 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAWU-Net: Spatial Attention Weighted Unmixing Network for Hyperspectral Images
Apr 22, 2023
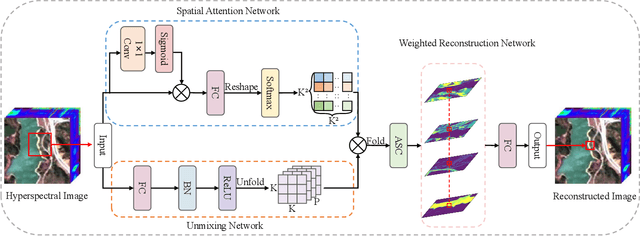
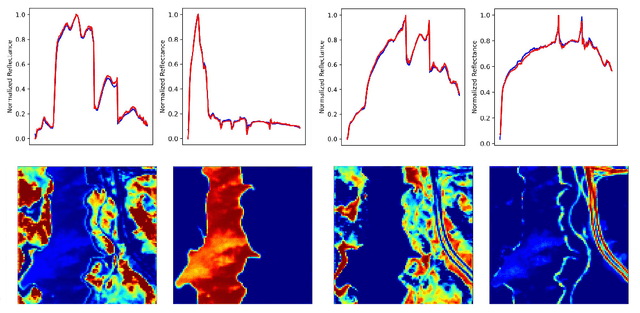
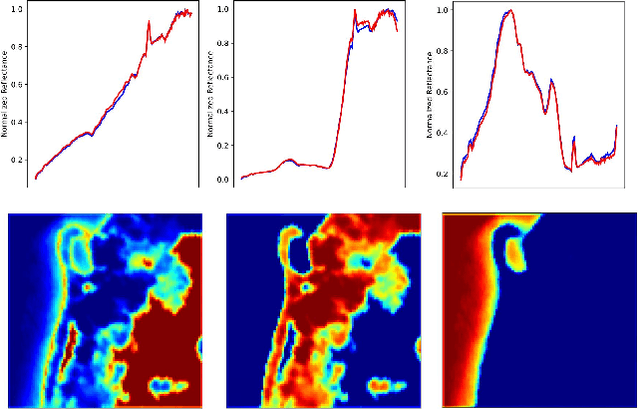
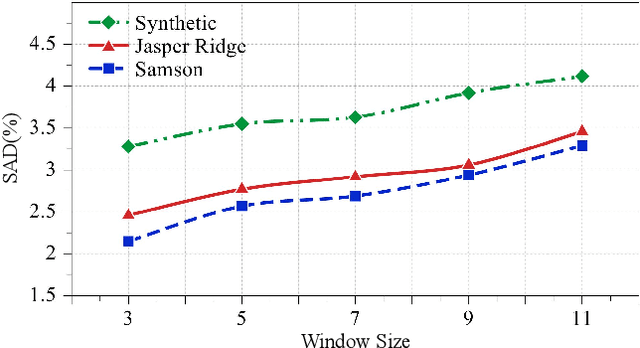
Hyperspectral unmixing is a critical yet challenging task in hyperspectral image interpretation. Recently, great efforts have been made to solve the hyperspectral unmixing task via deep autoencoders. However, existing networks mainly focus on extracting spectral features from mixed pixels, and the employment of spatial feature prior knowledge is still insufficient. To this end, we put forward a spatial attention weighted unmixing network, dubbed as SAWU-Net, which learns a spatial attention network and a weighted unmixing network in an end-to-end manner for better spatial feature exploitation. In particular, we design a spatial attention module, which consists of a pixel attention block and a window attention block to efficiently model pixel-based spectral information and patch-based spatial information, respectively. While in the weighted unmixing framework, the central pixel abundance is dynamically weighted by the coarse-grained abundances of surrounding pixels. In addition, SAWU-Net generates dynamically adaptive spatial weights through the spatial attention mechanism, so as to dynamically integrate surrounding pixels more effectively. Experimental results on real and synthetic datasets demonstrate the better accuracy and superiority of SAWU-Net, which reflects the effectiveness of the proposed spatial attention mechanism.
Uncovering the Representation of Spiking Neural Networks Trained with Surrogate Gradient
Apr 25, 2023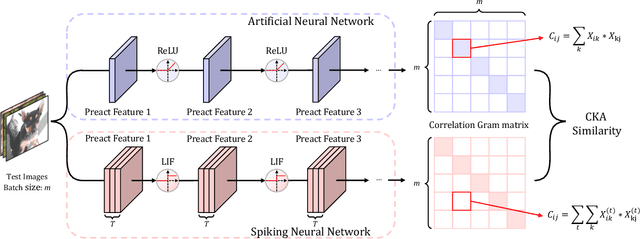

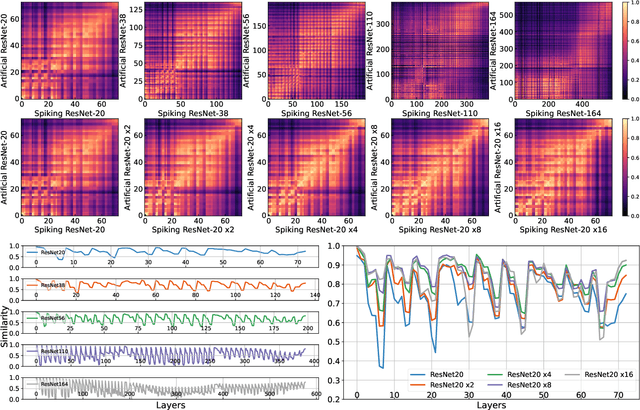

Spiking Neural Networks (SNNs) are recognized as the candidate for the next-generation neural networks due to their bio-plausibility and energy efficiency. Recently, researchers have demonstrated that SNNs are able to achieve nearly state-of-the-art performance in image recognition tasks using surrogate gradient training. However, some essential questions exist pertaining to SNNs that are little studied: Do SNNs trained with surrogate gradient learn different representations from traditional Artificial Neural Networks (ANNs)? Does the time dimension in SNNs provide unique representation power? In this paper, we aim to answer these questions by conducting a representation similarity analysis between SNNs and ANNs using Centered Kernel Alignment (CKA). We start by analyzing the spatial dimension of the networks, including both the width and the depth. Furthermore, our analysis of residual connections shows that SNNs learn a periodic pattern, which rectifies the representations in SNNs to be ANN-like. We additionally investigate the effect of the time dimension on SNN representation, finding that deeper layers encourage more dynamics along the time dimension. We also investigate the impact of input data such as event-stream data and adversarial attacks. Our work uncovers a host of new findings of representations in SNNs. We hope this work will inspire future research to fully comprehend the representation power of SNNs. Code is released at https://github.com/Intelligent-Computing-Lab-Yale/SNNCKA.
Image-to-Image Translation for Autonomous Driving from Coarsely-Aligned Image Pairs
Sep 23, 2022
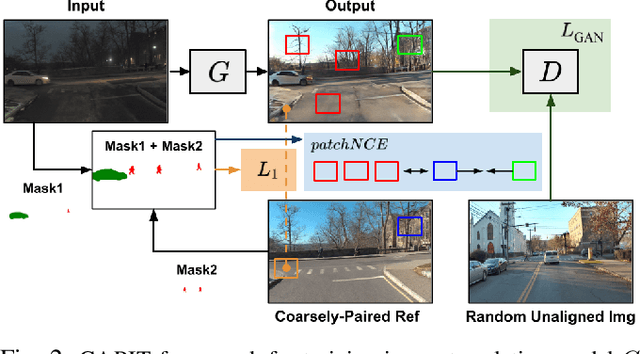

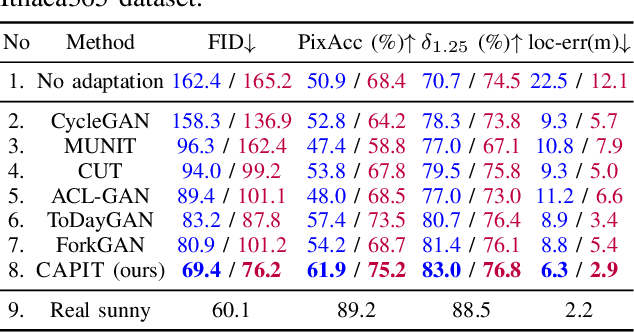
A self-driving car must be able to reliably handle adverse weather conditions (e.g., snowy) to operate safely. In this paper, we investigate the idea of turning sensor inputs (i.e., images) captured in an adverse condition into a benign one (i.e., sunny), upon which the downstream tasks (e.g., semantic segmentation) can attain high accuracy. Prior work primarily formulates this as an unpaired image-to-image translation problem due to the lack of paired images captured under the exact same camera poses and semantic layouts. While perfectly-aligned images are not available, one can easily obtain coarsely-paired images. For instance, many people drive the same routes daily in both good and adverse weather; thus, images captured at close-by GPS locations can form a pair. Though data from repeated traversals are unlikely to capture the same foreground objects, we posit that they provide rich contextual information to supervise the image translation model. To this end, we propose a novel training objective leveraging coarsely-aligned image pairs. We show that our coarsely-aligned training scheme leads to a better image translation quality and improved downstream tasks, such as semantic segmentation, monocular depth estimation, and visual localization.
Style Transfer for 2D Talking Head Animation
Mar 22, 2023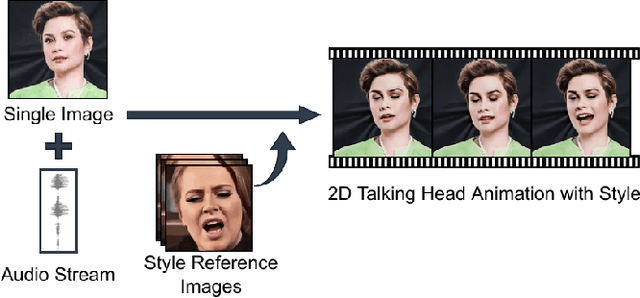
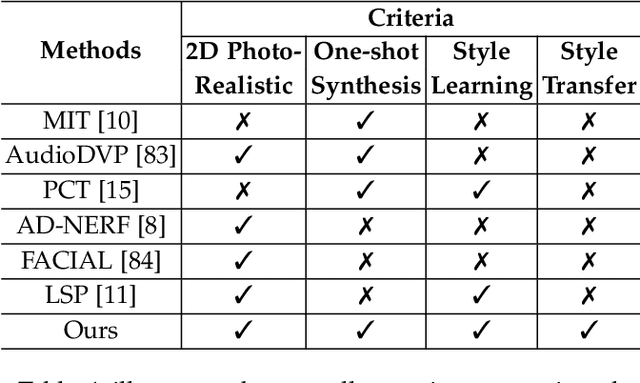
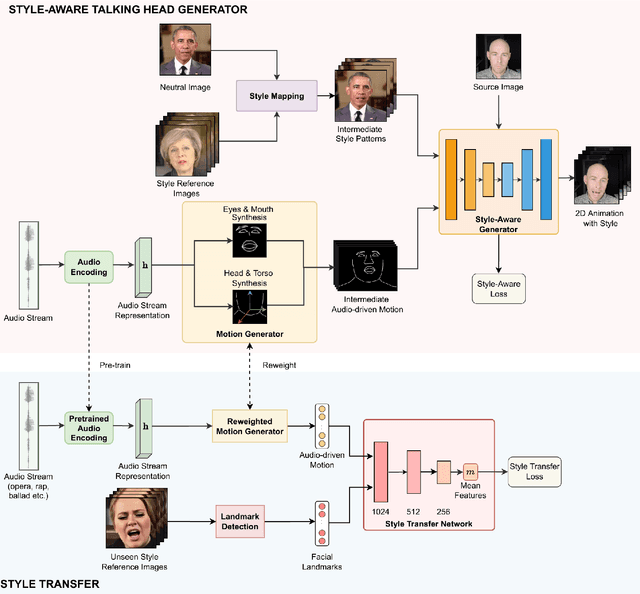
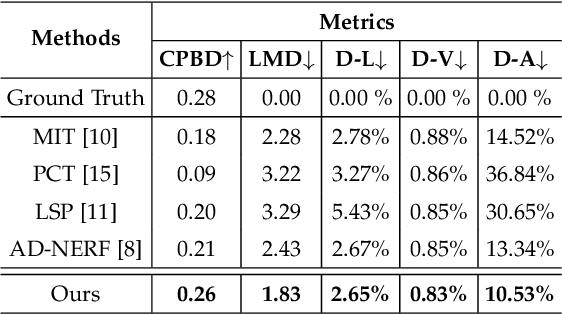
Audio-driven talking head animation is a challenging research topic with many real-world applications. Recent works have focused on creating photo-realistic 2D animation, while learning different talking or singing styles remains an open problem. In this paper, we present a new method to generate talking head animation with learnable style references. Given a set of style reference frames, our framework can reconstruct 2D talking head animation based on a single input image and an audio stream. Our method first produces facial landmarks motion from the audio stream and constructs the intermediate style patterns from the style reference images. We then feed both outputs into a style-aware image generator to generate the photo-realistic and fidelity 2D animation. In practice, our framework can extract the style information of a specific character and transfer it to any new static image for talking head animation. The intensive experimental results show that our method achieves better results than recent state-of-the-art approaches qualitatively and quantitatively.
Model-corrected learned primal-dual models for fast limited-view photoacoustic tomography
Apr 04, 2023Learned iterative reconstructions hold great promise to accelerate tomographic imaging with empirical robustness to model perturbations. Nevertheless, an adoption for photoacoustic tomography is hindered by the need to repeatedly evaluate the computational expensive forward model. Computational feasibility can be obtained by the use of fast approximate models, but a need to compensate model errors arises. In this work we advance the methodological and theoretical basis for model corrections in learned image reconstructions by embedding the model correction in a learned primal-dual framework. Here, the model correction is jointly learned in data space coupled with a learned updating operator in image space within an unrolled end-to-end learned iterative reconstruction approach. The proposed formulation allows an extension to a primal-dual deep equilibrium model providing fixed-point convergence as well as reduced memory requirements for training. We provide theoretical and empirical insights into the proposed models with numerical validation in a realistic 2D limited-view setting. The model-corrected learned primal-dual methods show excellent reconstruction quality with fast inference times and thus providing a methodological basis for real-time capable and scalable iterative reconstructions in photoacoustic tomography.
Segmentation Ability Map: Interpret deep features for medical image segmentation
Dec 19, 2022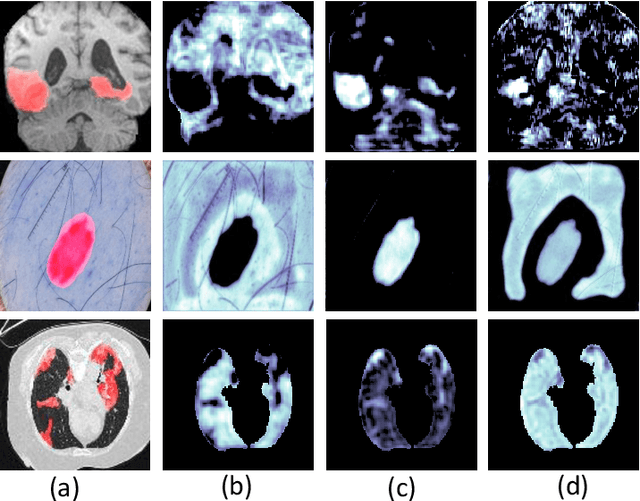
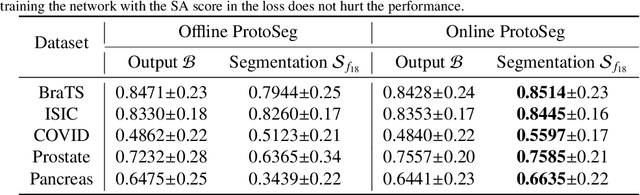
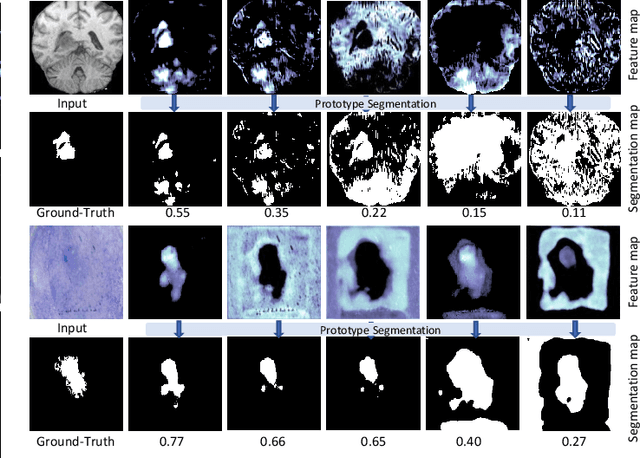
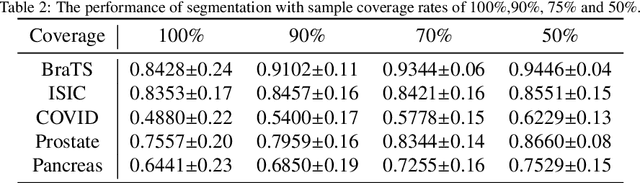
Deep convolutional neural networks (CNNs) have been widely used for medical image segmentation. In most studies, only the output layer is exploited to compute the final segmentation results and the hidden representations of the deep learned features have not been well understood. In this paper, we propose a prototype segmentation (ProtoSeg) method to compute a binary segmentation map based on deep features. We measure the segmentation abilities of the features by computing the Dice between the feature segmentation map and ground-truth, named as the segmentation ability score (SA score for short). The corresponding SA score can quantify the segmentation abilities of deep features in different layers and units to understand the deep neural networks for segmentation. In addition, our method can provide a mean SA score which can give a performance estimation of the output on the test images without ground-truth. Finally, we use the proposed ProtoSeg method to compute the segmentation map directly on input images to further understand the segmentation ability of each input image. Results are presented on segmenting tumors in brain MRI, lesions in skin images, COVID-related abnormality in CT images, prostate segmentation in abdominal MRI, and pancreatic mass segmentation in CT images. Our method can provide new insights for interpreting and explainable AI systems for medical image segmentation. Our code is available on: \url{https://github.com/shengfly/ProtoSeg}.
Fast Neural Scene Flow
Apr 20, 2023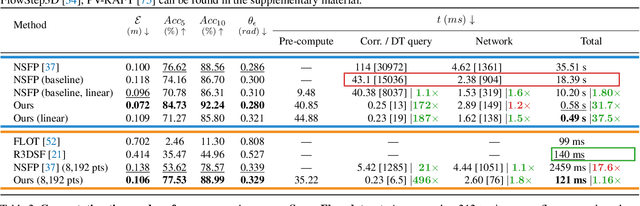

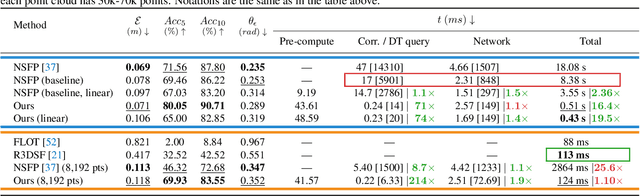
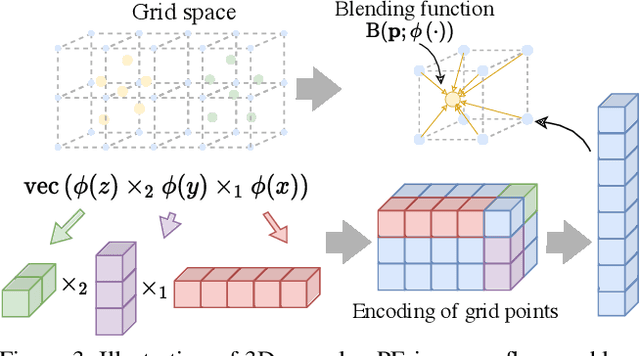
Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.
Learning CLIP Guided Visual-Text Fusion Transformer for Video-based Pedestrian Attribute Recognition
Apr 20, 2023

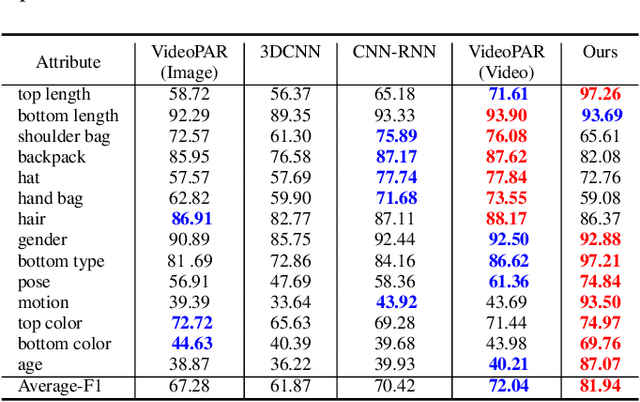
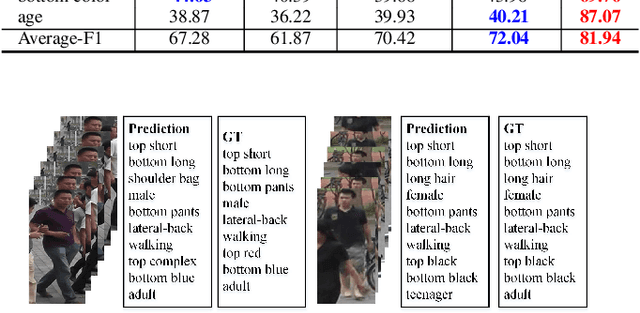
Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image. However, the performance is not reliable for images with challenging factors, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can make full use of temporal information. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt pre-trained big models CLIP to extract the feature embeddings of given video frames. To better utilize the semantic information, we take the attribute list as another input and transform the attribute words/phrase into the corresponding sentence via split, expand, and prompt. Then, the text encoder of CLIP is utilized for language embedding. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on a large-scale video-based PAR dataset fully validated the effectiveness of our proposed framework.
CornerFormer: Boosting Corner Representation for Fine-Grained Structured Reconstruction
Apr 20, 2023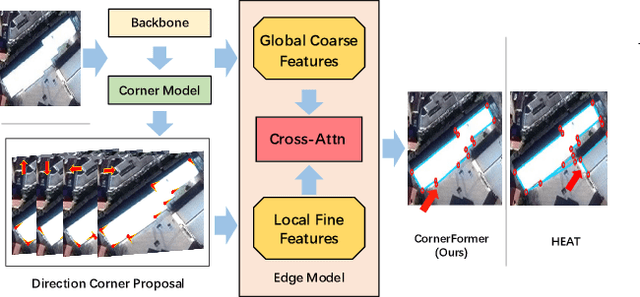
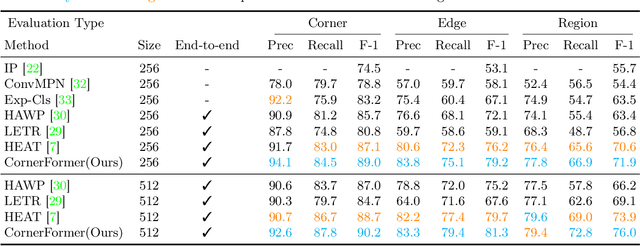
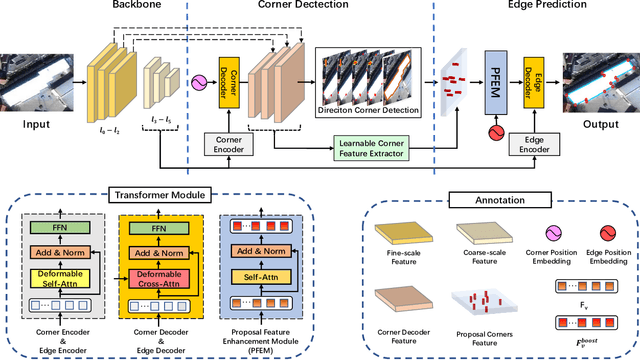
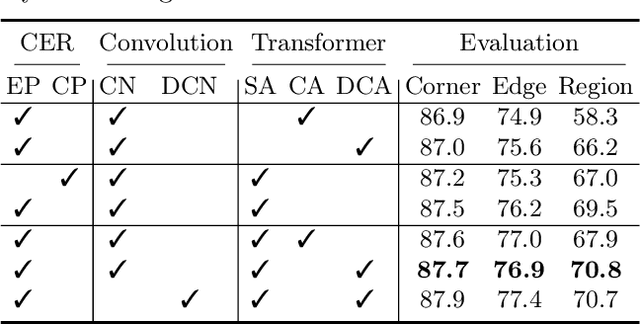
Structured reconstruction is a non-trivial dense prediction problem, which extracts structural information (\eg, building corners and edges) from a raster image, then reconstructs it to a 2D planar graph accordingly. Compared with common segmentation or detection problems, it significantly relays on the capability that leveraging holistic geometric information for structural reasoning. Current transformer-based approaches tackle this challenging problem in a two-stage manner, which detect corners in the first model and classify the proposed edges (corner-pairs) in the second model. However, they separate two-stage into different models and only share the backbone encoder. Unlike the existing modeling strategies, we present an enhanced corner representation method: 1) It fuses knowledge between the corner detection and edge prediction by sharing feature in different granularity; 2) Corner candidates are proposed in four heatmap channels w.r.t its direction. Both qualitative and quantitative evaluations demonstrate that our proposed method can better reconstruct fine-grained structures, such as adjacent corners and tiny edges. Consequently, it outperforms the state-of-the-art model by +1.9\%@F-1 on Corner and +3.0\%@F-1 on Edge.
DiracDiffusion: Denoising and Incremental Reconstruction with Assured Data-Consistency
Mar 25, 2023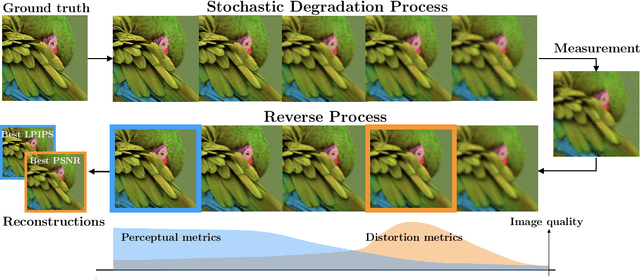
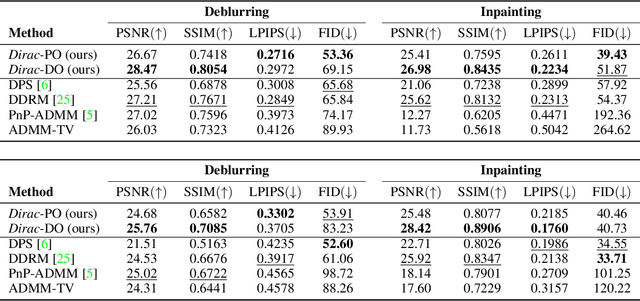
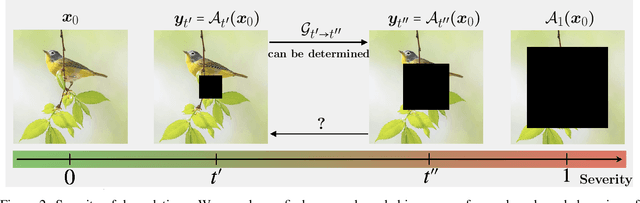
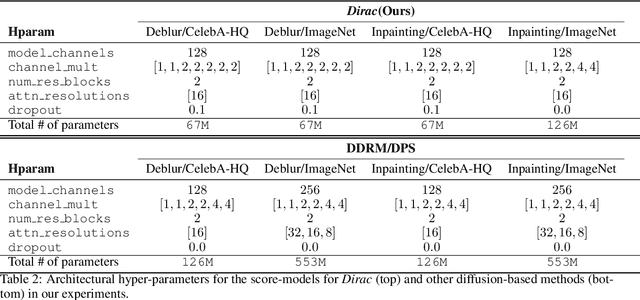
Diffusion models have established new state of the art in a multitude of computer vision tasks, including image restoration. Diffusion-based inverse problem solvers generate reconstructions of exceptional visual quality from heavily corrupted measurements. However, in what is widely known as the perception-distortion trade-off, the price of perceptually appealing reconstructions is often paid in declined distortion metrics, such as PSNR. Distortion metrics measure faithfulness to the observation, a crucial requirement in inverse problems. In this work, we propose a novel framework for inverse problem solving, namely we assume that the observation comes from a stochastic degradation process that gradually degrades and noises the original clean image. We learn to reverse the degradation process in order to recover the clean image. Our technique maintains consistency with the original measurement throughout the reverse process, and allows for great flexibility in trading off perceptual quality for improved distortion metrics and sampling speedup via early-stopping. We demonstrate the efficiency of our method on different high-resolution datasets and inverse problems, achieving great improvements over other state-of-the-art diffusion-based methods with respect to both perceptual and distortion metrics. Source code and pre-trained models will be released soon.