 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarity is all you need to learn and transfer faster
Mar 29, 2023Natural intelligences (NIs) thrive in a dynamic world - they learn quickly, sometimes with only a few samples. In contrast, Artificial intelligences (AIs) typically learn with prohibitive amount of training samples and computational power. What design principle difference between NI and AI could contribute to such a discrepancy? Here, we propose an angle from weight polarity: development processes initialize NIs with advantageous polarity configurations; as NIs grow and learn, synapse magnitudes update yet polarities are largely kept unchanged. We demonstrate with simulation and image classification tasks that if weight polarities are adequately set $\textit{a priori}$, then networks learn with less time and data. We also explicitly illustrate situations in which $\textit{a priori}$ setting the weight polarities is disadvantageous for networks. Our work illustrates the value of weight polarities from the perspective of statistical and computational efficiency during learning.
Why Do Networks Need Negative Weights?
Aug 05, 2022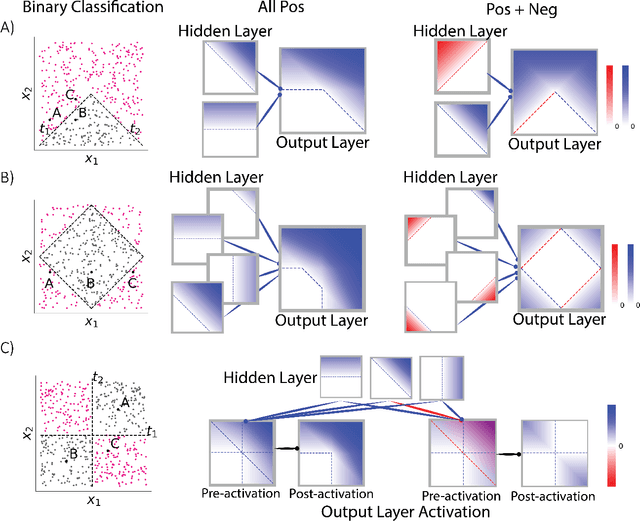
Why do networks have negative weights at all? The answer is: to learn more functions. We mathematically prove that deep neural networks with all non-negative weights are not universal approximators. This fundamental result is assumed by much of the deep learning literature without previously proving the result and demonstrating its necessity.