 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-view Vision-Prompt Fusion Network: Can 2D Pre-trained Model Boost 3D Point Cloud Data-scarce Learning?
Apr 20, 2023
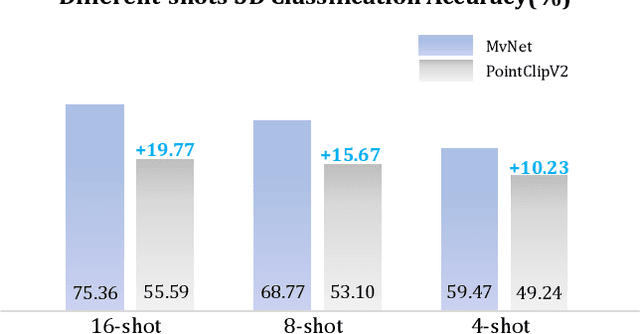
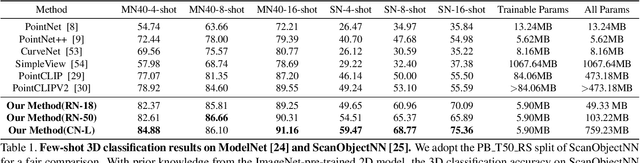
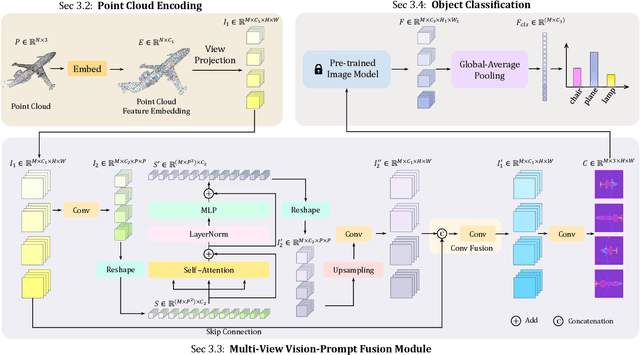
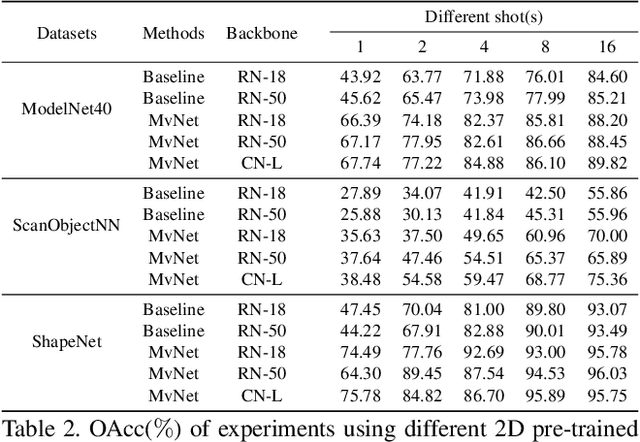
Point cloud based 3D deep model has wide applications in many applications such as autonomous driving, house robot, and so on. Inspired by the recent prompt learning in natural language processing, this work proposes a novel Multi-view Vision-Prompt Fusion Network (MvNet) for few-shot 3D point cloud classification. MvNet investigates the possibility of leveraging the off-the-shelf 2D pre-trained models to achieve the few-shot classification, which can alleviate the over-dependence issue of the existing baseline models towards the large-scale annotated 3D point cloud data. Specifically, MvNet first encodes a 3D point cloud into multi-view image features for a number of different views. Then, a novel multi-view prompt fusion module is developed to effectively fuse information from different views to bridge the gap between 3D point cloud data and 2D pre-trained models. A set of 2D image prompts can then be derived to better describe the suitable prior knowledge for a large-scale pre-trained image model for few-shot 3D point cloud classification. Extensive experiments on ModelNet, ScanObjectNN, and ShapeNet datasets demonstrate that MvNet achieves new state-of-the-art performance for 3D few-shot point cloud image classification. The source code of this work will be available soon.
Farm3D: Learning Articulated 3D Animals by Distilling 2D Diffusion
Apr 20, 2023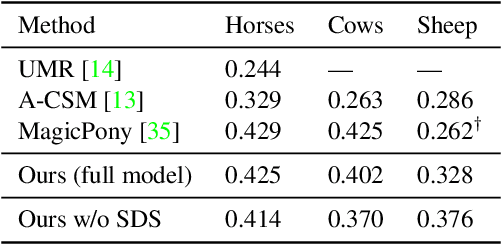
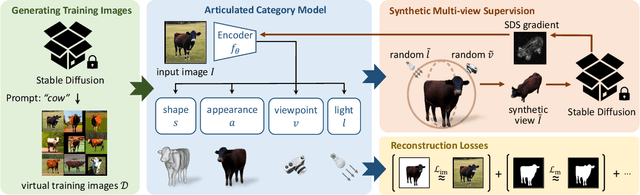

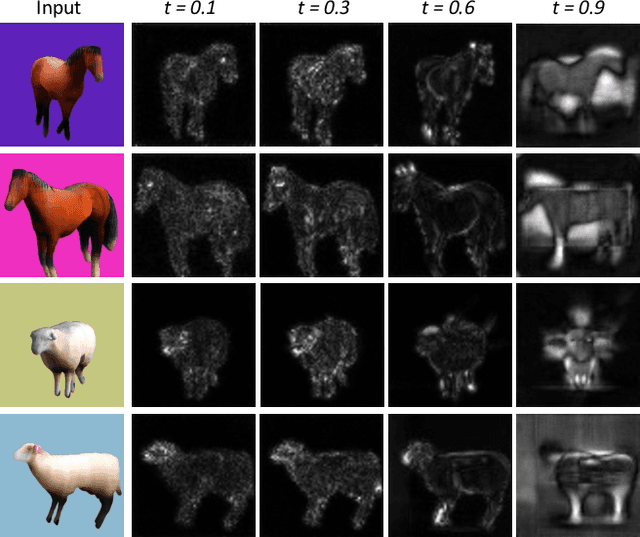
We present Farm3D, a method to learn category-specific 3D reconstructors for articulated objects entirely from "free" virtual supervision from a pre-trained 2D diffusion-based image generator. Recent approaches can learn, given a collection of single-view images of an object category, a monocular network to predict the 3D shape, albedo, illumination and viewpoint of any object occurrence. We propose a framework using an image generator like Stable Diffusion to generate virtual training data for learning such a reconstruction network from scratch. Furthermore, we include the diffusion model as a score to further improve learning. The idea is to randomise some aspects of the reconstruction, such as viewpoint and illumination, generating synthetic views of the reconstructed 3D object, and have the 2D network assess the quality of the resulting image, providing feedback to the reconstructor. Different from work based on distillation which produces a single 3D asset for each textual prompt in hours, our approach produces a monocular reconstruction network that can output a controllable 3D asset from a given image, real or generated, in only seconds. Our network can be used for analysis, including monocular reconstruction, or for synthesis, generating articulated assets for real-time applications such as video games.
Painterly Image Harmonization in Dual Domains
Dec 20, 2022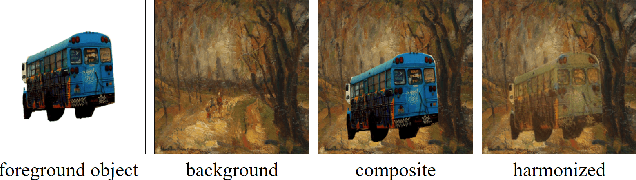
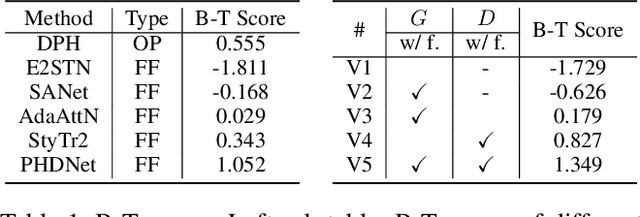

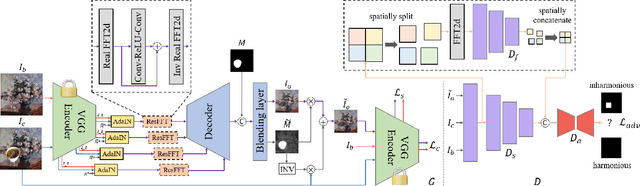
Image harmonization aims to produce visually harmonious composite images by adjusting the foreground appearance to be compatible with the background. When the composite image has photographic foreground and painterly background, the task is called painterly image harmonization. There are only few works on this task, which are either time-consuming or weak in generating well-harmonized results. In this work, we propose a novel painterly harmonization network consisting of a dual-domain generator and a dual-domain discriminator, which harmonizes the composite image in both spatial domain and frequency domain. The dual-domain generator performs harmonization by using AdaIn modules in the spatial domain and our proposed ResFFT modules in the frequency domain. The dual-domain discriminator attempts to distinguish the inharmonious patches based on the spatial feature and frequency feature of each patch, which can enhance the ability of generator in an adversarial manner. Extensive experiments on the benchmark dataset show the effectiveness of our method. Our code and model are available at https://github.com/bcmi/PHDNet-Painterly-Image-Harmonization.
PromptMix: Text-to-image diffusion models enhance the performance of lightweight networks
Jan 31, 2023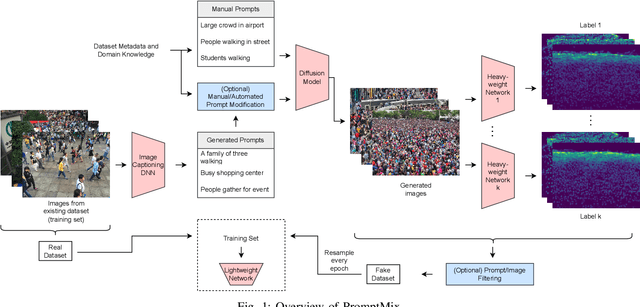

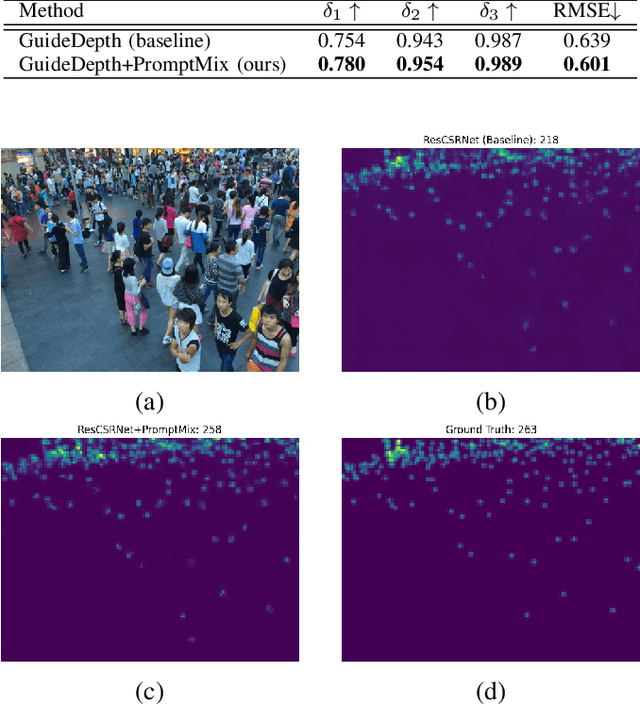

Many deep learning tasks require annotations that are too time consuming for human operators, resulting in small dataset sizes. This is especially true for dense regression problems such as crowd counting which requires the location of every person in the image to be annotated. Techniques such as data augmentation and synthetic data generation based on simulations can help in such cases. In this paper, we introduce PromptMix, a method for artificially boosting the size of existing datasets, that can be used to improve the performance of lightweight networks. First, synthetic images are generated in an end-to-end data-driven manner, where text prompts are extracted from existing datasets via an image captioning deep network, and subsequently introduced to text-to-image diffusion models. The generated images are then annotated using one or more high-performing deep networks, and mixed with the real dataset for training the lightweight network. By extensive experiments on five datasets and two tasks, we show that PromptMix can significantly increase the performance of lightweight networks by up to 26%.
Leaf Only SAM: A Segment Anything Pipeline for Zero-Shot Automated Leaf Segmentation
May 22, 2023

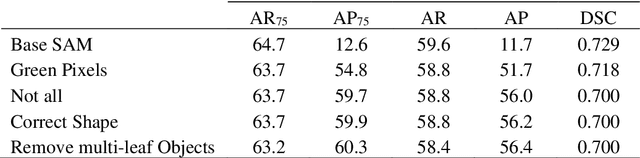

Segment Anything Model (SAM) is a new foundation model that can be used as a zero-shot object segmentation method with the use of either guide prompts such as bounding boxes, polygons, or points. Alternatively, additional post processing steps can be used to identify objects of interest after segmenting everything in an image. Here we present a method using segment anything together with a series of post processing steps to segment potato leaves, called Leaf Only SAM. The advantage of this proposed method is that it does not require any training data to produce its results so has many applications across the field of plant phenotyping where there is limited high quality annotated data available. We compare the performance of Leaf Only SAM to a Mask R-CNN model which has been fine-tuned on our small novel potato leaf dataset. On the evaluation dataset, Leaf Only SAM finds an average recall of 63.2 and an average precision of 60.3, compared to recall of 78.7 and precision of 74.7 for Mask R-CNN. Leaf Only SAM does not perform better than the fine-tuned Mask R-CNN model on our data, but the SAM based model does not require any extra training or annotation of our new dataset. This shows there is potential to use SAM as a zero-shot classifier with the addition of post processing steps.
D$^2$TV: Dual Knowledge Distillation and Target-oriented Vision Modeling for Many-to-Many Multimodal Summarization
May 22, 2023
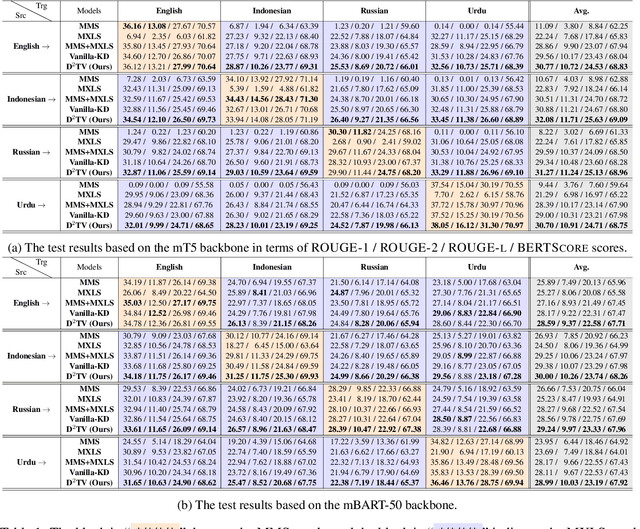
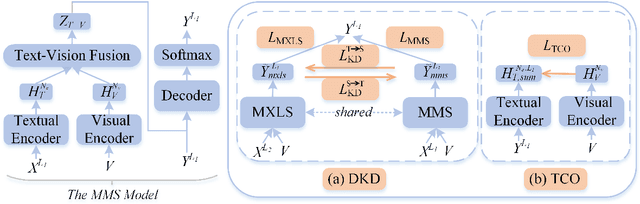

Many-to-many multimodal summarization (M$^3$S) task aims to generate summaries in any language with document inputs in any language and the corresponding image sequence, which essentially comprises multimodal monolingual summarization (MMS) and multimodal cross-lingual summarization (MXLS) tasks. Although much work has been devoted to either MMS or MXLS and has obtained increasing attention in recent years, little research pays attention to the M$^3$S task. Besides, existing studies mainly focus on 1) utilizing MMS to enhance MXLS via knowledge distillation without considering the performance of MMS or 2) improving MMS models by filtering summary-unrelated visual features with implicit learning or explicitly complex training objectives. In this paper, we first introduce a general and practical task, i.e., M$^3$S. Further, we propose a dual knowledge distillation and target-oriented vision modeling framework for the M$^3$S task. Specifically, the dual knowledge distillation method guarantees that the knowledge of MMS and MXLS can be transferred to each other and thus mutually prompt both of them. To offer target-oriented visual features, a simple yet effective target-oriented contrastive objective is designed and responsible for discarding needless visual information. Extensive experiments on the many-to-many setting show the effectiveness of the proposed approach. Additionally, we will contribute a many-to-many multimodal summarization (M$^3$Sum) dataset.
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
May 16, 2023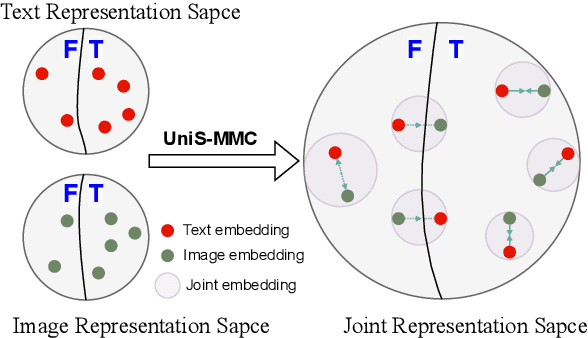
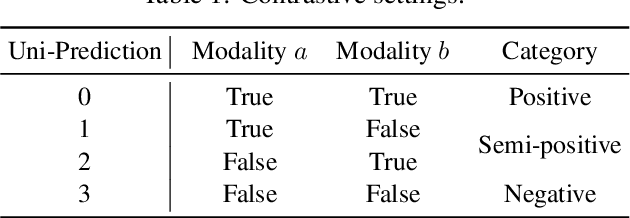
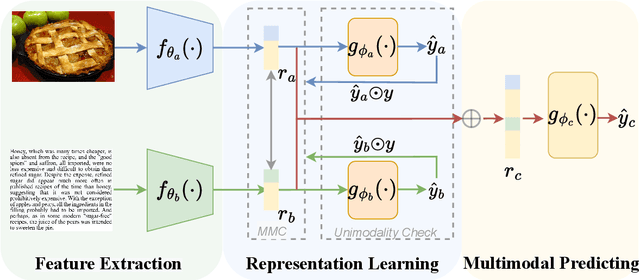
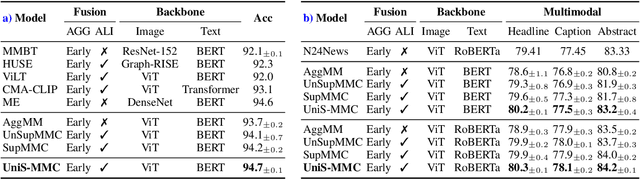
Multimodal learning aims to imitate human beings to acquire complementary information from multiple modalities for various downstream tasks. However, traditional aggregation-based multimodal fusion methods ignore the inter-modality relationship, treat each modality equally, suffer sensor noise, and thus reduce multimodal learning performance. In this work, we propose a novel multimodal contrastive method to explore more reliable multimodal representations under the weak supervision of unimodal predicting. Specifically, we first capture task-related unimodal representations and the unimodal predictions from the introduced unimodal predicting task. Then the unimodal representations are aligned with the more effective one by the designed multimodal contrastive method under the supervision of the unimodal predictions. Experimental results with fused features on two image-text classification benchmarks UPMC-Food-101 and N24News show that our proposed Unimodality-Supervised MultiModal Contrastive UniS-MMC learning method outperforms current state-of-the-art multimodal methods. The detailed ablation study and analysis further demonstrate the advantage of our proposed method.
Mobile User Interface Element Detection Via Adaptively Prompt Tuning
May 16, 2023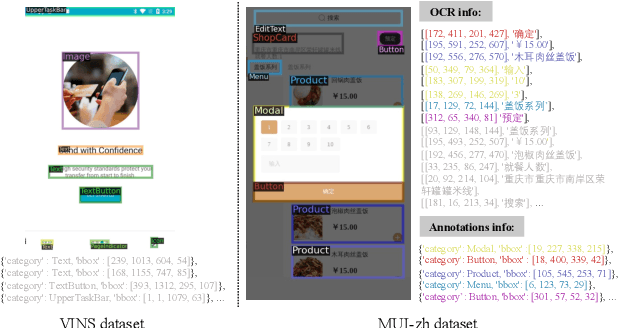
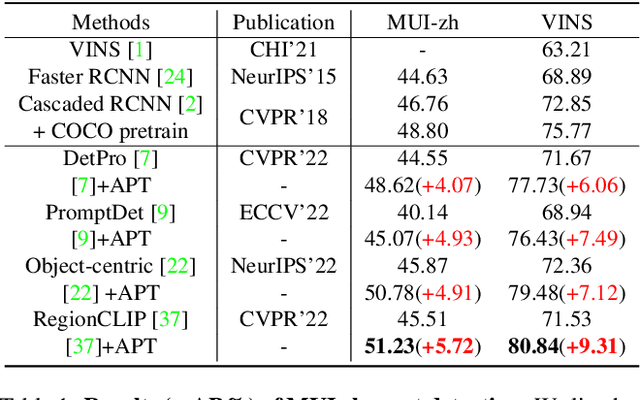
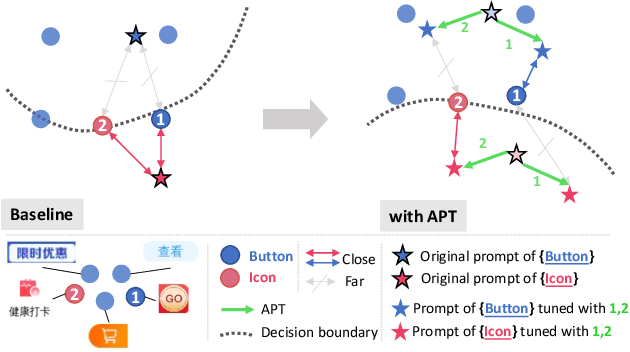
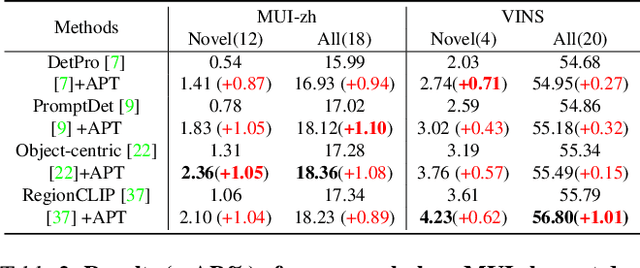
Recent object detection approaches rely on pretrained vision-language models for image-text alignment. However, they fail to detect the Mobile User Interface (MUI) element since it contains additional OCR information, which describes its content and function but is often ignored. In this paper, we develop a new MUI element detection dataset named MUI-zh and propose an Adaptively Prompt Tuning (APT) module to take advantage of discriminating OCR information. APT is a lightweight and effective module to jointly optimize category prompts across different modalities. For every element, APT uniformly encodes its visual features and OCR descriptions to dynamically adjust the representation of frozen category prompts. We evaluate the effectiveness of our plug-and-play APT upon several existing CLIP-based detectors for both standard and open-vocabulary MUI element detection. Extensive experiments show that our method achieves considerable improvements on two datasets. The datasets is available at \url{github.com/antmachineintelligence/MUI-zh}.
ADDSL: Hand Gesture Detection and Sign Language Recognition on Annotated Danish Sign Language
May 16, 2023

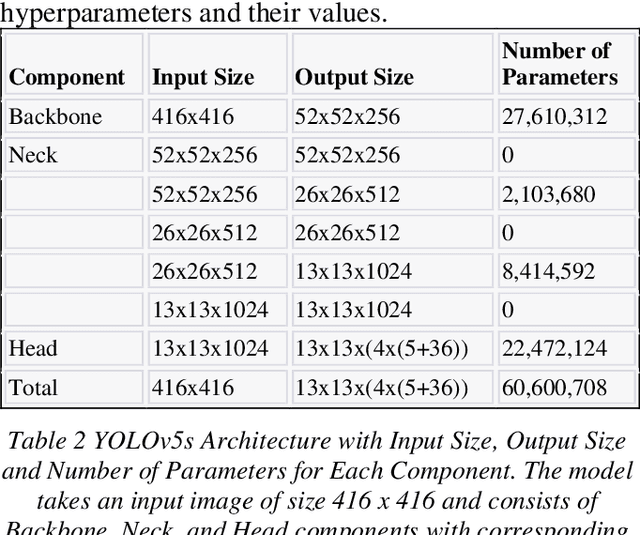

For a long time, detecting hand gestures and recognizing them as letters or numbers has been a challenging task. This creates communication barriers for individuals with disabilities. This paper introduces a new dataset, the Annotated Dataset for Danish Sign Language (ADDSL). Annota-tions for the dataset were made using the open-source tool LabelImg in the YOLO format. Using this dataset, a one-stage ob-ject detector model (YOLOv5) was trained with the CSP-DarkNet53 backbone and YOLOv3 head to recognize letters (A-Z) and numbers (0-9) using only seven unique images per class (without augmen-tation). Five models were trained with 350 epochs, resulting in an average inference time of 9.02ms per image and a best accu-racy of 92% when compared to previous research. Our results show that modified model is efficient and more accurate than existing work in the same field. The code repository for our model is available at the GitHub repository https://github.com/s4nyam/pvt-addsl.
A Range-Null Space Decomposition Approach for Fast and Flexible Spectral Compressive Imaging
May 16, 2023

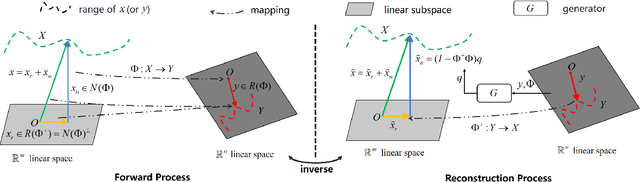

We present RND-SCI, a novel framework for compressive hyperspectral image (HSI) reconstruction. Our framework decomposes the reconstructed object into range-space and null-space components, where the range-space part ensures the solution conforms to the compression process, and the null-space term introduces a deep HSI prior to constraining the output to have satisfactory properties. RND-SCI is not only simple in design with strong interpretability but also can be easily adapted to various HSI reconstruction networks, improving the quality of HSIs with minimal computational overhead. RND-SCI significantly boosts the performance of HSI reconstruction networks in retraining, fine-tuning or plugging into a pre-trained off-the-shelf model. Based on the framework and SAUNet, we design an extremely fast HSI reconstruction network, RND-SAUNet, which achieves an astounding 91 frames per second while maintaining superior reconstruction accuracy compared to other less time-consuming methods. Code and models are available at https://github.com/hustvl/RND-SCI.