 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Uncertainty estimation in Deep Learning for Panoptic segmentation
Apr 04, 2023
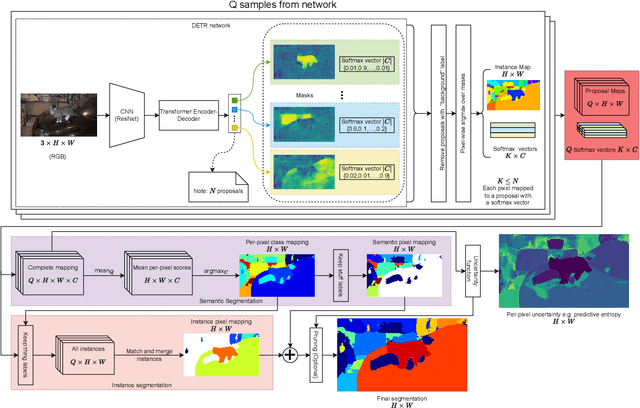
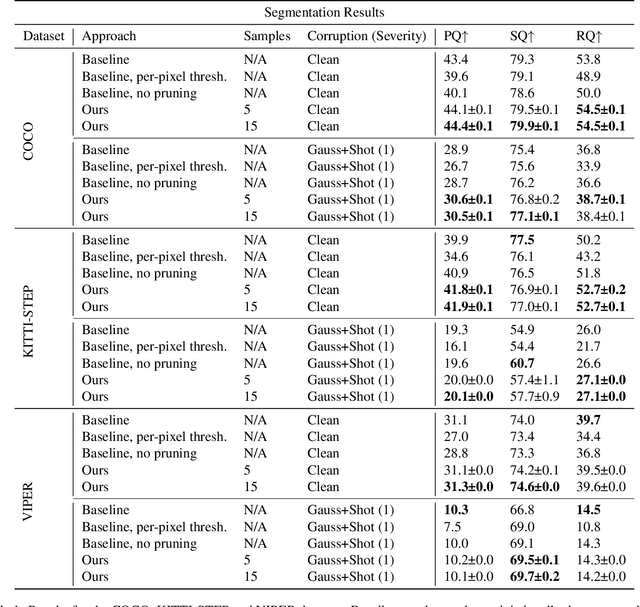
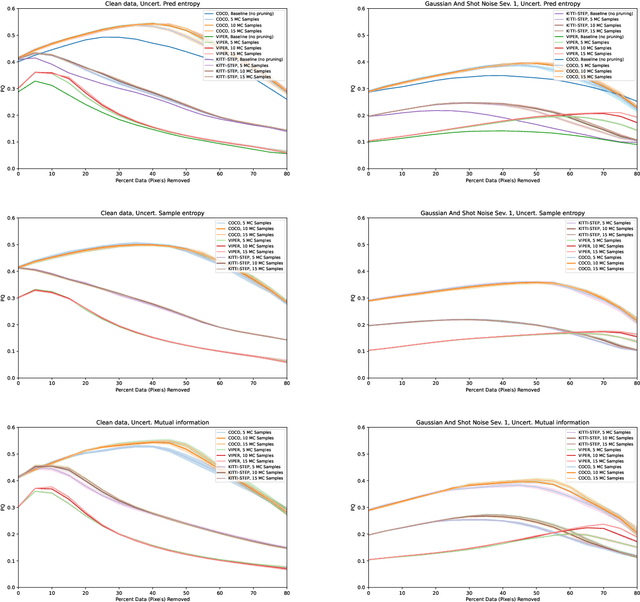
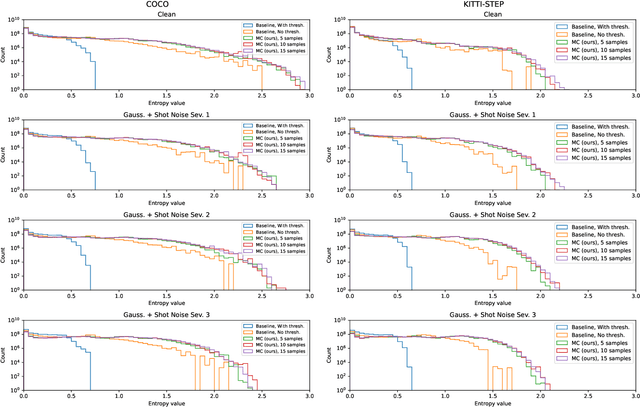
As deep learning-based computer vision algorithms continue to improve and advance the state of the art, their robustness to real-world data continues to lag their performance on datasets. This makes it difficult to bring an algorithm from the lab to the real world. Ensemble-based uncertainty estimation approaches such as Monte Carlo Dropout have been successfully used in many applications in an attempt to address this robustness issue. Unfortunately, it is not always clear if such ensemble-based approaches can be applied to a new problem domain. This is the case with panoptic segmentation, where the structure of the problem and architectures designed to solve it means that unlike image classification or even semantic segmentation, the typical solution of using a mean across samples cannot be directly applied. In this paper, we demonstrate how ensemble-based uncertainty estimation approaches such as Monte Carlo Dropout can be used in the panoptic segmentation domain with no changes to an existing network, providing both improved performance and more importantly a better measure of uncertainty for predictions made by the network. Results are demonstrated quantitatively and qualitatively on the COCO, KITTI-STEP and VIPER datasets.
From Isolated Islands to Pangea: Unifying Semantic Space for Human Action Understanding
Apr 04, 2023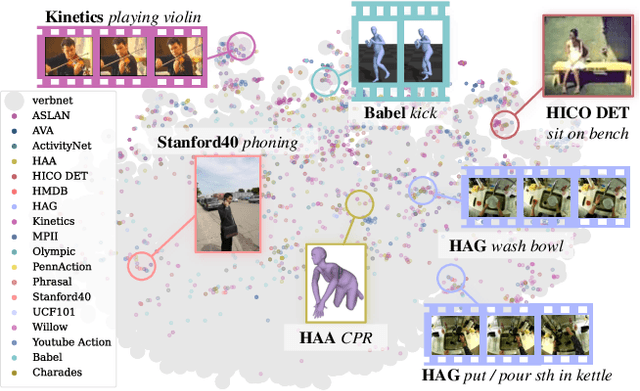
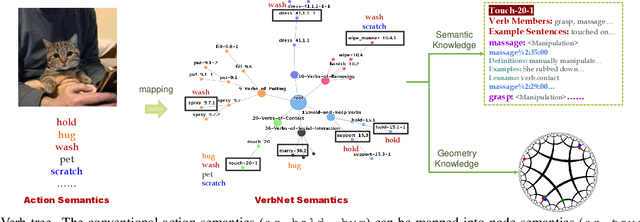
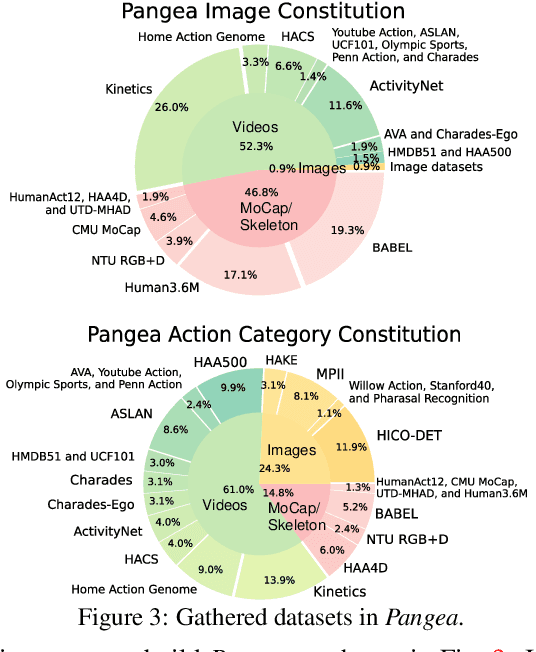
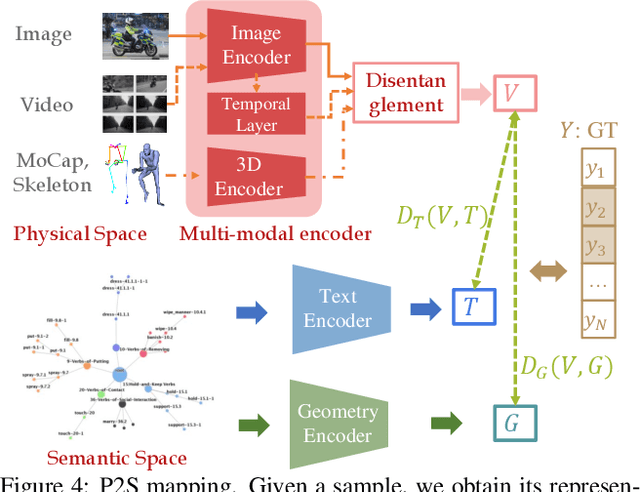
Action understanding matters and attracts attention. It can be formed as the mapping from the action physical space to the semantic space. Typically, researchers built action datasets according to idiosyncratic choices to define classes and push the envelope of benchmarks respectively. Thus, datasets are incompatible with each other like "Isolated Islands" due to semantic gaps and various class granularities, e.g., do housework in dataset A and wash plate in dataset B. We argue that a more principled semantic space is an urgent need to concentrate the community efforts and enable us to use all datasets together to pursue generalizable action learning. To this end, we design a Poincare action semantic space given verb taxonomy hierarchy and covering massive actions. By aligning the classes of previous datasets to our semantic space, we gather (image/video/skeleton/MoCap) datasets into a unified database in a unified label system, i.e., bridging "isolated islands" into a "Pangea". Accordingly, we propose a bidirectional mapping model between physical and semantic space to fully use Pangea. In extensive experiments, our system shows significant superiority, especially in transfer learning. Code and data will be made publicly available.
Mimic3D: Thriving 3D-Aware GANs via 3D-to-2D Imitation
Mar 16, 2023
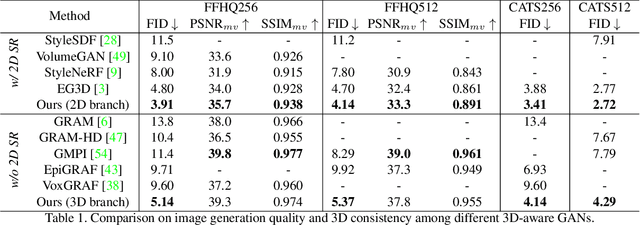


Generating images with both photorealism and multiview 3D consistency is crucial for 3D-aware GANs, yet existing methods struggle to achieve them simultaneously. Improving the photorealism via CNN-based 2D super-resolution can break the strict 3D consistency, while keeping the 3D consistency by learning high-resolution 3D representations for direct rendering often compromises image quality. In this paper, we propose a novel learning strategy, namely 3D-to-2D imitation, which enables a 3D-aware GAN to generate high-quality images while maintaining their strict 3D consistency, by letting the images synthesized by the generator's 3D rendering branch to mimic those generated by its 2D super-resolution branch. We also introduce 3D-aware convolutions into the generator for better 3D representation learning, which further improves the image generation quality. With the above strategies, our method reaches FID scores of 5.4 and 4.3 on FFHQ and AFHQ-v2 Cats, respectively, at 512x512 resolution, largely outperforming existing 3D-aware GANs using direct 3D rendering and coming very close to the previous state-of-the-art method that leverages 2D super-resolution. Project website: https://seanchenxy.github.io/Mimic3DWeb.
Polarity is all you need to learn and transfer faster
Mar 29, 2023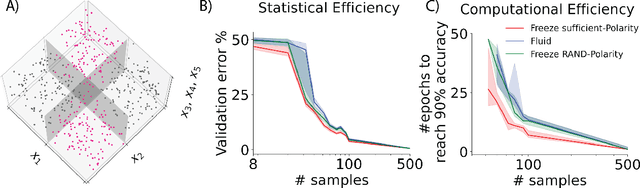
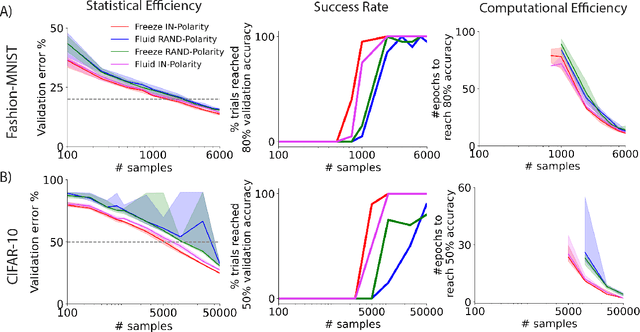
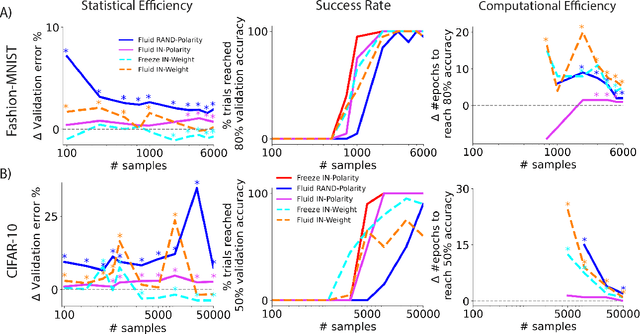
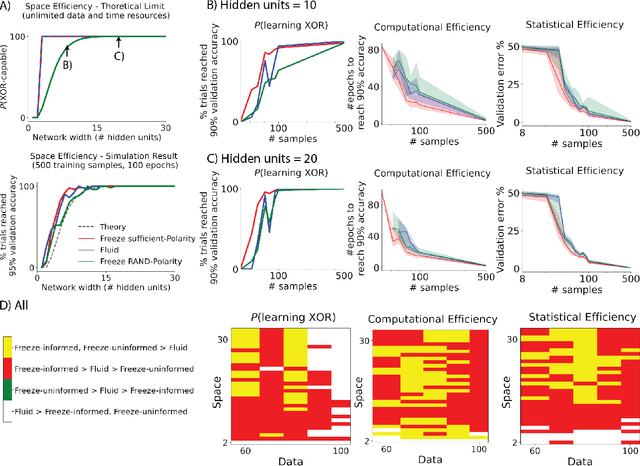
Natural intelligences (NIs) thrive in a dynamic world - they learn quickly, sometimes with only a few samples. In contrast, Artificial intelligences (AIs) typically learn with prohibitive amount of training samples and computational power. What design principle difference between NI and AI could contribute to such a discrepancy? Here, we propose an angle from weight polarity: development processes initialize NIs with advantageous polarity configurations; as NIs grow and learn, synapse magnitudes update yet polarities are largely kept unchanged. We demonstrate with simulation and image classification tasks that if weight polarities are adequately set $\textit{a priori}$, then networks learn with less time and data. We also explicitly illustrate situations in which $\textit{a priori}$ setting the weight polarities is disadvantageous for networks. Our work illustrates the value of weight polarities from the perspective of statistical and computational efficiency during learning.
Enhancing Depth Completion with Multi-View Monitored Distillation
Mar 29, 2023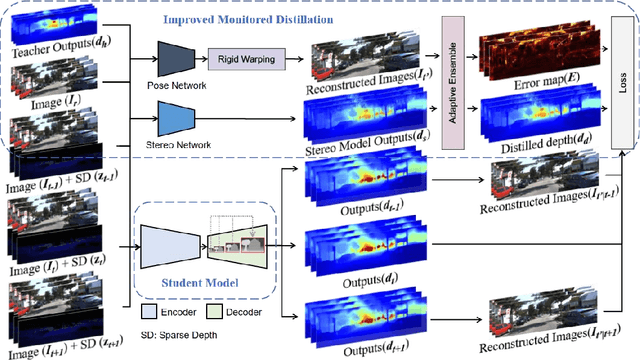
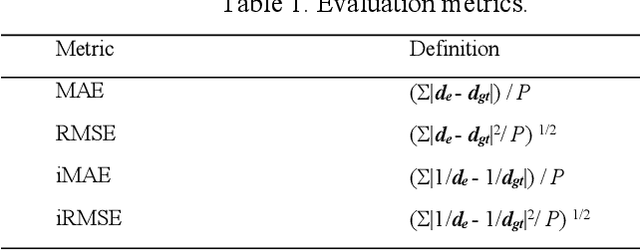
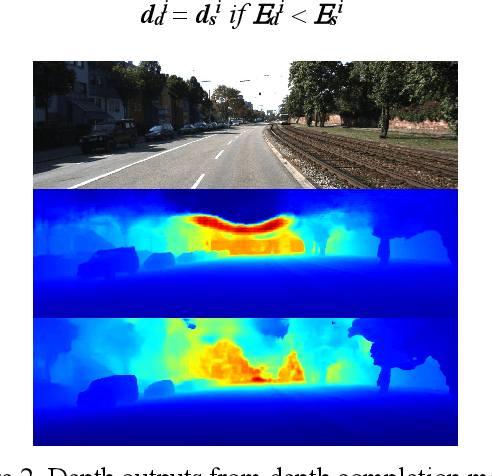
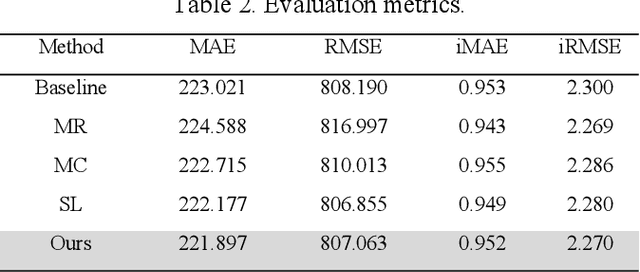
This paper presents a novel method for depth completion, which leverages multi-view improved monitored distillation to generate more precise depth maps. Our approach builds upon the state-of-the-art ensemble distillation method, in which we introduce a stereo-based model as a teacher model to improve the accuracy of the student model for depth completion. By minimizing the reconstruction error for a given image during ensemble distillation, we can avoid learning inherent error modes of completion-based teachers. To provide self-supervised information, we also employ multi-view depth consistency and multi-scale minimum reprojection. These techniques utilize existing structural constraints to yield supervised signals for student model training, without requiring costly ground truth depth information. Our extensive experimental evaluation demonstrates that our proposed method significantly improves the accuracy of the baseline monitored distillation method.
Point2Pix: Photo-Realistic Point Cloud Rendering via Neural Radiance Fields
Mar 29, 2023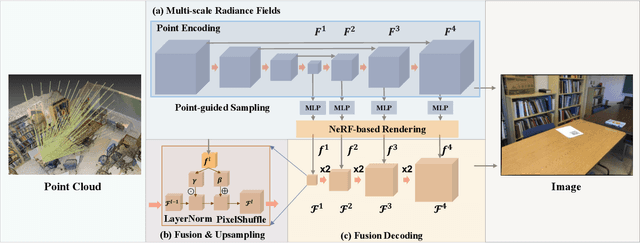
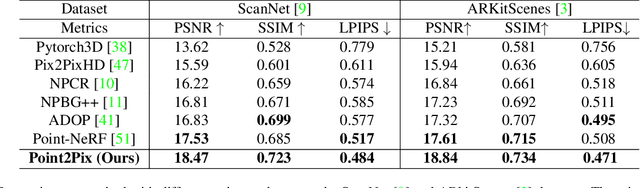
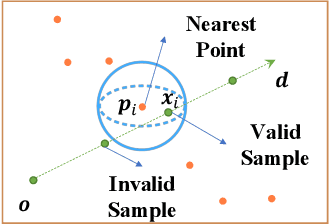
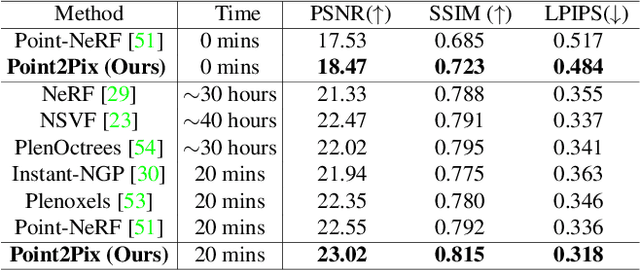
Synthesizing photo-realistic images from a point cloud is challenging because of the sparsity of point cloud representation. Recent Neural Radiance Fields and extensions are proposed to synthesize realistic images from 2D input. In this paper, we present Point2Pix as a novel point renderer to link the 3D sparse point clouds with 2D dense image pixels. Taking advantage of the point cloud 3D prior and NeRF rendering pipeline, our method can synthesize high-quality images from colored point clouds, generally for novel indoor scenes. To improve the efficiency of ray sampling, we propose point-guided sampling, which focuses on valid samples. Also, we present Point Encoding to build Multi-scale Radiance Fields that provide discriminative 3D point features. Finally, we propose Fusion Encoding to efficiently synthesize high-quality images. Extensive experiments on the ScanNet and ArkitScenes datasets demonstrate the effectiveness and generalization.
OPDMulti: Openable Part Detection for Multiple Objects
Mar 24, 2023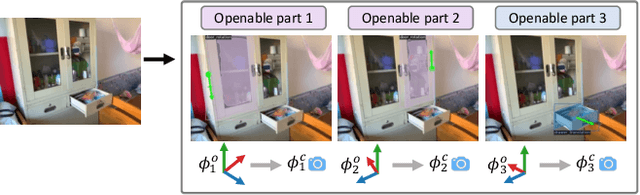
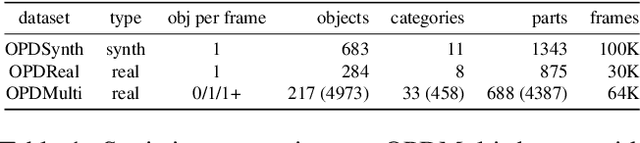

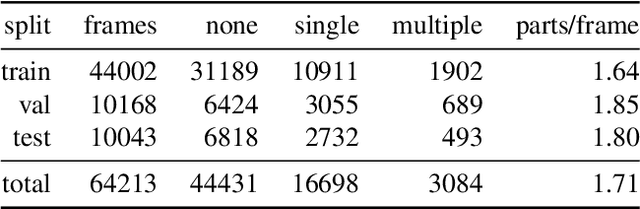
Openable part detection is the task of detecting the openable parts of an object in a single-view image, and predicting corresponding motion parameters. Prior work investigated the unrealistic setting where all input images only contain a single openable object. We generalize this task to scenes with multiple objects each potentially possessing openable parts, and create a corresponding dataset based on real-world scenes. We then address this more challenging scenario with OPDFormer: a part-aware transformer architecture. Our experiments show that the OPDFormer architecture significantly outperforms prior work. The more realistic multiple-object scenarios we investigated remain challenging for all methods, indicating opportunities for future work.
Sequential Recommendation with Diffusion Models
Apr 10, 2023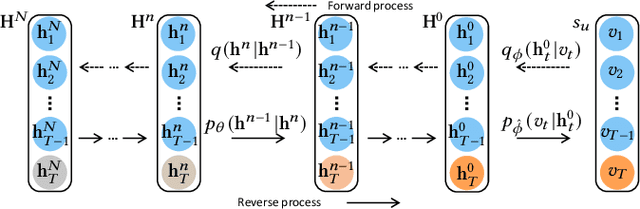
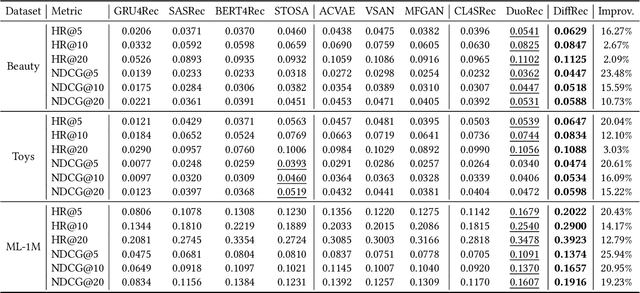

Generative models, such as Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN), have been successfully applied in sequential recommendation. These methods require sampling from probability distributions and adopt auxiliary loss functions to optimize the model, which can capture the uncertainty of user behaviors and alleviate exposure bias. However, existing generative models still suffer from the posterior collapse problem or the model collapse problem, thus limiting their applications in sequential recommendation. To tackle the challenges mentioned above, we leverage a new paradigm of the generative models, i.e., diffusion models, and present sequential recommendation with diffusion models (DiffRec), which can avoid the issues of VAE- and GAN-based models and show better performance. While diffusion models are originally proposed to process continuous image data, we design an additional transition in the forward process together with a transition in the reverse process to enable the processing of the discrete recommendation data. We also design a different noising strategy that only noises the target item instead of the whole sequence, which is more suitable for sequential recommendation. Based on the modified diffusion process, we derive the objective function of our framework using a simplification technique and design a denoise sequential recommender to fulfill the objective function. As the lengthened diffusion steps substantially increase the time complexity, we propose an efficient training strategy and an efficient inference strategy to reduce training and inference cost and improve recommendation diversity. Extensive experiment results on three public benchmark datasets verify the effectiveness of our approach and show that DiffRec outperforms the state-of-the-art sequential recommendation models.
DRIP: Deep Regularizers for Inverse Problems
Mar 30, 2023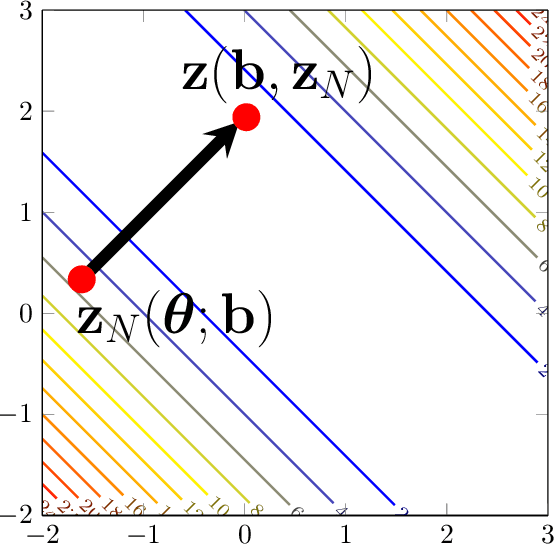
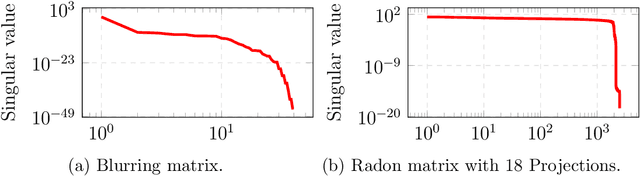

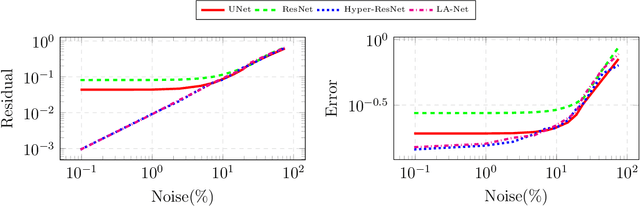
Inverse problems are mathematically ill-posed. Thus, given some (noisy) data, there is more than one solution that fits the data. In recent years, deep neural techniques that find the most appropriate solution, in the sense that it contains a-priori information, were developed. However, they suffer from several shortcomings. First, most techniques cannot guarantee that the solution fits the data at inference. Second, while the derivation of the techniques is inspired by the existence of a valid scalar regularization function, such techniques do not in practice rely on such a function, and therefore veer away from classical variational techniques. In this work we introduce a new family of neural regularizers for the solution of inverse problems. These regularizers are based on a variational formulation and are guaranteed to fit the data. We demonstrate their use on a number of highly ill-posed problems, from image deblurring to limited angle tomography.
Unlocking Layer-wise Relevance Propagation for Autoencoders
Mar 21, 2023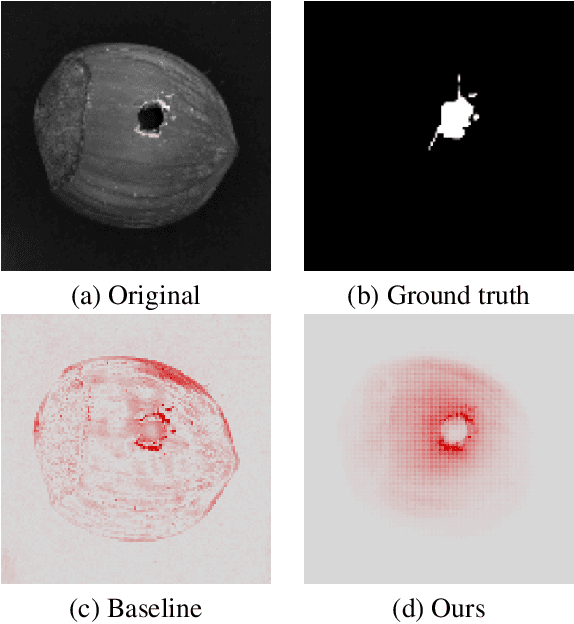
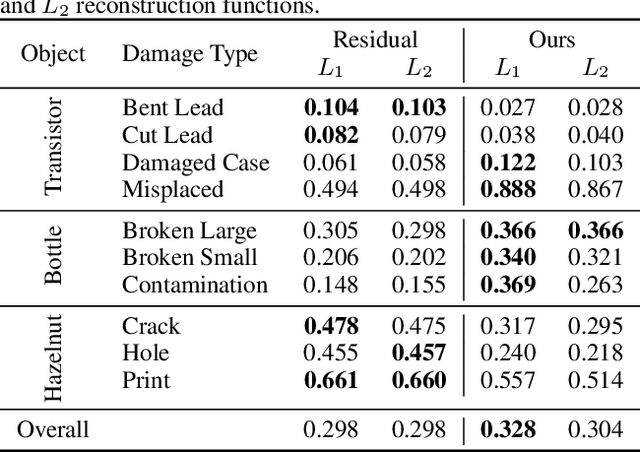
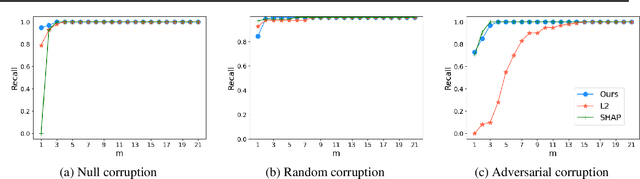
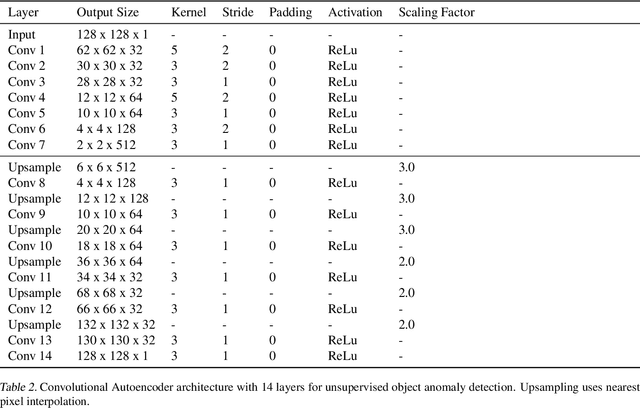
Autoencoders are a powerful and versatile tool often used for various problems such as anomaly detection, image processing and machine translation. However, their reconstructions are not always trivial to explain. Therefore, we propose a fast explainability solution by extending the Layer-wise Relevance Propagation method with the help of Deep Taylor Decomposition framework. Furthermore, we introduce a novel validation technique for comparing our explainability approach with baseline methods in the case of missing ground-truth data. Our results highlight computational as well as qualitative advantages of the proposed explainability solution with respect to existing methods.