 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Indiscernible Object Counting in Underwater Scenes
Apr 23, 2023

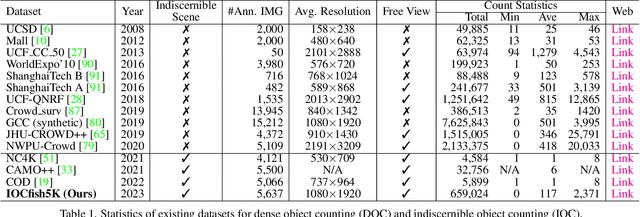

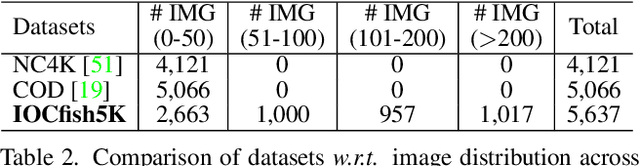
Recently, indiscernible scene understanding has attracted a lot of attention in the vision community. We further advance the frontier of this field by systematically studying a new challenge named indiscernible object counting (IOC), the goal of which is to count objects that are blended with respect to their surroundings. Due to a lack of appropriate IOC datasets, we present a large-scale dataset IOCfish5K which contains a total of 5,637 high-resolution images and 659,024 annotated center points. Our dataset consists of a large number of indiscernible objects (mainly fish) in underwater scenes, making the annotation process all the more challenging. IOCfish5K is superior to existing datasets with indiscernible scenes because of its larger scale, higher image resolutions, more annotations, and denser scenes. All these aspects make it the most challenging dataset for IOC so far, supporting progress in this area. For benchmarking purposes, we select 14 mainstream methods for object counting and carefully evaluate them on IOCfish5K. Furthermore, we propose IOCFormer, a new strong baseline that combines density and regression branches in a unified framework and can effectively tackle object counting under concealed scenes. Experiments show that IOCFormer achieves state-of-the-art scores on IOCfish5K.
No Free Lunch in Self Supervised Representation Learning
Apr 23, 2023

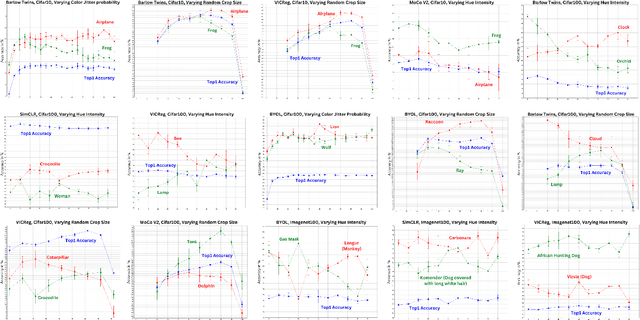

Self-supervised representation learning in computer vision relies heavily on hand-crafted image transformations to learn meaningful and invariant features. However few extensive explorations of the impact of transformation design have been conducted in the literature. In particular, the dependence of downstream performances to transformation design has been established, but not studied in depth. In this work, we explore this relationship, its impact on a domain other than natural images, and show that designing the transformations can be viewed as a form of supervision. First, we demonstrate that not only do transformations have an effect on downstream performance and relevance of clustering, but also that each category in a supervised dataset can be impacted in a different way. Following this, we explore the impact of transformation design on microscopy images, a domain where the difference between classes is more subtle and fuzzy than in natural images. In this case, we observe a greater impact on downstream tasks performances. Finally, we demonstrate that transformation design can be leveraged as a form of supervision, as careful selection of these by a domain expert can lead to a drastic increase in performance on a given downstream task.
Exploiting CNNs for Semantic Segmentation with Pascal VOC
Apr 26, 2023
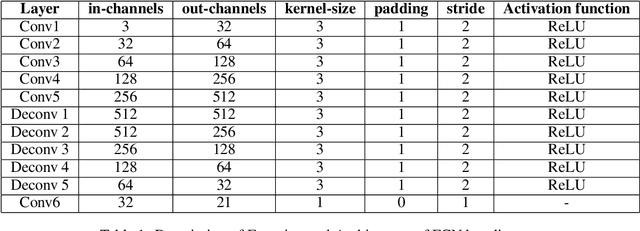
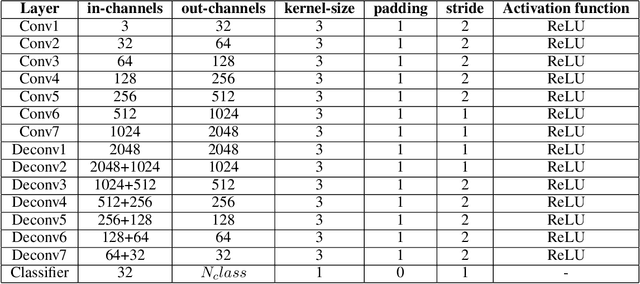
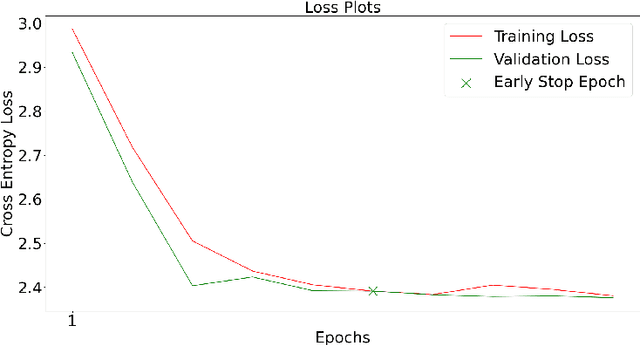
In this paper, we present a comprehensive study on semantic segmentation with the Pascal VOC dataset. Here, we have to label each pixel with a class which in turn segments the entire image based on the objects/entities present. To tackle this, we firstly use a Fully Convolution Network (FCN) baseline which gave 71.31% pixel accuracy and 0.0527 mean IoU. We analyze its performance and working and subsequently address the issues in the baseline with three improvements: a) cosine annealing learning rate scheduler(pixel accuracy: 72.86%, IoU: 0.0529), b) data augmentation(pixel accuracy: 69.88%, IoU: 0.0585) c) class imbalance weights(pixel accuracy: 68.98%, IoU: 0.0596). Apart from these changes in training pipeline, we also explore three different architectures: a) Our proposed model -- Advanced FCN (pixel accuracy: 67.20%, IoU: 0.0602) b) Transfer Learning with ResNet (Best performance) (pixel accuracy: 71.33%, IoU: 0.0926 ) c) U-Net(pixel accuracy: 72.15%, IoU: 0.0649). We observe that the improvements help in greatly improving the performance, as reflected both, in metrics and segmentation maps. Interestingly, we observe that among the improvements, dataset augmentation has the greatest contribution. Also, note that transfer learning model performs the best on the pascal dataset. We analyse the performance of these using loss, accuracy and IoU plots along with segmentation maps, which help us draw valuable insights about the working of the models.
Genetically-inspired convective heat transfer enhancement in a turbulent boundary layer
Apr 26, 2023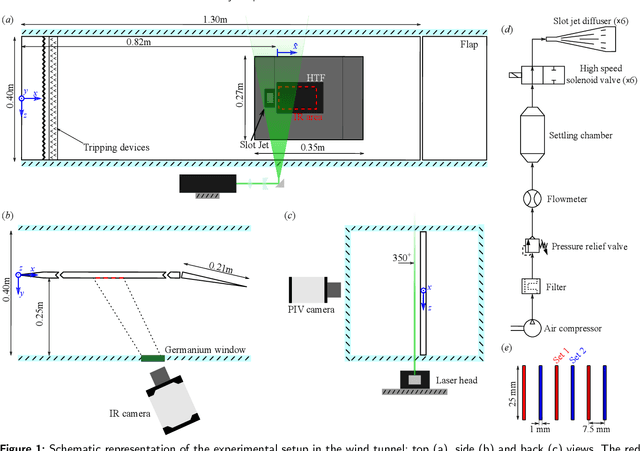
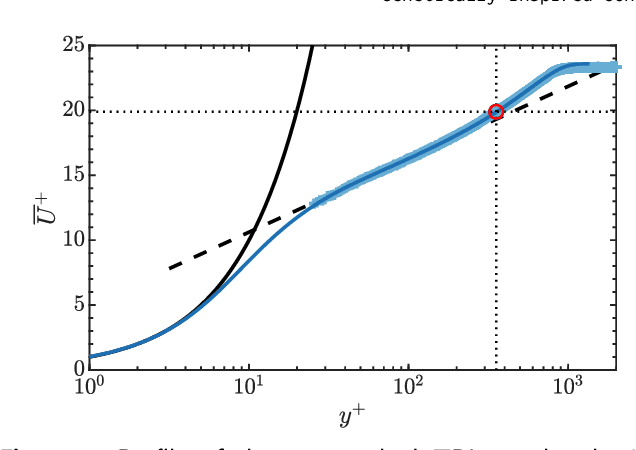

The convective heat transfer in a turbulent boundary layer (TBL) on a flat plate is enhanced using an artificial intelligence approach based on linear genetic algorithms control (LGAC). The actuator is a set of six slot jets in crossflow aligned with the freestream. An open-loop optimal periodic forcing is defined by the carrier frequency, the duty cycle and the phase difference between actuators as control parameters. The control laws are optimised with respect to the unperturbed TBL and to the actuation with a steady jet. The cost function includes the wall convective heat transfer rate and the cost of the actuation. The performance of the controller is assessed by infrared thermography and characterised also with particle image velocimetry measurements. The optimal controller yields a slightly asymmetric flow field. The LGAC algorithm converges to the same frequency and duty cycle for all the actuators. It is noted that such frequency is strikingly equal to the inverse of the characteristic travel time of large-scale turbulent structures advected within the near-wall region. The phase difference between multiple jet actuation has shown to be very relevant and the main driver of flow asymmetry. The results pinpoint the potential of machine learning control in unravelling unexplored controllers within the actuation space. Our study furthermore demonstrates the viability of employing sophisticated measurement techniques together with advanced algorithms in an experimental investigation.
FaceQAN: Face Image Quality Assessment Through Adversarial Noise Exploration
Dec 05, 2022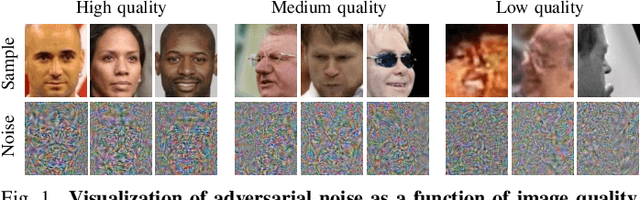
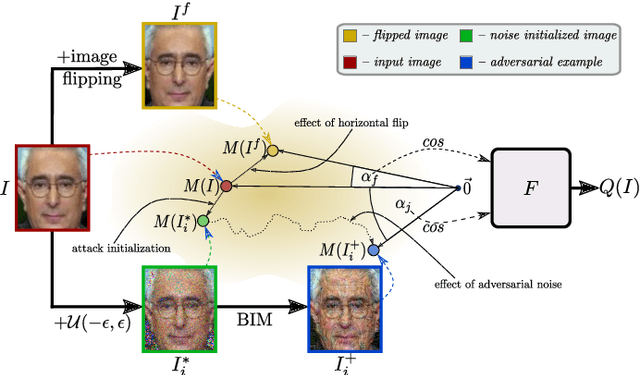
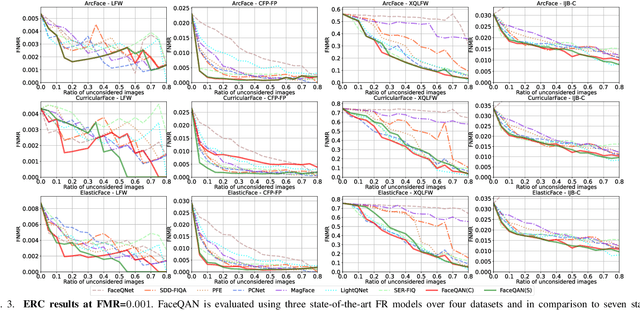

Recent state-of-the-art face recognition (FR) approaches have achieved impressive performance, yet unconstrained face recognition still represents an open problem. Face image quality assessment (FIQA) approaches aim to estimate the quality of the input samples that can help provide information on the confidence of the recognition decision and eventually lead to improved results in challenging scenarios. While much progress has been made in face image quality assessment in recent years, computing reliable quality scores for diverse facial images and FR models remains challenging. In this paper, we propose a novel approach to face image quality assessment, called FaceQAN, that is based on adversarial examples and relies on the analysis of adversarial noise which can be calculated with any FR model learned by using some form of gradient descent. As such, the proposed approach is the first to link image quality to adversarial attacks. Comprehensive (cross-model as well as model-specific) experiments are conducted with four benchmark datasets, i.e., LFW, CFP-FP, XQLFW and IJB-C, four FR models, i.e., CosFace, ArcFace, CurricularFace and ElasticFace, and in comparison to seven state-of-the-art FIQA methods to demonstrate the performance of FaceQAN. Experimental results show that FaceQAN achieves competitive results, while exhibiting several desirable characteristics.
Exploring Discrete Diffusion Models for Image Captioning
Nov 21, 2022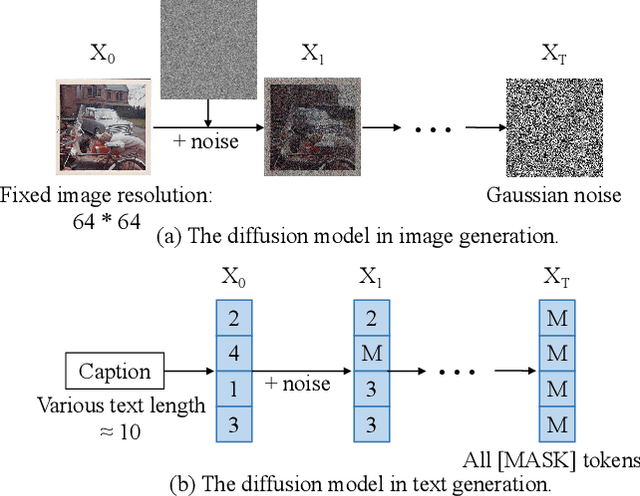

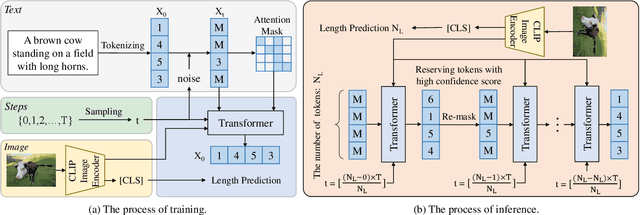
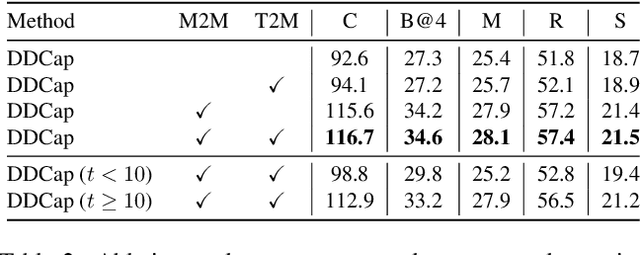
The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.
ODSmoothGrad: Generating Saliency Maps for Object Detectors
Apr 15, 2023
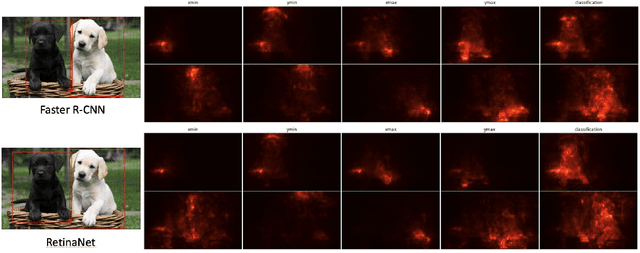
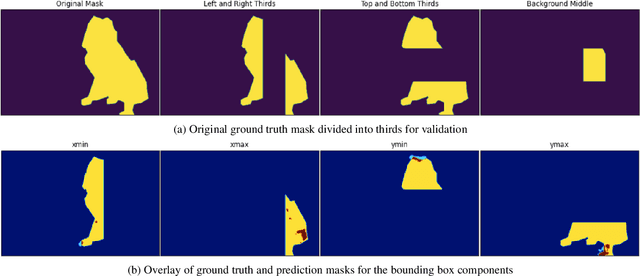
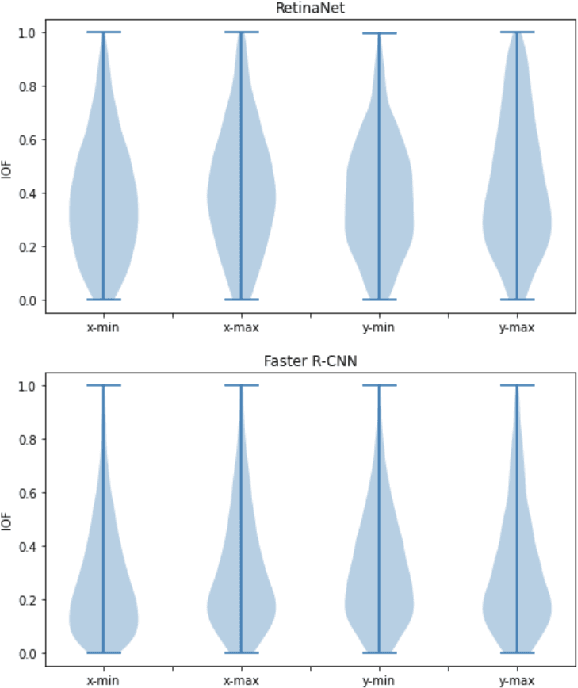
Techniques for generating saliency maps continue to be used for explainability of deep learning models, with efforts primarily applied to the image classification task. Such techniques, however, can also be applied to object detectors, not only with the classification scores, but also for the bounding box parameters, which are regressed values for which the relevant pixels contributing to these parameters can be identified. In this paper, we present ODSmoothGrad, a tool for generating saliency maps for the classification and the bounding box parameters in object detectors. Given the noisiness of saliency maps, we also apply the SmoothGrad algorithm to visually enhance the pixels of interest. We demonstrate these capabilities on one-stage and two-stage object detectors, with comparisons using classifier-based techniques.
Mixture-Net: Low-Rank Deep Image Prior Inspired by Mixture Models for Spectral Image Recovery
Nov 05, 2022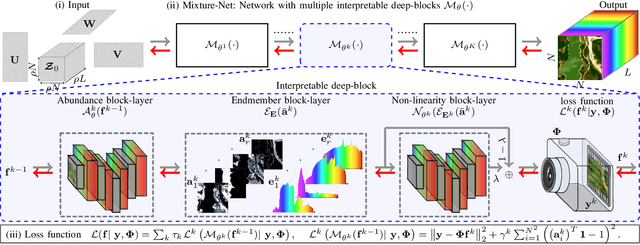
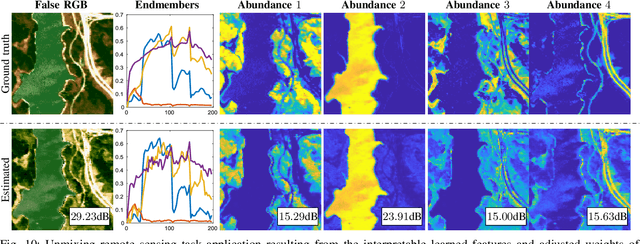

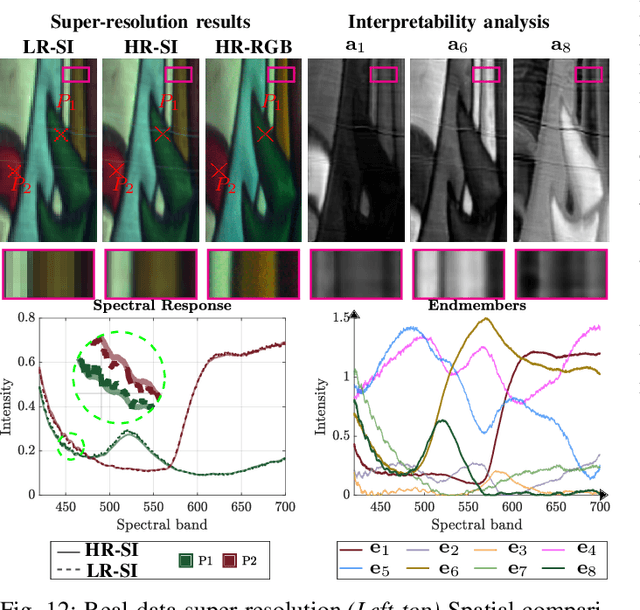
This paper proposes a non-data-driven deep neural network for spectral image recovery problems such as denoising, single hyperspectral image super-resolution, and compressive spectral imaging reconstruction. Unlike previous methods, the proposed approach, dubbed Mixture-Net, implicitly learns the prior information through the network. Mixture-Net consists of a deep generative model whose layers are inspired by the linear and non-linear low-rank mixture models, where the recovered image is composed of a weighted sum between the linear and non-linear decomposition. Mixture-Net also provides a low-rank decomposition interpreted as the spectral image abundances and endmembers, helpful in achieving remote sensing tasks without running additional routines. The experiments show the MixtureNet effectiveness outperforming state-of-the-art methods in recovery quality with the advantage of architecture interpretability.
SAOR: Single-View Articulated Object Reconstruction
Mar 23, 2023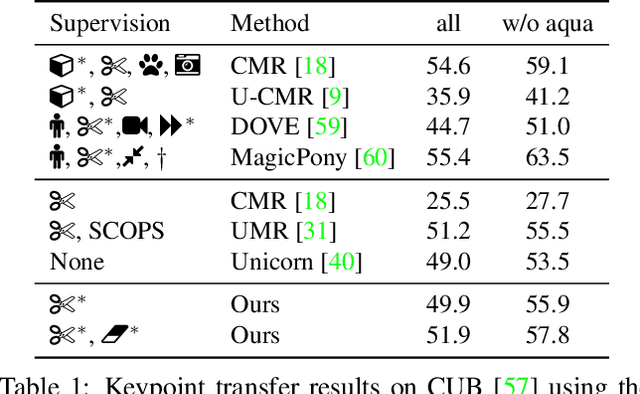
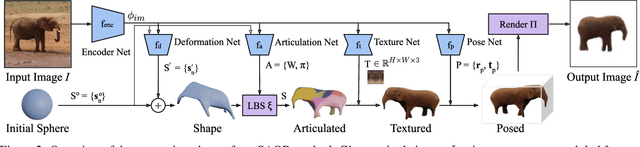
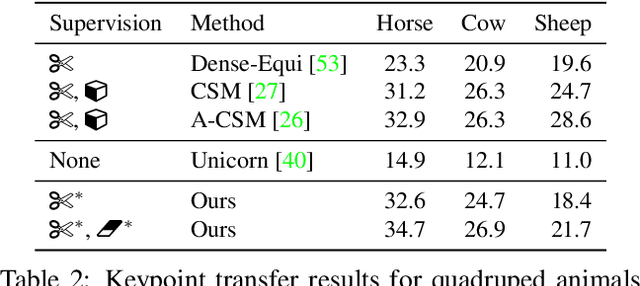

We introduce SAOR, a novel approach for estimating the 3D shape, texture, and viewpoint of an articulated object from a single image captured in the wild. Unlike prior approaches that rely on pre-defined category-specific 3D templates or tailored 3D skeletons, SAOR learns to articulate shapes from single-view image collections with a skeleton-free part-based model without requiring any 3D object shape priors. To prevent ill-posed solutions, we propose a cross-instance consistency loss that exploits disentangled object shape deformation and articulation. This is helped by a new silhouette-based sampling mechanism to enhance viewpoint diversity during training. Our method only requires estimated object silhouettes and relative depth maps from off-the-shelf pre-trained networks during training. At inference time, given a single-view image, it efficiently outputs an explicit mesh representation. We obtain improved qualitative and quantitative results on challenging quadruped animals compared to relevant existing work.
FSNet: Redesign Self-Supervised MonoDepth for Full-Scale Depth Prediction for Autonomous Driving
Apr 21, 2023
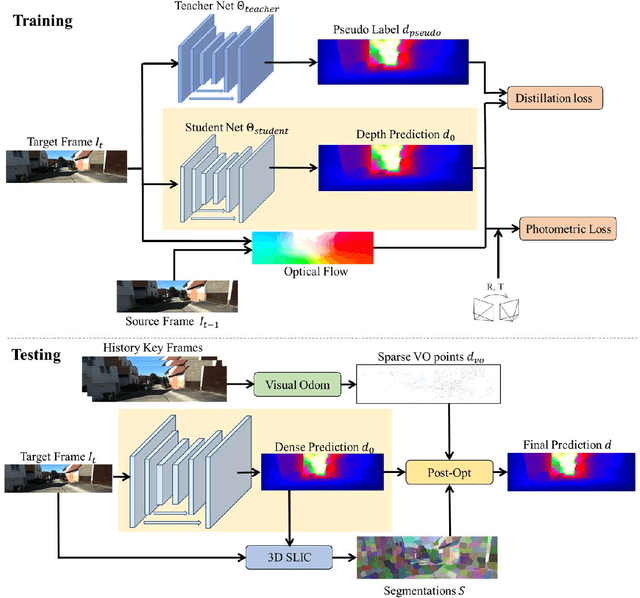


Predicting accurate depth with monocular images is important for low-cost robotic applications and autonomous driving. This study proposes a comprehensive self-supervised framework for accurate scale-aware depth prediction on autonomous driving scenes utilizing inter-frame poses obtained from inertial measurements. In particular, we introduce a Full-Scale depth prediction network named FSNet. FSNet contains four important improvements over existing self-supervised models: (1) a multichannel output representation for stable training of depth prediction in driving scenarios, (2) an optical-flow-based mask designed for dynamic object removal, (3) a self-distillation training strategy to augment the training process, and (4) an optimization-based post-processing algorithm in test time, fusing the results from visual odometry. With this framework, robots and vehicles with only one well-calibrated camera can collect sequences of training image frames and camera poses, and infer accurate 3D depths of the environment without extra labeling work or 3D data. Extensive experiments on the KITTI dataset, KITTI-360 dataset and the nuScenes dataset demonstrate the potential of FSNet. More visualizations are presented in \url{https://sites.google.com/view/fsnet/home}