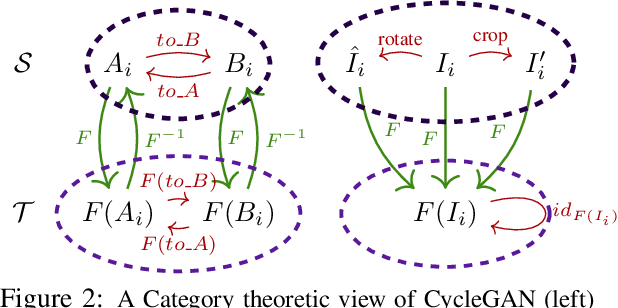
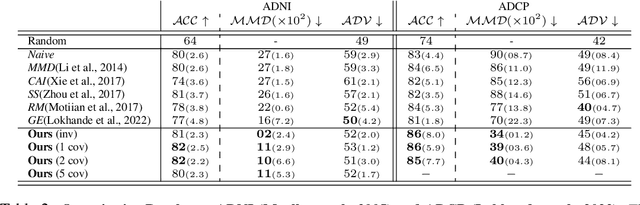
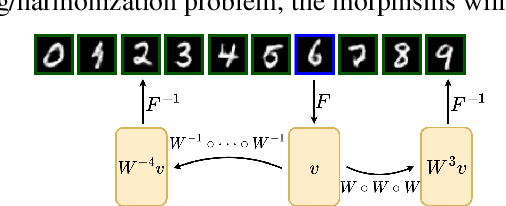
Small sample sizes are common in many disciplines, which necessitates pooling roughly similar datasets across multiple institutions to study weak but relevant associations between images and disease outcomes. Such data often manifest shift/imbalance in covariates (i.e., secondary non-imaging data). Controlling for such nuisance variables is common within standard statistical analysis, but the ideas do not directly apply to overparameterized models. Consequently, recent work has shown how strategies from invariant representation learning provides a meaningful starting point, but the current repertoire of methods is limited to accounting for shifts/imbalances in just a couple of covariates at a time. In this paper, we show how viewing this problem from the perspective of Category theory provides a simple and effective solution that completely avoids elaborate multi-stage training pipelines that would otherwise be needed. We show the effectiveness of this approach via extensive experiments on real datasets. Further, we discuss how this style of formulation offers a unified perspective on at least 5+ distinct problem settings, from self-supervised learning to matching problems in 3D reconstruction.
Entity6K: A Large Open-Domain Evaluation Dataset for Real-World Entity Recognition
Mar 19, 2024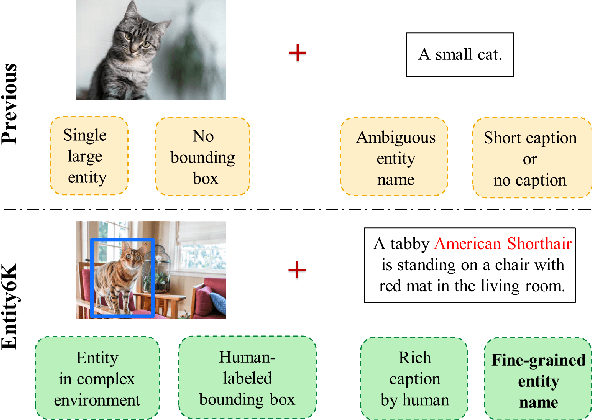
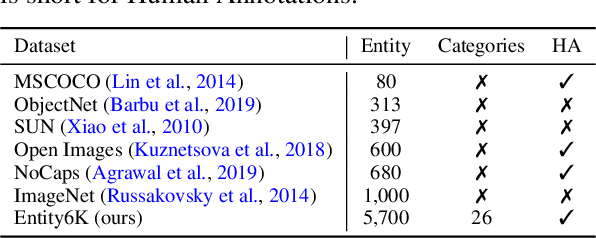

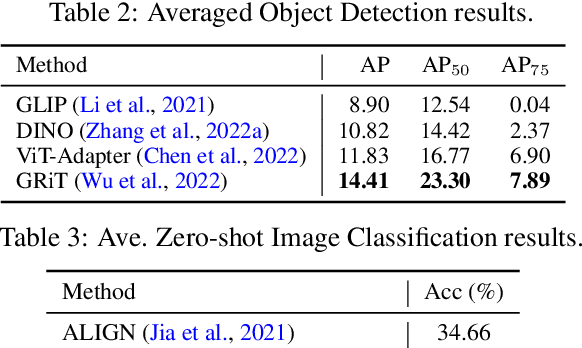
Open-domain real-world entity recognition is essential yet challenging, involving identifying various entities in diverse environments. The lack of a suitable evaluation dataset has been a major obstacle in this field due to the vast number of entities and the extensive human effort required for data curation. We introduce Entity6K, a comprehensive dataset for real-world entity recognition, featuring 5,700 entities across 26 categories, each supported by 5 human-verified images with annotations. Entity6K offers a diverse range of entity names and categorizations, addressing a gap in existing datasets. We conducted benchmarks with existing models on tasks like image captioning, object detection, zero-shot classification, and dense captioning to demonstrate Entity6K's effectiveness in evaluating models' entity recognition capabilities. We believe Entity6K will be a valuable resource for advancing accurate entity recognition in open-domain settings.
Knowing Your Nonlinearities: Shapley Interactions Reveal the Underlying Structure of Data
Mar 19, 2024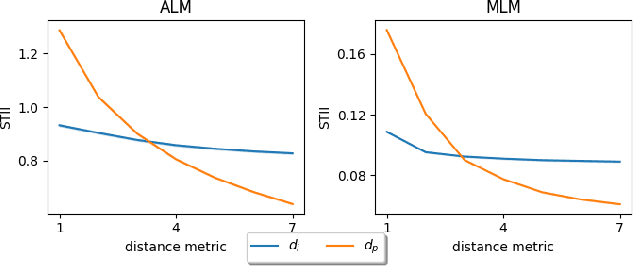
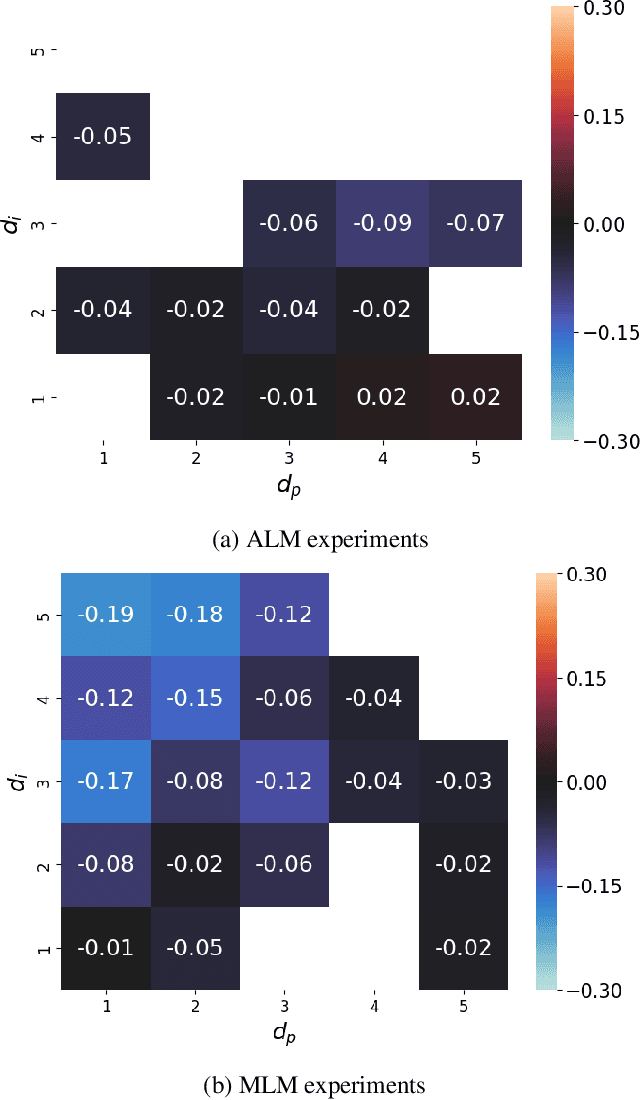
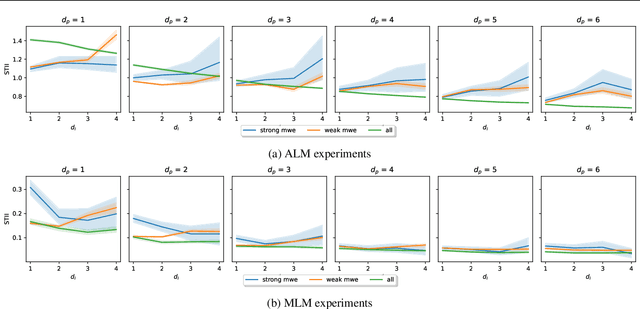
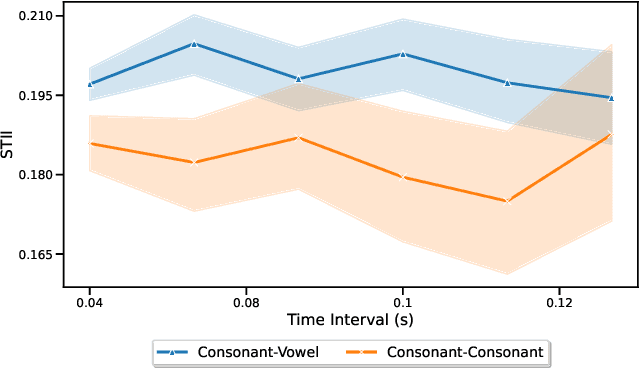
Measuring nonlinear feature interaction is an established approach to understanding complex patterns of attribution in many models. In this paper, we use Shapley Taylor interaction indices (STII) to analyze the impact of underlying data structure on model representations in a variety of modalities, tasks, and architectures. Considering linguistic structure in masked and auto-regressive language models (MLMs and ALMs), we find that STII increases within idiomatic expressions and that MLMs scale STII with syntactic distance, relying more on syntax in their nonlinear structure than ALMs do. Our speech model findings reflect the phonetic principal that the openness of the oral cavity determines how much a phoneme varies based on its context. Finally, we study image classifiers and illustrate that feature interactions intuitively reflect object boundaries. Our wide range of results illustrates the benefits of interdisciplinary work and domain expertise in interpretability research.