 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch-Discontinuity Mining for Generalized Deepfake Detection
Dec 26, 2025The rapid advancement of generative artificial intelligence has enabled the creation of highly realistic fake facial images, posing serious threats to personal privacy and the integrity of online information. Existing deepfake detection methods often rely on handcrafted forensic cues and complex architectures, achieving strong performance in intra-domain settings but suffering significant degradation when confronted with unseen forgery patterns. In this paper, we propose GenDF, a simple yet effective framework that transfers a powerful large-scale vision model to the deepfake detection task with a compact and neat network design. GenDF incorporates deepfake-specific representation learning to capture discriminative patterns between real and fake facial images, feature space redistribution to mitigate distribution mismatch, and a classification-invariant feature augmentation strategy to enhance generalization without introducing additional trainable parameters. Extensive experiments demonstrate that GenDF achieves state-of-the-art generalization performance in cross-domain and cross-manipulation settings while requiring only 0.28M trainable parameters, validating the effectiveness and efficiency of the proposed framework.
How Do Graph Signals Affect Recommendation: Unveiling the Mystery of Low and High-Frequency Graph Signals
Dec 10, 2025



Spectral graph neural networks (GNNs) are highly effective in modeling graph signals, with their success in recommendation often attributed to low-pass filtering. However, recent studies highlight the importance of high-frequency signals. The role of low-frequency and high-frequency graph signals in recommendation remains unclear. This paper aims to bridge this gap by investigating the influence of graph signals on recommendation performance. We theoretically prove that the effects of low-frequency and high-frequency graph signals are equivalent in recommendation tasks, as both contribute by smoothing the similarities between user-item pairs. To leverage this insight, we propose a frequency signal scaler, a plug-and-play module that adjusts the graph signal filter function to fine-tune the smoothness between user-item pairs, making it compatible with any GNN model. Additionally, we identify and prove that graph embedding-based methods cannot fully capture the characteristics of graph signals. To address this limitation, a space flip method is introduced to restore the expressive power of graph embeddings. Remarkably, we demonstrate that either low-frequency or high-frequency graph signals alone are sufficient for effective recommendations. Extensive experiments on four public datasets validate the effectiveness of our proposed methods. Code is avaliable at https://github.com/mojosey/SimGCF.
Wavelet Enhanced Adaptive Frequency Filter for Sequential Recommendation
Nov 10, 2025



Sequential recommendation has garnered significant attention for its ability to capture dynamic preferences by mining users' historical interaction data. Given that users' complex and intertwined periodic preferences are difficult to disentangle in the time domain, recent research is exploring frequency domain analysis to identify these hidden patterns. However, current frequency-domain-based methods suffer from two key limitations: (i) They primarily employ static filters with fixed characteristics, overlooking the personalized nature of behavioral patterns; (ii) While the global discrete Fourier transform excels at modeling long-range dependencies, it can blur non-stationary signals and short-term fluctuations. To overcome these limitations, we propose a novel method called Wavelet Enhanced Adaptive Frequency Filter for Sequential Recommendation. Specifically, it consists of two vital modules: dynamic frequency-domain filtering and wavelet feature enhancement. The former is used to dynamically adjust filtering operations based on behavioral sequences to extract personalized global information, and the latter integrates wavelet transform to reconstruct sequences, enhancing blurred non-stationary signals and short-term fluctuations. Finally, these two modules work to achieve comprehensive performance and efficiency optimization in long sequential recommendation scenarios. Extensive experiments on four widely-used benchmark datasets demonstrate the superiority of our work.
Intent Contrastive Learning with Cross Subsequences for Sequential Recommendation
Oct 31, 2023



The user purchase behaviors are mainly influenced by their intentions (e.g., buying clothes for decoration, buying brushes for painting, etc.). Modeling a user's latent intention can significantly improve the performance of recommendations. Previous works model users' intentions by considering the predefined label in auxiliary information or introducing stochastic data augmentation to learn purposes in the latent space. However, the auxiliary information is sparse and not always available for recommender systems, and introducing stochastic data augmentation may introduce noise and thus change the intentions hidden in the sequence. Therefore, leveraging user intentions for sequential recommendation (SR) can be challenging because they are frequently varied and unobserved. In this paper, Intent contrastive learning with Cross Subsequences for sequential Recommendation (ICSRec) is proposed to model users' latent intentions. Specifically, ICSRec first segments a user's sequential behaviors into multiple subsequences by using a dynamic sliding operation and takes these subsequences into the encoder to generate the representations for the user's intentions. To tackle the problem of no explicit labels for purposes, ICSRec assumes different subsequences with the same target item may represent the same intention and proposes a coarse-grain intent contrastive learning to push these subsequences closer. Then, fine-grain intent contrastive learning is mentioned to capture the fine-grain intentions of subsequences in sequential behaviors. Extensive experiments conducted on four real-world datasets demonstrate the superior performance of the proposed ICSRec model compared with baseline methods.
Contrastive Enhanced Slide Filter Mixer for Sequential Recommendation
May 07, 2023



Sequential recommendation (SR) aims to model user preferences by capturing behavior patterns from their item historical interaction data. Most existing methods model user preference in the time domain, omitting the fact that users' behaviors are also influenced by various frequency patterns that are difficult to separate in the entangled chronological items. However, few attempts have been made to train SR in the frequency domain, and it is still unclear how to use the frequency components to learn an appropriate representation for the user. To solve this problem, we shift the viewpoint to the frequency domain and propose a novel Contrastive Enhanced \textbf{SLI}de Filter \textbf{M}ixEr for Sequential \textbf{Rec}ommendation, named \textbf{SLIME4Rec}. Specifically, we design a frequency ramp structure to allow the learnable filter slide on the frequency spectrums across different layers to capture different frequency patterns. Moreover, a Dynamic Frequency Selection (DFS) and a Static Frequency Split (SFS) module are proposed to replace the self-attention module for effectively extracting frequency information in two ways. DFS is used to select helpful frequency components dynamically, and SFS is combined with the dynamic frequency selection module to provide a more fine-grained frequency division. Finally, contrastive learning is utilized to improve the quality of user embedding learned from the frequency domain. Extensive experiments conducted on five widely used benchmark datasets demonstrate our proposed model performs significantly better than the state-of-the-art approaches. Our code is available at https://github.com/sudaada/SLIME4Rec.
Ensemble Modeling with Contrastive Knowledge Distillation for Sequential Recommendation
May 04, 2023



Sequential recommendation aims to capture users' dynamic interest and predicts the next item of users' preference. Most sequential recommendation methods use a deep neural network as sequence encoder to generate user and item representations. Existing works mainly center upon designing a stronger sequence encoder. However, few attempts have been made with training an ensemble of networks as sequence encoders, which is more powerful than a single network because an ensemble of parallel networks can yield diverse prediction results and hence better accuracy. In this paper, we present Ensemble Modeling with contrastive Knowledge Distillation for sequential recommendation (EMKD). Our framework adopts multiple parallel networks as an ensemble of sequence encoders and recommends items based on the output distributions of all these networks. To facilitate knowledge transfer between parallel networks, we propose a novel contrastive knowledge distillation approach, which performs knowledge transfer from the representation level via Intra-network Contrastive Learning (ICL) and Cross-network Contrastive Learning (CCL), as well as Knowledge Distillation (KD) from the logits level via minimizing the Kullback-Leibler divergence between the output distributions of the teacher network and the student network. To leverage contextual information, we train the primary masked item prediction task alongside the auxiliary attribute prediction task as a multi-task learning scheme. Extensive experiments on public benchmark datasets show that EMKD achieves a significant improvement compared with the state-of-the-art methods. Besides, we demonstrate that our ensemble method is a generalized approach that can also improve the performance of other sequential recommenders. Our code is available at this link: https://github.com/hw-du/EMKD.
Meta-optimized Contrastive Learning for Sequential Recommendation
Apr 26, 2023Contrastive Learning (CL) performances as a rising approach to address the challenge of sparse and noisy recommendation data. Although having achieved promising results, most existing CL methods only perform either hand-crafted data or model augmentation for generating contrastive pairs to find a proper augmentation operation for different datasets, which makes the model hard to generalize. Additionally, since insufficient input data may lead the encoder to learn collapsed embeddings, these CL methods expect a relatively large number of training data (e.g., large batch size or memory bank) to contrast. However, not all contrastive pairs are always informative and discriminative enough for the training processing. Therefore, a more general CL-based recommendation model called Meta-optimized Contrastive Learning for sequential Recommendation (MCLRec) is proposed in this work. By applying both data augmentation and learnable model augmentation operations, this work innovates the standard CL framework by contrasting data and model augmented views for adaptively capturing the informative features hidden in stochastic data augmentation. Moreover, MCLRec utilizes a meta-learning manner to guide the updating of the model augmenters, which helps to improve the quality of contrastive pairs without enlarging the amount of input data. Finally, a contrastive regularization term is considered to encourage the augmentation model to generate more informative augmented views and avoid too similar contrastive pairs within the meta updating. The experimental results on commonly used datasets validate the effectiveness of MCLRec.
Sequential Recommendation with Probabilistic Logical Reasoning
Apr 22, 2023



Deep learning and symbolic learning are two frequently employed methods in Sequential Recommendation (SR). Recent neural-symbolic SR models demonstrate their potential to enable SR to be equipped with concurrent perception and cognition capacities. However, neural-symbolic SR remains a challenging problem due to open issues like representing users and items in logical reasoning. In this paper, we combine the Deep Neural Network (DNN) SR models with logical reasoning and propose a general framework named Sequential Recommendation with Probabilistic Logical Reasoning (short for SR-PLR). This framework allows SR-PLR to benefit from both similarity matching and logical reasoning by disentangling feature embedding and logic embedding in the DNN and probabilistic logic network. To better capture the uncertainty and evolution of user tastes, SR-PLR embeds users and items with a probabilistic method and conducts probabilistic logical reasoning on users' interaction patterns. Then the feature and logic representations learned from the DNN and logic network are concatenated to make the prediction. Finally, experiments on various sequential recommendation models demonstrate the effectiveness of the SR-PLR.
Frequency Enhanced Hybrid Attention Network for Sequential Recommendation
Apr 18, 2023



The self-attention mechanism, which equips with a strong capability of modeling long-range dependencies, is one of the extensively used techniques in the sequential recommendation field. However, many recent studies represent that current self-attention based models are low-pass filters and are inadequate to capture high-frequency information. Furthermore, since the items in the user behaviors are intertwined with each other, these models are incomplete to distinguish the inherent periodicity obscured in the time domain. In this work, we shift the perspective to the frequency domain, and propose a novel Frequency Enhanced Hybrid Attention Network for Sequential Recommendation, namely FEARec. In this model, we firstly improve the original time domain self-attention in the frequency domain with a ramp structure to make both low-frequency and high-frequency information could be explicitly learned in our approach. Moreover, we additionally design a similar attention mechanism via auto-correlation in the frequency domain to capture the periodic characteristics and fuse the time and frequency level attention in a union model. Finally, both contrastive learning and frequency regularization are utilized to ensure that multiple views are aligned in both the time domain and frequency domain. Extensive experiments conducted on four widely used benchmark datasets demonstrate that the proposed model performs significantly better than the state-of-the-art approaches.
Sequential Recommendation with Diffusion Models
Apr 10, 2023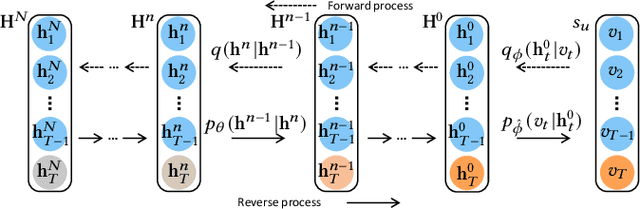
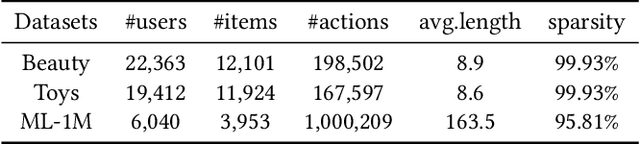
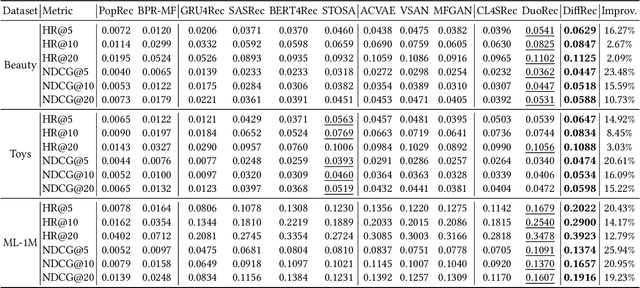
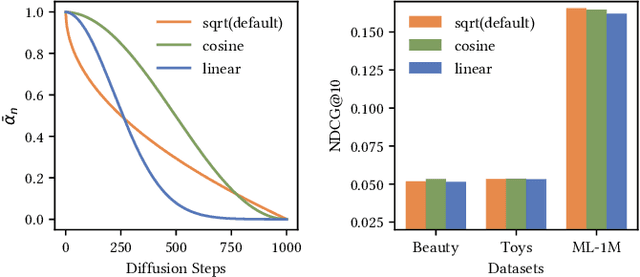
Generative models, such as Variational Auto-Encoder (VAE) and Generative Adversarial Network (GAN), have been successfully applied in sequential recommendation. These methods require sampling from probability distributions and adopt auxiliary loss functions to optimize the model, which can capture the uncertainty of user behaviors and alleviate exposure bias. However, existing generative models still suffer from the posterior collapse problem or the model collapse problem, thus limiting their applications in sequential recommendation. To tackle the challenges mentioned above, we leverage a new paradigm of the generative models, i.e., diffusion models, and present sequential recommendation with diffusion models (DiffRec), which can avoid the issues of VAE- and GAN-based models and show better performance. While diffusion models are originally proposed to process continuous image data, we design an additional transition in the forward process together with a transition in the reverse process to enable the processing of the discrete recommendation data. We also design a different noising strategy that only noises the target item instead of the whole sequence, which is more suitable for sequential recommendation. Based on the modified diffusion process, we derive the objective function of our framework using a simplification technique and design a denoise sequential recommender to fulfill the objective function. As the lengthened diffusion steps substantially increase the time complexity, we propose an efficient training strategy and an efficient inference strategy to reduce training and inference cost and improve recommendation diversity. Extensive experiment results on three public benchmark datasets verify the effectiveness of our approach and show that DiffRec outperforms the state-of-the-art sequential recommendation models.