 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Concept Erasure for Diffusion Models
May 27, 2026Concept erasure has emerged as a promising approach to mitigate undesired or unsafe content in diffusion models, yet existing methods still face significant limitations. While training-based methods are effective, their high computational cost limits scalability. Editing-based methods are more efficient and deployment-friendly, yet they struggle to simultaneously achieve precise concept erasure and preserve overall generative capacity. We identify this core limitation of the editing-based methods as reliance on additive parameter updates. Our empirical analysis reveals that concept semantics primarily depend on neuron direction rather than neuron magnitude, while overall generative capacity relies on the angular geometry of neurons. As additive updates inherently entangle direction, magnitude, and angular geometry, they inevitably introduce unintended interference between concept erasure and overall generation performance. To address this, we propose Orthogonal Concept Erasure (OCE), which reformulates editing-based erasure as multiplicative parameter updates from a geometric perspective. Specifically, OCE applies layer-wise orthogonal transformations derived from a closed-form solution to the parameters, enabling precise concept erasure while preserving the neuron magnitude and angular geometry. Furthermore, to address conflicting constraints in multi-concept erasure, OCE introduces a subspace-level objective with structured subspace manipulation, yielding a more effective and scalable erasure. Extensive experiments on single- and multi-concept erasure demonstrate that OCE outperforms existing methods in concept erasure and non-target preservation, erasing up to 100 concepts in 4.3 s. Code: https://github.com/HansSunY/OCE.
UpSafe$^\circ$C: Upcycling for Controllable Safety in Large Language Models
Oct 02, 2025



Large Language Models (LLMs) have achieved remarkable progress across a wide range of tasks, but remain vulnerable to safety risks such as harmful content generation and jailbreak attacks. Existing safety techniques -- including external guardrails, inference-time guidance, and post-training alignment -- each face limitations in balancing safety, utility, and controllability. In this work, we propose UpSafe$^\circ$C, a unified framework for enhancing LLM safety through safety-aware upcycling. Our approach first identifies safety-critical layers and upcycles them into a sparse Mixture-of-Experts (MoE) structure, where the router acts as a soft guardrail that selectively activates original MLPs and added safety experts. We further introduce a two-stage SFT strategy to strengthen safety discrimination while preserving general capabilities. To enable flexible control at inference time, we introduce a safety temperature mechanism, allowing dynamic adjustment of the trade-off between safety and utility. Experiments across multiple benchmarks, base model, and model scales demonstrate that UpSafe$^\circ$C achieves robust safety improvements against harmful and jailbreak inputs, while maintaining competitive performance on general tasks. Moreover, analysis shows that safety temperature provides fine-grained inference-time control that achieves the Pareto-optimal frontier between utility and safety. Our results highlight a new direction for LLM safety: moving from static alignment toward dynamic, modular, and inference-aware control.
Efficient Transfer Learning for Video-language Foundation Models
Nov 18, 2024



Pre-trained vision-language models provide a robust foundation for efficient transfer learning across various downstream tasks. In the field of video action recognition, mainstream approaches often introduce additional parameter modules to capture temporal information. While the increased model capacity brought by these additional parameters helps better fit the video-specific inductive biases, existing methods require learning a large number of parameters and are prone to catastrophic forgetting of the original generalizable knowledge. In this paper, we propose a simple yet effective Multi-modal Spatio-Temporal Adapter (MSTA) to improve the alignment between representations in the text and vision branches, achieving a balance between general knowledge and task-specific knowledge. Furthermore, to mitigate over-fitting and enhance generalizability, we introduce a spatio-temporal description-guided consistency constraint. This constraint involves feeding template inputs (i.e., ``a video of $\{\textbf{cls}\}$'') into the trainable language branch, while LLM-generated spatio-temporal descriptions are input into the pre-trained language branch, enforcing consistency between the outputs of the two branches. This mechanism prevents over-fitting to downstream tasks and improves the distinguishability of the trainable branch within the spatio-temporal semantic space. We evaluate the effectiveness of our approach across four tasks: zero-shot transfer, few-shot learning, base-to-novel generalization, and fully-supervised learning. Compared to many state-of-the-art methods, our MSTA achieves outstanding performance across all evaluations, while using only 2-7\% of the trainable parameters in the original model. Code will be avaliable at https://github.com/chenhaoxing/ETL4Video.
DeMamba: AI-Generated Video Detection on Million-Scale GenVideo Benchmark
May 30, 2024



Recently, video generation techniques have advanced rapidly. Given the popularity of video content on social media platforms, these models intensify concerns about the spread of fake information. Therefore, there is a growing demand for detectors capable of distinguishing between fake AI-generated videos and mitigating the potential harm caused by fake information. However, the lack of large-scale datasets from the most advanced video generators poses a barrier to the development of such detectors. To address this gap, we introduce the first AI-generated video detection dataset, GenVideo. It features the following characteristics: (1) a large volume of videos, including over one million AI-generated and real videos collected; (2) a rich diversity of generated content and methodologies, covering a broad spectrum of video categories and generation techniques. We conducted extensive studies of the dataset and proposed two evaluation methods tailored for real-world-like scenarios to assess the detectors' performance: the cross-generator video classification task assesses the generalizability of trained detectors on generators; the degraded video classification task evaluates the robustness of detectors to handle videos that have degraded in quality during dissemination. Moreover, we introduced a plug-and-play module, named Detail Mamba (DeMamba), designed to enhance the detectors by identifying AI-generated videos through the analysis of inconsistencies in temporal and spatial dimensions. Our extensive experiments demonstrate DeMamba's superior generalizability and robustness on GenVideo compared to existing detectors. We believe that the GenVideo dataset and the DeMamba module will significantly advance the field of AI-generated video detection. Our code and dataset will be aviliable at \url{https://github.com/chenhaoxing/DeMamba}.
Conditional Prototype Rectification Prompt Learning
Apr 15, 2024



Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at \url{https://github.com/chenhaoxing/CPR}.
TroubleLLM: Align to Red Team Expert
Feb 28, 2024Large Language Models (LLMs) become the start-of-the-art solutions for a variety of natural language tasks and are integrated into real-world applications. However, LLMs can be potentially harmful in manifesting undesirable safety issues like social biases and toxic content. It is imperative to assess its safety issues before deployment. However, the quality and diversity of test prompts generated by existing methods are still far from satisfactory. Not only are these methods labor-intensive and require large budget costs, but the controllability of test prompt generation is lacking for the specific testing domain of LLM applications. With the idea of LLM for LLM testing, we propose the first LLM, called TroubleLLM, to generate controllable test prompts on LLM safety issues. Extensive experiments and human evaluation illustrate the superiority of TroubleLLM on generation quality and generation controllability.
Segment Anything Model Meets Image Harmonization
Dec 20, 2023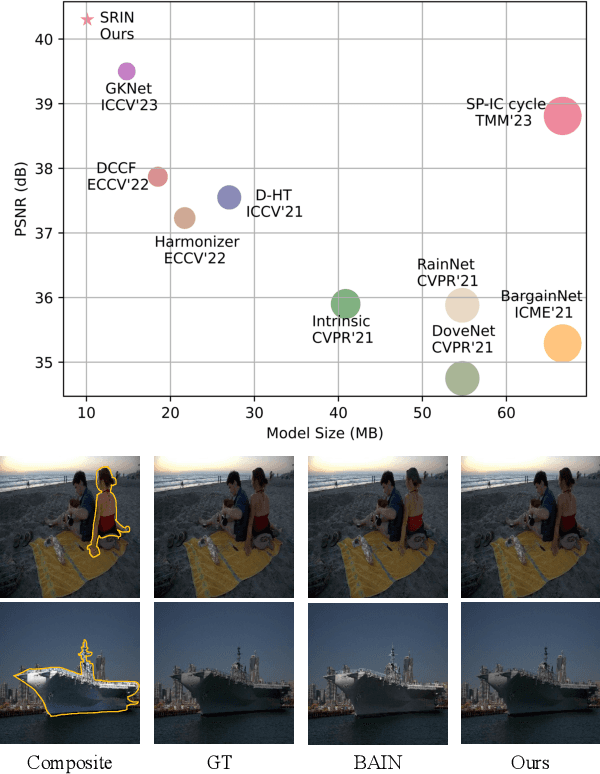
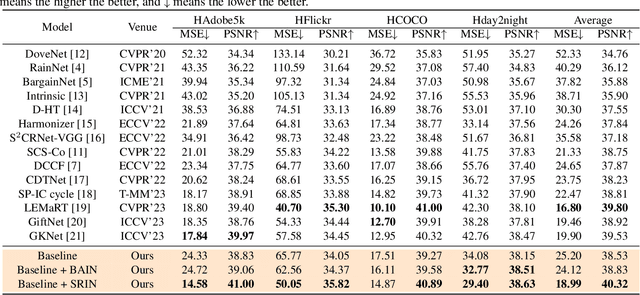
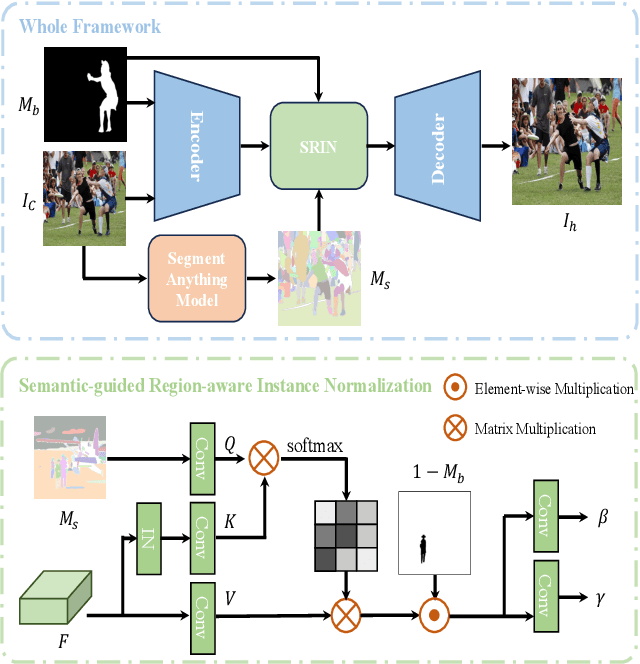
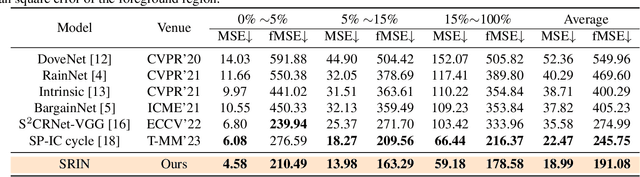
Image harmonization is a crucial technique in image composition that aims to seamlessly match the background by adjusting the foreground of composite images. Current methods adopt either global-level or pixel-level feature matching. Global-level feature matching ignores the proximity prior, treating foreground and background as separate entities. On the other hand, pixel-level feature matching loses contextual information. Therefore, it is necessary to use the information from semantic maps that describe different objects to guide harmonization. In this paper, we propose Semantic-guided Region-aware Instance Normalization (SRIN) that can utilize the semantic segmentation maps output by a pre-trained Segment Anything Model (SAM) to guide the visual consistency learning of foreground and background features. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods.
Boosting Audio-visual Zero-shot Learning with Large Language Models
Nov 21, 2023



Audio-visual zero-shot learning aims to recognize unseen categories based on paired audio-visual sequences. Recent methods mainly focus on learning aligned and discriminative multi-modal features to boost generalization towards unseen categories. However, these approaches ignore the obscure action concepts in category names and may inevitably introduce complex network structures with difficult training objectives. In this paper, we propose a simple yet effective framework named Knowledge-aware Distribution Adaptation (KDA) to help the model better grasp the novel action contents with an external knowledge base. Specifically, we first propose using large language models to generate rich descriptions from category names, which leads to a better understanding of unseen categories. Additionally, we propose a distribution alignment loss as well as a knowledge-aware adaptive margin loss to further improve the generalization ability towards unseen categories. Extensive experimental results demonstrate that our proposed KDA can outperform state-of-the-art methods on three popular audio-visual zero-shot learning datasets. Our code will be avaliable at \url{https://github.com/chenhaoxing/KDA}.
Backpropagation Path Search On Adversarial Transferability
Aug 15, 2023



Deep neural networks are vulnerable to adversarial examples, dictating the imperativeness to test the model's robustness before deployment. Transfer-based attackers craft adversarial examples against surrogate models and transfer them to victim models deployed in the black-box situation. To enhance the adversarial transferability, structure-based attackers adjust the backpropagation path to avoid the attack from overfitting the surrogate model. However, existing structure-based attackers fail to explore the convolution module in CNNs and modify the backpropagation graph heuristically, leading to limited effectiveness. In this paper, we propose backPropagation pAth Search (PAS), solving the aforementioned two problems. We first propose SkipConv to adjust the backpropagation path of convolution by structural reparameterization. To overcome the drawback of heuristically designed backpropagation paths, we further construct a DAG-based search space, utilize one-step approximation for path evaluation and employ Bayesian Optimization to search for the optimal path. We conduct comprehensive experiments in a wide range of transfer settings, showing that PAS improves the attack success rate by a huge margin for both normally trained and defense models.
On the Robustness of Latent Diffusion Models
Jun 14, 2023



Latent diffusion models achieve state-of-the-art performance on a variety of generative tasks, such as image synthesis and image editing. However, the robustness of latent diffusion models is not well studied. Previous works only focus on the adversarial attacks against the encoder or the output image under white-box settings, regardless of the denoising process. Therefore, in this paper, we aim to analyze the robustness of latent diffusion models more thoroughly. We first study the influence of the components inside latent diffusion models on their white-box robustness. In addition to white-box scenarios, we evaluate the black-box robustness of latent diffusion models via transfer attacks, where we consider both prompt-transfer and model-transfer settings and possible defense mechanisms. However, all these explorations need a comprehensive benchmark dataset, which is missing in the literature. Therefore, to facilitate the research of the robustness of latent diffusion models, we propose two automatic dataset construction pipelines for two kinds of image editing models and release the whole dataset. Our code and dataset are available at \url{https://github.com/jpzhang1810/LDM-Robustness}.