 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Object Hallucination in LVLMs via Emphasizing Image-negative Tokens
May 20, 2026Object hallucination is a significant challenge that hinders the application of large vision-language models (LVLMs) in practice. We hypothesize that one possible origin of hallucination is the model's tendency to prioritize text generation over meaningful interaction with images. To explore this, we examine the generation process and categorize text tokens into three groups: image-positive, invariant, and negative, based on their visual dependence on input image tokens. Our analysis reveals that most generated tokens are minimally influenced by the image information. This suggests that during the model's training stage, more emphasis is placed on learning how to follow textual instructions, rather than extracting information from images. Based on this finding, we propose adjusting the training weights of different tokens depending on their visual dependence to control hallucination. Additionally, we remove a portion of the training data that potentially contains more hallucinations as a data filtering strategy. Both methods achieve a reduction in hallucination without compromising response length or introducing additional computational costs during inference. We validate our methods across three LVLM variants, demonstrating the effectiveness and general applicability.
Next-Frame Feature Prediction for Multimodal Deepfake Detection and Temporal Localization
Nov 13, 2025Recent multimodal deepfake detection methods designed for generalization conjecture that single-stage supervised training struggles to generalize across unseen manipulations and datasets. However, such approaches that target generalization require pretraining over real samples. Additionally, these methods primarily focus on detecting audio-visual inconsistencies and may overlook intra-modal artifacts causing them to fail against manipulations that preserve audio-visual alignment. To address these limitations, we propose a single-stage training framework that enhances generalization by incorporating next-frame prediction for both uni-modal and cross-modal features. Additionally, we introduce a window-level attention mechanism to capture discrepancies between predicted and actual frames, enabling the model to detect local artifacts around every frame, which is crucial for accurately classifying fully manipulated videos and effectively localizing deepfake segments in partially spoofed samples. Our model, evaluated on multiple benchmark datasets, demonstrates strong generalization and precise temporal localization.
From Pretrain to Pain: Adversarial Vulnerability of Video Foundation Models Without Task Knowledge
Nov 10, 2025Large-scale Video Foundation Models (VFMs) has significantly advanced various video-related tasks, either through task-specific models or Multi-modal Large Language Models (MLLMs). However, the open accessibility of VFMs also introduces critical security risks, as adversaries can exploit full knowledge of the VFMs to launch potent attacks. This paper investigates a novel and practical adversarial threat scenario: attacking downstream models or MLLMs fine-tuned from open-source VFMs, without requiring access to the victim task, training data, model query, and architecture. In contrast to conventional transfer-based attacks that rely on task-aligned surrogate models, we demonstrate that adversarial vulnerabilities can be exploited directly from the VFMs. To this end, we propose the Transferable Video Attack (TVA), a temporal-aware adversarial attack method that leverages the temporal representation dynamics of VFMs to craft effective perturbations. TVA integrates a bidirectional contrastive learning mechanism to maximize the discrepancy between the clean and adversarial features, and introduces a temporal consistency loss that exploits motion cues to enhance the sequential impact of perturbations. TVA avoids the need to train expensive surrogate models or access to domain-specific data, thereby offering a more practical and efficient attack strategy. Extensive experiments across 24 video-related tasks demonstrate the efficacy of TVA against downstream models and MLLMs, revealing a previously underexplored security vulnerability in the deployment of video models.
Enhancing Modality Representation and Alignment for Multimodal Cold-start Active Learning
Dec 12, 2024Training multimodal models requires a large amount of labeled data. Active learning (AL) aim to reduce labeling costs. Most AL methods employ warm-start approaches, which rely on sufficient labeled data to train a well-calibrated model that can assess the uncertainty and diversity of unlabeled data. However, when assembling a dataset, labeled data are often scarce initially, leading to a cold-start problem. Additionally, most AL methods seldom address multimodal data, highlighting a research gap in this field. Our research addresses these issues by developing a two-stage method for Multi-Modal Cold-Start Active Learning (MMCSAL). Firstly, we observe the modality gap, a significant distance between the centroids of representations from different modalities, when only using cross-modal pairing information as self-supervision signals. This modality gap affects data selection process, as we calculate both uni-modal and cross-modal distances. To address this, we introduce uni-modal prototypes to bridge the modality gap. Secondly, conventional AL methods often falter in multimodal scenarios where alignment between modalities is overlooked. Therefore, we propose enhancing cross-modal alignment through regularization, thereby improving the quality of selected multimodal data pairs in AL. Finally, our experiments demonstrate MMCSAL's efficacy in selecting multimodal data pairs across three multimodal datasets.
Situational Scene Graph for Structured Human-centric Situation Understanding
Oct 30, 2024Graph based representation has been widely used in modelling spatio-temporal relationships in video understanding. Although effective, existing graph-based approaches focus on capturing the human-object relationships while ignoring fine-grained semantic properties of the action components. These semantic properties are crucial for understanding the current situation, such as where does the action takes place, what tools are used and functional properties of the objects. In this work, we propose a graph-based representation called Situational Scene Graph (SSG) to encode both human-object relationships and the corresponding semantic properties. The semantic details are represented as predefined roles and values inspired by situation frame, which is originally designed to represent a single action. Based on our proposed representation, we introduce the task of situational scene graph generation and propose a multi-stage pipeline Interactive and Complementary Network (InComNet) to address the task. Given that the existing datasets are not applicable to the task, we further introduce a SSG dataset whose annotations consist of semantic role-value frames for human, objects and verb predicates of human-object relations. Finally, we demonstrate the effectiveness of our proposed SSG representation by testing on different downstream tasks. Experimental results show that the unified representation can not only benefit predicate classification and semantic role-value classification, but also benefit reasoning tasks on human-centric situation understanding. We will release the code and the dataset soon.
A Unified Framework for Guiding Generative AI with Wireless Perception in Resource Constrained Mobile Edge Networks
Sep 04, 2023With the significant advancements in artificial intelligence (AI) technologies and powerful computational capabilities, generative AI (GAI) has become a pivotal digital content generation technique for offering superior digital services. However, directing GAI towards desired outputs still suffer the inherent instability of the AI model. In this paper, we design a novel framework that utilizes wireless perception to guide GAI (WiPe-GAI) for providing digital content generation service, i.e., AI-generated content (AIGC), in resource-constrained mobile edge networks. Specifically, we first propose a new sequential multi-scale perception (SMSP) algorithm to predict user skeleton based on the channel state information (CSI) extracted from wireless signals. This prediction then guides GAI to provide users with AIGC, such as virtual character generation. To ensure the efficient operation of the proposed framework in resource constrained networks, we further design a pricing-based incentive mechanism and introduce a diffusion model based approach to generate an optimal pricing strategy for the service provisioning. The strategy maximizes the user's utility while enhancing the participation of the virtual service provider (VSP) in AIGC provision. The experimental results demonstrate the effectiveness of the designed framework in terms of skeleton prediction and optimal pricing strategy generation comparing with other existing solutions.
Towards Balanced Active Learning for Multimodal Classification
Jun 14, 2023



Training multimodal networks requires a vast amount of data due to their larger parameter space compared to unimodal networks. Active learning is a widely used technique for reducing data annotation costs by selecting only those samples that could contribute to improving model performance. However, current active learning strategies are mostly designed for unimodal tasks, and when applied to multimodal data, they often result in biased sample selection from the dominant modality. This unfairness hinders balanced multimodal learning, which is crucial for achieving optimal performance. To address this issue, we propose three guidelines for designing a more balanced multimodal active learning strategy. Following these guidelines, a novel approach is proposed to achieve more fair data selection by modulating the gradient embedding with the dominance degree among modalities. Our studies demonstrate that the proposed method achieves more balanced multimodal learning by avoiding greedy sample selection from the dominant modality. Our approach outperforms existing active learning strategies on a variety of multimodal classification tasks. Overall, our work highlights the importance of balancing sample selection in multimodal active learning and provides a practical solution for achieving more balanced active learning for multimodal classification.
UniS-MMC: Multimodal Classification via Unimodality-supervised Multimodal Contrastive Learning
May 16, 2023



Multimodal learning aims to imitate human beings to acquire complementary information from multiple modalities for various downstream tasks. However, traditional aggregation-based multimodal fusion methods ignore the inter-modality relationship, treat each modality equally, suffer sensor noise, and thus reduce multimodal learning performance. In this work, we propose a novel multimodal contrastive method to explore more reliable multimodal representations under the weak supervision of unimodal predicting. Specifically, we first capture task-related unimodal representations and the unimodal predictions from the introduced unimodal predicting task. Then the unimodal representations are aligned with the more effective one by the designed multimodal contrastive method under the supervision of the unimodal predictions. Experimental results with fused features on two image-text classification benchmarks UPMC-Food-101 and N24News show that our proposed Unimodality-Supervised MultiModal Contrastive UniS-MMC learning method outperforms current state-of-the-art multimodal methods. The detailed ablation study and analysis further demonstrate the advantage of our proposed method.
Speech Emotion Recognition with Co-Attention based Multi-level Acoustic Information
Mar 29, 2022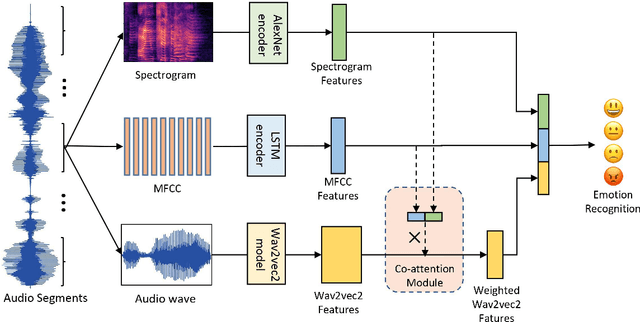
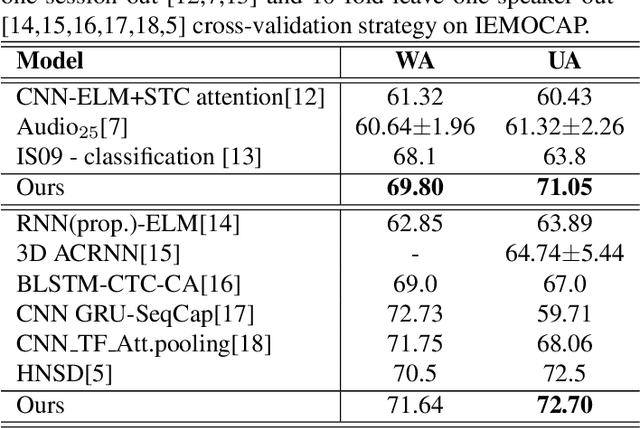
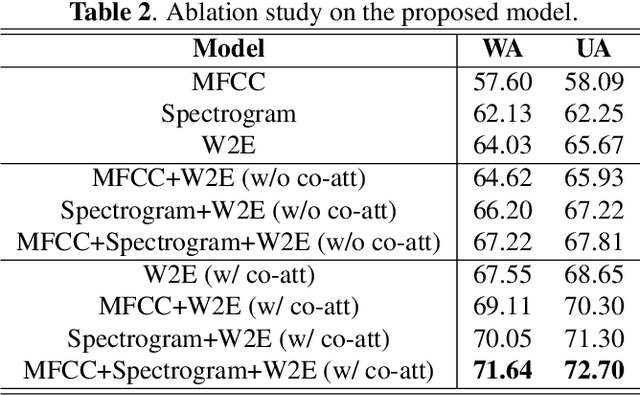
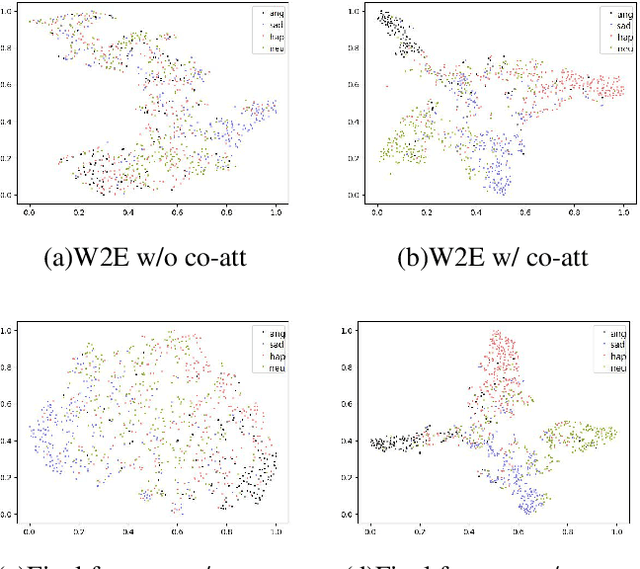
Speech Emotion Recognition (SER) aims to help the machine to understand human's subjective emotion from only audio information. However, extracting and utilizing comprehensive in-depth audio information is still a challenging task. In this paper, we propose an end-to-end speech emotion recognition system using multi-level acoustic information with a newly designed co-attention module. We firstly extract multi-level acoustic information, including MFCC, spectrogram, and the embedded high-level acoustic information with CNN, BiLSTM and wav2vec2, respectively. Then these extracted features are treated as multimodal inputs and fused by the proposed co-attention mechanism. Experiments are carried on the IEMOCAP dataset, and our model achieves competitive performance with two different speaker-independent cross-validation strategies. Our code is available on GitHub.
Are object detection assessment criteria ready for maritime computer vision?
Sep 12, 2018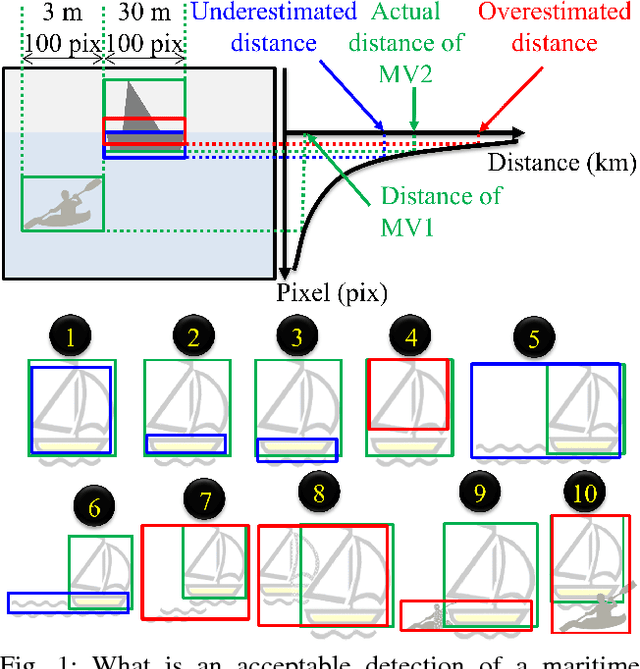
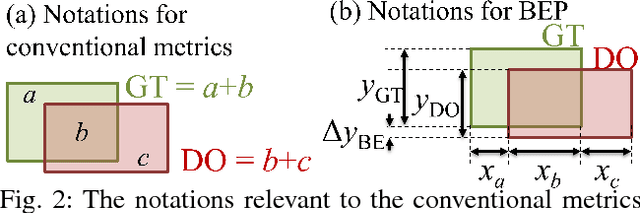
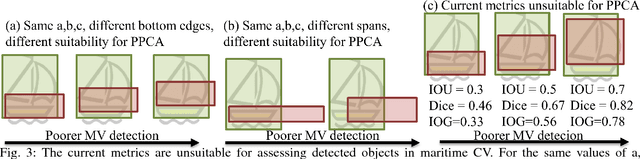
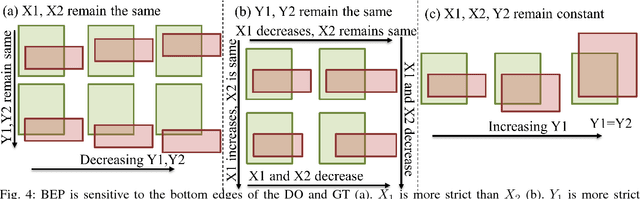
Maritime vessels equipped with visible and infrared cameras can complement other conventional sensors for object detection. However, application of computer vision techniques in maritime domain received attention only recently. Maritime environment offers its own unique requirements and challenges. Assessment of quality of detections is a fundamental need in computer vision. However, the conventional assessment metrics suitable for usual object detection are deficient in maritime setting. Thus, a large body of related work in computer vision appears inapplicable to maritime setting at the first sight. We discuss the problem of defining assessment metrics suitable for maritime computer vision. We consider new bottom edge proximity metrics as assessment metrics for maritime computer vision. These metrics indicate that existing computer vision approaches are indeed promising for maritime computer vision and can play a foundational role in the emerging field of maritime computer vision.